机器学习:PCA(使用梯度上升法求解数据主成分 Ⅰ )
一、目标函数的梯度求解公式
- PCA 降维的具体实现,转变为:
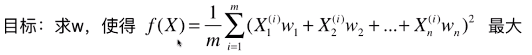
- 方案:梯度上升法优化效用函数,找到其最大值时对应的主成分 w ;
- 效用函数中,向量 w 是变量;
- 在最终要求取降维后的数据集时,w 是参数;
1)推导梯度求解公式
- 变形一
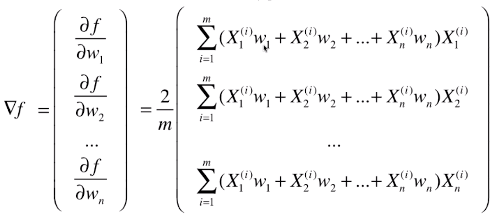
- 变形二
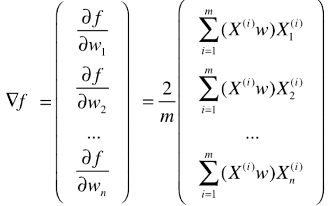
- 变形三:向量化处理
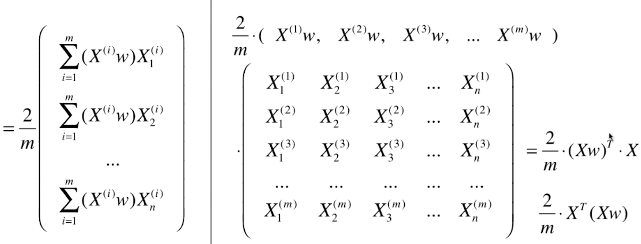
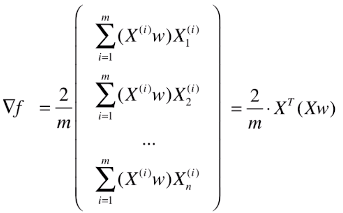
- 最终的梯度求解公式:▽f = 2 / m * XT . (X . dot(w) )
二、代码实现(以二维降一维为例)
1)模拟数据
import numpy as np
import matplotlib.pyplot as plt X = np.empty((100, 2))
X[:, 0] = np.random.uniform(0., 100., size=100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 10, size=100)
2)查看数据分布
plt.scatter(X[:, 0], X[:, 1])
plt.show()3)对原始数据集 demean 处理:得到新的数据集,数据集的每一种特征的均值都为 0
def demean(X):
return X - np.mean(X, axis=0) X_demean = demean(X)
- 数据集的每一个特征,都减去该列特征的均值,使得新的数据集的每一个特征的均值为 0;
- np.mean(X, axis=0):得到矩阵 X 每一列的均值,结果为一个列向量;
4)使用梯度上升法求解主成分
求当前参数 w 对应的目标函数值(按推导公式求解)
def f(w, X):
return np.sum((X.dot(w)**2)) / len(X)求当前参数 w 对应的梯度值(按推导公式求解)
def df_math(w, X):
return X.T.dot(X.dot(w))*2 / len(X)求当前参数 w 对应的梯度值(按调试公式求解)
def df_debug(w, X, epsilon=0.0001):
res = np.empty(len(w))
for i in range(len(w)):
w_1 = w.copy()
w_1[i] += epsilon
w_2 = w.copy()
w_2[i] -= epsilon
res[i] = (f(w_1, X) - f(w_2, X)) / (2 * epsilon)
return res将向量 w 转化为单位向量
def direction(w):
return w / np.linalg.norm(w)# 因为推导公式时人为的将 w 向量的模设为 1,如果不将 w 向量转化为单位向量,梯度上升法的搜索过程会不顺畅;
# np.linalg.norm(向量):求向量的模
# 向量 / 向量的模 == 单位向量梯度上升法的优化过程
def gradient_ascent(df, X, initial_w, eta, n_iters=10**4, epsilon=10**-8): # 将初始化的向量 initial_w 转化为单位向量
w = direction(initial_w)
cur_iter = 0 while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w += eta * gradient
# 注意1:将每一步优化后的向量 w 也转化为单位向量
w = direction(w)
if (abs(f(w, X) - f(last_w, X)) < epsilon):
break cur_iter += 1 return w# 注意1:每一步优化后的向量 w 都要转化为单位向量
5)求解数据的第一主成分
初始化
initial_w = np.random.random(X.shape[1])
eta = 0.001# 注意2:初始化 w 不能为 0 向量,因为在梯度公式中,若 w 为 0 ,无论什么数据,计算的结果都是没有任何方向的 0;
求解并绘制出第一主成分
w = gradient_ascent(df_math, X_demean, initial_w, eta) plt.scatter(X_demean[:,0], X_demean[:,1]) # 此处绘制直线,对应的两个点是(0, 0)、(w[0]*30, w[1]*30),构成了红色的直线
# 由于 w[0]、w[1]数值太小,为了让直线看的更清晰,将该点扩大 30 倍
# 这也是绘制向量的方法
plt.plot([0, w[0]*30], [0, w[1]*30], color='r')
plt.show()# 注意3:不能用 StandardScaler 标准化数据
