Boosting(提升方法)之GBDT
一、GBDT的通俗理解
提升方法采用的是加法模型和前向分步算法来解决分类和回归问题,而以决策树作为基函数的提升方法称为提升树(boosting tree)。GBDT(Gradient Boosting Decision Tree)就是提升树算法的一种,它使用的基学习器是CART(分类和回归树),且是CART中的回归树。
GBDT是一种迭代的决策树算法,通过多轮迭代,每轮学习都在上一轮训练的残差(用损失函数的负梯度来替代)基础上进行训练。在回归问题中,每轮迭代产生一棵CART回归树,迭代结束时将得到多棵CART回归树,然后把所有的树加总起来就得到了最终的提升树。下面是一个简单的示意图。
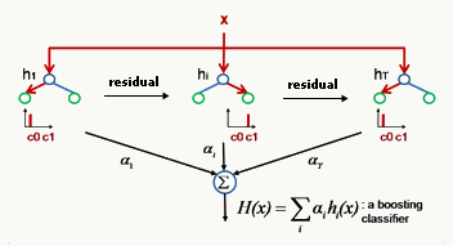
看到这个阐述还是很懵对不对?对于初次接触的人,应该是这种感觉。没关系,我们一步一步来分析这个阐述中所涉及到的关键词。
要理解GBDT,那么需要理解两个主要的概念:回归树(DT, 即Regression Decision Tree)和梯度提升(GB, 即Gradient Boosting)。
1、理解回归树
GBDT中的树都是CART回归树,不是分类树,因为GBDT的核心在于累加所有树的结果作为最终结果,而只有回归树的结果可以累加,分类树的结果进行累加是没有意义的。尽管GBDT调整后也可以用于分类,但这不代表GBDT中用到的决策树是分类树。
由于GBDT的学习过程是通过多轮迭代,每次都在上一轮训练结果的残差的基础上进行学习,于是要求基学习器要足够简单,具有高偏差、低方差的特点。GBDT的基学习器是CART回归树,由于高偏差和简单的要求,每棵CART回归树的深度不会很深。
训练的过程就是通过降低偏差来不断提高最终的提升树进行分类和回归的精度,使整体趋近于低偏差、低方差。最终的提升树就是将每轮训练得到的CART回归树加总求和得到(也就是加法模型)。
2、理解梯度提升
在理解GBDT中的梯度提升之前,首先要明白,提升树的每次迭代,就是用一棵决策树去拟合上一轮训练的残差,而之前所有树的预测值的累加值,加上这个残差就等于真实值。比如A的真实年龄是18岁,第一棵树预测的年龄是12岁,那么残差是6岁,6岁作为第二棵树学习的目标。如果第二棵树的预测年龄是5岁,那么残差等于真实年龄减去这两棵树的预测值之和(18-12-5),即为1。于是第三棵树中A的年龄变成了1岁,继续去学习,越来越逼近18岁这个目标。如果恰巧在第m棵树时,残差为0,那么累加这m棵树预测的年龄,就和真实的年龄完全相等了。
但是有个问题是损失函数各种各样,对各种损失函数的残差进行拟合并不容易,怎么找到一种通用的拟合方法呢?
于是在GBDT中,就使用损失函数的负梯度作为提升树算法中残差的近似值,然后每次迭代时,都去拟合损失函数在当前模型下的负梯度。这就找到了一种通用的拟合方法。
二、GBDT的推导过程
(一)提升树算法
开头介绍了,提升方法采用的是加法模型和前向分布算法来解决分类和回归问题,而以决策树作为基函数的提升方法称为提升树(boosting tree)。
那么提升树算法的大致情况是:
(1)模型为决策树的加法模型
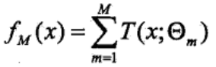
其中T(x; θm)表示决策树,θm为决策树的参数,M为树的个数。
(2)算法为前向分步算法
首先确定初始提升树f0(x)=0,经过迭代得到第m步的模型为:
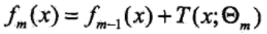
其中fm-1(x)为当前模型,而θm则通过经验风险极小化来确定,从而得到fm(x),即最小化损失函数:
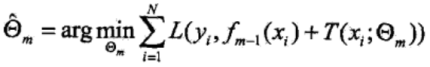
(3)由前向分步算法得到M棵决策树T(x; θm)后,再进行加总,就得到了提升树模型fM(x)。
分类问题中决策树是二叉分类树,回归问题中决策树是二叉回归树。在不同的问题中,损失函数的形式不同,分类问题一般选择指数损失函数,回归问题则选择平方误差损失函数。
