【阿圆实验】Alertmanager HA 高可用配置
注意:没有使用supervisor进程管理器的,只参考配置,忽略和supervisor相关命令。并且alertmanager的版本不得低于0.15.2,低版本alert不支持集群配置。
一.alertmanager高可用
这里使用的是supervisor配置,也可以把配置集合成命令行方式,在服务器运行配置。记得加&,后台运行。
1.配置alertmanager集群
1.1 修改各节点alertmanager.yml
cd /data/yy-monitor-server/etc
vim alertmanager.yml
# The root route on which each incoming alert enters.route: routes: group_wait: 15s group_interval: 15s |
1.2 修改启动文件
根目录下运行 vim /etc/supervisord.d/yy-monitor-server.ini
[program:alertmanager]priority = 3user = yycommand = /usr/bin/alertmanager --cluster.listen-address="10.22.0.1002:12001" # 当前节点ip和自定义的端口号 --log.level=debug |
其他节点配置:
[program:alertmanager]priority = 3user = yycommand = /usr/bin/alertmanager --cluster.listen-address="10.22.0.1001:12002" # 当前节点ip和自定义的端口号: --cluster.peer=10.22.0.1002:12001 # 选择一个节点加入集群 --log.level=debug |
重启配置,否则不能生效:
systemctl restart supervisord
supervisorctl restart alertmanager
2.查看日志
cd /data/yy-monitor-server/log
tail -f alermanager.log
level=debug ts=2018-08-28T08:58:44.75092899Z caller=cluster.go:287 component=cluster memberlist="2018/08/28 16:58:44 [DEBUG] memberlist: Initiating push/pull sync with: 10.22.0.1001:12002\n"level=debug ts=2018-08-28T08:59:21.675338872Z caller=cluster.go:287 component=cluster memberlist="2018/08/28 16:59:21 [DEBUG] memberlist: Stream connection from=10.22.0.1001:42736\n"level=debug ts=2018-08-28T08:59:44.754235616Z caller=cluster.go:287 component=cluster memberlist="2018/08/28 16:59:44 [DEBUG] memberlist: Initiating push/pull sync with: 10.22.0.1000:12003\n" |
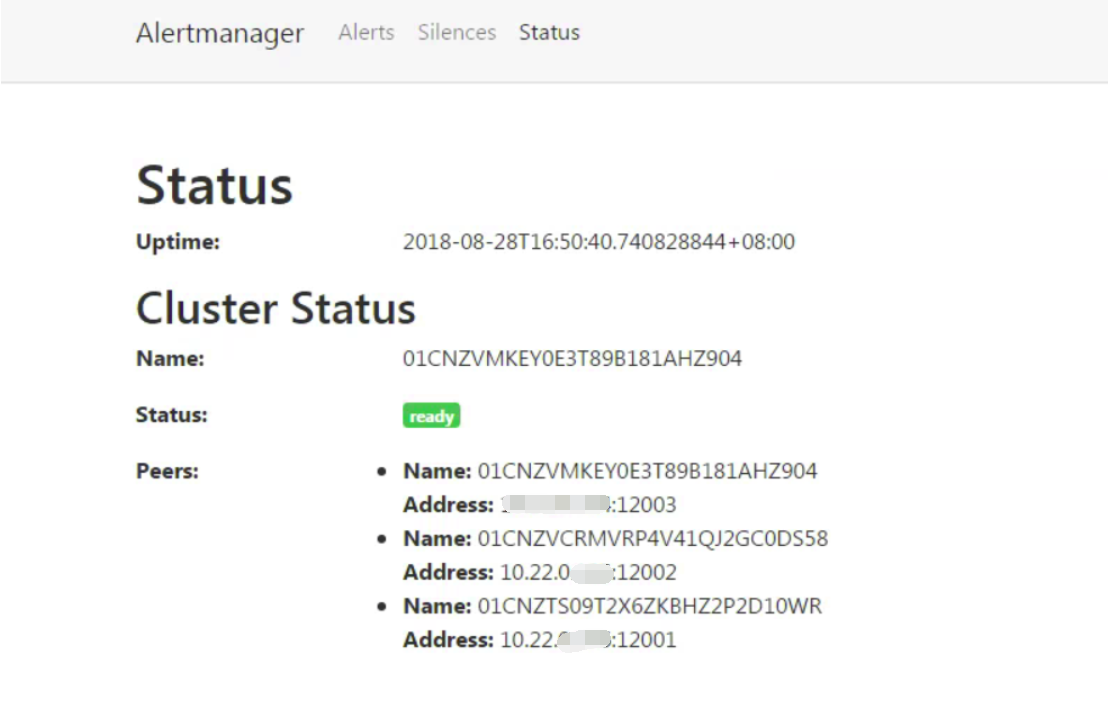
启动完成后访问任意Alertmanager节点http://localhost:9093/#/status,可以查看当前Alertmanager集群的状态。
3.修改各节点prometheus.yml
cd /data/yy-monitor-server/etc
vi prometheus.yml
global: scrape_interval: 5s scrape_timeout: 5s evaluation_interval: 5s # The labels to add to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager). external_labels: dc: europe1# Alertmanager configurationalerting: alert_relabel_configs: - source_labels: [dc] regex: (.+)\d+ target_label: dc alertmanagers: - static_configs: - targets:: ['10.22.0.1000:9093','10.22.0.1001:9093', '10.22.0.1002:9093'] |
global: scrape_interval: 5s scrape_timeout: 5s evaluation_interval: 5s# Note that this is different only by the trailing number. external_labels: dc: europe2# Alertmanager configurationalerting: alert_relabel_configs: - source_labels: [dc] regex: (.+)\d+ target_label: dc alertmanagers: - static_configs: - targets:: ['10.22.0.1000:9093','10.22.0.1001:9093', '10.22.0.1002:9093'] |
