机器翻译评价指标 — BLEU算法
1,概述
机器翻译中常用的自动评价指标是 $BLEU$ 算法,除了在机器翻译中的应用,在其他的 $seq2seq$ 任务中也会使用,例如对话系统。
2 $BLEU$算法详解
假定人工给出的译文为$reference$,机器翻译的译文为$candidate$。
1)最早的$BLEU$算法
最早的$BLEU$算法是直接统计$cadinate$中的单词有多少个出现在$reference$中,具体的式子是:
$BLEU = \frac {出现在reference中的candinate的单词的个数} {cadinate中单词的总数}$
以下面例子为例:
$ candinate:$ the the the the the the the
$ reference:$ the cat is on the mat
$cadinate$中所有的单词都在$reference$中出现过,因此:
$BLEU = \frac {7} {7} = 1$
对上面的结果显然是不合理的,而且主要是分子的统计不合理,因此对上面式子中的分子进行了改进。
2)改进的$BLEU$算法 — 分子截断计数
针对上面不合理的结果,对分子的计算进行了改进,具体的做法如下:
$Count_{w_i}^{clip} = min(Count_{w_i},Ref\_Count_{w_i})$
上面式子中:
$Count_{w_i}$ 表示单词$w_i$在$candinate$中出现的次数;
$Ref\_Count_{w_i}$ 表示单词$w_i$在$reference$中出现的次数;
但一般情况下$reference$可能会有多个,因此有:
$Count^{clip} = max(Count_{w_i,j}^{clip}), j=1,2,3......$
上面式子中:$j$表示第$j$个$reference$。
仍然以上面的例子为例,在$candinate$中只有一个单词$the$,因此只要计算一个$Count^{clip}$,$the$在$reference$中只出现了两次,因此:
$BLEU = \frac {2} {7}$
3)引入$n-gram$
在上面我们一直谈的都是对于单个单词进行计算,单个单词可以看作时$1-gram$,$1-gram$可以描述翻译的充分性,即逐字翻译的能力,但不能关注翻译的流畅性,因此引入了$n-gram$,在这里一般$n$不大于4。引入$n-gram$后的表达式如下:
$p_{n}=\frac{\sum_{c_{\in candidates}}\sum_{n-gram_{\in c}}Count_{clip}(n-gram)}{\sum_{c^{'}_{\in candidates}}\sum_{n-gram^{'}_{\in c^{'}}}Count(n-gram^{'})}$
很多时候在评价一个系统时会用多条$candinate$来评价,因此上面式子中引入了一个候选集合$candinates$。$p_{n}$ 中的$n$表示$n-gram$,$p_{n}$表示$n_gram$的精度,即$1-gram$时,$n = 1$。
接下来简单的理解下上面的式子,首先来看分子:
1)第一个$\sum$ 描述的是各个$candinate$的总和;
2)第二个$\sum$ 描述的是一条$candinate$中所有的$n-gram$的总和;
3)$Count_{clip}(n-gram)$ 表示某一个$n-gram$词的截断计数;
再来看分母,前两个$\sum$和分子中的含义一样,$Count(n-gram^{'})$表示$n-gram^{'}$在$candinate$中的计数。
再进一步来看,实际上分母就是$candinate$中$n-gram$的个数,分子是出现在$reference$中的$candinate$中$n-gram$的个数。
举一个例子来看看实际的计算:
$candinate:$ the cat sat on the mat
$reference:$ the cat is on the mat
计算$n-gram$的精度:
$p_1 = \frac {5} {6} = 0.83333$
$p_2 = \frac {3} {5} = 0.6$
$p_3 = \frac {1} {4} = 0.25$
$p_4 = \frac {0} {3} = 0$
4)添加对句子长度的乘法因子
在翻译时,若出现译文很短的句子时往往会有较高的$BLEU$值,因此引入对句子长度的乘法因子,其表达式如下:
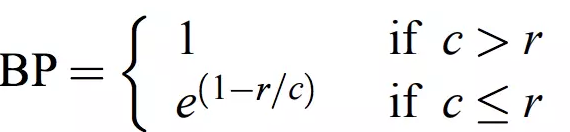
在这里$c$表示$cadinate$的长度,$r$表示$reference$的长度。
将上面的整合在一起,得到最终的表达式:
$BLEU = BP exp(\sum_{n=1}^N w_n \log p_n)$
其中$exp(\sum_{n=1}^N w_n \log p_n)$ 表示不同的$n-gram$的精度的对数的加权和。
3,$NLTK$实现
可以直接用工具包实现
from nltk.translate.bleu_score import sentence_bleu, corpus_bleu
from nltk.translate.bleu_score import SmoothingFunction
reference = [['The', 'cat', 'is', 'on', 'the', 'mat']]
candidate = ['The', 'cat', 'sat', 'on', 'the', 'mat']
smooth = SmoothingFunction() # 定义平滑函数对象
score = sentence_bleu(reference, candidate, weight=(0.25,0.25, 0.25, 0.25), smoothing_function=smooth.method1)
corpus_score = corpus_bleu([reference], [candidate], smoothing_function=smooth.method1)
$NLTK$中提供了两种计算$BLEU$的方法,实际上在sentence_bleu中是调用了corpus_bleu方法,另外要注意$reference$和$candinate$连个参数的列表嵌套不要错了,weight参数是设置不同的$n-gram$的权重,另外weight元祖中的数量决定了计算$BLEU$时,会用几个$n-gram$,以上面为例,会用$1-gram, 2-gram, 3-gram, 4-gram$。SmoothingFunction是用来平滑log函数的结果的,防止$f_n = 0$时,取对数为负无穷。
机器翻译评价指标 — BLEU算法的更多相关文章
- 机器翻译评测——BLEU算法详解
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7679284.html 前言 近年来,在自然语言研究领域中, ...
