ansj人名识别
1、前言
1.1、asian_name_freq.data
1.2、person.dic
1.3、何时触发人名识别
public void setlocFreq(int[][] ints) {
for (int i = 0; i < ints.length; i++) {
if (ints[i][0] > 0) {
flag = true;
break ;
}
}
locFreq = ints;
}
2、具体实现
2.1识别出可能的人名
Result terms = ToAnalysis.parse("罗毅虎和曹罗伟是高中同学");
System.out.println("分词结果:" + terms);
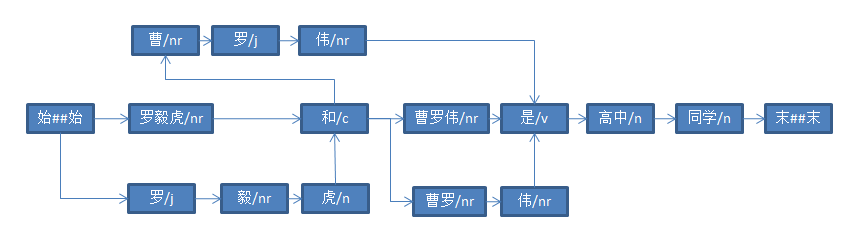
2.2、计算人名概率的一些理论基础
要想判断“曹罗伟”和“曹罗”哪个在此处更适合做人名,当然要计算二者存在的概率。
在谈到ansj的计算方法之前,我们先共同学习一下基于角色标注的中国人名自动识别研究这篇论文。(强烈建议读了这篇论文再往下看)
该论文将人名识别问题转化为了,对人名构成角色进行标注的问题。(详见论文的2.1、2.2)
我们要求解最终标注结果$T^{\#}=arg_{T}\,max\,P(T|W)$
论文中并不是直接求解$P(T|W)$,而是通过Bayes公式间接求解:
$P(T|W) = P(T)P(W|T)/P(W)$
没有直接求解,无非就是因为$P(T|W)$直接求解比较困难,或者根本无法直接求解。
我们先来看$P(t_{i}|w_{i})$是指:Token序列中的$w_{i}$,角色是$t_{i}$的概率。例如,对于人名识别前的Token序列:
$P(t_{i}|w_{i})$可以是指,“曹”这个$w_{i}$,角色是“三字姓名姓氏”的概率。
在大规模语料库训练的前提下,我们可以得到:
$P(t_{i}|w_{i})\approx C(t_{i},w_{i})/C(w_{i})$
其中,$C(t_{i},w_{i})$指角色$t_{i}$中出现$w_{i}$的次数,$C(w_{i})$是$w_{i}$出现的次数。
(1)、$C(w_{i})$是从大规模预料中统计出来,并保存在core词库中的,对该核心词库的整理,与人名识别无关,例如:
值得一提的是,$P(w_{i}|t_{i})$和$P(w_{i-1}|t_{i-1})$之间是相互独立的事件。
论文中提到,$P(W)$是一个常数。这确实是一个常数。并且,我们已经在现有核心词库(core.dic)的基础上,算得了这个数值。这正是上一节所讨论的内容。
2.3、计算人名概率
allFreq += Math.log(term.termNatures().allFreq + 1);
allFreq += -Math.log((freq));
但问题是,$C(w_{i})$ 和$C(t_{i},w_{i})$的统计来自不同的语料,所以这里的算法是没有理论依据的。
2.4、构造最短路径
计算完概率后,就可以使用Viterbi算法来求解最短路径,这与上一节类似。
以“陈颖超生前很和蔼”为例,将会得到以下结果:
2.5、人名消歧
2.6、用户自定义字典识别
// 用户自定义词典的识别
userDefineRecognition(graph, forests);
ansj人名识别的更多相关文章
- Hanlp实战HMM-Viterbi角色标注中国人名识别
这几天写完了人名识别模块,与分词放到一起形成了两层隐马模型.虽然在算法或模型上没有什么新意,但是胜在训练语料比较新,对质量把关比较严,实测效果很满意.比如这句真实的新闻“签约仪式前,秦光荣.李纪恒.仇 ...