global: scrape_interval: 5s scrape_timeout: 5s evaluation_interval: 5s external_labels: dc: europe3# Alertmanager configurationalerting: alert_relabel_configs: - source_labels: [dc] regex: (.+)\d+ target_label: dc alertmanagers: - static_configs: - targets:: ['10.22.0.1000:9093','10.22.0.1001:9093', '10.22.0.1002:9093'] |
2.重启prometheus:
# supervisorctl restart prometheusprometheus: stoppedprometheus: started |
二. Alertmanager代理配置
1.nginx配置
选取一台主机做配置(如:10.22.0.1002)
cd /data/yy-monitor-server/etc
vi nginx.conf
# Alertmanager upstream alert{ server 10.22.0.1002:9093; server 10.22.0.1001:9093; server 10.22.0.1000:9093; } server{ # alertmanager location /alertmanager/ { proxy_pass http://alert/; } } |
重启nginx
# supervisorctl restart nginxnginx: stoppednginx: started |
2.验证配置
停止其中两台服务:
1002 # supervisorctl stop alertmanageralertmanager: stopped1001 # supervisorctl stop alertmanageralertmanager: stopped |
访问ui正常,配置代理成功。
附录:https://github.com/prometheus/alertmanager#high-availability
To create a highly available cluster of the Alertmanager the instances need to be configured to communicate with each other. This is configured using the --cluster.* flags.
--cluster.listen-addressstring: cluster listen address (default "0.0.0.0:9094")--cluster.advertise-addressstring: cluster advertise address--cluster.peervalue: initial peers (repeat flag for each additional peer)--cluster.peer-timeoutvalue: peer timeout period (default "15s")--cluster.gossip-intervalvalue: cluster message propagation speed (default "200ms")--cluster.pushpull-intervalvalue: lower values will increase convergence speeds at expense of bandwidth (default "1m0s")--cluster.settle-timeoutvalue: maximum time to wait for cluster connections to settle before evaluating notifications.--cluster.tcp-timeoutvalue: timeout value for tcp connections, reads and writes (default "10s")--cluster.probe-timeoutvalue: time to wait for ack before marking node unhealthy (default "500ms")--cluster.probe-intervalvalue: interval between random node probes (default "1s")
The chosen port in the cluster.listen-address flag is the port that needs to be specified in the cluster.peer flag of the other peers.
To start a cluster of three peers on your local machine use goreman and the Procfile within this repository.
goreman start
To point your Prometheus 1.4, or later, instance to multiple Alertmanagers, configure them in your prometheus.yml configuration file, for example:
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager1:9093
- alertmanager2:9093
- alertmanager3:9093
Important: Do not load balance traffic between Prometheus and its Alertmanagers, but instead point Prometheus to a list of all Alertmanagers. The Alertmanager implementation expects all alerts to be sent to all Alertmanagers to ensure high availability.
