第三篇:爬虫框架 - Scrapy
前言
Python提供了一个比较实用的爬虫框架 - Scrapy。在这个框架下只要定制好指定的几个模块,就能实现一个爬虫。
本文将讲解Scrapy框架的基本体系结构,以及使用这个框架定制爬虫的具体步骤。
Scrapy体系结构
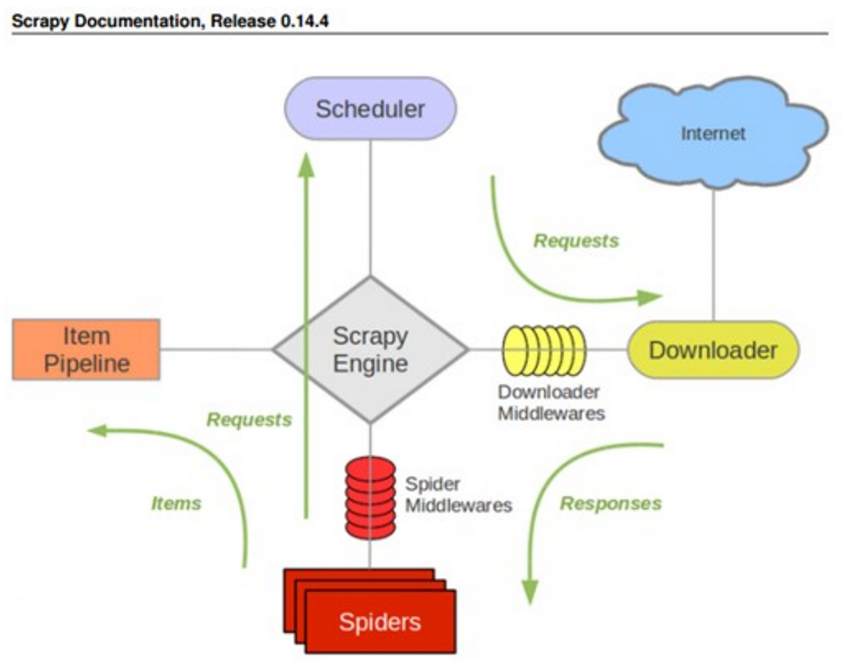
其具体执行流程如下:
1. 任务管理器Scheduler将初始下载任务递交给下载器Downloader;
2. 下载器Downloader将下载好了的页面传递给爬取分析器Spiders进行分析。
爬取分析器分析的结果分为两种:
a) 本次爬取所得数据 -> 它将传递给任务管理器Scheduler;
b) 需要进行下一级爬取的URL地址 -> 它将传递给数据管道进行相关的保存工作。
基于Scrapy框架的豆瓣网电影信息爬取器
1. 执行以下命令创建一个新的工程:
scrapy startproject doubanMovieSpider
doubanMovieSpider是工程名,工程包里将会有如下这些文件:
1) scrapy.cfg: 项目配置文件
2) items.py: 需要提取的数据结构定义文件
3) pipelines.py:管道定义,用来对items里面提取的数据做进一步处理,如保存等
4) settings.py: 爬虫配置文件
5) spiders: 放置spider的目录
该工程用于从豆瓣网爬取电影信息(如电影名,评分等等)。
2. 定义爬取结果数据结构Item --- 在items.py中编写如下代码:
# -*- coding: utf-8 -*-
# ================================================
# 作者: 方萌
# 创建时间: 20**/**/**
# 版本号: 1.0
# 联系方式: 1505033833@qq.com
# ================================================
# scrapy框架模块
import scrapy
class DoubanmoviespiderItem(scrapy.Item):
# 主题
title = scrapy.Field()
# 评分
rate = scrapy.Field()
# ID
id = scrapy.Field()
Item其实从本质来说,就是Scrapy框架自己实现的字典,需要继承scrapy.Item类。上述代码定义的字典表示要爬取的电影信息有:电影主题,电影评分,以及电影ID。
3. 实现爬取分析器Spider --- 在spiders目录下增加一个python文件MovieSpider.py:
在这个文件中自定义一个爬取分析器,该分析器为一个继承自scrapy.spider.BaseSpider(或者Scrapy框架下其他抽象爬取器)的类,它起码要实现以下几个字段:
1) name:spider的标识
2) start_urls:起始爬取URL
3) parse():爬取对象解析函数
实现代码如下:
# -*- coding: utf-8 -*-
# ================================================
# 作者: 方萌
# 创建时间: 20**/**/**
# 版本号: 1.0
# 联系方式: 1505033833@qq.com
# ================================================
# scrapy框架模块
import scrapy
# json解析模块
import json
# 系统模块
import sys
# items模块
import doubanMovieSpider.items
# 爬虫类
class MovieSpider(scrapy.spider.BaseSpider):
# 爬虫名
name = "douban"
# 域名限定
allowed_domains = ["www.douban.com"]
# 爬取URL队列
start_urls = [
"http://movie.douban.com/j/serch_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=200&page_start=0"
]
def parse(self, response):
"""
函数功能:
解析爬取到的数据
输入:
response -> 爬取返回数据对象
输出:
空
"""
# 将爬取到的电影信息存入json容器
json_container = json.loads(response.body)
# 构建items。该模块具体含义请查询相关文档。
items = []
for movie_elem in json_container['subjects']:
item = doubanMovieSpider.items.DoubanmoviespiderItem()
for key in movie_elem:
if key == 'title':
item['title'] = movie_elem[key]
print movie_elem[key]
if key == 'rate':
item['rate'] = movie_elem[key]
if key == 'id':
