apigw鉴权分析(1-3)百度 AI - 鉴权方式分析
http://ai.baidu.com/docs#/Begin/top
一、访问入口
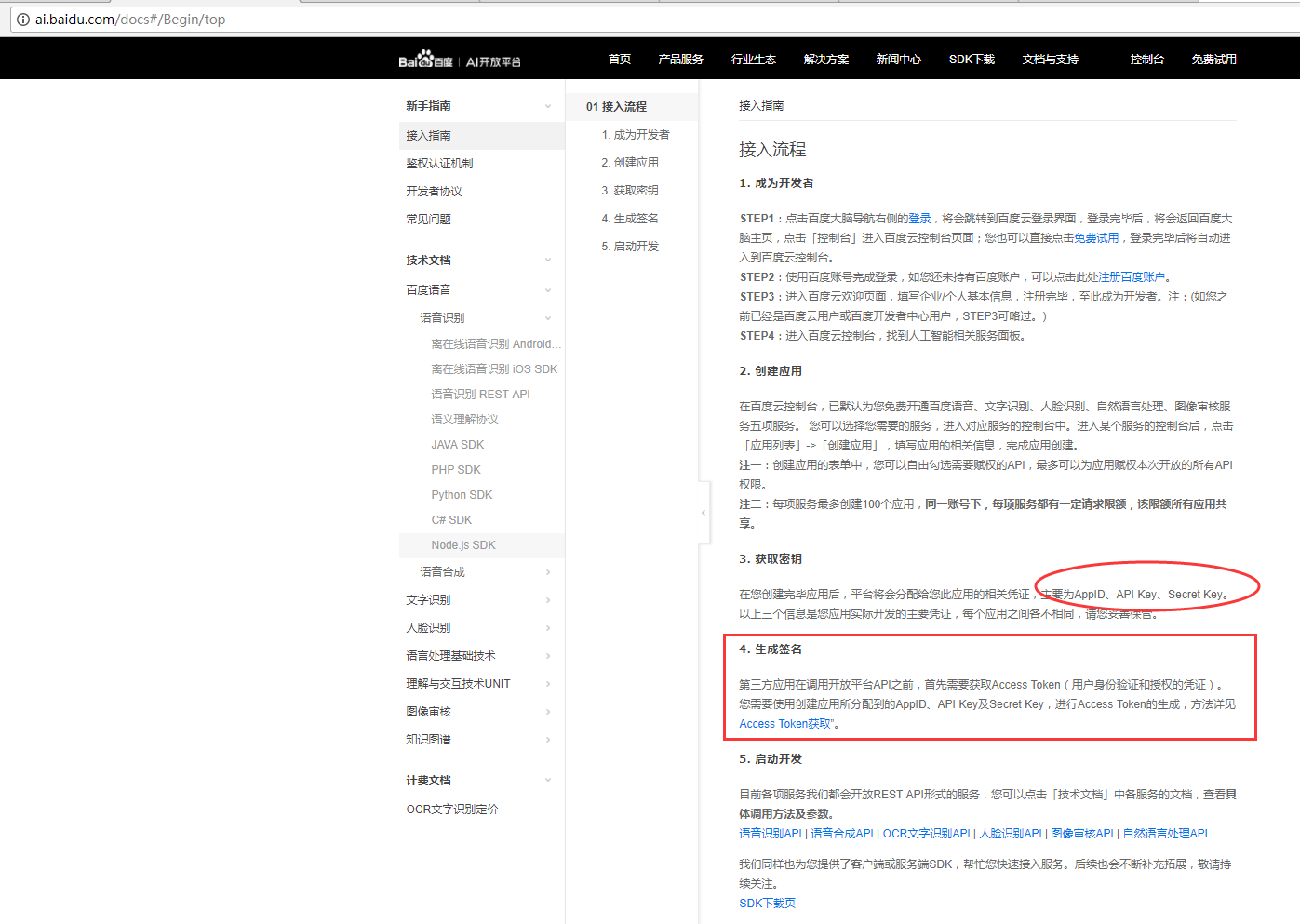
二、鉴权方式分析
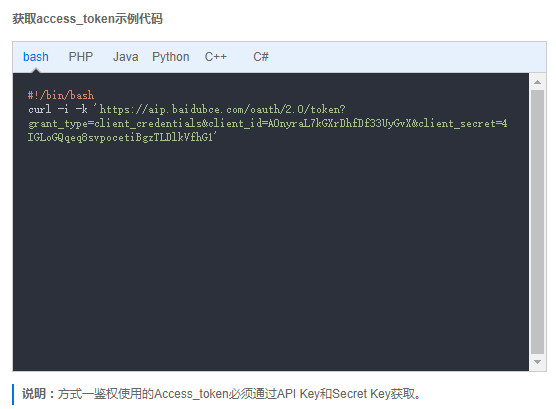
1、鉴权认证方式一 - access_token - 针对HTTP API调用者


2、鉴权认证方式二 - API认证 - 针对RESTful API调用者。
2.1、获取ak和sk
AK(Access Key ID)/SK(Secret Access Key),主要用于对用户的调用行为进行鉴权和认证,相当于百度云API专用的用户名及密码。有关API认证的详细介绍,请参看API认证机制


2.2、使用 认证方式和匿名方式 鉴权
用户可以通过两种方式与百度云进行交互,包括认证方式和匿名方式。
对于认证方式,需要通过使用Access Key Id / Secret Access Key加密的方法来验证某个请求的发送者身份。
Access Key Id(AK)用于标示用户,Secret Access Key(SK)是用户用于加密认证字符串和百度云用来验证认证字符串的密钥,其中SK必须保密,只有用户和百度云知道。
当百度云接收到用户的请求后,系统将使用相同的SK和同样的认证机制生成认证字符串,并与用户请求中包含的认证字符串进行比对。
如果认证字符串相同,系统认为用户拥有指定的操作权限,并执行相关操作;
如果认证字符串不同,系统将忽略该操作并返回错误码。




2.3、认证字符串生成机制
1 生成认证字符串的方法
1.1 概述
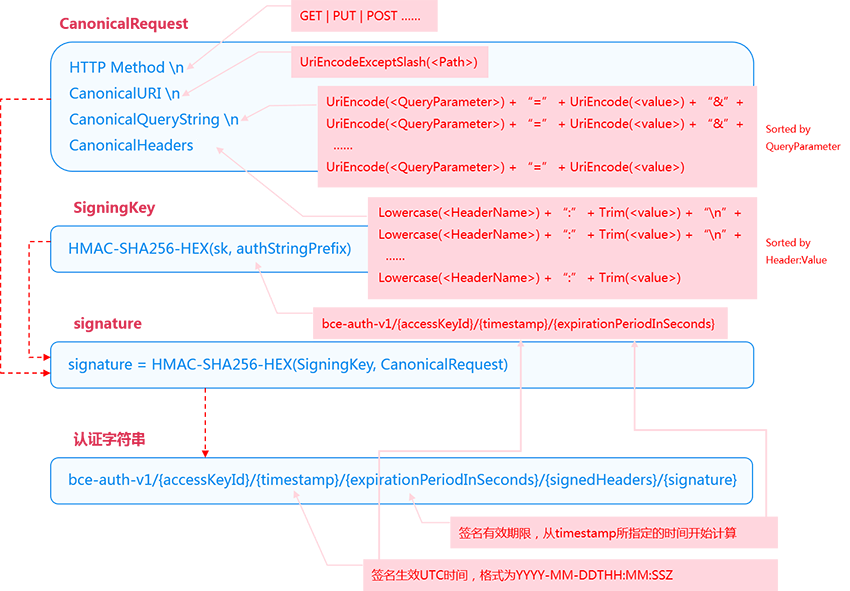
在生成认证字符串之前,首先需要生成Signature。为了生成Signature,用户需要首先构建CanonicalRequest并计算SigningKey,具体内容如下图所示:
下表介绍了上图中涉及的函数:
| 函数名 | 功能描述 |
|---|---|
| HMAC-SHA256-HEX() | 调用HMAC SHA256算法,根据开发者提供的密钥(key)和密文(message)输出密文摘要,并把结果转换为小写形式的十六进制字符串。 |
| Lowercase() | 将字符串全部变成小写。 |
| Trim() | 去掉字符串开头和结尾的空白字符。 |
| UriEncode() | RFC 3986规定,"URI非保留字符"包括以下字符:字母(A-Z,a-z)、数字(0-9)、连字号(-)、点号(.)、下划线(_)、波浪线(~),算法实现如下: 1. 将字符串转换成UTF-8编码的字节流 2. 保留所有“URI非保留字符”原样不变 3. 对其余字节做一次RFC 3986中规定的百分号编码(Percent-encoding),即一个“%”后面跟着两个表示该字节值的十六进制字母,字母一律采用大写形式。 |
| UriEncodeExceptSlash() | 与UriEncode() 类似,区别是斜杠(/)不做编码。一个简单的实现方式是先调用UriEncode(),然后把结果中所有的`%2F`都替换为`/` |
UriEncode()函数参考代码如下:
public static String uri-encode(CharSequence input, boolean encodeSlash) {;
StringBuilder result = new StringBuilder();;
for (int i = 0; i < input.length(); i++) {;
char ch = input.charAt(i);;
if ((ch >= 'A' && ch <= 'Z') || (ch >= 'a' && ch <= 'z') || (ch >= '0' && ch <= '9') || ch == '_' || ch == '-' || ch == '~' || ch == '.') {;
result.append(ch);;
} else if (ch == '/') {;