# 原因:由于PCA的过程本身就是求一个轴,使得所有的样本映射到轴上之后方差最大,但是,如果对数据标准化后,则样本的方差就变为 1 了,就不存在方差最大值了;
# 其实 demean 的过程就是对数据标准化处理的一部分过程,只是没让数据的标准差为 1;
# 在梯度下降法求解线性回归问题时需要对数据做归一化处理;
6)求前 n 个主成分
求下一个主成分的思路
- 思路:去掉当前数据集在上一个主成分方向上的分量,得到一个新的数据集,求新的数据集的主成分;
- 操作:将当前数据集的每一个样本,减去该样本在上一个主成分上的分量
- 步骤:
# 1)第一步:求新的数据集
X2 = np.empty(X.shape)
for i in range(len(X)):
X2[i] = X[i] - X[i].dot(w) * w
# for 循环向量化:X2 = X - X.dot(w).reshape(-1, 1) * w
# X[i].dot(w):表示样本 X[i] 在上一主成分 w 方向上的膜
# X[i].dot(w) * w:表示样本 X[i] 在上一主成分 w 上的分量(为向量)
# X2[i] = X[i] - X[i].dot(w) * w:表示样本 X[i] 减去其在上一主成分上的分量后的新的样本向量 # 2)第二步:初始化数据,求主成分
initial_w = np.random.random(X.shape[1])
eta = 0.01
w2 = first_component(X2, initial_w, eta)
import numpy as np
import matplotlib.pyplot as plt X = np.empty((100, 2))
X[:, 0] = np.random.uniform(0, 100, size=100)
X[:, 1] = 0.75 * X[:,0] + 3. + np.random.normal(0, 10, size=100) # demean函数,将原始数据集 demean 处理
def demean(X):
return X - np.mean(X, axis=0) # 求当前变量 w 对应的目标函数值
def f(w, X):
return np.sum((X.dot(w)**2)) / len(X) # 求当前变量 w 对应的梯度的值
def df(w, X):
return X.T.dot(X.dot(w))*2 / len(X) # 将向量转化为单位向量
def direction(w):
return w / np.linalg.norm(w) # 求主成分
def first_component(X, initial_w, eta, n_iters=10**4, epsilon=10**-8): w = direction(initial_w)
cur_iter = 0 while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w += eta * gradient
w = direction(w)
if (abs(f(w, X) - f(last_w, X)) < epsilon):
break cur_iter += 1 return w # 求取 X 的前 n 个主成分
# 求 X 的前 n 个主成分时,只需要对 X 做一次 demean 操作
def first_n_components(n, X, eta=0.01, n_iters=10**4, epsilon=10**-8): X_pca = X.copy()
X_pca = demean(X_pca)
res = []
# 循环 n 次,每次求出一个主成分,并将 n 个主成分放在列表 res 中返回
for i in range(n):
# 初始化搜索点:initial_w
initial_w = np.random.random(X_pca.shape[1])
# 求出主成分 w
w = first_component(X_pca, initial_w, eta)
res.append(w) # 获取下一次主成分的数据集:X_pca,用于计算下一个主成分
X_pca = X_pca - X_pca.dot(w).reshape(-1,1) * w return res # 求数据集 X 的前 2 个主成分
first_n_components(2, X)
# 输出:[array([0.7993679 , 0.60084187]), array([-0.60084187, 0.7993679 ])]
机器学习:PCA(使用梯度上升法求解数据主成分 Ⅰ )的更多相关文章
- 机器学习(4)——PCA与梯度上升法
主成分分析(Principal Component Analysis) 一个非监督的机器学习算法 主要用于数据的降维 通过降维,可以发现更便于人类理解的特征 其他应用:可视化.去噪 通过映射,我们可以 ...
- 机器学习(七) PCA与梯度上升法 (上)
一.什么是PCA 主成分分析 Principal Component Analysis 一个非监督学的学习算法 主要用于数据的降维 通过降维,可以发现更便于人类理解的特征 其他应用:可视化:去噪 第一 ...
