[DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.9_归一化normalization
觉得有用的话,欢迎一起讨论相互学习~Follow Me
1.9 归一化Normaliation
训练神经网络,其中一个加速训练的方法就是归一化输入(normalize inputs).
假设我们有一个训练集,它有两个输入特征,所以输入特征x是二维的,这是数据集的散点图.

归一化输入需要两个步骤
第一步-零均值化
subtract out or to zero out the mean 计算出u即x(i)的均值
\[u=\frac{1}{m}\sum^{m}_{i=1}x^{(i)}\]
u是一个向量,\(x=x-u\)每个训练数据\(x\)都是\(x-u\)的新值
意思是移动训练集,直到它完成零均值化
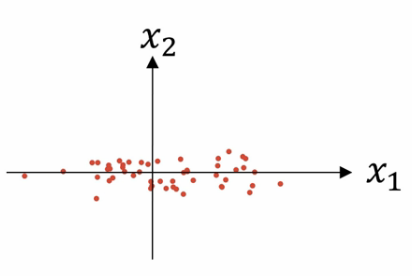
第二步-归一化方差
如上图所示:特征x1的方差比特征x2的方差要大得多,我们要做的是给\(\sigma\)赋值.\(\sigma\)是一个方差,它的每个特征都是方差.其中\(\sigma^2=\frac{1}{m}\sum^{m}_{i=1}x^{(i)}\).元素\(x^{(i)}\)表示每个特征的方差.我们已经对数据完成了零均值化,现在只需要将所有数据都除以向量\(\sigma^{2}\)
经过方差的归一化,数据分布变为:
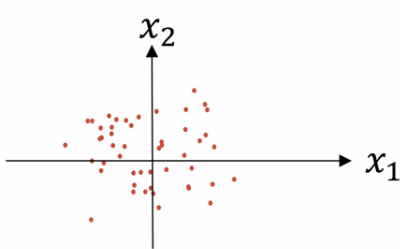
特征x1和特征x2的方差都等于1
注意:如果你要用它来调整数据,那么要用相同的\(u和\sigma^2\)来归一化测试集和训练集.这个数据集都是通过相同的\(u和\sigma定义的相同的数据转换\)其中\(u和\sigma都是通过训练数据集得来的\)
为什么要归一化输入特征
如果不使用归一化,则这是个非常细长狭窄的代价函数,你要找的代价函数的最小值点应该在这里.(如图中箭头标示)
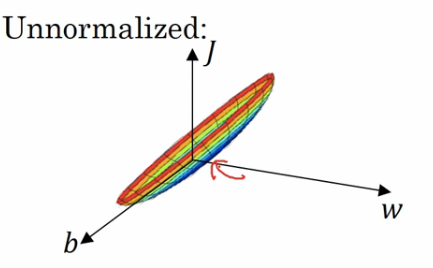
但是特征值在不同的取值范围内,例如x1取值范围从1到1000,特征x2的取值范围从0到1,结果是参数w1和w2值的范围或者比率完全不同,这些数据轴应该是w1和w2,为了直观理解,我标记为w和b,该函数的轮廓十分狭窄.

如果使用了归一化方法,代价函数更加对称

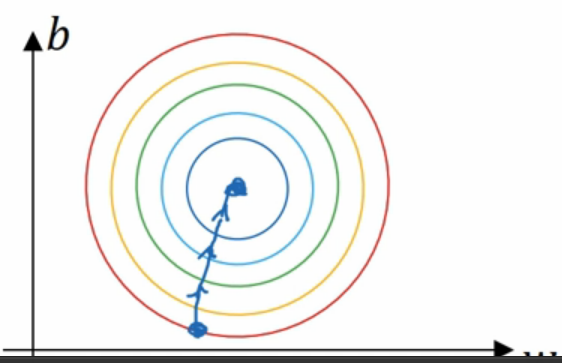
如果在不使用归一化方法且特征分布十分不均匀的数据集上的代价函数上运行梯度下降法,必须使用一个非常小的学习比率,因为如果是在这个位置,梯度下降法可能需要更多次迭代过程.