result.append(encodeSlash ? "%2F" : ch);;
} else {;
result.append(toHexUTF8(ch));;
};
};
return result.toString();;
};
1.2 生成CanonicalRequest
CanonicalRequest = HTTP Method + "\n" + CanonicalURI + "\n" + CanonicalQueryString + "\n" + CanonicalHeaders,其中:
HTTP Method:指HTTP协议中定义的GET、PUT、POST等请求,必须使用全大写的形式。百度云API所涉及的HTTP Method有五种:- GET
- POST
- PUT
- DELETE
- HEAD
CanonicalURI:是对URL中的绝对路径进行编码后的结果。要求绝对路径必须以“/”开头,不以“/”开头的需要补充上,空路径为“/”,即CanonicalURI=UriEncodeExceptSlash(Path)。相关举例:
若URL为
https://bos.cn-n1.baidubce.com/example/测试,则其URL Path为/example/测试,将之规范化得到CanonicalURI = /example/%E6%B5%8B%E8%AF%95。CanonicalQueryString:对于URL中的Query String(Query String即URL中“?”后面的“key1 = valve1 & key2 = valve2 ”字符串)进行编码后的结果。编码方法为:
- 将Query String根据
&拆开成若干项,每一项是key=value或者只有key的形式。 - 对拆开后的每一项进行如下处理:
- 对于
key是authorization,直接忽略。 - 对于只有
key的项,转换为UriEncode(key) + "="的形式。 - 对于
key=value的项,转换为UriEncode(key) + "=" + UriEncode(value)的形式。这里value可以是空字符串。
- 对于
- 将上面转换后的所有字符串按照字典顺序排序。
- 将排序后的字符串按顺序用
&符号链接起来。
相关举例:
若URL为
https://bos.cn-n1.baidubce.com/example?text&text1=测试&text10=test,在这个例子中Query String是text&text1=测试&text10=test。- 根据
&拆开成text、text1=测试和text10=test三项。 - 对每一项进行处理:
text=>UriEncode("text") + "="=>text=text1=测试=>UriEncode("text1") + "=" + UriEncode("测试")=>text1=%E6%B5%8B%E8%AF%95text10=test=>UriEncode("text10") + "=" + UriEncode("test")=>text10=test
- 对
text=、text1=%E6%B5%8B%E8%AF%95和text10=test按照字典序进行排序。它们有共同前缀text,但是=的ASCII码比所有数字的ASCII码都要大,因此text1=%E6%B5%8B%E8%AF%95和text10=test排在text=的前面。同样,text10=test要排在text1=%E6%B5%8B%E8%AF%95之前。最终结果是text10=test、text1=%E6%B5%8B%E8%AF%95、text=。 - 把排序好的三项
text10=test、text1=%E6%B5%8B%E8%AF%95、text=用&连接起来得到text10=test&text1=%E6%B5%8B%E8%AF%95&text=。
说明:
在这个特殊构造的例子里,我们展示了如何处理只有key的项,非英文的value,以及数字和=进行排序。在实际的BCE API中,因为参数起名是规范的,基本不会遇到这样的排序。正常的排序结果和只按照 key进行排序是完全一致的。算法中有这个约束主要是出于定义严密性的考虑。*
