分析 ajax 请求并抓取今日头条街拍美图
首先分析街拍图集的网页请求头部:
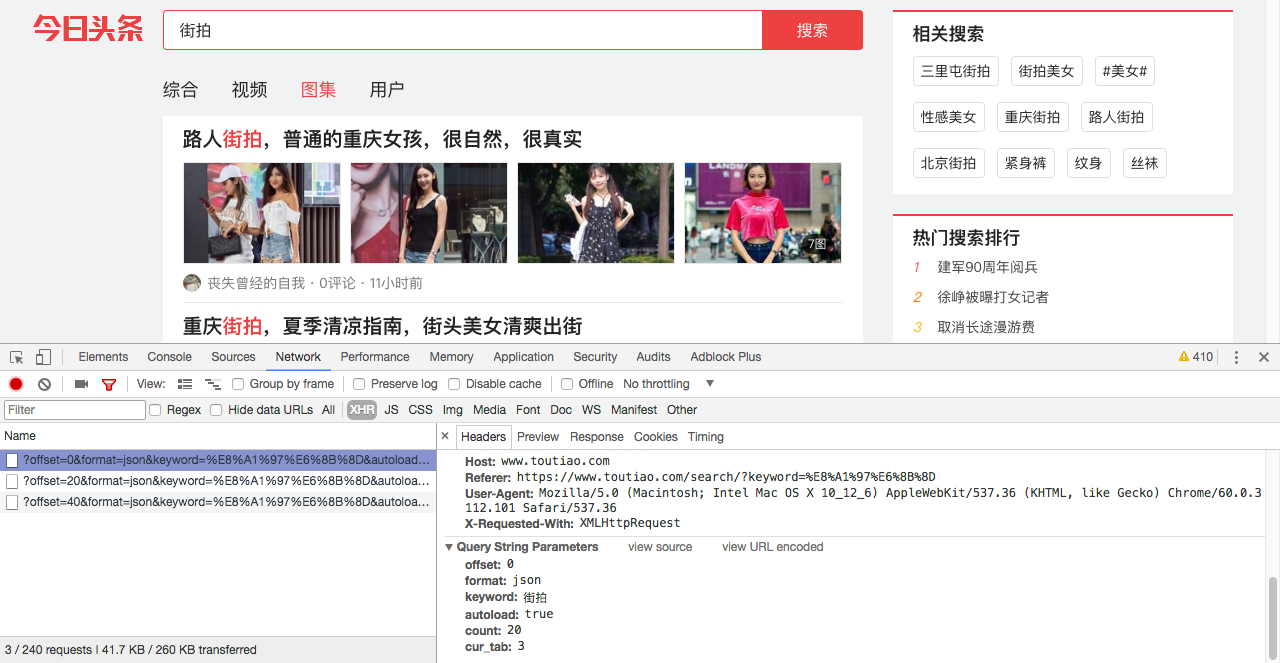
在 preview 选项卡我们可以找到 json 文件,分析 data 选项,找到我们要找到的图集地址 article_url:
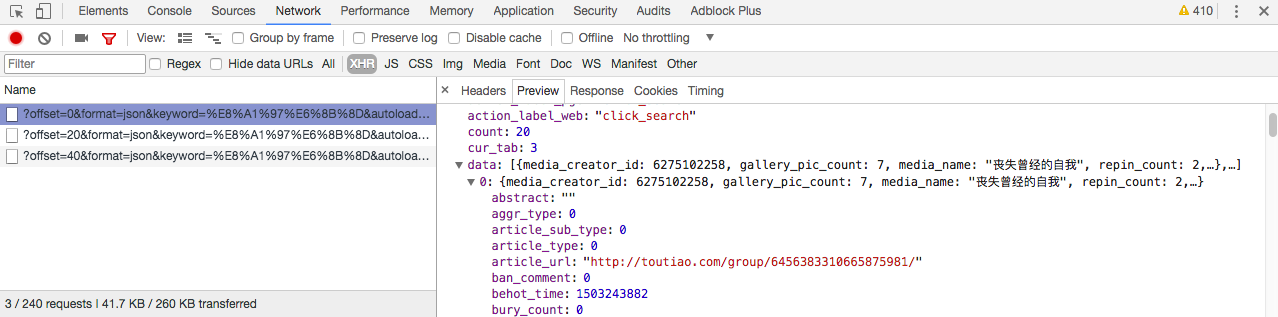
选中其中一张图片,分析 json 请求,可以找到图片地址在 gallery 一栏:
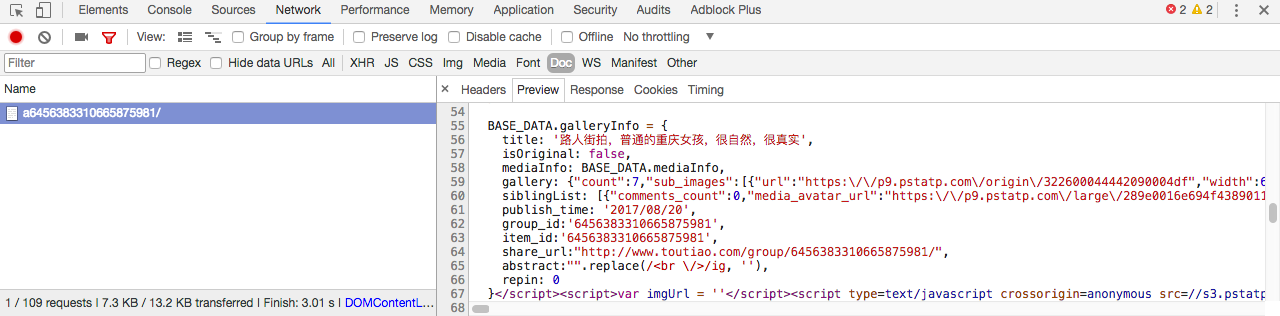
找到图片地址,接下来我们就可以来写代码了:
1.导入必要的库:
import requests
import json
import re
import pymongo
import os
from hashlib import md5
from multiprocessing import Pool
from json.decoder import JSONDecodeError
from requests.exceptions import RequestException
from urllib.parse import urlencode
from bs4 import BeautifulSoup
2.获取索引页并分析:
def get_page_index(offset, keyword):
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 3
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print(' 请求索引页出错')
return None def parse_page_index(text):
try:
data = json.loads(text)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
3.获取详情页并分析:
def get_page_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print(' 请求详情页出错')
return None def parse_page_detail(html, url):
soup = BeautifulSoup(html, 'lxml')
title = soup.select('title')[0].get_text()
images_pattern = re.compile('gallery: (.*?),\n', re.S)
result = re.search(images_pattern, html)
if result:
data = json.loads(result.group(1))
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images:
download_images(image)
return {
'title': title,
'url': url,
'images': images
}
4.使用 MongoDB 数据库存储数据:
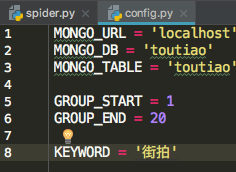
首先定义一个 config.py 文件,配置默认参数:
写入 MongoDB:
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print(' 存储到 MongoDB 成功', result)
return True
5.存储图片到本地:
def download_images(url):
print(' 正在下载', url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print(' 请求图片出错')
return None def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
6.最后定义 main()函数,并开启多线程抓取20页图集:
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close() def main(offset):
text = get_page_index(offset, KEYWORD)
for url in parse_page_index(text):
html = get_page_detail(url)
if html:
result = parse_page_detail(html, url)
if result:
save_to_mongo(result) if __name__ == '__main__':
groups = [x * 20 for x in range(GROUP_START, GROUP_END + 1)]
