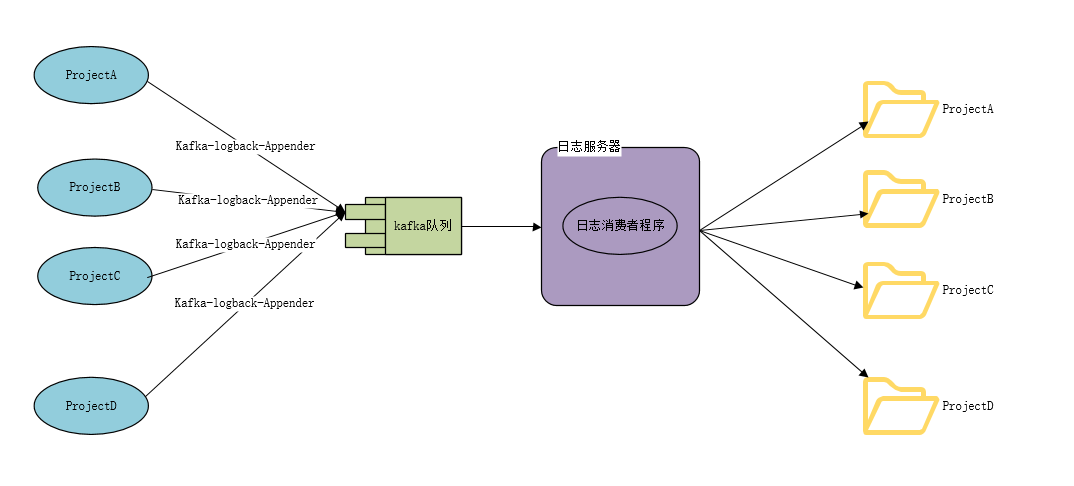
logback KafkaAppender 写入Kafka队列,集中日志输出.
为了减少应用服务器对磁盘的读写,以及可以集中日志在一台机器上,方便使用ELK收集日志信息,所以考虑做一个jar包,让应用集中输出日志
Redis 自定义 RedisAppender 插件, 实现日志缓冲队列,集中日志输出.
网上搜了一圈,只发现有人写了个程序在github
地址:https://github.com/johnmpage/logback-kafka
Redis 自定义 RedisAppender 插件, 实现日志缓冲队列,集中日志输出.
本来打算引用一下这个jar就完事了,没想到在pom里下不下来,只好把源码下了,拷贝了代码过来,自己修改一下.
首先,安装一个Kafka,作为一个懒得出神入化得程序员,我选择的安装方式是
启动zookeeper容器
docker run -d --name zookeeper --net=host -t wurstmeister/zookeeper
启动kafka容器
docker run --name kafka -d -e HOST_IP=192.168.1.7 --net=host -v /usr/local/docker/kafka/conf/server.properties:/opt/kafka_2.-1.0./config/server.properties -v /etc/localtime:/etc/localtime:ro -e KAFKA_ADVERTISED_PORT= -e KAFKA_BROKER_ID= -t wurstmeister/kafka
要修改Kafka的server.properties 中zookeeper配置
配置文件如下
listeners=PLAINTEXT://192.168.1.7:9092
delete.topic.enable=true
advertised.listeners=PLAINTEXT://192.168.1.7:9092
num.network.threads=
num.io.threads=
socket.send.buffer.bytes=
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=
log.dirs=/kafka/kafka-logs-92cfb0bbd88c
num.partitions=
num.recovery.threads.per.data.dir=
offsets.topic.replication.factor=
transaction.state.log.replication.factor=
transaction.state.log.min.isr=
log.retention.hours=
log.retention.bytes=
log.segment.bytes=
log.retention.check.interval.ms=
zookeeper.connect=192.168.1.7:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=
group.initial.rebalance.delay.ms=
version=1.0.

