深度学习之卷积神经网络(CNN)的应用-验证码的生成与识别
验证码的生成与识别
本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10755361.html
目录
1.验证码的制作
2.卷积神经网络结构
3.训练参数保存与使用
4.注意事项
5.代码实现(python3.5)
6.运行结果以及分析
1.验证码的制作
深度学习一个必要的前提就是需要大量的训练样本数据,毫不夸张的说,训练样本数据的多少直接决定模型的预测准确度。而本节的训练样本数据(验证码:字母和数字组成)通过调用Image模块(图像处理库)中相关函数生成。
安装:pip install pillow
验证码生成步骤:随机在字母和数字中选择4个字符 -> 创建背景图片 -> 添加噪声 -> 字符扭曲
具体样本如下所示:
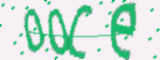

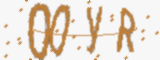
对于上图的验证码,如果用传统方式破解,其步骤一般是:
图片分割:采用分割算法分割出每一个字符;
字符识别:由分割出的每个字符图片,根据OCR光学字符识别出每个字符图片对应的字符;
难点在于:对于图片字符有黏连(2个,3个,或者4个全部黏连),图片是无法完全分割出来的,也就是说,即使分割出来了,字符识别基本上都是错误的,特别对于人眼都无法分辨的验证码,用传统的这种破解方法,成功率基本上是极其低的。
黏连验证码


人眼几乎无法分辨验证码
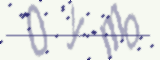

第一张是 0ymo or 0ynb ?第二张是 7e9l or 1e9l ?
对于以上传统方法破解验证码的短板,我们采用深度学习之卷积神经网络来进行破解。
2.卷积神经网络结构
前向传播组成:3个卷积层(3*3*1*32,3*3*32*64,3*3*64*64),3个池化层,4个dropout防过拟合层,2个全连接层((8*20*64,1024),(1024, MAX_CAPTCHA*CHAR_SET_LEN])),4个Relu激活函数。
反向传播组成:计算损失(sigmoid交叉熵),计算梯度,目标预测,计算准确率,参数更新。
tensorboard生成结构图(图片可能不是很清楚,在图片位置点击鼠标右键->在新标签页面打开图片,就可以放缩图片了。)

这里特别要注意数据流的变化:
(?,60,160,1) + conv1->(?,60,160,32)+ relu ->(?,60,160,32) + pool1 ->(?,30,80,32) + dropout -> (?,30,80,32)
+ conv2->(?,30,80,64) + relu ->(?,30,80,64) + pool2 ->(?,15,40,64) + dropout -> (?,15,40,64)
+ conv3->(?,15,40,64) + relu ->(?,15,40,64) + pool3 ->(?,8,20,64) + dropout -> (?,8,20,64)
+ fc1 ->(?,1024) + relu ->(?,1024) + dropout ->(?,1024)
+ fc2 ->(?,MAX_CAPTCHA*CHAR_SET_LEN)
只要把握住一点,卷积过程跟全连接运算是不一样的。
卷积过程:矩阵对应位置相乘再相加,要求相乘的两个矩阵宽、高必须相同(比如大小都是m * n),得到结果就是一个数值。
全连接(矩阵乘法):它要求第一个矩阵的列和第二个矩阵的行必须相同,比如矩阵A大小m * n,矩阵B大小n * k,红色部分必须相同,得到结果大小就是m * k。
3.训练参数保存与使用
参数保存:
tensorflow对于参数保存功能已帮我们做好了,我们只要直接使用就可以了。使用也很简单,就两步,获取保存对象,调用保存方法。
获取保存对象:
saver = tf.train.Saver()
调用保存方法:
saver.save(sess, "./model/crack_capcha.model99", global_step=step)
global_step=step :在保存文件时,会统计运行了多少次。
参数使用:
获取保存对象->获取最后一次生成文件的路径->导入参数到session会话中
获取保存对象与参数保存是一样的。
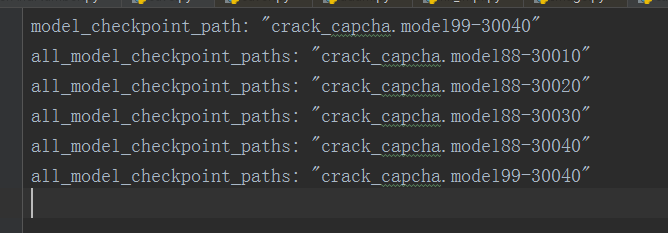
获取最后一次生成文件的路径:在参数保存时会生成一个checkpoint文件(我的是在model文件下),里面会记录最后一次生成文件的文件名。model文件
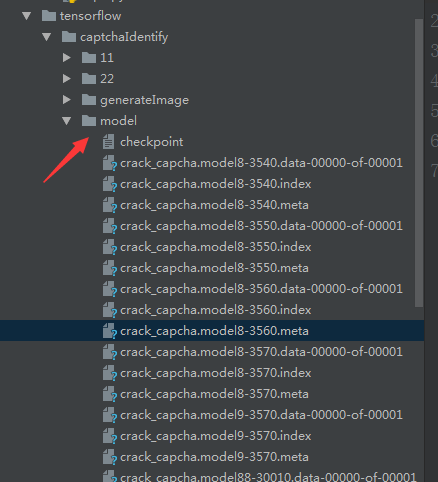
checkpoint内容
导入参数到session会话中:首先要开启session会话,然后调用保存对象的restore方法即可。
saver.restore(sess, checkpoint.model_checkpoint_path)
4.注意事项
1. 在session调用run方法时,一定不能遗漏某个操作结果对应的参数赋值,这表述比较绕口,我们来看下面的例子。
_, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.75})
X:输入数据,Y:标签数据,keep_prob:防过拟合概率因子(超参),这些参数在获取损失函数loss,计算梯度optimizer时被用到,
在tensorflow的CNN中只是作为占位符处理的,所以在session调用run方法时,一定要对这些参数赋值,并用feed_dict作为字典参数传入,注意大小写也要相同。
2. 在训练前需要将文本转为向量,在预测判断是否准确时需要将向量转为文本字符串。
这里的样例总长度63:数字10个(0-9),小写字母26(a-z),大写字母26(A-Z),'_':如果不够4个字符,用来补齐。
向量长度范围:字符4*(10 + 26 + 26 + 1) = 252
