centOS7下Spark安装配置
环境说明:
操作系统: centos7 64位 3台
centos7-1 192.168.190.130 master
centos7-2 192.168.190.129 slave1
centos7-3 192.168.190.131 slave2
安装spark需要同时安装如下内容:
jdk scale
1.安装jdk,配置jdk环境变量
这里不讲如何安装配置jdk,自行百度。
2.安装scala
下载scala安装包,https://www.scala-lang.org/download/选择符合要求的版本进行下载,使用客户端工具上传到服务器上。解压:
#tar -zxvf scala-2.13.0-M4.tgz
再次修改/etc/profile文件,添加如下内容:
export SCALA_HOME=$WORK_SPACE/scala-2.13.0-M4
export PATH=$PATH:$SCALA_HOME/bin
#source /etc/profile // 让其立即生效
#scala -version //查看scala是否安装完成
3.安装spark
spark下载地址:http://spark.apache.org/downloads.html
说明:有不同的版本包下载,选则你需要的下载安装即可
Source code: Spark 源码,需要编译才能使用,另外 Scala 2.11 需要使用源码编译才可使用
Pre-build with user-provided Hadoop: “Hadoop free” 版,可应用到任意 Hadoop 版本
Pre-build for Hadoop 2.7 and later: 基于 Hadoop 2.7 的预先编译版,需要与本机安装的 Hadoop 版本对应。可选的还有 Hadoop 2.6。我这里因为装的hadoop是3.1.0,所以直接安装for hadoop 2.7 and later的版本。
注:hadoop的安装请查看我的上一篇博客,不在重复描述。
#mkdir spark
#cd /usr/spark
#tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz
#vim /etc/profile
#添加spark的环境变量,加如PATH下、export出来
#source /etc/profile
#进入conf目录下,把spark-env.sh.template拷贝一份改名spark-env.sh
#cd /usr/spark/spark-2.3.1-bin-hadoop2.7/conf
#cp spark-env.sh.template spark-env.sh
#vim spark-env.sh
export SCALA_HOME=/usr/scala/scala-2.13.0-M4
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64
export HADOOP_HOME=/usr/hadoop/hadoop-3.1.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/spark/spark-2.3.1-bin-hadoop2.7
