【深度学习】--GAN从入门到初始
一、前述
GAN,生成对抗网络,在2016年基本火爆深度学习,所有有必要学习一下。生成对抗网络直观的应用可以帮我们生成数据,图片。
二、具体
1、生活案例
比如假设真钱 r
坏人定义为G 我们通过 G 给定一个噪音X 通过学习一组参数w 生成一个G(x),转换成一个真实的分布。 这就是生成,相当于造假钱。
警察定义为D 将G(x)和真钱r 分别输入给判别网络,能判别出真假,真钱判别为0,假钱判别为1 。这就是判别。
最后生成网络想让判别网络判别不出来什么是真实的,什么是假的。要想生成的更好,则判别的就必须更强。有些博弈的思想,只有你强了,我才更强!!。
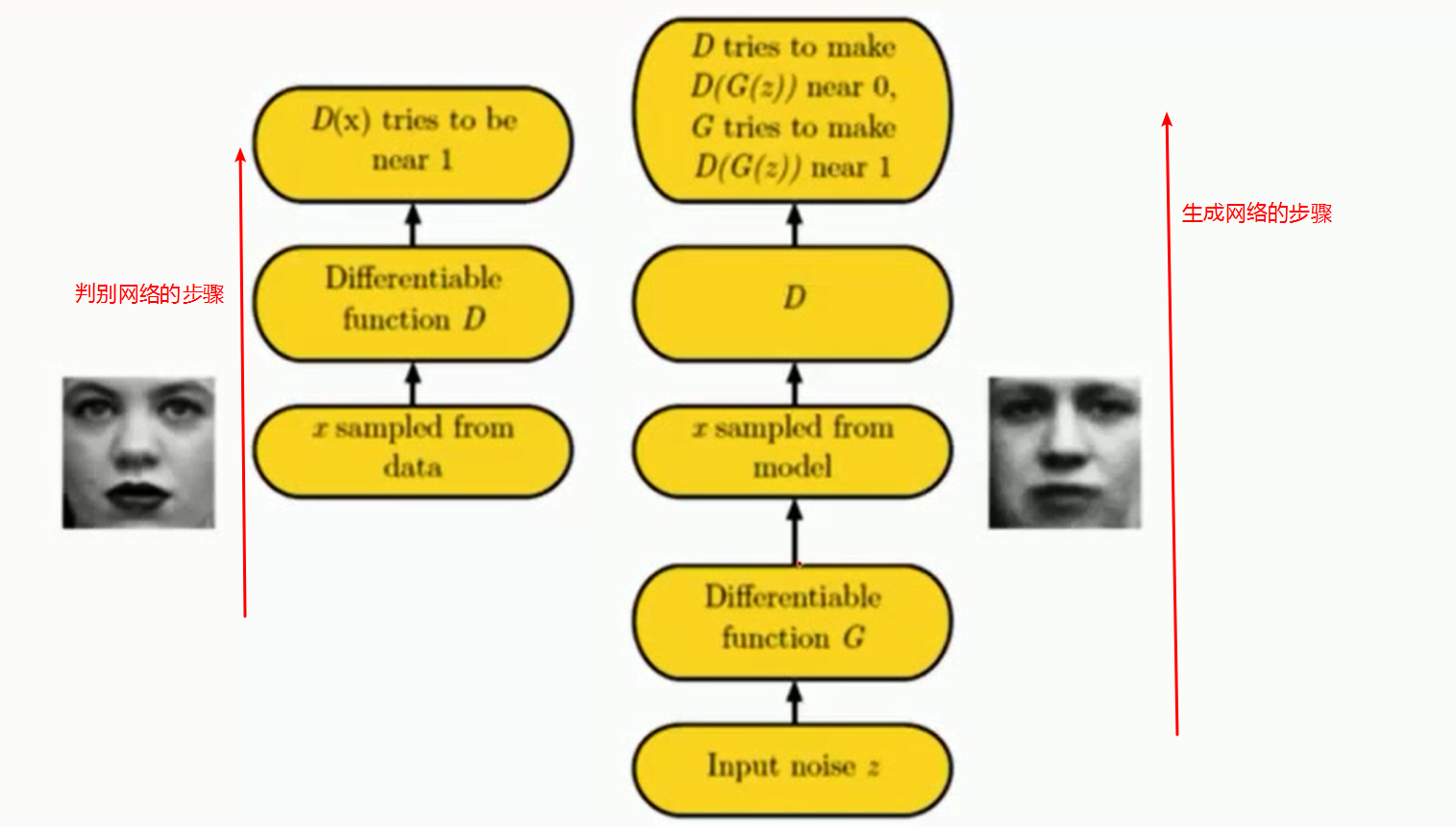
2、数学案例
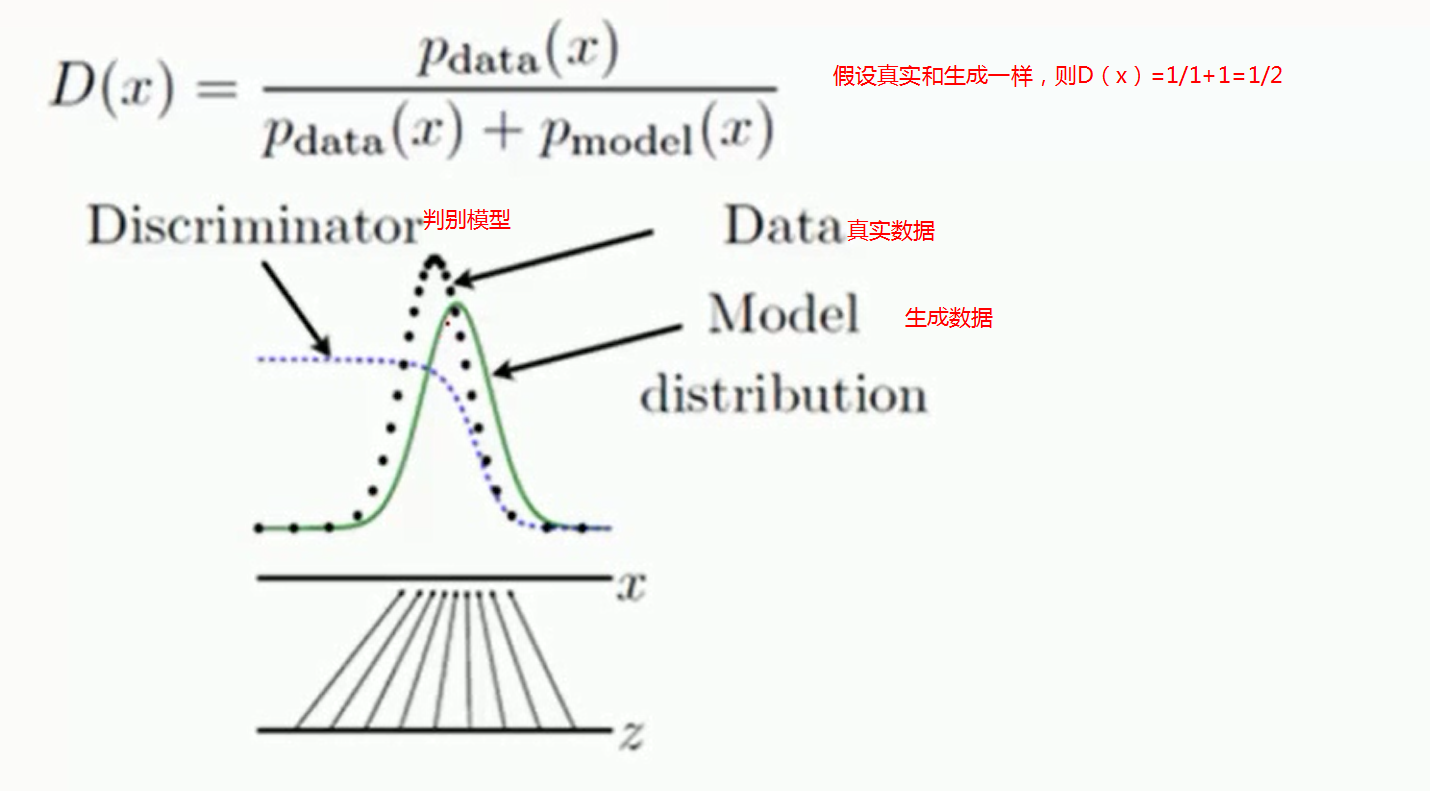
我们最后的希望。
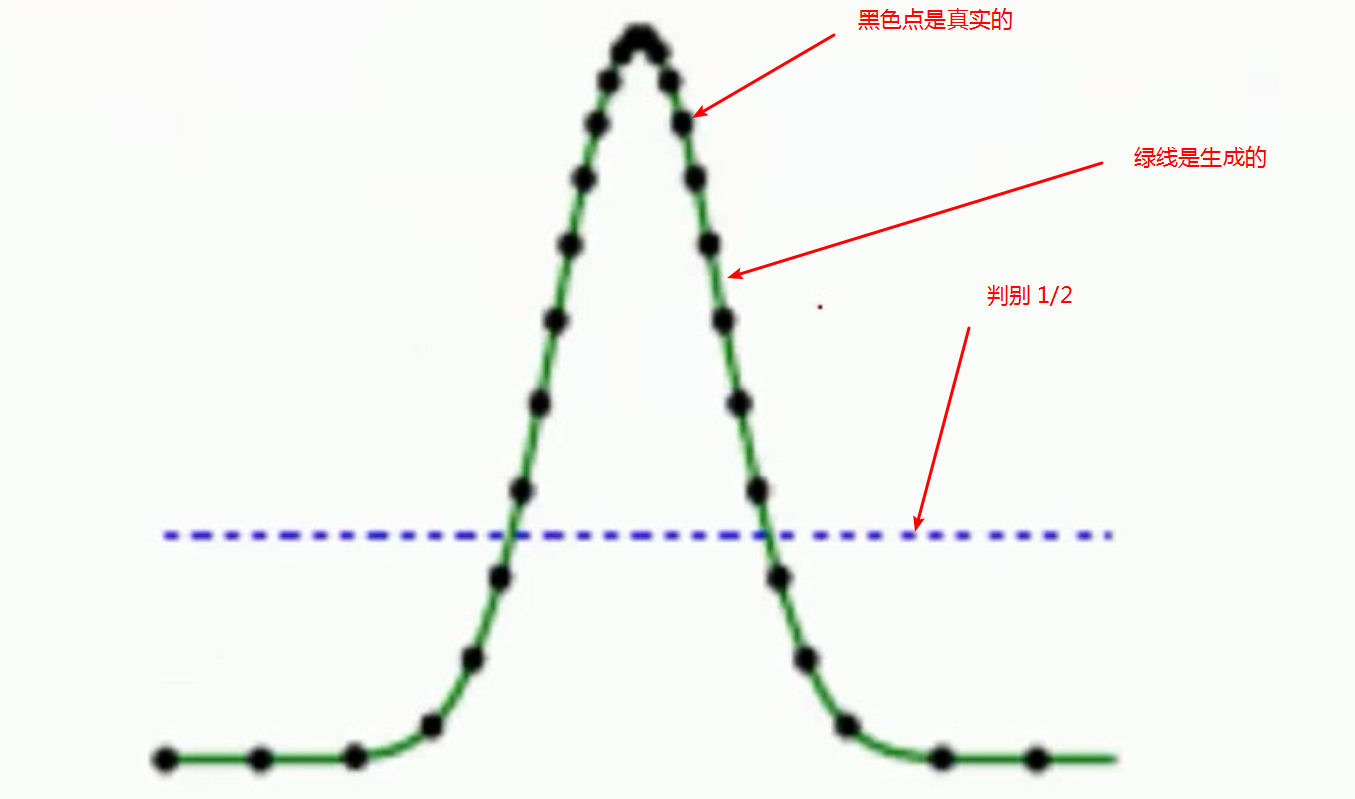
3、损失函数

4、代码案例
流程:
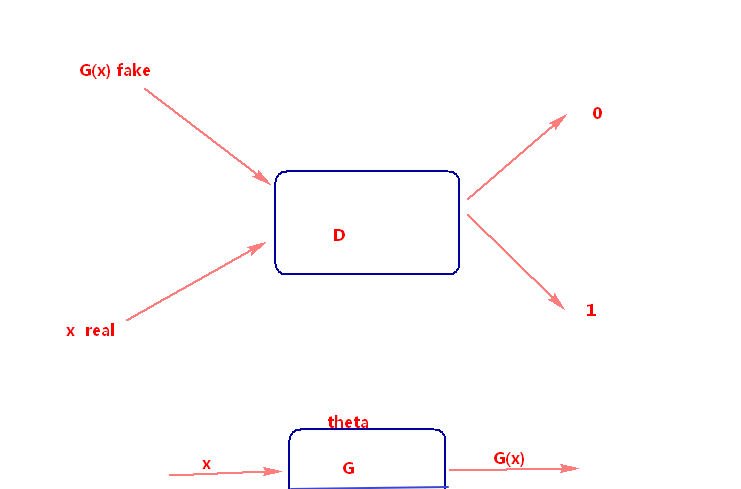
为了使判别模型更好,所以我们额外训练一个D_pre网络,使得判别模型能够判别出哪些是0,哪些是1,训练完之后会得到一组w,b参数。这样我们在真正初始化判别模型D的时候就能根据之前的D_pre来进行初始化。
代码:
import argparse
import numpy as np
from scipy.stats import norm
import tensorflow as tf
import matplotlib.pyplot as plt
from matplotlib import animation
import seaborn as sns sns.set(color_codes=True) seed = 42
np.random.seed(seed)