文本转向量:通过某种规则(char2pos),计算字符数值,然后根据该字符在4个字符中的位置,计算向量索引
idx = i * CHAR_SET_LEN + char2pos(c)
向量转文本:跟文本转向量操作相反(vec2text)
5.代码实现(python3.5)
在letterAndNumber.py文件中,train = 0 表示训练,1表示预测。
在训练时,采用的batch_size = 64,每训练100次计算一次准确率,如果准确率大于0.8,就将参数保存到model文件中,准确率大于0.9,在保存参数的同时结束训练。
在预测时,随机采用100幅图片,观察其准确率;另外,对于之前展示的黏连验证码,人眼不能较好分辨的验证码,单独进行识别。
letterAndNumber.py
import numpy as np
import tensorflow as tf
from captcha.image import ImageCaptcha
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import random number = ['','','','','','','','','','']
alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
ALPHABET = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'] def random_captcha_text(char_set=number+alphabet+ALPHABET, captcha_size=4):
#def random_captcha_text(char_set=number, captcha_size=4):
captcha_text = []
for i in range(captcha_size):
c = random.choice(char_set)
captcha_text.append(c)
return captcha_text def gen_captcha_text_and_image(i = 0):
# 创建图像实例对象
image = ImageCaptcha()
# 随机选择4个字符
captcha_text = random_captcha_text()
# array 转化为 string
captcha_text = ''.join(captcha_text)
# 生成验证码
captcha = image.generate(captcha_text)
if i%100 == 0 :
image.write(captcha_text, "./generateImage/" + captcha_text + '.jpg') captcha_image = Image.open(captcha)
captcha_image = np.array(captcha_image)
return captcha_text, captcha_image def convert2gray(img):
if len(img.shape) > 2:
gray = np.mean(img, -1)
# 上面的转法较快,正规转法如下
# r, g, b = img[:,:,0], img[:,:,1], img[:,:,2]
# gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray
else:
return img # 文本转向量
def text2vec(text):
text_len = len(text)
if text_len > MAX_CAPTCHA:
raise ValueError('验证码最长4个字符') vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN) def char2pos(c):
if c =='_':
k = 62
return k
k = ord(c)-48
if k > 9:
k = ord(c) - 55
if k > 35:
k = ord(c) - 61
if k > 61:
raise ValueError('No Map')
return k for i, c in enumerate(text):
#idx = i * CHAR_SET_LEN + int(c)
idx = i * CHAR_SET_LEN + char2pos(c)
vector[idx] = 1
return vector
# 向量转回文本
def vec2text(vec):
char_pos = vec[0]
text=[]
for i, c in enumerate(char_pos):
char_at_pos = i #c/63
char_idx = c % CHAR_SET_LEN
if char_idx < 10:
char_code = char_idx + ord('')
elif char_idx <36:
char_code = char_idx - 10 + ord('A')
elif char_idx < 62:
char_code = char_idx- 36 + ord('a')
elif char_idx == 62:
char_code = ord('_')
else:
raise ValueError('error')
text.append(chr(char_code))
"""
text=[]
char_pos = vec.nonzero()[0]
for i, c in enumerate(char_pos):
number = i % 10
text.append(str(number))
"""
return "".join(text) """
#向量(大小MAX_CAPTCHA*CHAR_SET_LEN)用0,1编码 每63个编码一个字符,这样顺利有,字符也有