- 将Query String根据
CanonicalHeaders:对HTTP请求中的Header部分进行选择性编码的结果。您可以自行决定哪些Header 需要编码。百度云API的唯一要求是Host域必须被编码。大多数情况下,我们推荐您对以下Header进行编码:
- Host
- Content-Length
- Content-Type
- Content-MD5
- 所有以
x-bce-开头的Header
如果这些Header没有全部出现在您的HTTP请求里面,那么没有出现的部分无需进行编码。
如果您按照我们的推荐范围进行编码,那么认证字符串中的
{signedHeaders}可以直接留空,无需填写。您也可以自行选择自己想要编码的Header。如果您选择了不在推荐范围内的Header进行编码,或者您的HTTP请求包含了推荐范围内的Header但是您选择不对它进行编码,那么您必须在认证字符串中填写
{signedHeaders}。填写方法为,把所有在这一阶段进行了编码的Header名字转换成全小写之后按照字典序排列,然后用分号(;)连接。选择哪些Header进行编码不会影响API的功能,但是如果选择太少则可能遭到中间人攻击。
对于每个要编码的Header进行如下处理:
- 将Header的名字变成全小写。
- 将Header的值去掉开头和结尾的空白字符。
- 经过上一步之后值为空字符串的Header忽略,其余的转换为
UriEncode(name) + ":" + UriEncode(value)的形式。 - 把上面转换后的所有字符串按照字典序进行排序。
- 将排序后的字符串按顺序用
\n符号连接起来得到最终的CanonicalQueryHeaders。
注意:很多发送HTTP请求的第三方库,会添加或者删除你指定的header(例如:某些库会删除content-length:0这个header),如果签名错误,请检查你您真实发出的http请求的header,看看是否与签名时的header一样。
相关举例1:
不使用signedHeaders默认值。若希望对
Date进行编码,但是不希望对x-bce-date进行编码,则需要用到signedHeaders。要编码的Header如下:
Host: bj.bcebos.com
Date: Mon, 27 Apr 2015 16:23:49 +0800
Content-Type: text/plain
Content-Length: 8
Content-Md5: NFzcPqhviddjRNnSOGo4rw==
- 首先把所有名字都改为小写。
host: bj.bcebos.com
date: Mon, 27 Apr 2015 16:23:49 +0800
content-type: text/plain
content-length: 8
content-md5: NFzcPqhviddjRNnSOGo4rw==
- 将Header的值去掉开头和结尾的空白字符。
host:bj.bcebos.com
date:Mon, 27 Apr 2015 16:23:49 +0800
content-type:text/plain
content-length:8
content-md5:NFzcPqhviddjRNnSOGo4rw==
- 做UriEncode。
host:bj.bcebos.com
date:Mon%2C%2027%20Apr%202015%2016%3A23%3A49%20%2B0800
content-type:text%2Fplain
content-length:8
content-md5:NFzcPqhviddjRNnSOGo4rw==
- 把上面转换后的所有字符串按照字典序进行排序。
content-length:8
content-md5:NFzcPqhviddjRNnSOGo4rw==
content-type:text%2Fplain
date:Mon%2C%2027%20Apr%202015%2016%3A23%3A49%20%2B0800
host:bj.bcebos.com
- 将排序后的字符串按顺序用
\n符号连接起来得到最终结果。content-length:8
