一个简易的Python爬虫,将爬取到的数据写入txt文档中
代码如下:
import requests
import re
import os
#url
url = "http://wiki.akbfun48.com/index.php?title=%E4%B9%83%E6%9C%A8%E5%9D%82%E5%B7%A5%E4%BA%8B%E4%B8%AD&variant=zh-hans"
#请求头
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer":url
}
r = requests.get(url,headers=headers)
if r.status_code == 200: #响应200为请求成功
r.encoding = r.apparent_encoding #转换字符编码
html = r.text
#正则表达式匹配数据,获取数据列表
list = re.findall(r'>http://www.bilibili.com/video/av.*\/<',html)
count = 0
#循环列表,将数据写入txt文档中
for i in list:
count += 1
#如果没有txt文件则新建文件,并执行写入操作
with open("abc.txt",'a',encoding='utf-8') as f:
f.write("ep"+str(count)+i+'\n')
print("success")
else:
print(404)
运行效果如下:

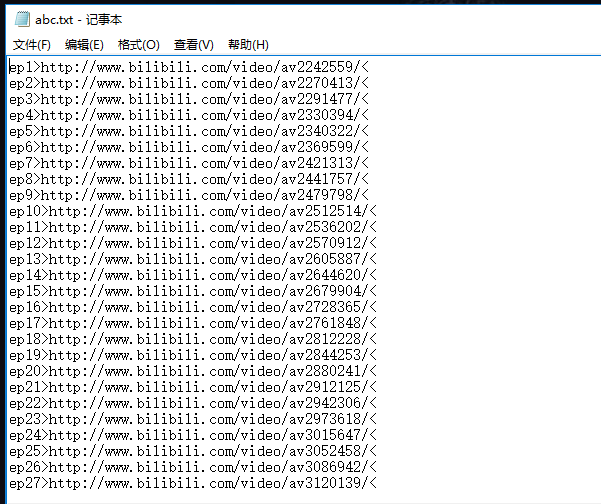
执行后,会在本程序的路径下新建abc.txt文件,并保存爬取的数据
一个简易的Python爬虫,将爬取到的数据写入txt文档中的更多相关文章
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- python爬虫25 | 爬取下来的数据怎么保存? CSV 了解一下
大家好 我是小帅b 是一个练习时长两年半的练习生 喜欢 唱! 跳! rap! 篮球! 敲代码! 装逼! 不好意思 我又走错片场了 接下来的几篇文章 小帅b将告诉你 如何将你爬取到的数据保存下来 有文本 ...
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
随机推荐
- django 的时区设置
在Django的配置文件settings.py中,有两个配置参数是跟时间与时区有关的,分别是TIME_ZONE和USE_TZ 如果USE_TZ设置为True时,Django会使用系统默认设置的时区,即 ...
- Universal-Image-Loader源码解解析---display过程 + 获取bitmap过程
Universal-Image-Loader在github上的地址:https://github.com/nostra13/Android-Universal-Image-Loader 它的基本使用请 ...
- ASP.NET Core 借助 K8S 玩转容器编排
Production-Grade Container Orchestration - Automated container deployment, scaling, and management. ...
- 【效率神奇】Github丧心病狂的9个狠招
Github,一个被业内朋友成为「全球最大的同性交友社区」的平台. 小时候遇到不会的字可以查新华字典.后来写作文我们可以通过作文书.或者文摘去找合适的素材.同样,写代码可以去Github上找适合自己的 ...
- 【推荐】.NETCore 简单且高级的库 csredis v3.0.0
前言 .NETCore 从1.0发布历经坎坷,一开始各种库缺失到现在的部分完善,走到今天实属不易. 比如 redis-cli SDK 简直是坑出不穷. 过去 .net 最有名望的 ServiceSta ...
- JavaScript实现登录窗口的拖拽
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Java学习路线图分析
Java学习路线分析图 第一阶段 技术名称 技术内容 J2SE(java基础部分) java开发前奏 计算机基本原理,Java语言发展简史以及开发环境的搭建,体验Java程序的开发,环境变量的设置, ...
- 来聊一聊不low的Linux命令——find、grep、awk、sed
前几天面试,被一位面试官嫌弃了"你的Linux命令有点low".被嫌弃也挺正常的,因为我的简历写的我自己都有点看不下去:了解Linux常用命令,如ls,tail -f等命令,基本满 ...
- 如何给自己的app添加分享到有道云笔记这样的功能
文章同步自http://javaexception.com/archives/34 如何给自己的app添加分享到有道云笔记这样的功能 问题: 在之前的一个开源笔记类项目Leanote中,有个用户反馈想 ...
- Git - git branch - 查看远端所有分支
索引: 目录索引 一.示例: git branch -r 二.说明: 该命令将列出仓库中所有存在的远端分支,无论该分支是否已签出到本地. 蒙 2018-09-29 19:59 周六