pool = Pool()
pool.map(main, groups)
代码GitHub地址:https://github.com/weixuqin/PythonProjects/tree/master/jiepai
分析 ajax 请求并抓取今日头条街拍美图的更多相关文章
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 2.分析Ajax请求并抓取今日头条街拍美图
import requests from urllib.parse import urlencode # 引入异常类 from requests.exceptions import RequestEx ...
- python爬虫知识点总结(十)分析Ajax请求并抓取今日头条街拍美图
一.流程框架
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- Python爬虫系列-分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. 2.抓取详情页内容 解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 3.下载图片与保存数据库 将 ...
- 【Python爬虫案例学习】分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. from urllib.parse import urlencode from requests.excep ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 爬虫(八):分析Ajax请求抓取今日头条街拍美图
(1):分析网页 分析ajax的请求网址,和需要的参数.通过不断向下拉动滚动条,发现请求的参数中offset一直在变化,所以每次请求通过offset来控制新的ajax请求. (2)上代码 a.通过aj ...
随机推荐
- Spring中配置数据源常用的形式
不管采用何种持久化技术,都需要定义数据源.Spring中提供了4种不同形式的数据源配置方式: spring自带的数据源(DriverManagerDataSource),DBCP数据源,C3P0数据源 ...
- OSM数据下载地址
1.OSM数据下载地址 官网下载: http://planet.openstreetmap.org/ GeoFabrik:http://www.geofabrik.de/ Metro Extracts ...
- (译文)开始学习Vue.js特性--Scoped Slots
什么是scoped slots A scoped slot is a special type of slot that functions as a reusable template (that ...
- 20162320刘先润第三周Bag类测试
前言 以下内容是本周Bag代码的课后作业,要求是完成伪代码.产品代码和测试代码,为了书写方便我将伪代码以注释的形式写在了产品代码的后面 测试步骤 1.首先对Bag类引用BagInterface的代码进 ...
- 百词斩APP分析
一.调研 1.第一次上手 第一次使用,可以使用微信和qq登录感觉挺不错的不然又要注册有点麻烦,在功能上,用户可以针对自身选择不同水平的英语背单词,然后有多钟方式对自己的听力和单词翻译进行提升.在u ...
- const volatile同时限定一个类型int a = 10
const和volatile放在一起的意义在于: (1)本程序段中不能对a作修改,任何修改都是非法的,或者至少是粗心,编译器应该报错,防止这种粗心: (2)另一个程序段则完全有可能修改,因此编译器最好 ...
- 5种做法实现table表格中的斜线表头效果
table表格,这个东西大家肯定都不陌生,代码中我们时常都能碰到,那么给table加一个斜线的表头有时是很有必要的,但是到底该怎么实现这种效果呢? 我总结了以下几种方法: 1.最最最简单的做法 直接去 ...
- Linux的安装和使用技巧
LinuxCentOs开始设置一个普通的用户,如果想进入root用户,可以su然后设置密码,然后第二次再次输入su,然后输入相同的密码就可以进去了 有很多命令需要在root下才能执行,但是在创建时却是 ...
- 鼠标滑过切换div显示(鼠标事件)
<html> <head> <meta http-equiv="Content-Type" content="text/html; char ...
- 第四章 JavaScript操作DOM对象
第四章 JavaScript操作DOM对象 一.DOM操作 DOM是Document Object Model的缩写,即文档对象模型,是基于文档编程的一套API接口,1988年,W3C发布了第一级 ...