vec = text2vec("F5Sd")
text = vec2text(vec)
print(text) # F5Sd
vec = text2vec("SFd5")
text = vec2text(vec)
print(text) # SFd5
""" # 生成一个训练batch
def get_next_batch(batch_size=128):
batch_x = np.zeros([batch_size, IMAGE_HEIGHT*IMAGE_WIDTH])
batch_y = np.zeros([batch_size, MAX_CAPTCHA*CHAR_SET_LEN]) # 有时生成图像大小不是(60, 160, 3)
def wrap_gen_captcha_text_and_image(i):
while True:
text, image = gen_captcha_text_and_image(i)
if image.shape == (60, 160, 3):
return text, image for i in range(batch_size):
text, image = wrap_gen_captcha_text_and_image(i)
image = convert2gray(image) batch_x[i,:] = image.flatten() / 255 # (image.flatten()-128)/128 mean为0
batch_y[i,:] = text2vec(text) return batch_x, batch_y # 定义CNN
def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1):
x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1]) #w_c1_alpha = np.sqrt(2.0/(IMAGE_HEIGHT*IMAGE_WIDTH)) #
#w_c2_alpha = np.sqrt(2.0/(3*3*32))
#w_c3_alpha = np.sqrt(2.0/(3*3*64))
#w_d1_alpha = np.sqrt(2.0/(8*32*64))
#out_alpha = np.sqrt(2.0/1024) # 3 conv layer
w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 32]))
b_c1 = tf.Variable(b_alpha*tf.random_normal([32]))
# 卷积 + Relu激活函数
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
# 池化
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# dropout 防止过拟合
conv1 = tf.nn.dropout(conv1, rate = 1 - keep_prob) w_c2 = tf.Variable(w_alpha*tf.random_normal([3, 3, 32, 64]))
b_c2 = tf.Variable(b_alpha*tf.random_normal([64]))
# 卷积 + Relu激活函数
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2))
# 池化
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# dropout 防止过拟合
conv2 = tf.nn.dropout(conv2, rate = 1 - keep_prob) w_c3 = tf.Variable(w_alpha*tf.random_normal([3, 3, 64, 64]))
b_c3 = tf.Variable(b_alpha*tf.random_normal([64]))
# 卷积 + Relu激活函数
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3))
# 池化
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# dropout 防止过拟合
conv3 = tf.nn.dropout(conv3, rate = 1 - keep_prob) # Fully connected layer
w_d = tf.Variable(w_alpha*tf.random_normal([8*20*64, 1024]))
b_d = tf.Variable(b_alpha*tf.random_normal([1024]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
# 全连接 + Relu
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
dense = tf.nn.dropout(dense, rate = 1 - keep_prob) w_out = tf.Variable(w_alpha*tf.random_normal([1024, MAX_CAPTCHA*CHAR_SET_LEN]))
b_out = tf.Variable(b_alpha*tf.random_normal([MAX_CAPTCHA*CHAR_SET_LEN]))
# 全连接
out = tf.add(tf.matmul(dense, w_out), b_out)
return out # 训练
def train_crack_captcha_cnn():
output = crack_captcha_cnn()
# 计算损失
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits= output, labels= Y))