启动好了,新建SpringBoot项目,首先消费队列的
pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion>
<groupId>com.lzw</groupId>
<artifactId>kafkalog</artifactId>
<version>0.0.-SNAPSHOT</version>
<packaging>jar</packaging> <name>kafkalog</name>
<description>Demo project for Spring Boot</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0..M6</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</project>
程序结构
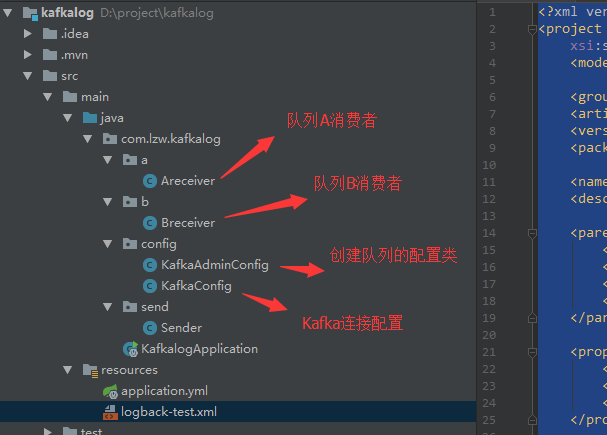
KafkaConfig
package com.lzw.kafkalog.config;
/**
* Created by laizhenwei on 2017/11/28
*/
@Configuration
@EnableKafka
public class KafkaConfig { @Value("${spring.kafka.consumer.bootstrap-servers}")
private String consumerBootstrapServers; @Value("${spring.kafka.producer.bootstrap-servers}")
private String producerBootstrapServers; @Bean
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>>
kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(3);
factory.getContainerProperties().setPollTimeout(3000);
return factory;
}
@Bean
public ConsumerFactory<Integer, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
} @Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, consumerBootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "foo");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
} @Bean
public Areceiver areceiver() {
return new Areceiver();
} @Bean
public Breceiver breceiver(){
return new Breceiver();
}
}
KafkaAdminConfig
package com.lzw.kafkalog.config; import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.KafkaAdmin; import java.util.HashMap;
import java.util.Map; /**
* Created by laizhenwei on 2017/11/28
*/
@Configuration
public class KafkaAdminConfig { @Value("${spring.kafka.producer.bootstrap-servers}")
private String producerBootstrapServers; @Bean
public KafkaAdmin admin() {
Map<String, Object> configs = new HashMap<>();
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,producerBootstrapServers);
return new KafkaAdmin(configs);
} /**
* 创建队列A,1个分区
* @return
*/
@Bean
public NewTopic a() {
return new NewTopic("A", 1, (short) 1);
} /**
* 创建队列B,1个分区
* @return
*/
@Bean
public NewTopic b() {
return new NewTopic("B", 1, (short) 1);
}
}
B队列消费者
package com.lzw.kafkalog.b; import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener; /**
* Created by laizhenwei on 2017/11/28
*/
public class Breceiver {
Logger logger = LoggerFactory.getLogger(this.getClass());
@KafkaListener(topics={"B"})
public void listen(ConsumerRecord data) {
logger.info(data.value().toString());
}
}
application.yml
spring:
kafka:
consumer:
bootstrap-servers: 192.168.1.7:9092
producer:
bootstrap-servers: 192.168.1.7:9092
logback-test.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="true">
<contextName>logback</contextName>
<property name="LOG_HOME" value="F:/log" />
<appender name="aAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/a/a.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/a/a-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<!--<fileNamePattern>${LOG_HOME}/a/a-%d{yyyy-MM-dd}.%i.tar.gz</fileNamePattern>-->
<!-- 日志文件保留天数 -->
<MaxHistory>30</MaxHistory>
<!-- 文件大小触发重写新文件 -->
<MaxFileSize>100MB</MaxFileSize>
<totalSizeCap>10GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender> <appender name="bAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/b/b.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/b/b-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<!--<fileNamePattern>${LOG_HOME}/b/b-%d{yyyy-MM-dd}.%i.tar.gz</fileNamePattern>-->
<!-- 日志文件保留天数 -->
<MaxHistory>30</MaxHistory>
<!-- 文件大小触发重写新文件 -->
<MaxFileSize>100MB</MaxFileSize>
<totalSizeCap>10GB</totalSizeCap>
</rollingPolicy> <encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender> <!--异步输出-->
<appender name="aAsyncFile" class="ch.qos.logback.classic.AsyncAppender">
<discardingThreshold>0</discardingThreshold>
<queueSize>2048</queueSize>
<appender-ref ref="aAppender" />