【阿圆实验】Alertmanager HA 高可用配置的更多相关文章
- HA高可用配置
HA 即 (high available)高可用,又被叫做双机热备,用于关键性业务. 简单理解就是,有两台机器A和B,正常是A提供服务,B待命闲置,当A宕机或服务宕掉,会切换至B机器继续提供服务. 下 ...
- hadoop2.5.0 HA高可用配置
hadoop2.5.0 HA配置 1.修改hadoop中的配置文件 进入/usr/local/src/hadoop-2.5.0-cdh5.3.6/etc/hadoop目录,修改hadoop-env.s ...
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- 【阿圆实验】Grafana HA高可用方案
一.实现Grafana高可用 1.Grafana实现高可用性有两步: >>使用共享数据库存储仪表板,用户和其他持久数据>>决定如何存储会话数据. 2.Grafana高可用部署图 ...
- springcloud-07-eureka HA的高可用配置
单机版的eureka, 运行时间稍长, 就会在管理界面出现红色的警告, 为了消除这个警告, 可以使用eureka的高可用配置: 只需要写一个工程配置不同的配置文件, 然后启动多实例即可: 请参照单机版 ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- 大数据技术之HA 高可用
HDFS HA高可用 1.1 HA概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA ...
- ResourceManager高可用配置
ResourceManager高可用配置 1. yarn-site.xml配置 <property> <name>yarn.resourcemanager.cluster-id ...
- HA高可用的搭建
HA 即 (high available)高可用,又被叫做双机热备,用于关键性业务. 简单理解就是,有两台机器A和B,正常是A提供服务,B待命闲置,当A宕机或服务宕掉,会切换至B机器继续提供服务.常用 ...
随机推荐
- HDU5478(快速幂)
Can you find it Time Limit: 8000/5000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)T ...
- Network(lca暴力)
Network Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/65536K (Java/Other) Total Submi ...
- [iOS]UIImageView增加圆角
[iOS]UIImageView增加圆角 "如何给一个UIImageView增加圆角?有几种方法?各自区别?" 备注:本文参考自http://www.jianshu.com/p/d ...
- 五颜六色的记事本 Notepad2.cn
这是一款五颜六色的记事本,支持同时五种颜色的标签录入,可随意切换. 考虑到使用者的用眼舒适度,特意采用颜色对比明显并且色调柔和的配色方案,选择通用的微软雅黑字体作为编辑字体,字体工整便于识别. 针对使 ...
- 第四章 Java并发编程基础
线程简介 什么是线程? 现代操作系统在一个运行程序时,会为其创建一个进程.例如,启动一个Java程序,操作系统就会创建一个Java进程.现代操作系统调度的最小单元是线程,也叫轻量进程(Light We ...
- ABP仓储
简介 我们都知道ABP已经实现了仓储模式,支持EF core 和dapper 进行数据库的连接和管理,可以很方便的注入仓储来操作你的数据,不需要自己单独定义一个仓储来实现,通用的仓储实现了通用的cru ...
- struts2学习笔记(5)拦截器
继承AbstractInterceptor类,在类中完成拦截器的功能,只需实现intercept方法即可,提供了init()和destroy()的空实现 示例:显示执行action所用的时间 ①在sr ...
- Servlet开发中注意的细节问题
客户端访问服务器的时候是通过URL访问的,所以我们要想用浏览器访问我们的Servlet的时候,我们就需要将我们的Servlet映射到一个URL上(通过我们的web.xml文件中的<servler ...
- python笔记--3--函数、生成器、装饰器、函数嵌套定义、函数柯里化
函数 函数定义语法: def 函数名([参数列表]): '''注释''' 函数体 函数形参不需要声明其类型,也不需要指定函数返回值类型 即使该函数不需要接收任何参数,也必须保留一对空的圆括号 括号后面 ...
- 线段树教做人系列(2)HDU 4867 XOR
题意:给你一个数组a,长度为.有两种操作.一种是改变数组的某个元素的值,一种是满足某种条件的数组b有多少种.条件是:b[i] <= a[i],并且b[1]^b[2]...^b[n] = k的数组 ...