tf.set_random_seed(seed) class DataDistribution(object):
def __init__(self):
self.mu = 4#均值
self.sigma = 0.5#标准差 def sample(self, N):
samples = np.random.normal(self.mu, self.sigma, N)
samples.sort()
return samples class GeneratorDistribution(object):#在生成模型额噪音点,初始化输入
def __init__(self, range):
self.range = range def sample(self, N):
return np.linspace(-self.range, self.range, N) + \
np.random.random(N) * 0.01 def linear(input, output_dim, scope=None, stddev=1.0):
norm = tf.random_normal_initializer(stddev=stddev)
const = tf.constant_initializer(0.0)
with tf.variable_scope(scope or 'linear'):
w = tf.get_variable('w', [input.get_shape()[1], output_dim], initializer=norm)
b = tf.get_variable('b', [output_dim], initializer=const)
return tf.matmul(input, w) + b def generator(input, h_dim):
h0 = tf.nn.softplus(linear(input, h_dim, 'g0'))#12*1
h1 = linear(h0, 1, 'g1')
return h1#z最后的生成模型 def discriminator(input, h_dim):
h0 = tf.tanh(linear(input, h_dim * 2, 'd0'))#linear 控制初始化参数
h1 = tf.tanh(linear(h0, h_dim * 2, 'd1'))
h2 = tf.tanh(linear(h1, h_dim * 2, scope='d2')) h3 = tf.sigmoid(linear(h2, 1, scope='d3'))#最终的输出值 对判别网络输出
return h3 def optimizer(loss, var_list, initial_learning_rate):
decay = 0.95
num_decay_steps = 150#没迭代150次 学习率衰减一次0.95-150*0.95
batch = tf.Variable(0)
learning_rate = tf.train.exponential_decay(
initial_learning_rate,
batch,
num_decay_steps,
decay,
staircase=True
)
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(
loss,
global_step=batch,
var_list=var_list
)
return optimizer class GAN(object):
def __init__(self, data, gen, num_steps, batch_size, log_every):
self.data = data
self.gen = gen
self.num_steps = num_steps
self.batch_size = batch_size
self.log_every = log_every
self.mlp_hidden_size = 4#隐层神经元个数 self.learning_rate = 0.03#学习率 self._create_model() def _create_model(self): with tf.variable_scope('D_pre'):#构造D_pre模型骨架,预先训练,为了去初始化真正的判别模型
self.pre_input = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
self.pre_labels = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
D_pre = discriminator(self.pre_input, self.mlp_hidden_size)
self.pre_loss = tf.reduce_mean(tf.square(D_pre - self.pre_labels))
self.pre_opt = optimizer(self.pre_loss, None, self.learning_rate) # This defines the generator network - it takes samples from a noise
# distribution as input, and passes them through an MLP.
with tf.variable_scope('Gen'):#生成模型
self.z = tf.placeholder(tf.float32, shape=(self.batch_size, 1))#噪音的输入
self.G = generator(self.z, self.mlp_hidden_size)#最后的生成结果 # The discriminator tries to tell the difference between samples from the