</appender> <logger name="com.lzw.kafkalog.a" level="INFO" additivity="false">
<appender-ref ref="aAsyncFile" />
</logger> <!--异步输出-->
<appender name="bAsyncFile" class="ch.qos.logback.classic.AsyncAppender">
<discardingThreshold>0</discardingThreshold>
<queueSize>2048</queueSize>
<appender-ref ref="bAppender" />
</appender>
<logger name="com.lzw.kafkalog.b" level="INFO" additivity="false">
<appender-ref ref="bAsyncFile" />
</logger> </configuration>
消费者程序,重点是红框部分
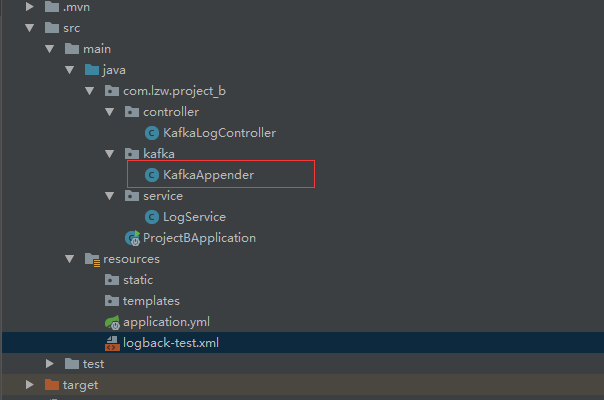
红框源码,本来想做个容错,后来发现不行,原因等下再说
package com.lzw.project_b.kafka; import ch.qos.logback.core.AppenderBase;
import ch.qos.logback.core.Layout;
import ch.qos.logback.core.status.ErrorStatus;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; import java.io.StringReader;
import java.util.Properties; public class KafkaAppender<E> extends AppenderBase<E> { protected Layout<E> layout;
private static final Logger LOGGER = LoggerFactory.getLogger("local");
private boolean logToLocal = false;
private String kafkaProducerProperties;
private String topic;
private KafkaProducer producer; public void start() {
super.start();
int errors = 0;
if (this.layout == null) {
this.addStatus(new ErrorStatus("No layout set for the appender named \"" + this.name + "\".", this));
++errors;
} if (errors == 0) {
super.start();
} LOGGER.info("Starting KafkaAppender...");
final Properties properties = new Properties();
try {
properties.load(new StringReader(kafkaProducerProperties));
producer = new KafkaProducer<>(properties);
} catch (Exception exception) {
System.out.println("KafkaAppender: Exception initializing Producer. " + exception + " : " + exception.getMessage());
}
System.out.println("KafkaAppender: Producer initialized: " + producer);
if (topic == null) {
System.out.println("KafkaAppender requires a topic. Add this to the appender configuration.");
} else {
System.out.println("KafkaAppender will publish messages to the '" + topic + "' topic.");
}
LOGGER.info("kafkaProducerProperties = {}", kafkaProducerProperties);
LOGGER.info("Kafka Producer Properties = {}", properties);
if (logToLocal) {
LOGGER.info("KafkaAppender: kafkaProducerProperties = '" + kafkaProducerProperties + "'.");
LOGGER.info("KafkaAppender: properties = '" + properties + "'.");
}
} @Override
public void stop() {
super.stop();
LOGGER.info("Stopping KafkaAppender...");
producer.close();
} @Override
protected void append(E event) {
/**
* 源码这里是用Formatter类转为JSON
*/
String msg = layout.doLayout(event);
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topic, msg);
producer.send(producerRecord);
} public String getTopic() {
return topic;
} public void setTopic(String topic) {
this.topic = topic;
} public boolean getLogToLocal() {
return logToLocal;
} public void setLogToLocal(String logToLocal) {
if (Boolean.valueOf(logToLocal)) {
this.logToLocal = true;
}
} public void setLayout(Layout<E> layout) {
this.layout = layout;
} public String getKafkaProducerProperties() {
return kafkaProducerProperties;
} public void setKafkaProducerProperties(String kafkaProducerProperties) {
this.kafkaProducerProperties = kafkaProducerProperties;
}
}
LogService就记录一段长的垃圾日志
package com.lzw.project_b.service; import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component; /**
* Created by laizhenwei on 2017/12/1
*/
@Component
public class LogService {
Logger logger = LoggerFactory.getLogger(this.getClass()); private static final String msg = "asdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfa" +
"sdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdf" +
"sadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfa" +
"sdfsadfasdfsadfasdfsaasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsa" +
"dfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadf" +
"asdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfas" +
"dfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsa" +
"dfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfas" +
"dfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadf" +
"sdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfa" +
"sdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsadfasdfsa"; public void dolog() {
logger.info(msg, new RuntimeException(msg));
} }
KafkaLogController就一个很无聊的输出日志请求,并记录入队时间
package com.lzw.project_b.controller; import com.lzw.project_b.service.LogService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; /**
* Created by laizhenwei on 2017/11/29
*/
@RestController
@RequestMapping(path = "/kafka")
public class KafkaLogController { @Autowired
private LogService logService; @GetMapping(path = "/aa")
public void aa() {
long begin = System.nanoTime();
for (int i = 0; i < 100000; i++) {
logService.dolog();
}
long end = System.nanoTime(); System.out.println((end - begin) / 1000000);
} }
启动两个程序,来一个请求

查看耗时
生产者的 logback-test.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="true">
<appender name="KAFKA" class="com.lzw.project_b.kafka.KafkaAppender">
<topic>B</topic>
<kafkaProducerProperties>
bootstrap.servers=192.168.1.7:9092
retries=0
value.serializer=org.apache.kafka.common.serialization.StringSerializer
key.serializer=org.apache.kafka.common.serialization.StringSerializer
<!--reconnect.backoff.ms=1-->
producer.type=async
request.required.acks=0
<!--acks=0-->
<!--producer.type=async -->
<!--request.required.acks=1 -->
<!--queue.buffering.max.ms=20000 -->
<!--queue.buffering.max.messages=1000-->
<!--queue.enqueue.timeout.ms = -1 -->
<!--batch.num.messages=8-->
<!--metadata.fetch.timeout.ms=3000-->
<!--producer.type=sync-->
<!--request.required.acks=1-->
<!--reconnect.backoff.ms=3000-->
<!--retry.backoff.ms=3000-->
</kafkaProducerProperties>
<logToLocal>true</logToLocal>
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n</pattern>
</layout>
</appender> 时间滚动输出 level为 monitor 日志
<appender name="localAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>F:/localLog/b/b.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>F:/localLog/b/b-%d{yyyy-MM-dd}.%i.tar.gz</fileNamePattern>
<!-- 日志文件保留天数 -->
<MaxHistory>30</MaxHistory>
<!-- 文件大小触发重写新文件 -->
<MaxFileSize>200MB</MaxFileSize>
<totalSizeCap>10GB</totalSizeCap>
</rollingPolicy> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n</pattern>
<charset>UTF-8</charset>
</encoder>
</appender> <appender name="asyncLocal" class="ch.qos.logback.classic.AsyncAppender">
<!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 -->
<discardingThreshold>0</discardingThreshold>
<queueSize>2048</queueSize>
<appender-ref ref="localAppender"/>
</appender> <!--万一kafka队列不通,记录到本地-->
<logger name="local" additivity="false">
<appender-ref ref="asyncLocal"/>
</logger> <!--<appender name="asyncKafka" class="ch.qos.logback.classic.AsyncAppender">-->
<!--<!– 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 –>-->
<!--<discardingThreshold>0</discardingThreshold>-->
<!--<queueSize>2048</queueSize>-->
<!--<appender-ref ref="KAFKA"/>-->
<!--</appender>--> <root level="INFO">
<appender-ref ref="KAFKA"/>
</root> </configuration>
关于为什么我没用有源码中的Json Formatter ,因为转换Json会花更多时间,性能更低.源码中是用了Json-simple,我换成了Gson,快了很多,但是还是有性能影响,如果非要转成Json
我选择在ELK中转,也不会在应用中耗时间去转
生产者之里,我用了最极端的one way 方式.吞吐量最高,但是无法得知是否已经入队.
这里生产者的程序里Logback 必须使用同步日志才能客观知道入队的耗时.
总结
容错:我尝试在生产者中写一段容错代码,一旦链接Kafka不通.或者队列不可写的时候,记录倒本地日志.关闭Kafka测试,生产者却阻塞了,一直重连,程序基本废了
找了很多方法,没有找到关闭重连的方式.
灵活性:相比起redis队列来说,Kafka就比较尴尬(例如我这个场景,还需要保证Kafka队列可用,性能没提升多少,还增加了维护成本)
性能:我在固态硬盘与机械硬盘中测试过,由于Kafka很懂机械硬盘,并且对顺序写入做了很大优化,在机械硬盘上表现比固态硬盘性能大概高30%,主打低成本?
入队的性能不怎么高,实际上还比不上直接写入本地(别忘了入队以后,在消费者那边还要写盘,队列也是持久化倒硬盘,等于写了两次盘)
用户体验:据说JAVA驱动还算是做得比较好的了
最后:不适合我的业务场景.也用得不深.最后我选择了redis做队列
我也没找到办法关闭Kafaka的持久化,写两次硬盘,某些情况日志并不是不可丢失(redis做队列很灵活,写不进队列的时候,可以写入本地硬盘),redis进的快消费快,内存基本不会有很大压力,cpu消耗也不高,个人认为在数据不是特别重要的情况下成本比Kafka还低,性能可是质的提升.
logback KafkaAppender 写入Kafka队列,集中日志输出.的更多相关文章
- Redis 自定义 RedisAppender 插件, 实现日志缓冲队列,集中日志输出.
