Kafka写入流程和副本策略
Kafka写入流程:
1.producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader
2. producer 将消息发送给该 leader
3. leader 将消息写入本地 log
4. followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
5. leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
副本策略:
Kafka的高可靠性的保障来源于其健壮的副本(replication)策略。
1) 数据同步
kafka在0.8版本前没有提供Partition的Replication机制,一旦Broker宕机,其上的所有Partition就都无法提供服务,而Partition又没有备份数据,数据的可用性就大大降低了。所以0.8后提供了Replication机制来保证Broker的failover。
引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。
[root@tourbis kafka_2.10-0.8.2.1]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2
Topic: test Partition: 1 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: test Partition: 2 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
1个Topic,3个分区,每个分区有3个副本。
2) 副本放置策略
为了更好的做负载均衡,Kafka尽量将所有的Partition均匀分配到整个集群上。Kafka分配Replica的算法如下:
将所有存活的N个Brokers和待分配的Partition排序
将第i个Partition分配到第(i mod n)个Broker上,这个Partition的第一个Replica存在于这个分配的Broker上,并且会作为partition的优先副本
将第i个Partition的第j个Replica分配到第((i + j-1) mod n)个Broker上
假设集群一共有4个brokers,一个topic有4个partition,每个Partition有3个副本。下图是每个Broker上的副本分配情况。
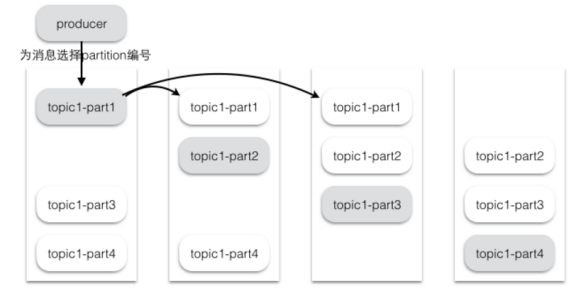
1 2 3 4
3)同步策略
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少,Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW【high watermark】并且向Producer发送ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。
Consumer读消息也是从Leader读取,只有被commit过的消息才会暴露给Consumer。
Kafka写入流程和副本策略的更多相关文章
- Kafka生产者----向kafka写入数据
开发者可以使用kafka内置的客户端API开发kafka应用程序.除了内置的客户端之外,kafka还提供了二进制连接协议,也就是说,我们直接向kafka网络端口发送适当的字节序列,就可以实现从Kafk ...
- Kafka工作流程分析
Kafka工作流程分析 生产过程分析 写入方式 producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘 ...
- 3、kafka工作流程
一.kafka各成员 kafka: 分布式消息系统,将消息直接存入磁盘,默认保存一周. broker: 组成kafka集群的节点,之间没有主从关系,依赖zookeeper来协调,broker负责满息的 ...
- Kafka工作流程
Kafka生产过程分析 1 写入方式 producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机 ...
- kafka学习(二)kafka工作流程分析
一.发送数据 follower的同步流程 PS:Producer在写入数据的时候永远的找leader,不会直接将数据写入follower PS:消息写入leader后,follower是主动的去lea ...
- Kafka权威指南 读书笔记之(三)Kafka 生产者一一向 Kafka 写入数据
不管是把 Kafka 作为消息队列.消息总线还是数据存储平台来使用 ,总是需要有一个可以往 Kafka 写入数据的生产者和一个从 Kafka 读取数据的消费者,或者一个兼具两种角色的应用程序. 开发者 ...
- kafka消息存储与partition副本原理
消息的存储原理: 消息的文件存储机制: 前面我们知道了一个 topic 的多个 partition 在物理磁盘上的保存路径,那么我们再来分析日志的存储方式.通过 ll /tmp/kafka-logs/ ...
- elasticsearch的数据写入流程及优化
Elasticsearch 写入流程及优化 一. 集群分片设置:ES一旦创建好索引后,就无法调整分片的设置,而在ES中,一个分片实际上对应一个lucene 索引,而lucene索引的读写会占用很多的系 ...
- Kafka 存储机制和副本
1.概述 Kafka 快速稳定的发展,得到越来越多开发者和使用者的青睐.它的流行得益于它底层的设计和操作简单,存储系统高效,以及充分利用磁盘顺序读写等特性,和其实时在线的业务场景.对于Kafka来说, ...
随机推荐
- Linux命令之创建文件夹3
1)mkdir fyr即可在当前目录下创建一个文件夹 2)在fyr文件夹下创建一个子目录 mkdir fyr/fyr1 注意:如果不存在父层目录直接创建对应父层目录下的子目录mkdir FYR/f ...
- 批处理实现虚拟WIFI
类似于360免费WiFi那个软件,可以PC发射WiFi(需要有无线网卡). 源码如下: @Echo off title Windows7 虚拟Wifi----By yllinux mode con c ...
- php:定义时间跳转到指定页面
我们想要定义延迟时间,再跳转到指定页面,只要用header()即可,语法: header("Refresh:延迟时间;url=要跳转的页面"); 例子: 注意注意:我们在heade ...
- eclipse快捷键(个人经常使用的)
周末闲来无聊,就把一直以来eclipse使用的快捷键梳理了下,希望对有需要的朋友有所帮助,绝对原创! 1.快速复制一行或者多行 首先选中你要复制的行,如果是一行,则鼠标焦点在那一行即可,如果是多行,可 ...
- css3弹性盒子
CSS3 弹性盒子(Flex Box) 弹性盒子是 CSS3 的一种新的布局模式. CSS3 弹性盒( Flexible Box 或 flexbox),是一种当页面需要适应不同的屏幕大小以及设备类型时 ...
- 卷积神经网络CNN在自然语言处理的应用
摘要:CNN作为当今绝大多数计算机视觉系统的核心技术,在图像分类领域做出了巨大贡献.本文从计算机视觉的用例开始,介绍CNN及其在自然语言处理中的优势和发挥的作用. 当我们听到卷积神经网络(Convol ...
- linux flushing file system caches
We may drop the file system caches on Linux to free up memory for applications. Kernels 2.6.16 and n ...
- @NotEmpty@NotNull和@NotBlank的区别
这几个可以为对象,不只是字符串 1.@NotNull 不能为null,但可以为empty (""," "," ") 2.@NotEmpty ...
- Git版本控制的原理
Git工作区域 工作目录(Working Directory) 暂存区(Stage/Index) 资源库(Repository或Git Directory) 远程的git仓库(Remote Direc ...
- Android 最新学习资料收集
收集这份资料的灵感来源于我的浏览器收藏夹快爆了,后来在github 上也看到了很优秀的开源库的收集资料,非常的好,但是太过于多,也不够新,所以决定自己来做一个.原始的markdowm文件已经放到git ...