- 关于机器翻译评价指标BLEU(bilingual evaluation understudy)的直觉以及个人理解
最近我在做Natural Language Generating的项目,接触到了BLEU这个指标,虽然知道它衡量的是机器翻译的效果,也在一些文献的experiment的部分看到过该指标,但我实际上经常 ...
- 机器翻译质量评测算法-BLEU
机器翻译领域常使用BLEU对翻译质量进行测试评测.我们可以先看wiki上对BLEU的定义. BLEU (Bilingual Evaluation Understudy) is an algorithm ...
- 机器翻译评测——BLEU改进后的NIST算法
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7765345.html 上一节介绍了BLEU算的缺陷.NIS ...
- 机器翻译评价指标之BLEU详细计算过程
原文连接 https://blog.csdn.net/guolindonggld/article/details/56966200 1. 简介 BLEU(Bilingual Evaluation Un ...
- BLEU (Bilingual Evaluation Understudy)
什么是BLEU? BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text w ...
- 对于文本生成类4种评价指标的的计算BLEU METEOR ROUGE CIDEr
github下载链接:https://github.com/Maluuba/nlg-eval 将下载的文件放到工程目录,而后使用如下代码计算结果 具体的写作格式如下: from nlgeval imp ...
- Deep Learning基础--机器翻译BLEU与Perplexity详解
前言 近年来,在自然语言研究领域中,评测问题越来越受到广泛的重视,可以说,评测是整个自然语言领域最核心和关键的部分.而机器翻译评价对于机器翻译的研究和发展具有重要意义:机器翻译系统的开发者可以通过评测 ...
- 理解bleu
bleu全称为Bilingual Evaluation Understudy(双语评估替换),是2002年提出的用于评估机器翻译效果的一种方法,这种方法简单朴素.短平快.易于理解.因为其效果还算说得过 ...
随机推荐
- js导出excel表格并生成多sheet
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 小白学习Python之路---开发环境的搭建
本节内容 1.Python的介绍 2.发展史 3.安装Python 4.搭建开发环境 5.Hello World程序 一.Python的介绍 Python的创始人为荷兰人吉多·范罗苏姆(Guido v ...
- 【Android Studio安装部署系列】三十七、从Android Studio3.2升级到Android Studio3.4【以及创建Android Q模拟器】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 概述 保持Android Studio开发环境的最新版本. 下载Android Studio3.4 使用Android Studio自带的 ...
- AntZipUtils【基于Ant的Zip压缩解压缩工具类】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 Android 压缩解压zip文件一般分为两种方式: 基于JDK的Zip压缩工具类 该版本存在问题:压缩时如果目录或文件名含有中文, ...
- 【java线程池】
一.概述 1.线程池的优点 ①降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的消耗: ②提高系统响应速度,当有任务到达时,无需等待新线程的创建便能立即执行: ③方便线程并发数的管控,线 ...
- Devexpress常见问题
1.DevExpress控件组中的GridControl控件不能使横向滚动条有效. 现象:控件中的好多列都挤在一起,列宽都变的很小,根本无法正常浏览控件单元格中的内容. 解决:gridView1.Op ...
- Mac实用技巧之:访达/Finder
更多Mac实用技巧系列文章请访问我的博客:Mac实用技巧系列文章 Finder就相当于windows XP系统的『我的电脑』或win7/win10系统里的『计算机』(打开后叫资源管理器),find是查 ...
- [JavaScript] 函数节流(throttle)和函数防抖(debounce)
js 的函数节流(throttle)和函数防抖(debounce)概述 函数防抖(debounce) 一个事件频繁触发,但是我们不想让他触发的这么频繁,于是我们就设置一个定时器让这个事件在 xxx 秒 ...
- Springboot 系列(十一)使用 Mybatis(自动生成插件) 访问数据库
1. Springboot mybatis 介绍 MyBatis 是一款优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数获取 ...
- C# 2进制、8进制、10进制、16进制...各种进制间的转换(三) 数值运算和位运算
一.数值运算 各进制的数值计算很简单,把各进制数转换成 十进制数进行计算,然后再转换成原类型即可. 举例 :二进制之间的加法 /// <summary> /// 二进制之间的加法 /// ...