Redis --> Redis架构设计
Redis架构设计
一、前言
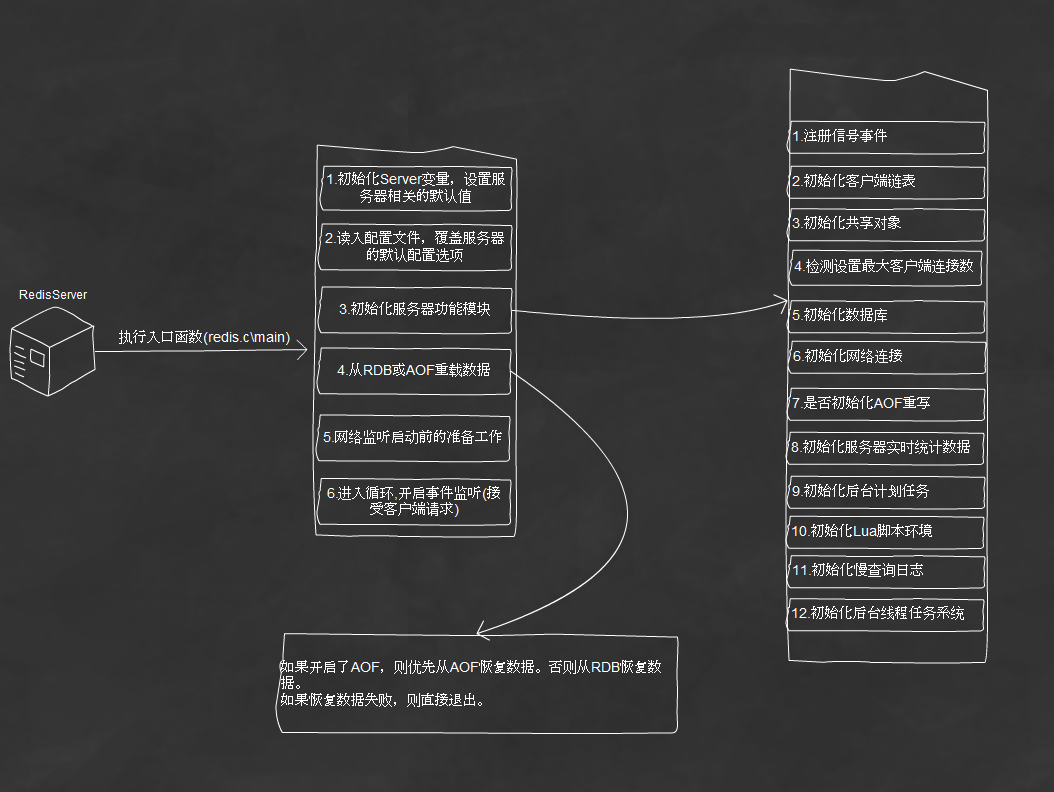
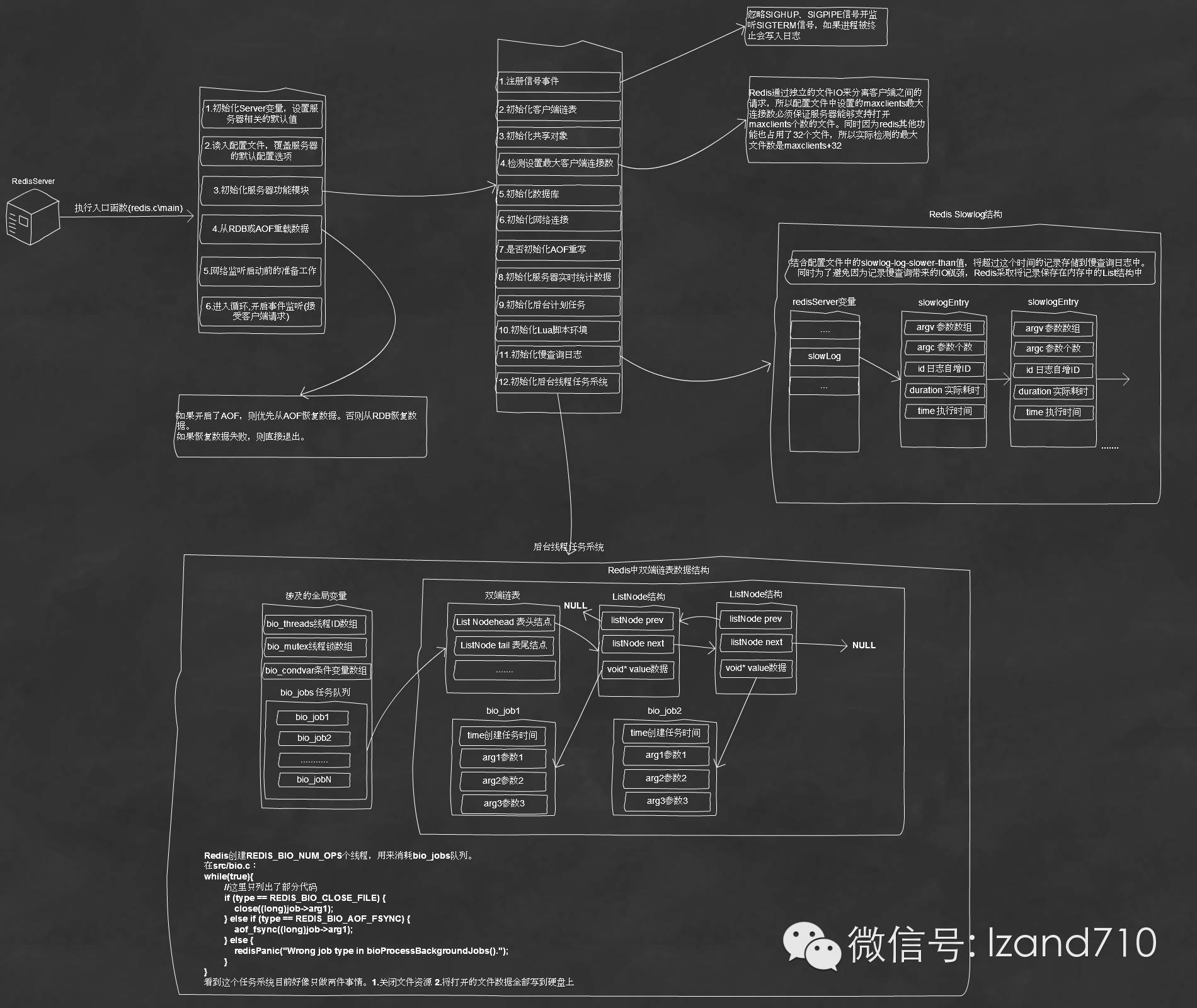
二、redis启动流程
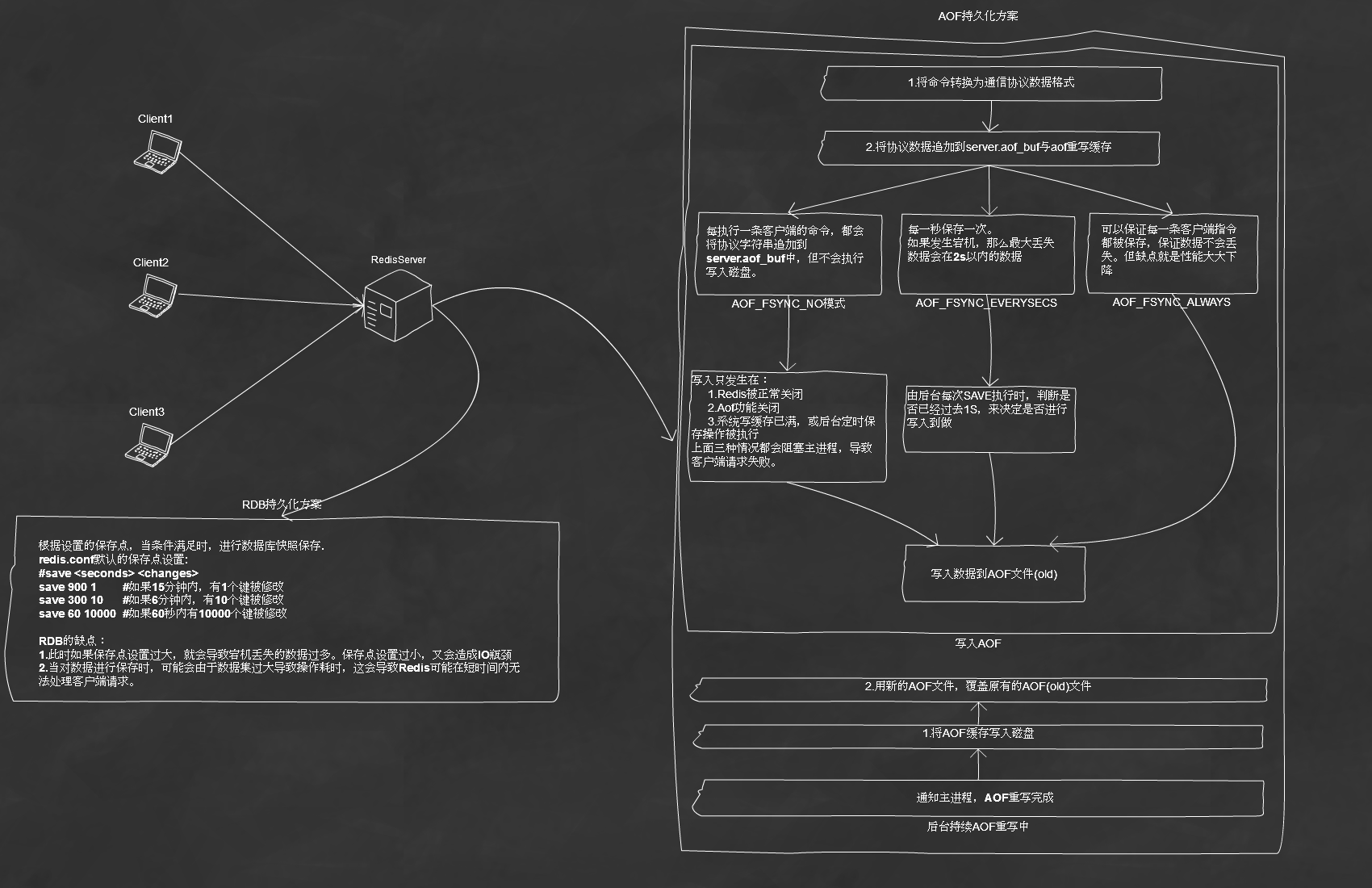
三、Redis数据持久化方案
1.RDB持久化方案
a)保存(rdbSave)