# true data distribution (self.x) and the generated samples (self.z).
#
# Here we create two copies of the discriminator network (that share parameters),
# as you cannot use the same network with different inputs in TensorFlow.
with tf.variable_scope('Disc') as scope:#判别模型 不光接受真实的数据 还要接受生成模型的判别
self.x = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
self.D1 = discriminator(self.x, self.mlp_hidden_size)#真实的数据
scope.reuse_variables()#变量重用
self.D2 = discriminator(self.G, self.mlp_hidden_size)#生成的数据 # Define the loss for discriminator and generator networks (see the original
# paper for details), and create optimizers for both
self.loss_d = tf.reduce_mean(-tf.log(self.D1) - tf.log(1 - self.D2))#判别网络的损失函数
self.loss_g = tf.reduce_mean(-tf.log(self.D2))#生成网络的损失函数,希望其趋向于1 self.d_pre_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='D_pre')
self.d_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Disc')
self.g_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Gen') self.opt_d = optimizer(self.loss_d, self.d_params, self.learning_rate)
self.opt_g = optimizer(self.loss_g, self.g_params, self.learning_rate) def train(self):
with tf.Session() as session:
tf.global_variables_initializer().run() # pretraining discriminator
num_pretrain_steps = 1000#迭代次数,先训练D_pre ,先让其有一个比较好的初始化参数
for step in range(num_pretrain_steps):
d = (np.random.random(self.batch_size) - 0.5) * 10.0
labels = norm.pdf(d, loc=self.data.mu, scale=self.data.sigma)
pretrain_loss, _ = session.run([self.pre_loss, self.pre_opt], {#相当于一次迭代
self.pre_input: np.reshape(d, (self.batch_size, 1)),
self.pre_labels: np.reshape(labels, (self.batch_size, 1))
})
self.weightsD = session.run(self.d_pre_params)#相当于拿到之前的参数
# copy weights from pre-training over to new D network
for i, v in enumerate(self.d_params):
session.run(v.assign(self.weightsD[i]))#吧权重参数拷贝 for step in range(self.num_steps):#训练真正的生成对抗网络
# update discriminator
x = self.data.sample(self.batch_size)#真实的数据
z = self.gen.sample(self.batch_size)#随意的数据,噪音点
loss_d, _ = session.run([self.loss_d, self.opt_d], {#D两种输入真实,和生成的
self.x: np.reshape(x, (self.batch_size, 1)),
self.z: np.reshape(z, (self.batch_size, 1))
}) # update generator
z = self.gen.sample(self.batch_size)#G网络
loss_g, _ = session.run([self.loss_g, self.opt_g], {
self.z: np.reshape(z, (self.batch_size, 1))
}) if step % self.log_every == 0:
print('{}: {}\t{}'.format(step, loss_d, loss_g))
if step % 100 == 0 or step==0 or step == self.num_steps -1 :
self._plot_distributions(session) def _samples(self, session, num_points=10000, num_bins=100):
xs = np.linspace(-self.gen.range, self.gen.range, num_points)
bins = np.linspace(-self.gen.range, self.gen.range, num_bins) # data distribution
d = self.data.sample(num_points)
pd, _ = np.histogram(d, bins=bins, density=True) # generated samples
zs = np.linspace(-self.gen.range, self.gen.range, num_points)
g = np.zeros((num_points, 1))
for i in range(num_points // self.batch_size):
g[self.batch_size * i:self.batch_size * (i + 1)] = session.run(self.G, {
self.z: np.reshape(
zs[self.batch_size * i:self.batch_size * (i + 1)],
(self.batch_size, 1)
)
})
pg, _ = np.histogram(g, bins=bins, density=True) return pd, pg def _plot_distributions(self, session):
pd, pg = self._samples(session)
p_x = np.linspace(-self.gen.range, self.gen.range, len(pd))
f, ax = plt.subplots(1)
ax.set_ylim(0, 1)
plt.plot(p_x, pd, label='real data')
plt.plot(p_x, pg, label='generated data')
plt.title('1D Generative Adversarial Network')
plt.xlabel('Data values')
plt.ylabel('Probability density')
plt.legend()
plt.show()
def main(args):
model = GAN(
DataDistribution(),
GeneratorDistribution(range=8),
args.num_steps,
args.batch_size,
args.log_every,
)
model.train() def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--num-steps', type=int, default=1200,
help='the number of training steps to take')
parser.add_argument('--batch-size', type=int, default=12,
help='the batch size')
parser.add_argument('--log-every', type=int, default=10,
help='print loss after this many steps')
return parser.parse_args() if __name__ == '__main__':
main(parse_args())
结果:
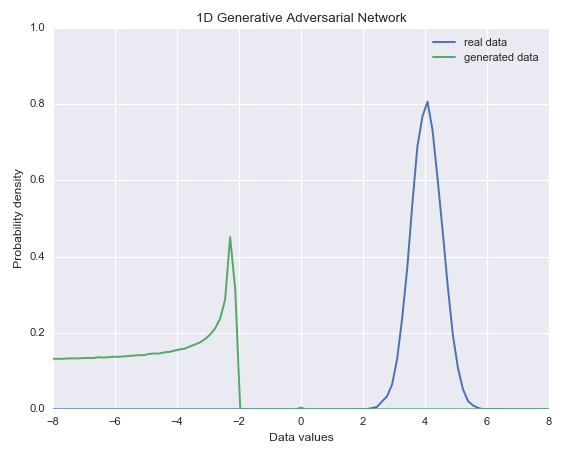
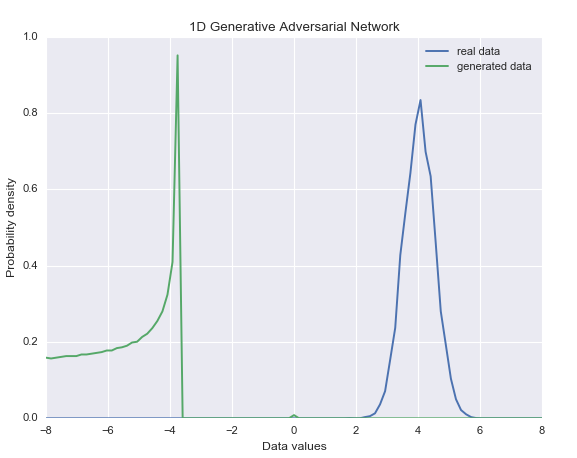
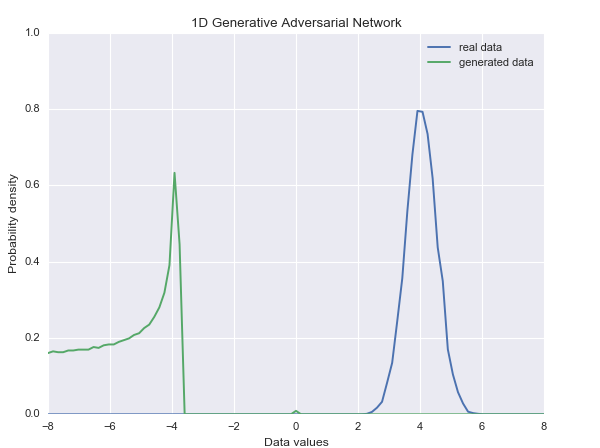
迭代到最后时候可以看到结果越来越类似。
【深度学习】--GAN从入门到初始的更多相关文章
- 腾讯QQ会员技术团队:人人都可以做深度学习应用:入门篇(下)
四.经典入门demo:识别手写数字(MNIST) 常规的编程入门有"Hello world"程序,而深度学习的入门程序则是MNIST,一个识别28*28像素的图片中的手写数字的程序 ...
- 【腾讯Bugly干货分享】人人都可以做深度学习应用:入门篇
导语 2016年,继虚拟现实(VR)之后,人工智能(AI)的概念全面进入大众的视野.谷歌,微软,IBM等科技巨头纷纷重点布局,AI 貌似将成为互联网的下一个风口. 很多开发同学,对人工智能非常感兴趣, ...
- 分享《机器学习实战基于Scikit-Learn和TensorFlow》中英文PDF源代码+《深度学习之TensorFlow入门原理与进阶实战》PDF+源代码
下载:https://pan.baidu.com/s/1qKaDd9PSUUGbBQNB3tkDzw <机器学习实战:基于Scikit-Learn和TensorFlow>高清中文版PDF+ ...