export SPARK_MASTER_IP=master
export SPARK_EXECUTOR_MEMORY=1G
#进入conf目录下,把slaves.template拷贝一份改名为slaves
#cd /usr/spark/spark-2.3.1-bin-hadoop2.7/conf
#cp slaves.template slaves
#vim slaves
#添加节点域名到slaves文件中
#master //该域名为centos7-1的域名
#slave1 //该域名为centos7-2的域名
#slave2 //该域名为centos7-3的域名启动spark
#启动spark之前先要把hadoop节点启动起来
#cd /usr/hadoop/hadoop-3.1.0/
#sbin/start-all.sh
#jps //检查启动的线程是否已经把hadoop启动起来了
#cd /usr/spark/spark-2.3.1-bin-hadoop2.7
#sbin/start-all.sh
备注:在slave1\slave2节点上也必须按照上面的方式安装spark,或者直接拷贝一份到slave1,slave2节点上
#scp -r /usr/spark root@slave1ip:/usr/spark
启动信息如下:starting org.apache.spark.deploy.master.Master, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
slave2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.com.cn.out
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.com.cn.out
master: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-master.out
测试Spark集群:
用浏览器打开master节点上的spark集群url:http://192.168.190.130:8080/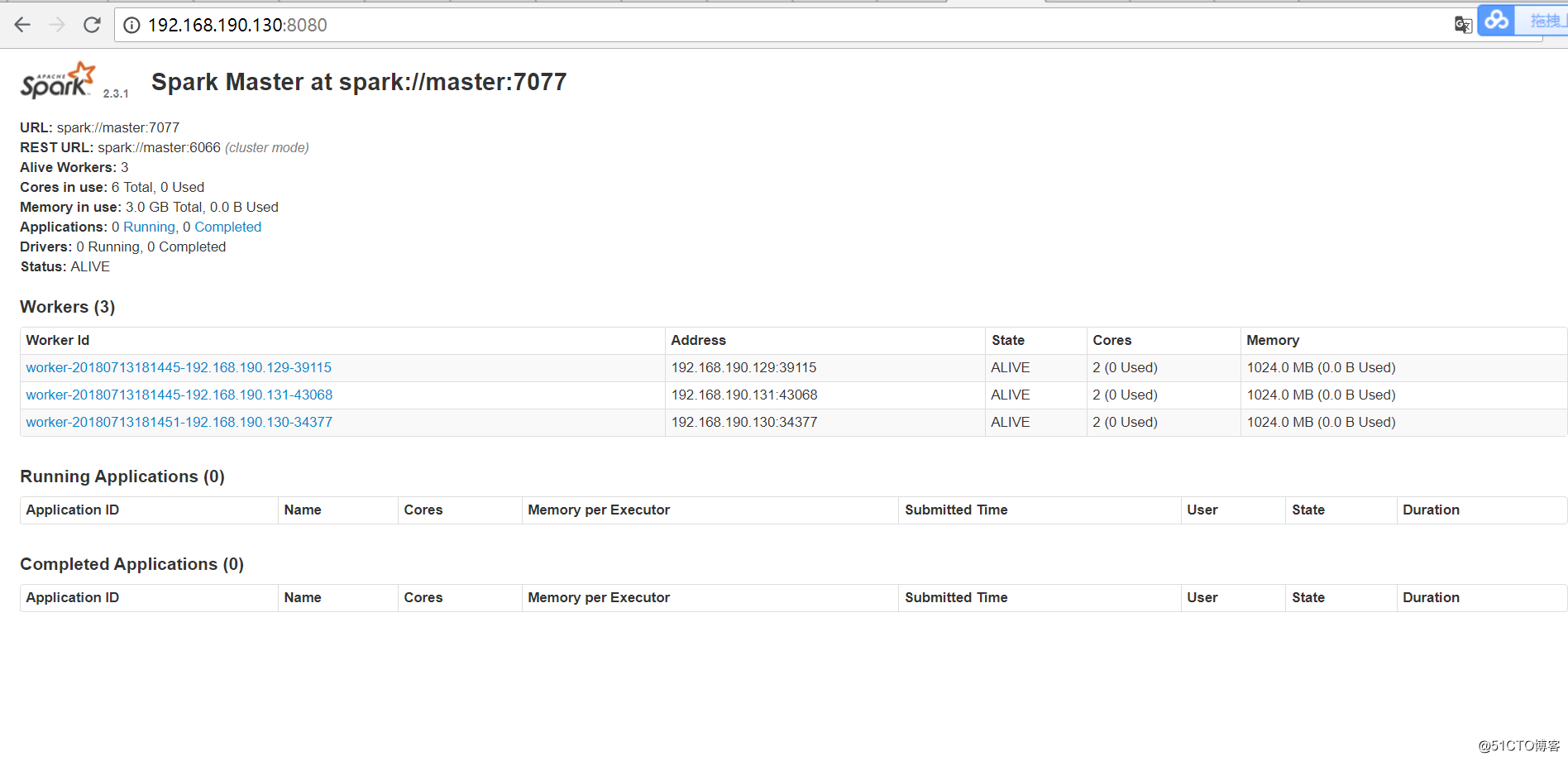
centOS7下Spark安装配置的更多相关文章
- ubuntu下spark安装配置
一.安装vmware虚拟机 二.在虚拟机上安装ubuntu12.04操作系统 三.安装jdk1.8.0_25 http://www.oracle.com/technetwork/java/javase ...
- centos7下elasticSearch安装配置
OS:Centos7x虚拟机 1H2Gjdk:1.8elasticsearch:5.6.0 1.下载“elasticsearch-5.6.0.tar.gz”解压到/usr/local/elastics ...
- Centos7下yum安装配置nginx与php
实现LNMP环境搭建. 开始安装Nginx和PHP-FPM之前,首先卸载系统中以前安装的Apache和PHP保证安装不会冲突.用root登录输入下面的命令: yum remve httpd* php* ...