(二)GBDT推导
在提升方法中,我之前学习了AdaBoost算法,这里又来了提升树和GBDT,让人有点头疼。那么这三者的大致关系是什么样的呢?
在二类分类问题中,如果提升树算法选择二类分类树,并且损失函数选择指数损失函数,那么这个提升树算法就是AdaBoost算法的一个特例。GBDT尽管必须使用回归树来构建,但是它也可以用于分类问题;GBDT在解决分类问题时有两种办法,一个是选择指数损失函数作为损失函数,此时GBDT退化为AdaBoost算法,另一个是选择类似于逻辑回归的对数似然损失函数。
此外,GBDT就是提升树的一种,可以用于回归问题,它使用的基学习器是CART(分类和回归树),且是CART中的回归树,损失函数一般选择平方误差损失函数。它的特点在于gradient,也就是用损失函数的负梯度作为提升树算法的残差的近似值去拟合回归树,让损失函数沿着梯度方向下降。
于是理解GBDT要分为两步,第一步是理解什么叫做用决策树去拟合当前模型的残差,第二步是理解为什么以及如何用损失函数的负梯度去替代当前模型的残差。
1、回归问题的提升树算法
步骤一:已知训练数据集T={(x1, y1),(x2, y2),..., (xN,yN)}, xi∈χ∈Rn,yi∈γ∈R,损失函数选择平方误差损失函数。确定初始提升树f0(x)=0。
步骤二:对于m=1, 2, ..., M,采用加法模型和前向分步算法,循环地进行下面的计算:
(1)将输入空间X划分为J个互不相交的区域R1, R2, ..., Rj,并且在每个区域上确定输出的常量cj,那么决策树可以表示为:
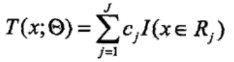
其中,参数Θ={(R1,c1),(R2,c2),...,(RJ,cJ)}表示树的区域划分和每个区域上的输出值。J表示回归树的叶节点的个数。
(2)当前模型为fm-1(x),预设fm(x)=fm-1(x)+T(x;Θm),由经验风险最小化来求解fm(x)中的参数Θm,即求解:
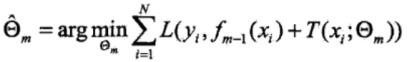
由于损失函数具体选择的是平方误差损失函数,所以损失函数为:
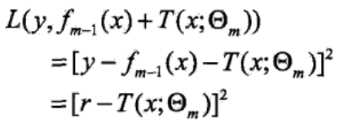
而当前模型拟合数据的残差(residual)为:r = y - fm-1(x),所以实际上,就是用一个决策树去拟合当前模型的残差r,得到参数Θm和决策树T(x;Θm)。
(3)更新提升树fm(x)=fm-1(x)+T(x;Θm)。
步骤三:得到M个决策树后,根据加法模型,得到回归问题的提升树:
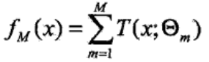
2、GBDT回归算法的负梯度拟合
上面得到了回归问题的提升树算法,为什么还要提出个GBDT算法?原因在于回归问题的提升树算法采用加法模型和前向分步算法来进行优化求解,但每一步优化过程其实并不容易求解。当损失函数取平方误差损失函数和指数损失函数时,每一步的优化还算简单,可是如果损失函数是其他一般损失函数时,那可就难了。而回想逻辑回归中的求解过程,是用梯度下降法来简化了优化过程,因此有学者(Friedman)就想到了用梯度提升(gradient boosting)的方法来近似求解提升树的优化问题,这样就找到了一个通用的解决办法,适用于各种不同类型损失函数的情形。这就是为什么提出了GBDT的原因。
而GBDT这个算法中最关键的一点就是用损失函数在当前模型中的负梯度值,即:
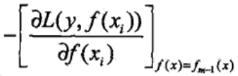
作为回归问题提升树算法中残差的近似值,再用一棵CART回归树去拟合这个负梯度值,从而得到下一棵CART回归树。
所以GBDT回归算法的求解过程如下:
步骤一:已知训练数据集T={(x1, y1),(x2, y2),..., (xN,yN)}, xi∈χ∈Rn,yi∈γ∈R。初始化提升树:

c是第一个决策树的输出值。
步骤二:对于m=1,2,..., M,循环对以下过程进行计算:
(1)对于i=1, 2, ..., N,计算提升树fm-1(x)的负梯度:
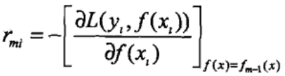
(2)对负梯度rmi拟合一棵CART树,得到第m棵树的叶结点区域Rmj,j=1,2,..., J。
(3)对于j=1, 2, ..., J,使损失函数最小,计算每个区域Rmj上的最优输出值:
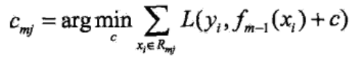
从而得到本轮拟合的决策树:
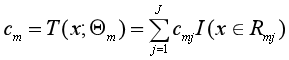
(4)更新提升树fm(x),然后回到(1)继续求负梯度。

步骤三:求得M棵CART回归树后,加总得到最终的回归树

从回归树的提升树算法过渡到GBDT算法,理解起来就不那么难受了。GBDT通过损失函数的负梯度来拟合CART回归树,这是一种通用的近似替代残差来拟合决策树的方法,不管损失函数取什么类型,都可以用这种方法。
3、GBDT的特征选择
GBDT的基学习器选择的是CART回归树,所以GBDT的特征选择过程其实就是CART回归树的特征选择问题。
CART回归树是一棵二叉树,它在训练数据集所在的输入空间中,选择最优切分变量和切分点,递归地将每个区域划分为两个子区域,并决定每个子区域上的输出值。假设训练数据集中的实例有J个特征,于是首先要选择一个最优的特征j,作为二叉树的第一个节点。再对特征j的值选择一个最优的切分点s,将输入空间划分为两个子区域。具体是通过求解以下的公式来得到最优的特征j和切分点s:

过程据说比较粗暴,就是先遍历训练样本的所有特征,找到最优特征j后,固定特征j,扫描所有可能的切分点,找到最优的切分点s。
而找到了最优的特征j和切分点s后,对于特征值小于s的样本,归为第一类,特征值大于s的样本,归为第二类,就可以把输入空间划分为两个区域:

就构建了二叉树的两个子节点。
三、GBDT用于分类
经过以上对回归问题中GBDT算法的推导,GBDT这个神奇的模型在我脑中的轮廓渐渐清晰,褪去了原有的神秘感。可是我要继续探索,学习GBDT如何应用于分类问题,毕竟分类问题实在太常见了。
GBDT的分类算法从思想上和GBDT的回归算法没有区别,但是由于样本的输出不是连续的值,而是离散的类别,一般用{-1, 0, 1, ...}这样的整数表示,导致我们无法直接用样本的输出去计算残差。
回想一下线性回归和逻辑回归,线性回归是一种回归算法,而逻辑回归却是一种分类算法。逻辑回归用于分类的关键就在于逻辑回归采用了sigmoid函数,得到了类别的预测概率分布,同时采用了对数似然损失函数。于是借鉴这种做法,在GBDT分类算法中,采用对数似然损失函数来计算残差,并用对数似然损失函数的负梯度作为残差的近似替代,然后用决策树去拟合残差。
1、二分类GBDT算法
在Friedman的论文中,他采用负二项对数似然损失函数(negative binomial log-likelihood)作为GBDT的损失函数:
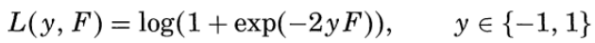

他这个损失函数其实和逻辑回归的损失函数是等价的,作者省略了一些步骤,推导过程附在本文的末尾。
步骤一:对F(x)进行初始化
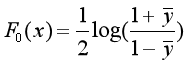
步骤二:对于m=1,2,..., M,循环进行以下的计算:
(1)求对数似然损失函数的负梯度:
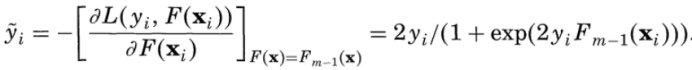
(2)对于第m棵树的叶结点区域Rmj,j=1,2,..., J,使对数损失最小化,计算每个区域Rmj上的J个最优输出值:
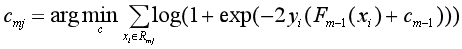
由于上面这个公式很难求,所以就用已经算出来的负梯度和牛顿-拉弗森迭代法(Newton–Raphson )来近似求解:
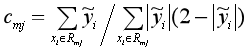
从而得到本轮拟合的决策树:
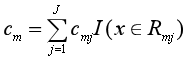
(3)更新Fm(x),然后回到(1)中求负梯度。
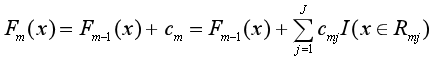
步骤三:求得M棵CART回归树后,加总得到最终的回归树
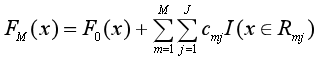
算法的流程整理得简洁一些就是:
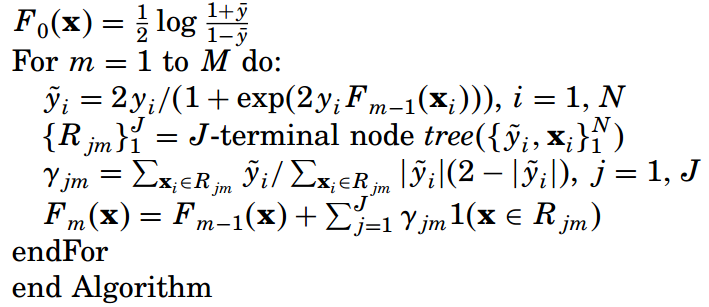
求出了用于分类的GBDT回归树后,尽可以计算实例属于两个类别中每一类的概率:

进而进行分类。
2、多分类GBDT算法
在二元分类GBDT中,我们用逻辑回归来进行类比,而在多元分类GBDT中,就用softmax回归来进行类比。Friedman选择多元对数似然损失函数作为损失函数:
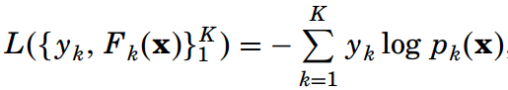
这里类别yk=1(类别=k)相当于一个指示函数,取值1或0,表示当类别为k时,yk=1。而Pk(x)=P(yk=1|x),表示类别为k的概率,用softmax来进行计算:

与二元分类的GBDT类似,由上面两个公式,根据链式法则和softmax的简便求导公式【(Pk(x))'=Pk(x)(1-Pk(x)),不过求出来还是不太一样】,我们求出第m轮迭代中第i个样本对应类别k的负梯度:
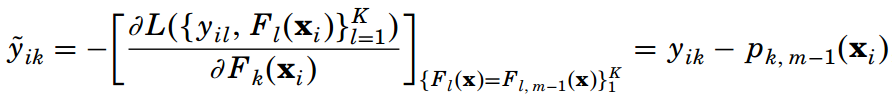
负梯度的表达式清晰地表明了这是样本i对应类别k的真实概率yik和第m轮的概率预测值Pk,m-1(xi)的差值,即为训练的误差。
接下来在每一轮迭代中,都用K棵决策树来拟合K个类别的训练误差。每棵决策树都有J个叶节点,或者说划分为了J个子区域 {Rjkm}Jj=1。然后求每棵树在每个子区域上的最优输出值:
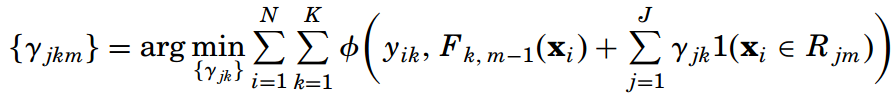
这里的函数Φ(yk, Fk) = -yklog(pk)。
同样使用牛顿-拉弗森迭代法来简化求解,得到最优输出值的近似值:
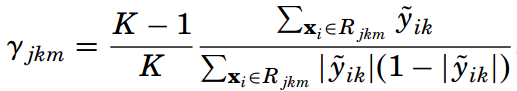
再通过下面的公式来更新K棵提升树,然后继续求负梯度,进行下一轮迭代:

把上面求负梯度、计算每棵树的最优输出值、更新提升树的过程重复M次,最终得到K棵提升树FkM(x):
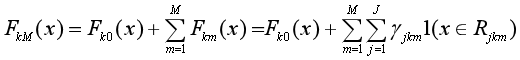
求出了K棵用于多元分类的提升树FkM(x)后,对于每一个样本x,都可以计算它属于K个类别的概率分布,从而确定它所属的类别。