content-md5:NFzcPqhviddjRNnSOGo4rw==
content-type:text%2Fplain
date:Mon%2C%2027%20Apr%202015%2016%3A23%3A49%20%2B0800
host:bj.bcebos.com
这时候认证字符串的
signedHeaders内容应该是content-length;content-md5;content-type;date;host。
相关举例2:
CanonicalHeaders的排序和signedHeaders排序不一致。和
CanonicalQueryString的示例一样,CanonicalHeaders也需要考虑排序的特殊情况。因为BCE API存在允许用户自定义Header的情况,所以这里需要特别注意。在BOS的PutObject中允许用户上传自定义meta,为了简明介绍,我们省略大部分Header,假设要编码的Headers如下:
Host: bj.bcebos.com
x-bce-meta-data: my meta data
x-bce-meta-data-tag: description
最终得到的
CanonicalHeaders是:host:bj.bcebos.com
x-bce-meta-data-tag:description
x-bce-meta-data:my%20meta%20data
而
signedHeaders是host;x-bce-meta-data;x-bce-meta-data-tag。从字符串比较的角度来说
x-bce-meta-data应该放在x-bce-meta-data-tag之前,因此signedHeaders里面遵循了这个排序。但是CanonicalHeaders中因为在name和value之间还有一个冒号(:),而冒号的ASCII码值要大于连字号(-)的ASCII码值,因此x-bce-meta-data反而放在了x-bce-meta-data-tag之后。
1.3 生成SigningKey
SigningKey = HMAC-SHA256-HEX(sk, authStringPrefix),其中:
sk为用户的Secret Access Key,可以通过在控制台中进行查询,关于SK的获取方法,请参看获取AK/SK。authStringPrefix代表认证字符串的前缀部分,即:bce-auth-v1/{accessKeyId}/{timestamp}/{expirationPeriodInSeconds}。
1.4 生成Signature
Signature = HMAC-SHA256-HEX(SigningKey, CanonicalRequest)
1.5 生成认证字符串
认证字符串 = bce-auth-v1/{accessKeyId}/{timestamp}/{expirationPeriodInSeconds}/{signedHeaders}/{signature}
timestamp:签名生效UTC时间,格式为yyyy-mm-ddThh:mm:ssZ,例如:2015-04-27T08:23:49Z,默认值为当前时间。expirationPeriodInSeconds:签名有效期限,从timestamp所指定的时间开始计算,时间为秒,默认值为1800秒(30)分钟。signedHeaders:签名算法中涉及到的HTTP头域列表。HTTP头域名字一律要求小写且头域名字之间用分号(;)分隔,如host;range;x-bce-date。列表按照字典序排列。当signedHeaders为空时表示取默认值。
2 认证字符串生成举例
为了便于用户理解认证字符串的生成过程,我们将使用一个例子来详细介绍算法的生成步骤。
假设用户向北京的BOS集群使用UploadPart接口上传一个文件的最后一个Part,内容为Example。
- Bucket name:test
- Object key:myfolder/readme.txt
- uploadId:a44cc9bab11cbd156984767aad637851
- partNumber:9
- Access Key ID:aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