# 计算梯度
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
# 目标预测
predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN])
# 目标预测最大值
max_idx_p = tf.argmax(predict, 2)
# 真实标签最大值
max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
correct_pred = tf.equal(max_idx_p, max_idx_l)
# 准确率
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) saver = tf.train.Saver()
with tf.Session() as sess:
# 打印tensorboard流程图
tf.summary.FileWriter("./tensorboard/", sess.graph)
sess.run(tf.global_variables_initializer()) step = 0
while True:
batch_x, batch_y = get_next_batch(64)
_, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.75})
print(step, loss_) # 每100 step计算一次准确率
if step % 100 == 0:
batch_x_test, batch_y_test = get_next_batch(100)
acc = sess.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.})
print(step, acc)
# 如果准确率大于80%,保存模型,完成训练
if acc > 0.90:
saver.save(sess, "./model/crack_capcha.model99", global_step=step)
break
if acc > 0.80:
saver.save(sess, "./model/crack_capcha.model88", global_step=step) step += 1
def crack_captcha(captcha_image, output): saver = tf.train.Saver() with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
# 获取训练后的参数
checkpoint = tf.train.get_checkpoint_state("model")
if checkpoint and checkpoint.model_checkpoint_path:
saver.restore(sess, checkpoint.model_checkpoint_path)
print("Successfully loaded:", checkpoint.model_checkpoint_path)
else:
print("Could not find old network weights") predict = tf.argmax(tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
text_list = sess.run(predict, feed_dict={X: [captcha_image], keep_prob: 1})
#text = text_list[0].tolist()
text = vec2text(text_list)
return text
if __name__ == '__main__':
train = 0 # 0: 训练 1: 预测
if train == 0:
number = ['','','','','','','','','','']
alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
ALPHABET = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'] text, image = gen_captcha_text_and_image()
print("验证码图像channel:", image.shape) # (60, 160, 3)
# 图像大小
IMAGE_HEIGHT = 60
IMAGE_WIDTH = 160
MAX_CAPTCHA = len(text)
print("验证码文本最长字符数", MAX_CAPTCHA)
# 文本转向量
char_set = number + alphabet + ALPHABET + ['_'] # 如果验证码长度小于4, '_'用来补齐
#char_set = number
CHAR_SET_LEN = len(char_set)
# placeholder占位符,作用域:整个页面,不需要声明时初始化
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT*IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32) # dropout train_crack_captcha_cnn()
# 预测时需要将训练的变量初始化,且只能初始化一次。
if train == 1:
# 自然计数
step = 0
# 正确预测计数
rightCnt = 0
# 设置测试次数
count = 100
number = ['','','','','','','','','','']
alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