多分类GBDT算法的流程整理如下:
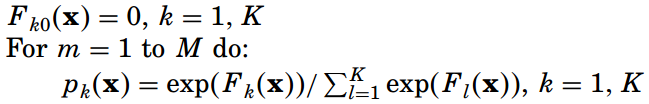
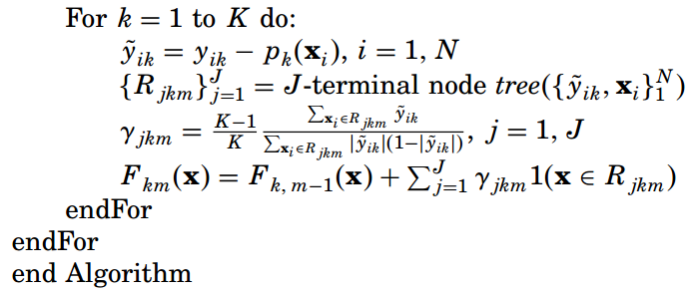
四、两个小问题
看其他人的博客上分析了下面两个问题,我感觉对于更深入地理解GBDT有一定帮助,所以摘录在这里。
第一个问题,为什么GBDT要把CART回归树树分成m棵二叉树去求(每棵树只有两个叶子节点),而不是求一棵二叉树,这棵树有m+1(最多有2m个叶子节点)层呢?这是为了解决过拟合问题,因为在决策树的剪枝算法中我们知道,只要允许一棵树的叶子节点足够多,那么训练数据集总是能训练到100%的准确率,但是模型的复杂度非常高,在测试数据上表现比较差。而GBDT把一棵树拆成m棵树,限制每棵树只有两个叶子节点,就可以解决过拟合问题。前面也说了,基学习器要具有简单、高偏差和低方差的特点,因此每棵CART回归树的深度不会很深。
第二个问题是,为什么第m次学习的目标,是前m-1棵树预测值的累加和的残差?可以这样理解,一方面通过分步求解,一步步逼近目标值,比一步到位要简单;另一方面每一步的残差计算其实变相地增大了被分错的实例的权重,因为被分错的实例其残差较大,而已经分对的实例的残差趋近于0。这样后面的树就能越来越专注于前面被分错的实例了。
附:负二项对数似然损失函数的推导
考虑一个二项逻辑回归模型,模型由条件概率分布P(Y|X)表示,随机变量X取值为实数,而随机变量Y取值为1或-1(注意一般逻辑回归的Y取值为1或0)。
则二项逻辑回归模型是如下的条件概率分布(参考《统计学习方法》第六章):
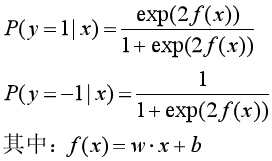
把条件概率分布统一为一个函数F(x):
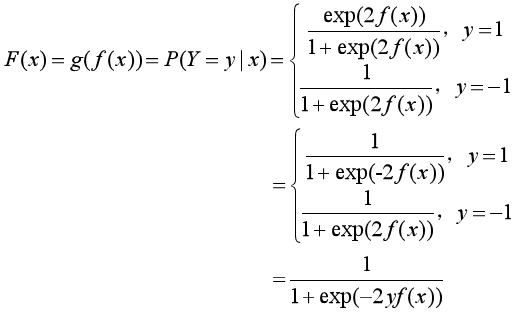
对数损失函数的标准形式为:
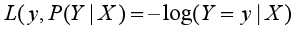
于是把F(x)的表达式代入对数损失函数中,得到:

再把f(x)用概率的形式表示:
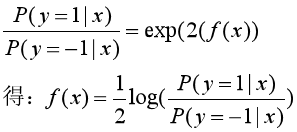
参考资料:
1、李航:《统计学习方法》
2、Friedman J H . Greedy Function:《Approximation: A Gradient Boosting Machine》
我的分享:https://pan.baidu.com/s/1JBAA6qk6aPZIDUqkVlLYVg 提取码:eyt4
2、https://www.cnblogs.com/peizhe123/p/5086128.html
3、https://www.cnblogs.com/ModifyRong/p/7744987.html
4、https://www.zybuluo.com/vivounicorn/note/446479#24-bagging-and-boosting框架
5、https://www.cnblogs.com/pinard/p/6140514.html
Boosting(提升方法)之GBDT的更多相关文章
- Boosting(提升方法)之AdaBoost
集成学习(ensemble learning)通过构建并结合多个个体学习器来完成学习任务,也被称为基于委员会的学习. 集成学习构建多个个体学习器时分两种情况:一种情况是所有的个体学习器都是同一种类型的 ...
- Boosting(提升方法)之XGBoost
XGBoost是一个机器学习味道非常浓厚的模型,在数学上非常规范,运用正则化.L2范数.二阶梯度.泰勒公式和分布式计算方法,对GBDT等提升树模型进行优化,不仅能处理更大规模的数据,而且运行效率特别高 ...
- 提升方法(boosting)详解
提升方法(boosting)详解 提升方法(boosting)是一种常用的统计学习方法,应用广泛且有效.在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性 ...
- 前向分步算法 && AdaBoost算法 && 提升树(GBDT)算法 && XGBoost算法
1. 提升方法 提升(boosting)方法是一种常用的统计学方法,在分类问题中,它通过逐轮不断改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能 0x1: 提升方法的基本 ...
- 机器学习相关知识整理系列之三:Boosting算法原理,GBDT&XGBoost
1. Boosting算法基本思路 提升方法思路:对于一个复杂的问题,将多个专家的判断进行适当的综合所得出的判断,要比任何一个专家单独判断好.每一步产生一个弱预测模型(如决策树),并加权累加到总模型中 ...
- 组合方法(ensemble method) 与adaboost提升方法
组合方法: 我们分类中用到非常多经典分类算法如:SVM.logistic 等,我们非常自然的想到一个方法.我们是否可以整合多个算法优势到解决某一个特定分类问题中去,答案是肯定的! 通过聚合多个分类器的 ...
- js 变量提升+方法提升
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- 机器学习理论提升方法AdaBoost算法第一卷
AdaBoost算法内容来自<统计学习与方法>李航,<机器学习>周志华,以及<机器学习实战>Peter HarringTon,相互学习,不足之处请大家多多指教! 提 ...
- 统计学习方法c++实现之七 提升方法--AdaBoost
提升方法--AdaBoost 前言 AdaBoost是最经典的提升方法,所谓的提升方法就是一系列弱分类器(分类效果只比随机预测好一点)经过组合提升最后的预测效果.而AdaBoost提升方法是在每次训练 ...
随机推荐
- Bootstrap 4,“未捕获错误:Bootstrap工具提示需要Tether(http://github.hubspot.com/tether/)”
如果出现了这个错误,我想你是没有引用tether文件,这在v4之前不需要单独引入的. https://cdnjs.cloudflare.com/ajax/libs/tether/1.4.0/js/te ...
- Ocelot中文文档-日志
目前,Ocelot使用标准的日志记录接口ILoggerFactory/ILogger . 在IOcelotLogger / IOcelotLoggerFactory中提供了标准的asp.net cor ...
- java文件传输之文件编码和File类的使用
---恢复内容开始--- 我们知道,在用户端和服务端之间存在一个数据传输的问题,例如下载个电影.上传个照片.发一条讯息.在这里我们 就说一下文件的传输. 1.文件编码 相信大家小时候玩过积木(没玩过也 ...
- Java的精确整数计算-Bigdecimal学习总结和工具类
随笔:随着最近工作需要,回首需要涉及到一些精确的数据计算,就需要用到Bigdecimal,索性就趁着闲暇之余整理收集一下关于Bigdecimal的使用方法,由于时间的原因,整理的并不是特别详细,但相信 ...
- Http 状态码(status code)常用总结
本来计划写一篇浏览器错误码使用的详细总结,近来想了想,第一这不是很深入的知识点.主要还是一种规定:第二对常用的几种的一个使用场景已经有所了解了,所以今天就写一个简单的汇总,并黏贴常用几个错误码的介绍在 ...
- LinkedList源码
1.介绍及注意事项 链表由Josh Bloch书写,属于Java集合框架中的一种,LinkedList实现的是双链表,实现了所有的链表操作,可能够实现所有元素(包括)的基本操作. 链表是非线程同步的, ...
- vim编辑器常见命令归纳大全
Esc:命令行模式 i:插入命令 a:附加命令 o:打开命令 c:修改命令 r:取代命令 s:替换命令 以上进入文本输入模式 : 进入末行模式 末行模式: w:保存 q:退出,没保存则无法退出 w ...
- 设计一个卖不同种类车的4s店
# 定义奔驰车类 class BenchiCar(object): # 定义车的方法 def move(self): print('---奔驰车在移动---') def stop(self): pri ...
- spring事务机制
一.Java动态代理 1.定义 Java动态代理是利用反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理. 默认情况下会采用JDK的动态代理实现AOP . 2. ...
- Java 使用BigDecimal类处理高精度计算
Java在java.math包中提供的API类BigDecimal,用来对超过16位有效位的数进行精确的运算.双精度浮点型变量double可以处理16位有效数,但在实际应用中,可能需要对更大或者更小的 ...