初探kafka streams
1、启动zookeeper
zkServer.cmd
2、启动kafka
kafka-server-start.bat d:\soft\tool\Kafka\kafka_2.12-2.1.0\config\server.properties
3、创建一个用于存储输入数据的topic
kafka-console-producer.bat --broker-list localhost:9092 --topic streams-file-input < file-input.txt
为了方便演示,其中file-input.txt我是直接放到kafka的bin目录下
4、在idea中创建一个简单的项目,书写以下代码:
/**
* ymm56.com Inc.
* Copyright (c) 2013-2019 All Rights Reserved.
*/
package wikiedits; import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KStreamBuilder;
import org.apache.kafka.streams.kstream.KTable; import java.util.Arrays;
import java.util.Properties; /**
* @author LvHuiKang
* @version $Id: KafkaStreamTest.java, v 0.1 2019-03-26 19:45 LvHuiKang Exp $$
*/
public class KafkaStreamTest {
public static void main(String[] args) {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
Serde<String> sdeStr = Serdes.String();
Serde<Long> sdeLong = Serdes.Long();
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> inputLines = builder.stream(sdeStr, sdeStr, "streams-file-input");
KTable<String, Long> wordCounts = inputLines.flatMapValues(inputLine -> Arrays.asList(inputLine.toLowerCase().split("\\W+"))).groupBy((key, word) -> word).count("Counts");
wordCounts.to(sdeStr, sdeLong, "streams-wordcount-output");
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
System.out.println(); }
}
pom 依赖如下:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.</artifactId>
<version>0.11.0.0</version>
</dependency>
然后启动main方法,运行如下:
5、启动consumer:
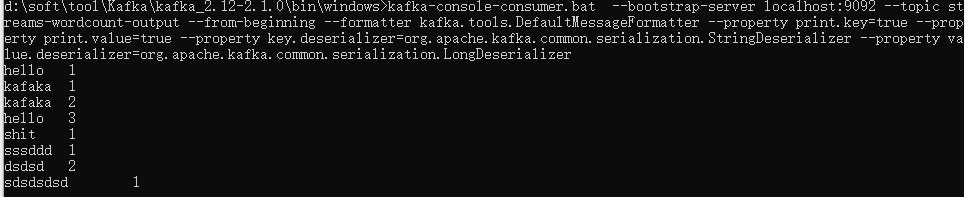
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic streams-wordcount-output --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
展示如下:
按Ctrl + C 退出。
以上就演示了kafka streams 的word-count示例
初探kafka streams的更多相关文章
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
来自 Confluent 的 Confluent Platform 3.0 消息系统支持使用 Kafka Streams 实现实时的数据处理,这家公司也是在背后支撑 Apache Kafka 消息框架 ...
- [翻译]Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- Kafka Streams 剖析
1.概述 Kafka Streams 是一个用来处理流式数据的库,属于Java类库,它并不是一个流处理框架,和Storm,Spark Streaming这类流处理框架是明显不一样的.那这样一个库是做什 ...
- 浅谈kafka streams
随着数据时代的到来,数据的实时计算也越来越被大家重视.实时计算的一个重要方向就是实时流计算,目前关于流计算的有很多成熟的技术实现方案,比如Storm.Spark Streaming.flink等.我今 ...
- Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- 手把手教你写Kafka Streams程序
本文从以下四个方面手把手教你写Kafka Streams程序: 一. 设置Maven项目 二. 编写第一个Streams应用程序:Pipe 三. 编写第二个Streams应用程序:Line Split ...
- Kafka Streams演示程序
本文从以下六个方面详细介绍Kafka Streams的演示程序: Step 1: 下载代码 Step 2: 启动kafka服务 Step 3: 准备输入topic并启动Kafka生产者 Step 4: ...
- 大全Kafka Streams
本文将从以下三个方面全面介绍Kafka Streams 一. Kafka Streams 概念 二. Kafka Streams 使用 三. Kafka Streams WordCount 一. ...
- 简介Kafka Streams
本文从以下几个方面介绍Kafka Streams: 一. Kafka Streams 背景 二. Kafka Streams 架构 三. Kafka Streams 并行模型 四. Kafka Str ...
随机推荐
- 编译安装Keepalived2.0.0
简介 Keepalived是基于vrrp协议的一款高可用软件.Keepailived有一台主服务器和多台备份服务器,在主服务器和备份服务器上面部署相同的服务配置,使用一个虚拟IP地址对外提供服务,当主 ...
- vue-cli项目使用mock数据的方法(借助express)
前言 现如今前后端分离开发越来越普遍,前端人员写好页面后可以自己模拟一些数据进行代码测试,这样就不必等后端接口,提高了我们开发效率.今天就来分析下前端常用的mock数据的方式是如何实现的. 主体 项目 ...
- .NET CORE 中使用AutoMapper进行对象映射
简介 AutoMapper uses a fluent configuration API to define an object-object mapping strategy. AutoMappe ...
- Jmeter API Performance Test
笔者最近了解 Apache组织开发了基于Java的压力测试工具Apache JMeter.如有兴趣可自行搜索它的相关信息.笔者记录了一些使用方法,如有错误或遗漏,欢迎联系改正. 官方下载地址:http ...
- 第四章:shiro的INI配置
4.1 根对象SecurityManager 从之前的Shiro架构图可以看出,Shiro是从根对象SecurityManager进行身份验证和授权的:也就是所有操作都是自它开始的,这个对象是线程安全 ...
- 剑指前端(前端入门笔记系列)—— JS基本数据类型及其类型转换
基本数据类型 ECMAScript中有5中简单数据类型性(也称为基本数据类型):Undefined.Null.Boolean.Number和String,还有一种复杂数据类型——Object,Obje ...
- Android防止按钮快速重复点击
在用户使用 Android 应用的时候,经常会出现过快且多次点击同一按钮的情况,一方面这是因为应用或手机当前有些卡顿,另一方面也可能是由于很多应用并没有设置按钮点击时的 selector 或者其它按钮 ...
- android使用百度地图最新sdk5.0后后代码混淆时,地图无法显示闪退问题
描述:刚开始遇到这个问题我一步一步去排除,最后发现在初始化地图的时候,代码混淆就有问题了, 问题描述:当跳显示地图的页面APP闪退, 解决对比: 1:对于老版本百度sdk:代码混淆时语句: -libr ...
- QT连接postgreSQL
这是我之前项目遇到的问题,连接postgreSQL数据库,一直找不到引擎,最后终于找到 原因了,需要程序加载 1.安装postgresql客户端,2.需要配置postgresql客户端的bin和lib ...
- gitbook 入门教程之主题插件
主题插件 目前 gitbook 提供三类文档: Book 文档,API 文档和 FAQ 文档. 其中,默认的也是最常使用的就是 Book 文档,如果想要了解其他两种文档模式,需要引入相应的主题插件. ...