ALPHABET = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'] IMAGE_HEIGHT = 60
IMAGE_WIDTH = 160 char_set = number + alphabet + ALPHABET + ['_']
CHAR_SET_LEN = len(char_set)
MAX_CAPTCHA = 4 # len(text)
# placeholder占位符,作用域:整个页面,不需要声明时初始化
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT*IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32) # dropout
output = crack_captcha_cnn() saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 获取训练后参数路径
checkpoint = tf.train.get_checkpoint_state("model")
if checkpoint and checkpoint.model_checkpoint_path:
saver.restore(sess, checkpoint.model_checkpoint_path)
print("Successfully loaded:", checkpoint.model_checkpoint_path)
else:
print("Could not find old network weights.") while True:
# image = Image.open("D:/Project/python/myProject/CNN/tensorflow/captchaIdentify/11/0sHB.jpg")
# image = np.array(image)
# text = '0sHB'
text, image = gen_captcha_text_and_image()
# f = plt.figure()
# ax = f.add_subplot(111)
# ax.text(0.1, 0.9,text, ha='center', va='center', transform=ax.transAxes)
# plt.imshow(image)
#
# plt.show() image = convert2gray(image)
image = image.flatten() / 255
predict = tf.math.argmax(tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
text_list = sess.run(predict, feed_dict= { X: [image], keep_prob : 1})
predict_text = vec2text(text_list)
predict_text = crack_captcha(image, output)
# predict_text_list = [str(x) for x in predict_text]
# predict_text_new = ''.join(predict_text_list)
print("step:{} 真实值: {} 预测: {} 预测结果: {}".format(str(step), text, predict_text, "正确" if text.lower()==predict_text.lower() else "错误"))
if text.lower()==predict_text.lower():
rightCnt += 1
if step == count - 1:
print("测试总数: {} 测试准确率: {}".format(str(count), str(rightCnt/count)))
break
step += 1
6.运行结果以及分析
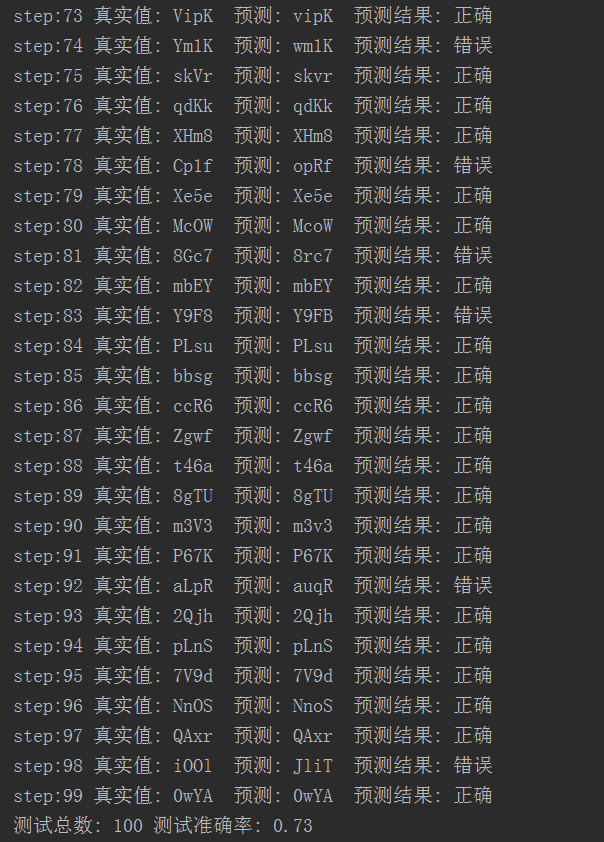
随机采用100幅图片,运行结果如下:
黏连验证码


运行结果


人眼较难识别验证码


运行结果


结果分析:随机选取100张验证码测试,准确率有73%,这个准确率在同类型的验证码中已经比较可观了。当然,可以在训练时将测试准确率继续提高,比如0.95或更高,这样,在预测时的准确率应该还会有提升的,大家有兴趣的话可以试试。
不要让懒惰占据你的大脑,不要让妥协拖垮了你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐就掌握在你的脚下。
深度学习之卷积神经网络(CNN)的应用-验证码的生成与识别的更多相关文章
- 深度学习之卷积神经网络CNN及tensorflow代码实例
深度学习之卷积神经网络CNN及tensorflow代码实例 什么是卷积? 卷积的定义 从数学上讲,卷积就是一种运算,是我们学习高等数学之后,新接触的一种运算,因为涉及到积分.级数,所以看起来觉得很复杂 ...
- 深度学习之卷积神经网络CNN及tensorflow代码实现示例
深度学习之卷积神经网络CNN及tensorflow代码实现示例 2017年05月01日 13:28:21 cxmscb 阅读数 151413更多 分类专栏: 机器学习 深度学习 机器学习 版权声明 ...
- 深度学习之卷积神经网络(CNN)详解与代码实现(一)
卷积神经网络(CNN)详解与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10430073.html 目 ...
- 深度学习之卷积神经网络CNN
转自:https://blog.csdn.net/cxmscb/article/details/71023576 一.CNN的引入 在人工的全连接神经网络中,每相邻两层之间的每个神经元之间都是有边相连 ...