因为某些异步日志设置了即使队列满了,也不可丢弃,在并发高的时候,导致请求方法同步执行,响应变慢. 编写这个玩意,除了集中日志输出以外,还希望在高并发的时间点有缓冲作用. 之前用Kafka实现了一次入队 ...
- springboot+logback日志输出企业实践(下)
目录 1.引言 2. 输出 logback 状态数据 3. logback 异步输出日志 3.1 异步输出配置 3.2 异步输出原理 4. springboot 多环境下 logback 配置 5. ...
- springboot+logback日志输出企业实践(上)
目录 1.引言 2.logback简介 3. springboot默认日志框架-logback 3.1 springboot示例工程搭建 3.2 日志输出与基本配置 3.2.1 日志默认输出 3.2. ...
- logback kafkaAppender输出日志到kafka
官网地址https://github.com/danielwegener/logback-kafka-appender 本文以spring boot项目为基础,更多的信息,请参考官网 https:// ...
- Logback 整合 RabbitMQ 实现统一日志输出
原文地址:Logback 整合 RabbitMQ 实现统一日志输出 博客地址:http://www.extlight.com 一.前言 公司项目做了集群实现请求分流,由于线上或多或少会出现请求失败或系 ...
- Flume 读取RabbitMq消息队列消息,并将消息写入kafka
首先是关于flume的基础介绍 组件名称 功能介绍 Agent代理 使用JVM 运行Flume.每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks. Client ...
- 2.logback+slf4j+janino 配置项目的日志输出
作者QQ:1095737364 QQ群:123300273 欢迎加入! 1.创建项目 参考:http://www.cnblogs.com/yysbolg/p/6898453.html 2 ...
- 使用Log4j将程序日志实时写入Kafka(转)
原文链接:使用Log4j将程序日志实时写入Kafka 很多应用程序使用Log4j记录日志,如何使用Kafka实时的收集与存储这些Log4j产生的日志呢?一种方案是使用其他组件(比如Flume,或者自己 ...
- java实时监听日志写入kafka(转)
原文链接:http://www.sjsjw.com/kf_cloud/article/020376ABA013802.asp 目的 实时监听某目录下的日志文件,如有新文件切换到新文件,并同步写入kaf ...
随机推荐
- __getattr__动态获取接口
# -*- coding:utf-8 -*- #在看廖雪峰的python3.5教学时,看到面向对象高级编程_定义类 https://www.liaoxuefeng.com/wiki/001431608 ...
- MySQL复制相关变量
server_id是必须设置在master和每个slave上的唯一标识ID,其取值范围 是1~4294967295之间,且同一个复制组之内不能重复 server_uuid:server_uuid会在G ...
- 几次面试后才弄懂的HashMap
本人大四,以前也开发过几个项目,Map相关集合也总用.但是从来没有研究过底层的实现,只知道杂用.结果在最开始的几次面试中一脸懵逼.认识到不足后,浅显的学习了一下,总结成一下几点.(如果写错了还望指正) ...
- iOS简单动画效果:闪烁、移动、旋转、路径、组合
#define kDegreesToRadian(x) (M_PI * (x) / 180.0) #define kRadianToDegrees(radian) (radian*180.0)/(M_ ...
- Tomcat8远程访问manager,host-manager被拒绝403
Tomcat部署在服务器之后在服务器本地访问manager和host-manager成功(即127.0.0.1:8080或者localhost:8080),但使用测试主机访问tomcat的manage ...
- LINUX文件定位
body, table{font-family: 微软雅黑; font-size: 10pt} table{border-collapse: collapse; border: solid gray; ...
- 轮询、长轮询、长连接、flash socket 的区别
轮询:客户端定时向服务器发送Ajax请求,服务器接到请求后马上返回响应信息并关闭连接. 优点:后端程序编写比较容易. 缺点:请求中有大半是无用,浪费带宽和服务器资源. 实例:适于小型应用. 长轮询:客 ...
- P1045 麦森数
别问我为什么要写水题 #include <iostream> #include <cstdio> #include <cstring> #include <a ...
- BZOJ 4276: [ONTAK2015]Bajtman i Okrągły Robin [线段树优化建边]
4276: [ONTAK2015]Bajtman i Okrągły Robin 题意:\(n \le 5000\)个区间\(l,r\le 5000\),每个区间可以选一个点得到val[i]的价值,每 ...
- SDP(5):ScalikeJDBC- JDBC-Engine:Streaming
作为一种通用的数据库编程引擎,用Streaming来应对海量数据的处理是必备功能.同样,我们还是通过一种Context传递产生流的要求.因为StreamingContext比较简单,而且还涉及到数据抽 ...