- HanLP中人名识别分析
HanLP中人名识别分析 在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: 名字识别的问题 #387 机构名识别错误 关 ...
- HanLP中人名识别分析详解
HanLP中人名识别分析详解 在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: l ·名字识别的问题 #387 l ·机 ...
- HanLP中的人名识别分析详解
在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: u u名字识别的问题 #387 u u机构名识别错误 u u关于层叠H ...
- ICTCLAS中的HMM人名识别
http://www.hankcs.com/nlp/segment/ictclas-the-hmm-name-recognition.html 本文主要从代码的角度分析标注过程中的细节,理论谁都能说, ...
- 【文智背后的奥秘】系列篇——基于CRF的人名识别
版权声明:本文由文智原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/133 来源:腾云阁 https://www.qclou ...
- 基于分布式的短文本命题实体识别之----人名识别(python实现)
目前对中文分词精度影响最大的主要是两方面:未登录词的识别和歧义切分. 据统计:未登录词中中文姓人名在文本中一般只占2%左右,但这其中高达50%以上的人名会产生切分错误.在所有的分词错误中,与人名有关的 ...
- hanlp自然语言处理包的人名识别代码解析
HanLP发射矩阵词典nr.txt中收录单字姓氏393个.袁义达在<中国的三大姓氏是如何统计出来的>文献中指出:当代中国100个常见姓氏中,集中了全国人口的87%,根据这一数据我们只保留n ...
- HanLP-基于HMM-Viterbi的人名识别原理介绍
Hanlp自然语言处理包中的基于HMM-Viterbi处理人名识别的内容大概在年初的有分享过这类的文章,时间稍微久了一点,有点忘记了.看了 baiziyu 分享的这篇比我之前分享的要简单明了的多.下面 ...
随机推荐
- Java-Cookie源码
public class Cookie implements Cloneable { private static final String LSTRING_FILE = "javax.se ...
- 关于MySQL主从复制中UUID的警告信息
日期: 2014年5月23日 博客: 铁锚 最近在查看MariaDB主从复制服务器 Master 的错误日志时看到很多条警告信息,都是提示 UUID()函数不安全,可能 Slave 产生的值和 Mas ...
- Android BLE与终端通信(四)——实现服务器与客户端即时通讯功能
Android BLE与终端通信(四)--实现服务器与客户端即时通讯功能 前面几篇一直在讲一些基础,其实说实话,蓝牙主要为多的还是一些概念性的东西,当你把概念都熟悉了之后,你会很简单的就可以实现一些逻 ...
- 一键安装 redmine on rhel6.4
一键安装 redmine on rhel6.4 一键式安装redmine省去了大量不必要的时间.下载:bitnami-redmine-2.5.2-1-linux-x64-installer.run. ...
- Linux变量键盘读取、数组与声明: read, array, declare
[root@www ~]# read [-pt] variable 选项与参数: -p :后面可以接提示字符! -t :后面可以接等待的『秒数!』这个比较有趣-不会一直等待使用者啦! 范例一:让用户由 ...
- OpenCV——颜色运算(二)
#ifndef PS_ALGORITHM_H_INCLUDED #define PS_ALGORITHM_H_INCLUDED #include <iostream> #include & ...
- 【47】java的类之间的关系:泛化、依赖、关联、实现、聚合、组合
java的类之间的关系:泛化.依赖.关联.实现.聚合.组合 泛化: • 泛化关系(Generalization)也就是继承关系,也称为"is-a-kind-of"关系,泛化关系用于 ...
- Java Socket:Java-NIO-ServerSocketChannel
ServerSocketChannel 让我们从最简单的ServerSocketChannel来开始对socket通道类的讨论 ServerSocketChannel是一个基于通道的socket监听器 ...
- List,Set,Map三种接口的区别
set --其中的值不允许重复,无序的数据结构 list --其中的值允许重复,因为其为有序的数据结构 map--成对的数据结构,健值必须具有唯一性(键不能同,否则值替换) List按对象进 ...
- xmlrpc
xmlrpc编辑 官方URL:http://ws.apache.org/xmlrpc/xmlrpc2/index.html 本词条缺少名片图,补充相关内容使词条更完整,还能快速升级,赶紧来编辑吧! x ...