分布式缓存一致性hash算法理解
今天阅读了一下大型网络技术架构这本苏中的分布式缓存一致性hash算法这一节,针对大型分布式系统来说,缓存在该系统中必不可少,分布式集群环境中,会出现添加缓存节点的需求,这样需要保障缓存服务器中对缓存的命中率,就有很大的要求了:
采用普通方法,将key值进行取hash后对分布式缓存机器数目进行取余,以集群3台分布式缓存为例子:
对于数据进行取hash值然后对3其进行取余,余数为0则进入node 0,余数位1则进入node1,余数位2则进入node2.
如果增加一个节点则对4进行取余,则会将node0中的部分,node1中的部分,node2中的部分分割到node3中,则出现了命中率为75%
如果增加2个节点的话则对5进行取余,则只有3/5的机器被命中
普通方法的设计会导致当你的节点添加的数目越多,导致你的命中率越低导致对数据库的操作压力就越大
采用一致性Hash算法:
构造一个0~2^32的整数环,然后将节点的名称比如说node0对其进行取hash值将其分布在该店上,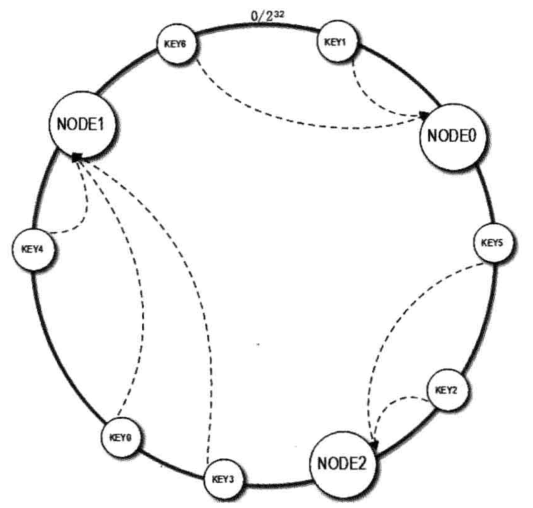
然后将key值取hash值后进行比较:
举例:node0的hash值为432323232;node1 hash值为879798098,则如果key1的hash值为559798098,则其大于node0的hashi值,则顺时针旋转,找到了node1则将其存放在node1中的缓存中。
扩容后,将三个变成4个
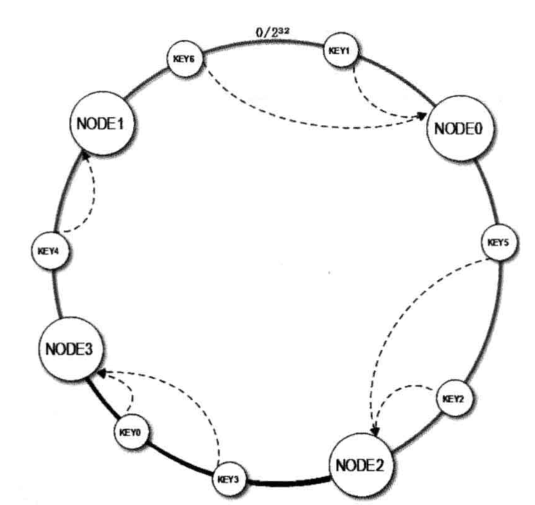
在node2和node0中插入一个node3,则导致node2到node1中中原先存放在node1中的数据分成两半,node2-node3部分存放在node3中,node3和node1的存放在node1中,则可以看出node0-node2以及node0-node1中这段没有改变。则也是75%但是还有问题就是node2和node0的负载数是node2的一倍,所以还是得出现解决办法
引用虚拟的方式:将一个物理分布式缓存服务器分层n个虚拟机,分布在这个圆环周围,由于hash散列的不规则性,他会分布于不同的区域,见下图,如果再次插入新服务器之后,他会在器分布的虚拟机器上不规则的分布于各个点中,则会比较均匀的分布在各个环中,这样影响的可以将上面的问题解决了。

根据该书说明,在实践中,一台物理服务器虚拟成150个虚拟服务器节点合适。
分布式缓存一致性hash算法理解的更多相关文章
- 分布式缓存一致性hash算法
当服务器不多,并且不考虑扩容的时候,可直接使用简单的路由算法,用服务器数除缓存数据KEY的hash值,余数作为服务器下标即可. 但是当业务发展,网站缓存服务需要扩容时就会出现问题,比如3台缓存服务器要 ...