b)读取(rdbLoad)
#save <seconds> <changes>
save //如果15分钟内,有1个键被修改
save //如果6分钟内,有10个键被修改
save //如果60秒内有10000个键被修改
2.AOF持久化方案
a)保存
b)读取
LPUSH list
LPOP list
LPOP list
LPUSH list
最初保存到AOF文件的将会是四条指令。但经过AOF重写后,会变成一条指令:
LPUSH list
c)AOF重写流程
d)AOF缺点
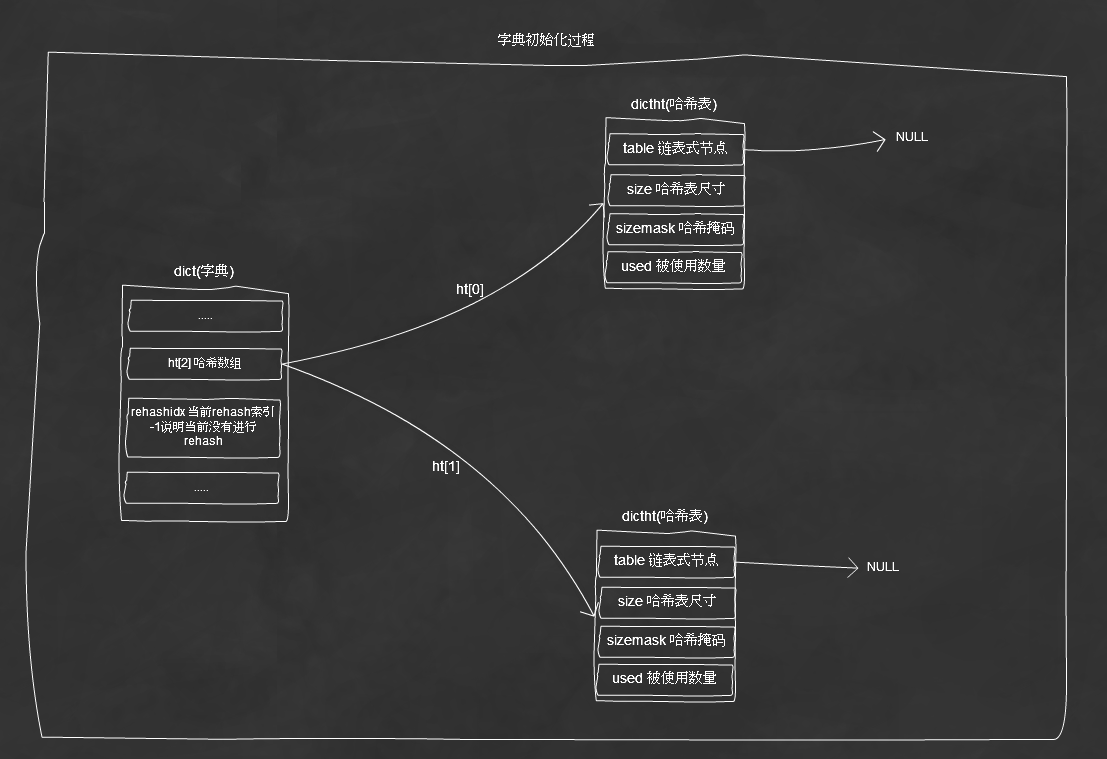
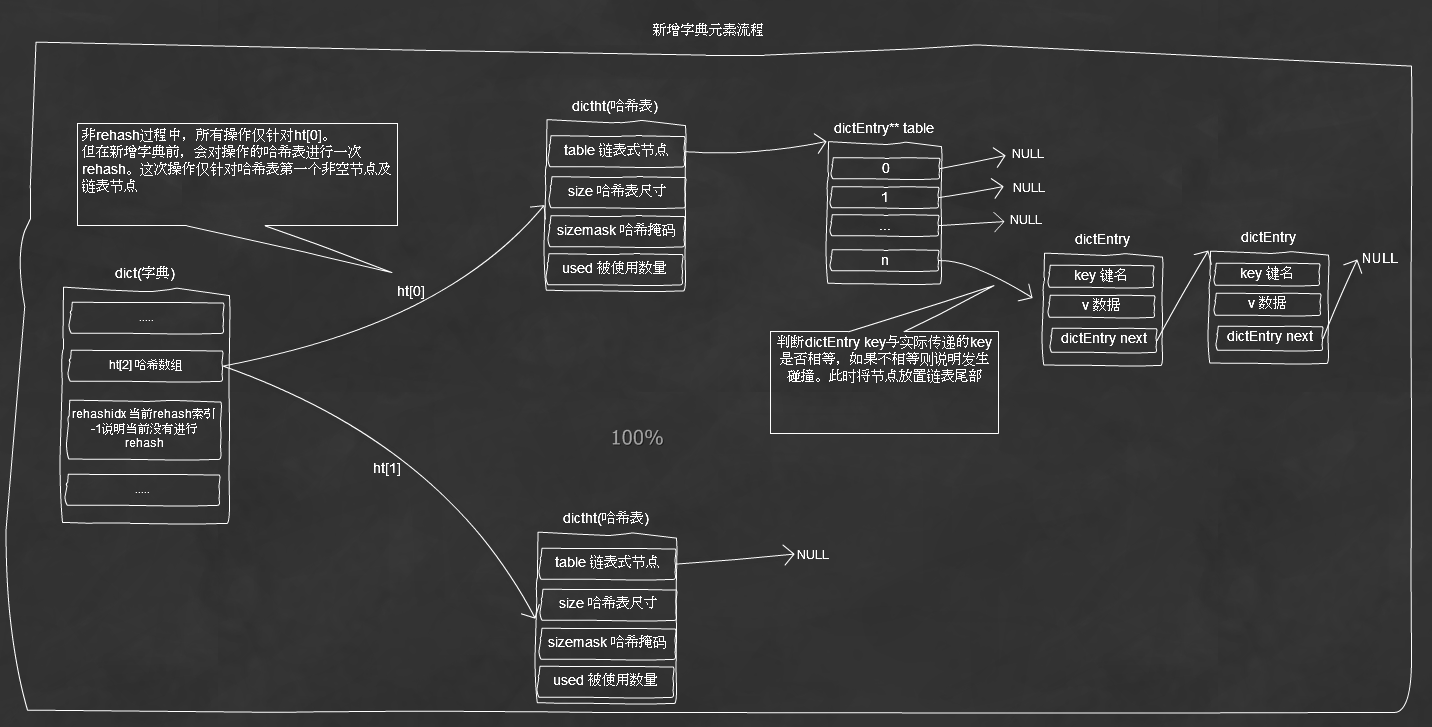
四、Redis数据库的实现
a)PHP主要应用于WEB场景,在WEB场景针对单次请求数据之间是隔离的,并且哈希的数量是有限的,那么进行一次rehash也是很快的。所以PHP内核使用阻塞形式rehash,即rehash进行中将不能对当前哈希表进行任何操作。

Redis --> Redis架构设计的更多相关文章
- Redis缓存项目应用架构设计二
一.概述 由于架构设计一里面如果多平台公用相同Key的缓存更改配置后需要多平台上传最新的缓存配置文件来更新,比较麻烦,更新了架构设计二实现了缓存配置的集中管理,不过这样有有了过于中心化的问题,后续在看 ...