- Secret Access Key:bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
- 时间:北京时间2015年4月27日16点23分49秒(转换为UTC时间是2015年4月27日8点23分49秒)
则其HTTP请求如下:
PUT /v1/test/myfolder/readme.txt?partNumber=9&uploadId=a44cc9bab11cbd156984767aad637851 HTTP/1.1
Host: bj.bcebos.com
Date: Mon, 27 Apr 2015 16:23:49 +0800
Content-Type: text/plain
Content-Length: 8
Content-Md5: NFzcPqhviddjRNnSOGo4rw==
x-bce-date: 2015-04-27T08:23:49Z
Example
A. 生成CanonicalRequest
PUT
/v1/test/myfolder/readme.txt
partNumber=9&uploadId=a44cc9bab11cbd156984767aad637851
content-length:8
content-md5:NFzcPqhviddjRNnSOGo4rw==
content-type:text%2Fplain
host:bj.bcebos.com
x-bce-date:2015-04-27T08%3A23%3A49Z
B. 生成SigningKey
SigningKey = HMAC-SHA256-HEX(sk, authStringPrefix)
= HMAC-SHA256-HEX("bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb", "bce-auth-v1/aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/2015-04-27T08:23:49Z/1800")
最终得到:SigningKey = 1d5ce5f464064cbee060330d973218821825ac6952368a482a592e6615aef479
C. 生成Signature
Signature = HMAC-SHA256-HEX(SigningKey, CanonicalRequest)
= 8566237931756474409b68828a8175d0a3dde00359560e5cf6adccdb09a195e0
D. 生成认证字符串
Authorization = bce-auth-v1/aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/2015-04-27T08:23:49Z/1800//b02547aedd91dc438d6bb6d1be68b35917828271b340b9e7d1a7bcd051869054
注意:
超时时间1800与签名结果之间为两个”/”,含义是使用默认签名方式,signedHeaders内容留空。
三、分析结论
1、方式一:签名方式
2、方式二:oath2方式
apigw鉴权分析(1-3)百度 AI - 鉴权方式分析的更多相关文章
- apigw鉴权分析(1-1)阿里数加 - 鉴权方式分析
一.访问方式 1.访问阿里云首页 https://www.aliyun.com/?utm_medium=text&utm_source=bdbrand&utm_campaign=bdb ...
- 了解人工智能?-百度AI
了解人工智能? 什么是人工智能? 由人创造的"智慧能力",同样具备智慧生物的能力 耳朵=倾听=麦克风=语音识别 ASR Automatic Speech Recognition 嘴 ...
- 百度AI开放平台- API实战调用
百度AI开放平台- API实战调用 一. 前言 首先说一下项目需求. 两个用户,分别上传了两段不同的文字,要计算两段文字相似度有多少,匹配数据库中的符合条件的数据,初步估计列出来会有60-1 ...