直到最后找到最小值.
但是如果函数是经过归一化的特征分布,那么会是一个更圆的轮廓,那么无论从哪个位置开始,梯度下降法都能够更直接地找到最小值,并且可以使用较大步长,而不是需要以较小步长反复执行.
这只是一个二维特征的例子,实际上w是一个高维向量,因此用二维绘制w并不能正确的传达直观理解,但总的直观理解是代价函数会更圆一些,并且更加荣艺油画,前提是特征都在相似范围内,而不是从1到1000,0到1的差别很大的范围内,而是都在-1到1的范围内,或者相似偏差,这使得优化代价函数变的更简单更快捷.
实际上,如果特征x1范围在0~1之间,x2在-1~1之间,x3在1~2之间,它们是相似范围,所以会表现的很好,如果在不同的取值范围内,如其中一个从1到1000,另一个从0到1,这对优化算法十分不利,但是仅将它们设置为均化零值,假设方差为1,确保特征都在相似范围内,通常可以使算法运算得更快.
如果数据的不同特征值取值范围差异很大,那么归一化就很重要了,如果特征值处于相似范围,那么归一化就变得不那么重要了.
[DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.9_归一化normalization的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.10_1.12/梯度消失/梯度爆炸/权重初始化
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.10 梯度消失和梯度爆炸 当训练神经网络,尤其是深度神经网络时,经常会出现的问题是梯度消失或者梯度爆炸,也就是说当你训练深度网络时,导数或坡 ...
- deeplearning.ai 改善深层神经网络 week1 深度学习的实用层面 听课笔记
1. 应用机器学习是高度依赖迭代尝试的,不要指望一蹴而就,必须不断调参数看结果,根据结果再继续调参数. 2. 数据集分成训练集(training set).验证集(validation/develop ...
- deeplearning.ai 改善深层神经网络 week1 深度学习的实用层面
1. 应用机器学习是高度依赖迭代尝试的,不要指望一蹴而就,必须不断调参数看结果,根据结果再继续调参数. 2. 数据集分成训练集(training set).验证集(validation/develop ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.3_2.5_带修正偏差的指数加权平均
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.3 指数加权平均 举个例子,对于图中英国的温度数据计算移动平均值或者说是移动平均值( ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.1_2.2_mini-batch梯度下降法
觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.1 mini-batch gradient descent mini-batch梯度下降法 我们将训练数据组合到一个大的矩阵中 \(X=\b ...
- [DeeplearningAI笔记]改善深层神经网络1.1_1.3深度学习使用层面_偏差/方差/欠拟合/过拟合/训练集/验证集/测试集
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 训练/开发/测试集 对于一个数据集而言,可以将一个数据集分为三个部分,一部分作为训练集,一部分作为简单交叉验证集(dev)有时候也成为验 ...
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
随机推荐
- 初识DJango——MTV模型
一.Django—MTV模型 Django的MTV分别代表: Model(模型):负责业务对象与数据库的对象(ORM) Template(模版):负责如何把页面展示给用户 View(视图):负责业务逻 ...
- 使用python写天气预告
先去YY天气注册一个账号,然后就能用API了 http://www.yytianqi.com/ # encoding=utf-8import urllib.requestimport jsonimpo ...
- CTF---隐写术入门第一题 SB!SB!SB!
SB!SB!SB!分值:20 来源: 西普学院 难度:中 参与人数:4913人 Get Flag:1541人 答题人数:1577人 解题通过率:98% LSB 解题链接: http://ctf5.sh ...
- java构建学生管理系统(一)
用java搭建学生管理系统,重要还是对数据库的操作,诸如增删改查等. 1.基本的功能: 老师完成对学生信息的查看和修改,完成对班级的信息的概览. 学生可以看自己的成绩和对自己信息的修改. 学生和老师有 ...
- SSL证书绑定成功
LNMPA一键安装包:装好后, 静态文件用nginx服务器,php文件用Apache服务器, 默认Apache端口为88:nginx为80: SSL证书装之前80端口, 装好后用443端口:
- vue ajax获取数据的时候,如何保证传递参数的安全或者说如何保护api的安全
https://segmentfault.com/q/1010000005618139 vue ajax获取数据的时候,如何保证传递参数的安全或者说如何保护api的安全 点击提交,发送请求.但是api ...
- Switch 语句
如果您希望有选择地执行若干代码块之一,请使用 Switch 语句. 使用 Switch 语句可以避免冗长的 if..elseif..else 代码块. 语法 工作原理: 对表达式(通常是变量)进行一次 ...
- 基于FPGA的HDMI高清显示接口驱动
HDMI是(High Definition Multimedia Interface)的缩写,意思是高清晰度多媒体接口,是一种数字化视频/音频接口技术,适合影像传输的专用型数字化接口,可同时传送音频和 ...
- log4j配置文件简要记录
和大多数配置文件一样,log4j配置文件也有key-value形式和xml形式.这里主要记录一下key-value的形式 我们通过配置,可以创建出Log4j的运行环境.Log4j由三个重要的组件构成: ...
- iphone开发笔记目录
http://www.cnblogs.com/syxchina/archive/2012/10/20/2732731.html#2653802