- 亿级流量场景下,大型缓存架构设计实现【1】---redis篇
*****************开篇介绍**************** -------------------------------------------------------------- ...
- Redis架构设计
高可用Redis服务架构分析与搭建 各种web开发业务中最为常用的key-value数据库了 应用: 在业务中用其存储用户登陆态(Session存储),加速一些热数据的查询(相比较mysql而言,速度 ...
- 细说分布式Redis架构设计和踩过的那些坑
细说分布式Redis架构设计和踩过的那些坑_redis 分布式_ redis 分布式锁_分布式缓存redis 细说分布式Redis架构设计和踩过的那些坑
- Redis 高可用架构设计(转载)
转载自:https://mp.weixin.qq.com/s?__biz=MzA3NDcyMTQyNQ==&mid=2649263292&idx=1&sn=b170390684 ...
- Redis的高并发、持久化、高可用架构设计
就是如果你用redis缓存技术的话,肯定要考虑如何用redis来加多台机器,保证redis是高并发的,还有就是如何让Redis保证自己不是挂掉以后就直接死掉了,redis高可用 我这里会选用我之前讲解 ...
- 《【面试突击】— Redis篇》--Redis Cluster及缓存使用和架构设计的常见问题
能坚持别人不能坚持的,才能拥有别人未曾拥有的.关注编程大道公众号,让我们一同坚持心中所想,一起成长!! <[面试突击]— Redis篇>--Redis Cluster及缓存使用和架构设计的 ...
- Redis初识、设计思想与一些学习资源推荐
一.Redis简介 1.什么是Redis Redis 是一个开源的使用ANSI C 语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value 数据库,并提供多种语言的API.从2010 年 ...
- Redis Cluster架构优化
Redis Cluster架构优化 在<全面剖析Redis Cluster原理和应用>中,我们已经详细剖析了现阶段Redis Cluster的缺点: 无中心化架构 Gossip消息的开销 ...
随机推荐
- 微信 Tinker 的一切都在这里,包括源码
最近半年以来,Android热补丁技术热潮继续爆发,各大公司相继推出自己的开源框架.Tinker在最近也顺利完成了公司的审核,并非常荣幸的成为github.com/Tencent上第一个正式公开的项目 ...
- Linux中的DRM
如果在搜索引擎离搜索 DRM 映入眼帘的尽是Digital Rights Managemen,也就是数字版权加密保护技术.这当然不是我们想要的解释.在类unix世界中还有一个DRM即The Direc ...
- Redis相关指令文档
连接控制 QUIT 关闭连接 AUTH (仅限启用时)简单的密码验证 适合全体类型的命令 EXISTS key 判断一个键是否存在;存在返回 1;否则返回0; DEL key 删除某个key,或是一系 ...
- Error Code: 1175. You are using safe update mode and you tried to update a table
错误描述 11:14:39 delete from t_analy_yhd Error Code: 1175. You are using safe update mode and you tried ...
- org.springframework.beans.factory.NoSuchBeanDefinitionException: No bean named 'transactionManager'
1.错误描述 五月 01, 2015 2:12:31 下午 org.hibernate.validator.util.Version <clinit> 信息: Hibernate Vali ...
- org.apache.subversion.javahl.ClientException: Attempted to lock an already-locked dir
1.错误描述 org.apache.subversion.javahl.ClientException: Attempted to lock an already-locked dir svn: Co ...
- sqlserver 以年月日为条件查询记录
今天做一个东西的时候,要查某年,某月的记录,从网上找到了sqlserver中的datepart函数,该函数是用来提取年份,月份,日期的一个函数,带两个参数,第一个为(yy,mm,dd)其中一个,表示年 ...
- 芝麻HTTP:pyspider的安装
pyspider是国人binux编写的强大的网络爬虫框架,它带有强大的WebUI.脚本编辑器.任务监控器.项目管理器以及结果处理器,同时支持多种数据库后端.多种消息队列,另外还支持JavaScript ...
- 使input文本框不可编辑的3种方法
一:disabled disabled 属性规定应该禁用 input 元素,被禁用的 input 元素,不可编辑,不可复制,不可选择,不能接收焦点,后台也不会接收到传值.设置后文字的颜色会变成灰色.d ...
- 解决无法同步 OneNote 的问题
在本地创建的笔记本,无法共享到云端,显示无法连接onedrive. 关闭改笔记本,重新连接共享. 参考: https://support.office.com/zh-cn/article/%E8%A7 ...