- 4.pca与梯度上升法
(一)什么是pca pca,也就是主成分分析法(principal component analysis),主要是用来对数据集进行降维处理.举个最简单的例子,我要根据姓名.年龄.头发的长度.身高.体重 ...
- 机器学习(七) PCA与梯度上升法 (下)
五.高维数据映射为低维数据 换一个坐标轴.在新的坐标轴里面表示原来高维的数据. 低维 反向 映射为高维数据 PCA.py import numpy as np class PCA: def __ini ...
- 第7章 PCA与梯度上升法
主成分分析法:主要作用是降维 疑似右侧比较好? 第三种降维方式: 问题:????? 方差:描述样本整体分布的疏密的指标,方差越大,样本之间越稀疏:越小,越密集 第一步: 总结: 问题:????怎样使其 ...
- [吴恩达机器学习笔记]14降维5-7重建压缩表示/主成分数量选取/PCA应用误区
14.降维 觉得有用的话,欢迎一起讨论相互学习~Follow Me 14.5重建压缩表示 Reconstruction from Compressed Representation 使用PCA,可以把 ...
- 【笔记】求数据的对应主成分PCA(第一主成分)
求数据的第一主成分 (在notebook中) 将包加载好,再创建出一个虚拟的测试用例,生成的X有两个特征,特征一为0到100之间随机分布,共一百个样本,对于特征二,其和特征一有一个基本的线性关系(为什 ...
- 【笔记】求数据前n个主成分以及对高维数据映射为低维数据
求数据前n个主成分并进行高维数据映射为低维数据的操作 求数据前n个主成分 先前的将多个样本映射到一个轴上以求使其降维的操作,其中的样本点本身是二维的样本点,将其映射到新的轴上以后,还不是一维的数据,对 ...
- PCA:利用PCA(四个主成分的贡献率就才达100%)降维提高测试集辛烷值含量预测准确度并《测试集辛烷值含量预测结果对比》—Jason niu
load spectra; temp = randperm(size(NIR, 1)); P_train = NIR(temp(1:50),:); T_train = octane(temp(1:50 ...
随机推荐
- Vue.js学习笔记 第八篇 组件
全局注册组件 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <ti ...
- poj 2186 Popular Cows 【强连通分量Tarjan算法 + 树问题】
题目地址:http://poj.org/problem?id=2186 Popular Cows Time Limit: 2000MS Memory Limit: 65536K Total Sub ...
- juniper常用命令
Juniper防火墙基本命令 get interface ethernet0/0 查看 端口 常用查看命令 Get int 查看接口配置信息 Get int ethx/x 查看指定接口配置信息 G ...
- Complex social network Partition for Balanced Subnetworks---Hao Lan Zhang,Jiming Liu,Chunyu Feng,Chaoyi Pang,Tongliang Li,Jing He阅读
摘要:Abstract—Complex social network analysis methods have been applied extensively in various domains ...
- 重置密码解决MySQL for Linux错误 ERROR 1045 (28000)
重置密码解决MySQL for Linux错误 ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using passwor ...
- IDEA配置文件的保存目录
IntelliJ IDEA 的实时代码模板保存在 /templates 目录下,其他系统目录位置如下:(因为目录名在各个系统上是一致的,建议用硬盘搜索工具搜索即可) Windows: . Linux: ...
- window7 共享wifi(不通过wifi软件)
1.新建共享网络账号 管理员登录cmd输入:netsh wlan set hostednetwork mode=allow ssid=4Gtest key=12345678 ssid是无线网络名称.k ...
- 基于“基于dockerhub的jetty镜像的ossfs镜像”部署war包,遇到的文件夹读写权限被限制的问题解决方案
前提: “基于dockerhub的jetty镜像的ossfs镜像” 已经搭建好了. 部署准备: 1.本地打包:war包-->idea工具 mvn 打包. 2.本地sh脚本:compile_vps ...
- 剑指Offer——重建二叉树2
Question 输入某二叉树的后序遍历和中序遍历的结果,请重建出该二叉树.假设输入的后序遍历和中序遍历的结果中都不含重复的数字.例如输入后序遍历序列{1, 3, 4, 2}和中序遍历序列{1, 2, ...
- JavaWeb -- 内省—beanutils工具包 的使用
Apache组织开发了一套用于操作JavaBean的API,这套API考虑到了很多实际开发中的应用场景,因此在实际开发中很多程序员使用这套API操作JavaBean,以简化程序代码的编写. Beanu ...