- 深度学习之卷积神经网络(CNN)详解与代码实现(二)
用Tensorflow实现卷积神经网络(CNN) 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10737065. ...
- 【转载】 深度学习之卷积神经网络(CNN)详解与代码实现(一)
原文地址: https://www.cnblogs.com/further-further-further/p/10430073.html ------------------------------ ...
- 【神经网络与深度学习】卷积神经网络(CNN)
[神经网络与深度学习]卷积神经网络(CNN) 标签:[神经网络与深度学习] 实际上前面已经发布过一次,但是这次重新复习了一下,决定再发博一次. 说明:以后的总结,还应该以我的认识进行总结,这样比较符合 ...
- 深度学习之卷积神经网络(CNN)
卷积神经网络(CNN)因为在图像识别任务中大放异彩,而广为人知,近几年卷积神经网络在文本处理中也有了比较好的应用.我用TextCnn来做文本分类的任务,相比TextRnn,训练速度要快非常多,准确性也 ...
- 深度学习FPGA实现基础知识10(Deep Learning(深度学习)卷积神经网络(Convolutional Neural Network,CNN))
需求说明:深度学习FPGA实现知识储备 来自:http://blog.csdn.net/stdcoutzyx/article/details/41596663 说明:图文并茂,言简意赅. 自今年七月份 ...
随机推荐
- C语言出来多久了你知道吗?
在20世纪80年代,为了避免不同开发者使用的C语言语法的差异,美国国家标准局为C语言开发了一套完整的美国国家标准语言文法,称为ANSI C,作为C语言的初始标准.. [1] 2011年12月8日,国际 ...
- CSS 静态进度条效果
今天学习到了实现一个静态进度条的方法,固写一篇笔记稳固一下自己的知识. 最终的效果如下,进度条放在一个框里,水平宽自适应. 现在就开始,首先写一个进度条先. .progress-bar{ /* 进度条 ...
- 一些遇到的Qt程序在Windows平台间移植问题整理
今天尝试把Qt程序移植到各种虚拟机中测试,由于Qt的依赖库报告往往不能显示出全部依赖库.结果频频出现问题,好不容易全部解决了,这里给出一些套路. 首先对于Qt版本,我用过很多,最终表示现阶段推荐Min ...
- Xamarin.Android 使用百度地图获取定位信息
最近做一个项目,web端使用百度地图,PDA使用手持机自带的GPS定位系统获取经纬度,然后再百度地图上显示该经纬度会有一定距离的差异,这里就像可乐的瓶子拧上雪碧的盖子,能拧的上却不美观.所以为了数据的 ...
- 导出excel记录
前言: 记录这篇使用记录,是为了方便以后学习查阅和让没有使用过的人了解一下,其中不足还请见谅.不是很全的文章,大神请绕行. 在项目中我们或多或少的会遇到数据导出到excel表格以便线下查看或者记录一些 ...
- Python_marshal模块操作二进制文件
import marshal #导入模块 x1=30 #待序列化的对象 x2=5.0 x3=[1,2,3] x4=(4,5,6) x5={'a':1,'b':2,'c':3} x6={7,8,9} x ...
- PAT1093: Count PAT's
1093. Count PAT's (25) 时间限制 120 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CAO, Peng The strin ...
- 并行(Parallelism)与并发(Concurrency)
并行(Parallelism):多任务在同一时刻运行.例如,多个任务在多核处理器上运行. 并发(Concurrency):两个或者两个以上的任务在一段时间内开始.运行.完成,这意味着它们不是在同一时刻 ...
- SSM-Spring-18:Spring中aspectJ的XML版
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- aspectJ的xml版是开发中最常用的: 下面直接已案例入手,毕竟繁琐的日子不多了 案例:两个接口,俩个实现 ...
- linux ubuntukylin和deepin操作系统的比较及改进方向的建议
研发中国的操作系统的需求在我看来是安全,还有就是自主.如果做的好还可以在创新上,使用体验上进行一波超越.现有的所谓的国产操作系统我了解的除了基于安卓的凤凰系统就是基于Linux的像优麒麟和deepin ...