- 百度AI技术
利用百度提供接口,实现智能语音 语音合成 -- TTS(text to speech) 注册 在 ai.baidu.com 页面中点击 控制台 ,弹出登陆 / 注册页面 创建应用 登陆成功后,点击左侧 ...
- 百度AI技术QQ群
百度语音QQ群 648968704 视频分析QQ群 632473158 DuerOSQQ群 604592023 图像识别QQ群 649285136 文字识别QQ群 631977213 理解与交互技术U ...
- 初探机器学习之使用百度AI服务实现图片识别与相似图片
一.百度云AI服务 最近在调研一些云服务平台的AI(人工智能)服务,了解了一下阿里云.腾讯云和百度云.其中,百度云提供了图像识别及图像搜索,而且还细分地提供了相似图片这项服务,比较符合我的需求,且百度 ...
- python 全栈开发,Day122(人工智能初识,百度AI)
一.人工智能初识 什么是智能? 我们通常把人成为智慧生物,那么”智慧生物的能力”就是所谓的”智能”我们有什么能力?听,说,看,理解,思考,情感等等 什么是人工智能? 顾名思义就是由人创造的”智慧能力” ...
- 百度AI认为最漂亮的中国女星是----范冰冰
一.程序说明 1.1 程序说明 之前写调用百度AI接口的程序,然后刷到了两条明星的新闻,就想到了写个给明星颜值排下名的程序. 程序的关键点是两个,第一个是百度AI接口的调用这点其实直接使用早前实现的类 ...
- 百度AI人脸识别的学习总结
本文主要分以下几个模块进行总结分析 项目要求:运用百度AI(人脸识别)通过本地与外网之间的信息交互(MQService),从而通过刷脸实现登陆.签字.会议签到等: 1.准备工作: 内网:单击事件按钮— ...
随机推荐
- 关于del命令
del命令用于删除具体的文件,但是删除文件的时候如果不指定文件的扩展名就会显示找不到文件 还有如果所要删除文件的文件名中含有空格的话该命令会自动识别为几个文件,就从空格处把文件 分成几份,然后就会显示 ...
- js 数组 remove
在写js代码时候,有时需要移除数组的元素,在js数组中没有remove 方法, 不过有splice 方法同样可以用于移除数组元素:(http://www.w3school.com.cn/jsref/j ...
- spring+springMVC 整合 MongoDB 实现注册登录
发现一入手 MongoDB,便无法脱离,简要说一下,MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的. 也是在 Nosql 中我最喜欢的一种 ...
- 使用jitpack来获取github上的开源项目
在开发中我们需要经常使用第三方依赖库,在构建工具Gradle或maven中声明依赖, 大部分使用的是maven中心仓库或者阿里云仓库等等,但是这样也存在一个问题,上述仓库的库虽然简单快捷好用,但并不是 ...
- 笔记:Maven 项目报告插件
Maven 项目报告插件,都是对于前面生成的项目站点的内容丰富,因此都是基于项目站点的,生成的命令和生成项目站点一致(mvn site),项目报告插件的配置和一般插件不同,是在 project-> ...
- 大数据 --> 一致性Hash算法
一致性Hash算法 一致性Hash算法(Consistent Hash)
- 常见的链表排序(Java版)
上篇博客中讲解了九大内部排序算法,部分算法还提供了代码实现,但是那些代码实现都是基于数组进行排序的,本篇博客就以链表排序实现几种常见的排序算法,以飨读者. 快速排序的链表实现 算法思想:对于一个链表, ...
- 测试对bug如何分析和定位
如何去区分一个功能测试工程师的水平高和低? 可以从很多个方面去检查,比如测试的思路, 比如测试用例的覆盖度?,比如测试出bug是否能够定位到根因? 上面说的各个方面都很合理,那我们平常如何如更深的定位 ...
- http的CA证书安装(也就是https)
近几年随着安全意识的提高,https流行起来,很多小伙伴不太了解https是什么,其实http和https并没有区别,简单的来说,https就是将http通信进行了加密和解密的一个过程.加上谷歌浏览器 ...
- [日常] 最近的一些破事w...
更新博文一篇以示诈尸(大雾 (其实只是断了个网然后就彻底失踪了一波w...连题解都没法写了QAQ) $ \tiny{诈尸的实际情况是老姚提前走还把十一机房门锁了然而钥匙在联赛的时候就还了于是并不能进去 ...