机器学习--最邻近规则分类KNN算法
理论学习:

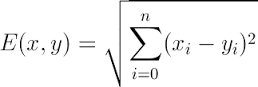
from sklearn import neighbors
from sklearn import datasets knn = neighbors.KNeighborsClassifier() iris = datasets.load_iris() print(iris) knn.fit(iris.data, iris.target) # 建模,两个参数:二维的特征值矩阵、一维的每一个实例所对应的对象 predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]]) print(predictedLabel)
2、不调用任何库来实现knn算法,其中使用到的数据集是sklearn自带的iris数据集
# 不调用任何库来实现knn算法 import csv
import random
import math
import operator # 将数据集装载到Python里面
# filename:数据集存放的文件
# split:以此参数为界限将数据集分为trainingSet训练集和testSet测试集
def loadDataset(filename, split, trainingSet=[], testSet=[]):
with open(filename, 'r') as csvfile: # 打开文件
lines = csv.reader(csvfile) # 读取文件的所有行
dataset = list(lines) # 文件内容转换成list结构 # 将数据集分为两部分
for x in range(len(dataset) - 1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
# 随机数小于split放入训练集,大于就放入测试集
if random.random() < split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x]) # 计算两个实例之间的欧式距离
# instance1、instance2是两个实例
# length是实例的维数
def euclideanDistance(instance1, instance2, length):
distance = 0 # 设置初始值为0 # 计算所有维度的差的平方和
for x in range(length):
distance += pow((instance1[x] - instance2[x]), 2)
return math.sqrt(distance) # 测试集中的一个实例到训练集的距离最近的k个实例
# trainingSet:训练集
# testInstance:测试集实例
# k:距离最近的个数
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance) - 1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors def getResponse(neighbors):
"""
得到
:param neighbors:附近的实例
:return:得票最多的类别情况 """
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) # classVotes.iteritems()
return sortedVotes[0][0] def getAccuracy(testSet, predictions):
"""
得到预测的正确率
:param testSet:测试集
:param predictions: 预测结果
:return: 预测的正确率 """
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet))) * 100.0 def main():
""" :return:
"""
trainingSet = []
testSet = []
split = 0.67 # 把2/3的数据作为训练集,1/3为测试集
loadDataset(r'irisdata.txt', split, trainingSet, testSet)
print('Train set: ' + repr(len(trainingSet)))
print('Test set: ' + repr(len(testSet))) predictions = []
k = 3
for x in range(len(testSet)):
neighbors = getNeighbors(trainingSet, testSet[x], k) # 找到各个测试集实例最近的邻居
result = getResponse(neighbors)
predictions.append(result)
print('> predicted=' + repr(result) + ',actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: ' + repr(accuracy) + '%') if __name__ == '__main__':
main()
机器学习--最邻近规则分类KNN算法的更多相关文章
- 最邻近规则分类KNN算法
例子: 求未知电影属于什么类型: 算法介绍: 步骤: 为了判断未知实例的类别,以所有已知类别的实例作为参照 选择参数K 计算未知实例与所有已知实例的距离 选择最近K个已 ...
- 机器学习算法 - 最近邻规则分类KNN
上节介绍了机器学习的决策树算法,它属于分类算法,本节我们介绍机器学习的另外一种分类算法:最近邻规则分类KNN,书名为k-近邻算法. 它的工作原理是:将预测的目标数据分别跟样本进行比较,得到一组距离的数 ...
- kNN(K-Nearest Neighbor)最邻近规则分类
KNN最邻近规则,主要应用领域是对未知事物的识别,即推断未知事物属于哪一类,推断思想是,基于欧几里得定理,推断未知事物的特征和哪一类已知事物的的特征最接近: K近期邻(k-Nearest Neighb ...
- kNN(K-Nearest Neighbor)最邻近规则分类(转)
KNN最邻近规则,主要应用领域是对未知事物的识别,即判断未知事物属于哪一类,判断思想是,基于欧几里得定理,判断未知事物的特征和哪一类已知事物的的特征最接近: K最近邻(k-Nearest Neighb ...
- 机器学习实战(笔记)------------KNN算法
1.KNN算法 KNN算法即K-临近算法,采用测量不同特征值之间的距离的方法进行分类. 以二维情况举例: 假设一条样本含有两个特征.将这两种特征进行数值化,我们就可以假设这两种特种分别 ...
- 机器学习(一)之KNN算法
knn算法原理 ①.计算机将计算所有的点和该点的距离 ②.选出最近的k个点 ③.比较在选择的几个点中那个类的个数多就将该点分到那个类中 KNN算法的特点: knn算法的优点:精度高,对异常值不敏感,无 ...
- 最邻近规则分类(K-Nearest Neighbor)KNN算法
自写代码: # Author Chenglong Qian from numpy import * #科学计算模块 import operator #运算符模块 def createDaraSet( ...
- 4.2 最邻近规则分类(K-Nearest Neighbor)KNN算法应用
1 数据集介绍: 虹膜 150个实例 萼片长度,萼片宽度,花瓣长度,花瓣宽度 (sepal length, sepal width, petal length and petal wi ...
- python实现简单分类knn算法
原理:计算当前点(无label,一般为测试集)和其他每个点(有label,一般为训练集)的距离并升序排序,选取k个最小距离的点,根据这k个点对应的类别进行投票,票数最多的类别的即为该点所对应的类别.代 ...
随机推荐
- SQL 实现行列互换
Oracle:不过大多数是采用 oracle 数据库当中的一些便捷函数进行处理,比如 ”pivot”: MySql:目前没有找到更好的方法 题目:数据库中有一张如下所示的表,表名为sales. 年 季 ...
- DAY10-python并发之IO模型
一 IO模型介绍 同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?这个问 ...
- VS2013 ERROR SCRIPT5009: “WebForm_AutoFocus”未定义
提示错误: <script type="text/javascript">//<![CDATA[WebForm_AutoFocus('txtcUserID');/ ...
- day17-jdbc 6.Connection介绍
package cn.itcast.jdbc; import com.mysql.jdbc.Connection; import java.sql.DriverManager; import java ...
- 【转】pecl,pear的不同
PEAR是PHP扩展与应用库(the PHP Extension and Application Repository)的缩写.它是一个PHP扩展及应用的一个代码仓库,基于php代码的,安装目录在/u ...
- 高性能MySQL笔记-第5章Indexing for High Performance-001B-Tree indexes(B+Tree)
一. 1.什么是B-Tree indexes? The general idea of a B-Tree is that all the values are stored in order, and ...
- Android 菜单 之 上下文菜单ContextMenu
所谓上下文菜单就是当我们长按某一个文件时弹出的菜单 操作这个菜单我们要重写onCreateContextMenu()方法 如上一篇文章一样,对于这个菜单中选型的操作也有动态添加和xml文件添加两种方法 ...
- React 和 Redux理解
学习React有一段时间了,但对于Redux却不是那么理解.网上看了一些文章,现在把对Redux的理解总结如下 从需求出发,看看使用React需要什么 1. React有props和state pro ...
- UVa 766 Sum of powers (伯努利数)
题意: 求 ,要求M尽量小. 析:这其实就是一个伯努利数,伯努利数公式如下: 伯努利数满足条件B0 = 1,并且 也有 几乎就是本题,然后只要把 n 换成 n-1,然后后面就一样了,然后最后再加上一个 ...
- web.xml文件的Url-pattern 节点配置