- 在Centos7下源代码安装配置Nginx
1.安装前准备开发环境安装pcre开发包:yum install -y pcre-devel 安装编译源码所需的工具和库:yum install gcc gcc-c++ ncurses-devel p ...
- centos7下zookeeper安装配置
1.下载zookeeper文件 cd /opt/ wget http://mirrors.hust.edu.cn/apache/zookeeper/stable/zookeeper-3.4.9.tar ...
- centos7下编译安装php-7.0.15(PHP-FPM)
centos7下编译安装php-7.0.15(PHP-FPM) 一.下载php7源码包 http://php.net/downloads.php 如:php-7.0.15.tar.gz 二.安装所需依 ...
- Centos7下快速安装Mongo3.2
Centos7下快速安装Mongo3.2 一般安装Mongo推荐源码安装,有时候为了快部署测试环境,或者仅仅是想装个mongo shell,这时候yum安装是最合适的方式, 下面介绍一下如何在Cent ...
- 19.CentOS7下PostgreSQL安装过程
CentOS7下PostgreSQL安装过程 装包 sudo yum install postgresql-server postgresql-contrib 说明: 这种方式直接明了,其他方法也可以 ...
- centos7 下 yum 安装Nginx
centos7 下 yum 安装和配置 Nginx 添加yum源 Nginx不在默认的yum源中,可以使用epel或者官网的yum源,这里使用官网的yum源 rpm -ivh http://nginx ...
随机推荐
- HSTS 详解,让 HTTPS 更安全
随着互联网的快速发展,人们在生活中越来越离不开互联网.无论是社交.购物还是搜索,互联网都能给人带来很多的便捷.与此同时,由于用户对网络安全的不了解和一些网站.协议的安全漏洞,让很多用户的个人信息数据“ ...
- SpringBoot之旅第三篇-日志
一.前言 日志对于一个系统的重要性不言而喻,日志能帮我们快速定位线上问题,市场上存在非常多的日志框架,比较常见的有 JUL,JCL,Log4j,Log4j2,Logback.SLF4j.jboss-l ...
- java 轻量级同步volatile关键字简介与可见性有序性与synchronized区别 多线程中篇(十二)
概念 JMM规范解决了线程安全的问题,主要三个方面:原子性.可见性.有序性,借助于synchronized关键字体现,可以有效地保障线程安全(前提是你正确运用) 之前说过,这三个特性并不一定需要全部同 ...
- 折腾Java设计模式之解释器模式
解释器模式 解释器模式是类的行为模式.给定一个语言之后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器.客户端可以使用这个解释器来解释这个语言中的句子. 意图 给定一个语言,定义它的文法表 ...
- vue项目中vux的使用
vux VUX 是基于 WeUI 和 Vue.js 的 移动端 UI 组件库,提供丰富的组件满足移动端(微信)页面常用业务需求. 在vue-cli中使用步骤如下: 1.安装: npm i vux -S ...
- UiPath实践经验总结(一)
用UiPath做RPA也有一段时间了,初上阵不久,遇到过不少大大小小的坑.以下列出一些心得体会,望能抛砖引玉,与同行进行更多交流. 1. 日志策略:将UiPath Robot的Logging Leve ...
- Github排序(转载)
目录 1. 冒泡排序 2. 选择排序 3. 插入排序 4. 希尔排序 5. 归并排序 6. 快速排序 7. 堆排序 8. 计数排序 9. 桶排序 10. 基数排序 参考:https://mp.weix ...
- sqlserver的over开窗函数(与排名函数或聚合函数一起使用)
首先初始化表和数据 create table t_student( Id INT, Name varchar(), Score int, ClassId INT ); insert i ...
- Linux集群时间同步方法
方法1.ntp 平滑同步时间 (一)确认ntp的安装 1)确认是否已安装ntp [命令] rpm –qa | grep ntp 若只有ntpdate而未见ntp,则需删除原有ntpdate.如: n ...
- PHP中$GLOBALS和global的区别
很多人都认为$GLOBALS['var']和global $var只是写法上不同,其实并不是这样 根据官方的解释是 $GLOBALS['var']是外部全局变量$var的本身, 而global $v ...