item['id'] = movie_elem[key]
items.append(item)
# 返回items
return items
4. 实现PipeLine --- 修改items.py文件:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class DoubanmoviespiderPipeline(object):
def __init__(self):
pass
def process_item(self, item, spider):
pass
PipeLine用来对Spider返回的Item列表进行保存操作,可以写入到文件、或者数据库等。
我们可以在其中的__init__方法内编写打开文件部分代码,在process_item方法内编写具体的写入函数(可直接将数据写入进远程数据库);也可以不实现这个模块,scrapy会有其默认的写入机制(本系统采用默认写入机制)
5. 在项目当前目录下执行如下命令即可启动此爬虫系统:
scrapy crawl douban -o items.json -t json
该命令表示启动爬取分析器“douban”,并将爬取到的items以json格式保存到items.json文件中。“douban” 即是在爬取分析器中由name域指定的。
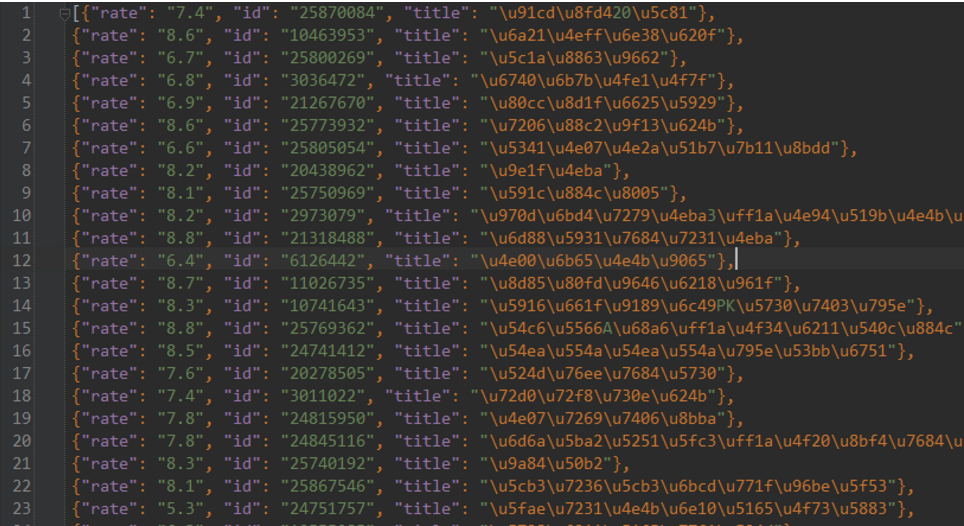
下图为爬取到的结果:
小结
本文仅仅给出Scrapy框架的基本使用。如果要实现生产级别的项目,还需对该框架内的一些具体设置,各种抽象爬取分析器进行深入研究。
第三篇:爬虫框架 - Scrapy的更多相关文章
- 洗礼灵魂,修炼python(72)--爬虫篇—爬虫框架:Scrapy
题外话: 前面学了那么多,相信你已经对python很了解了,对爬虫也很有见解了,然后本来的计划是这样的:(请忽略编号和日期,这个是不定数,我在更博会随时改的) 上面截图的是我的草稿 然后当我开始写博文 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 爬虫框架Scrapy
前面十章爬虫笔记陆陆续续记录了一些简单的Python爬虫知识, 用来解决简单的贴吧下载,绩点运算自然不在话下. 不过要想批量下载大量的内容,比如知乎的所有的问答,那便显得游刃不有余了点. 于是乎,爬虫 ...
随机推荐
- php define和const的区别
1.使用const使得代码简单易读,const本身就是一个语言结构,而define是一个函数2.const用于类成员变量的定义,一经定义,不可修改.3.Define不可以用于类成员变量的定义,可用于全 ...
- 初识vps,域名与购买,初步配置
终于还是到了这一天,不管我们是不是程序员,当我们想拥有自己的一个的博客,当我们想有自己的一个空间,当我们想在网上有一个自己可以随心所欲编写任何不被限制的仅仅是酷炫的效果,当我们想收录自己的技术,经历, ...
- Sourcetree的安装与使用
1 安装遇到的问题 https://segmentfault.com/q/1010000007643870 解决该问题的方法: http://www.jianshu.com/p/3478e2a214a ...
- CENTOS6.6上搭建单实例ORACLE12C
本文来自我的github pages博客http://galengao.github.io/ 即www.gaohuirong.cn 摘要: 自己在centos6.6上搭建的单实例oracle12c 由 ...
- JVM自动内存管理-Java内存区域与内存溢出异常
摘要: JVM内存的划分,导致内存溢出异常的可能区域. 1. JVM运行时内存区域 JVM在执行Java程序的过程中会把它所管理的内存划分为以下几个区域: 1.1 程序计数器 程序计数器是一块较小的内 ...
- (MonoGame从入门到放弃-3)-放弃MonoGame
又一段时间过去了,这一章没内容了.我真的已经放弃MonoGame的学习了,MonoGame用起来感觉就是在自己实现2d游戏引擎一样,好多现代游戏引擎有的内容都没有...,我只是想做游戏,而不是给引擎添 ...
- Python——文件操作详解
python中对文件.文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块. 得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd() 返回指定目录下的所有文件和目 ...
- STL中坑爹的max函数
hdu1754永远难忘的痛,参数最好不要传耗时特别长的函数,因为会调用两次,如果是递归的话,不知道多少次呢.. 切记!切记!切记! 例如: //return max(getAns(root<&l ...
- Docker系列一:Docker基本概念及指令介绍
1. Docker是什么? Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用 ...
- tcp/ip 卷一 读书笔记(2)物理层和链路层网络
物理层和链路层网络 术语 链路 是一对相邻结点间的物理线路,中间没有任何其他的交换结点. 数据链路 除了物理线路外,还必须有通信协议来控制这些数据的传输. 帧 数据链路层的协议数据单元(PDU) 串行 ...