- redis一致性hash算法理解
一般算法: 对对象先hash然后对redis数量取模,如果结果是0就存在0的节点上. 1.2同上,假设有0-3四个redis节点.20个数据: 进行取模后分布如下: 现在因为压力过大需要扩容,增加一台 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- Nginx+Memcache+一致性hash算法 实现页面分布式缓存(转)
网站响应速度优化包括集群架构中很多方面的瓶颈因素,这里所说的将页面静态化.实现分布式高速缓存就是其中的一个很好的解决方案... 1)先来看看Nginx负载均衡 Nginx负载均衡依赖自带的 ngx_h ...
- 分布式缓存设计:一致性Hash算法
缓存作为数据库前的一道屏障,它的可用性与缓存命中率都会直接影响到数据库,所以除了配置主从保证高可用之外还需要设计分布式缓存来扩充缓存的容量,将数据分布在多台机器上如果有一台不可用了对整体影响也比较小. ...
- 一致性Hash算法在Redis分布式中的使用
由于redis是单点,但是项目中不可避免的会使用多台Redis缓存服务器,那么怎么把缓存的Key均匀的映射到多台Redis服务器上,且随着缓存服务器的增加或减少时做到最小化的减少缓存Key的命中率呢? ...
- 分布式一致性hash算法
写在前面 在学习Redis的集群内容时,看到这么一句话:Redis并没有使用一致性hash算法,而是引入哈希槽的概念.而分布式缓存Memcached则是使用分布式一致性hash算法来实现分布式存储. ...
- 7.redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?
作者:中华石杉 面试题 redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗? 面试官心理分析 在前几年, ...
随机推荐
- 在Word2010文档中显示域代码而非域值
当Word2010文档中含有域内容时,默认情况下显示域值,这样可以使插入的域内容清晰明了.用户可以根据需要选择显示域代码或显示域值,操作步骤如下所述: 步骤/方法 第1步,打开Word2010文档窗口 ...
- 2.supervisor实时监控程序存活状态
1.supervisor是一款python开发的一个client/server服务,是一款进程管理工具,支持linux/unix系统,但是不支持windows系统. 它可以很方便的监听.启动.停止.重 ...
- WEB前端大神之路之基础篇
CSS篇: 1.CSS权重: 不重复造轮子啦,直接传送门(CSS选择器的权重与优先规则) JavaScript篇: 1.this关键字: 它是一种引用(referent).指向的是当前上下文(cont ...
- HierarchyID 数据类型用法
树形层次结构(Hierarchy)经常出现在有结构的数据中,T-SQL新增数据类型HierarchyID, 其长度可变,用于存储层次结构中的路径.HierarchyID表示的层次结构是树形的,由应用程 ...
- Django_生产环境静态文件配置
需求: 当Django项目运行在线上的时候,需要关闭debug模式,那么Django设置中,静态文件路径配置将会失效,如何解决这个问题? 问题原因: Django默认关闭debug模式,Django错 ...
- Windows脚本相关
1 获取IP地址 echo StartChangeIPFile echo 获取主机名 for /f %%i in ('hostname') do (set pcName=%%i) ::ping %pc ...
- TOMCAT原理详解及请求过程
Tomcat: Tomcat是一个JSP/Servlet容器.其作为Servlet容器,有三种工作模式:独立的Servlet容器.进程内的Servlet容器和进程外的Servlet容器. Tomcat ...
- 关于HDPHP,HDCMS 安装,空白问题
这几天,框论坛发现,HDPHP,号称还不错. 微信,支付宝支付,短信,阿里云OSS,权限认证等,都有.对开发人员来说很好了.. 马上下载来试试, HDPHP官方文档说需要PHP5.6,不过貌似我5.5 ...
- Python CRM项目七
仿照Django Admin实现对readonly的字段进行设置 功能点: 1.页面不可进行更改 2.如果改变html代码中的值,则需要进行后端的数据库数据校验 3.可以对某些字段进行自定制校验规则 ...
- iOS-Mac远程连接控制Window【苹果电脑远程连接控制Windows电脑】
用Mac电脑时想远程控制Windows电脑,摸索了半天搞定了 1.下载Mac远程控制安装包:http://pan.baidu.com/s/1o7ZsDQy 提取密码:r2ja 2.安装好之后打开,就 ...