- 萌新深度学习与Pytorch入门记录(一):Win10下环境安装
深度学习从入门到入土,安装软件及配置环境踩了不少坑,过程中参考了多处博主给的解决方法,遂整合一下自己的采坑记录. (若遇到不一样的错误,请参考其他博主答案解决) 笔者电脑系统为win10系统,在此环境 ...
- 深度学习:Keras入门(一)之基础篇
1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorflow的深度学习框架. Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结 ...
- 深度学习、图像识别入门,从VGG16卷积神经网络开始
刚开始接触深度学习.卷积神经网络的时候非常懵逼,不知道从何入手,我觉得应该有一个进阶的过程,也就是说,理应有一些基本概念作为奠基石,让你有底气去完全理解一个庞大的卷积神经网络: 本文思路: 一.我认为 ...
- 深度学习:Keras入门(一)之基础篇【转】
本文转载自:http://www.cnblogs.com/lc1217/p/7132364.html 1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorfl ...
- 深度学习:Keras入门(一)之基础篇(转)
转自http://www.cnblogs.com/lc1217/p/7132364.html 1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorflow的深 ...
- 总结笔记 | 深度学习之Pytorch入门教程
笔记作者:王博Kings 目录 一.整体学习的建议 1.1 如何成为Pytorch大神? 1.2 如何读Github代码? 1.3 代码能力太弱怎么办? 二.Pytorch与TensorFlow概述 ...
随机推荐
- jQuery学习之旅 Item4 细说DOM操作
jQuery-–DOM操作(文档处理) Dom是Document Object Model的缩写,意思是文档对象模型.DOM是一种与浏览器.平台.语言无关的接口,使用该接口可以轻松访问页面中所有的标准 ...
- sublime安装AngularJS插件
sublime能够支持AngularJS开发那绝对是一件很爽的事情.下面我一步步讲解如何为sublime安装AngularJS插件. 1.添加控制包站点 根据你安装sublime 版本不同,在控制台写 ...
- Android SlidingMenu 使用详解
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/36677279 很多APP都有侧滑菜单的功能,部分APP左右都是侧滑菜单~Slid ...
- python assert的作用
使用assert断言是学习python一个非常好的习惯,python assert 断言句语格式及用法很简单.在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行最崩溃,不如在出现错误条件 ...
- [论文解读]CNN网络可视化——Visualizing and Understanding Convolutional Networks
概述 虽然CNN深度卷积网络在图像识别等领域取得的效果显著,但是目前为止人们对于CNN为什么能取得如此好的效果却无法解释,也无法提出有效的网络提升策略.利用本文的反卷积可视化方法,作者发现了AlexN ...
- 在 Java 中运用动态挂载实现 Bug 的热修复
大多数 JVM 具备 Java 的 HotSwap 特性,大部分开发者认为它仅仅是一个调试工具.利用这一特性,有可能在不重启 Java 进程条件下,改变 Java 方法的实现.典型的例子是使用 IDE ...
- bzoj 1485 [HNOI2009]有趣的数列 卡特兰数
把排好序的序列看成一对对括号,要把他们往原数列里塞,所以就是括号序合法方案数 即为卡特兰数 f(n)=Cn2nn+1 求的时候为避免除法,可以O(n)计算每个素数出现次数,最后乘起来,打完之后发现其实 ...
- 我和Python的Py交易》》》》》》数据类型
Python里的变量 ---门牌 Python在使用变量之前无须定义它的类型,但是必须声明以及初始化该变量. Python中给变量赋值就是声明,初始化变量(也就是创建一个相应数据类型的对象,而那些数据 ...
- 实战经验丨CTF中文件包含的技巧总结
站在巨人的肩头才会看见更远的世界,这是一篇技术牛人对CTF比赛中文件包含的内容总结,主要是对一些包含点的原理和特征进行归纳分析,并结合实际的例子来讲解如何绕过,全面细致,通俗易懂,掌握这个新技能定会让 ...
- Python猫荐书系列:文也深度学习,理也深度学习
最近出了两件大新闻,相信大家可能有所耳闻. 我来当个播报员,给大家转述一下: 1.中国队在第 11 界罗马尼亚数学大师赛(RMM)中无缘金牌.该项赛事是三大国际赛事之一,被誉为中学奥数的最高难度.其中 ...