python之数据类型的内置方法(set、tuple、dict)与简单认识垃圾回收机制
字典的内置方法
类型转换
# dict()用于转换成字典
print(dict(name='tom', age=18)) # 输出结果:{'name': 'tom', 'age': 18}
字典取值
d1 = {
'name': 'jason',
'age': 18,
'hobbies': ['play game', 'basketball']
}
# 按key取值,这种方式最简单,但是如果找不到key所对应的值会报错,所以不推荐
print(d1['name']) # 输出结果:jason
print(d1['xxx']) # 报错
# 用get()方法,推荐使用
print(d1.get('name')) # 输出结果:jason
print(d1.get('xxx')) # 输出结果:None
# get()方法可以填两个变量,第一个填key,第二个填写如果key不存在则会返回的值
print(d1.get('xxx', '不存在')) # 输出结果:不存在
修改值
ps:字典是可变类型
# 直接用key索引直接赋值修改
d1 = {
'name': 'jason',
'age': 18,
'hobbies': ['play game', 'basketball']
}
d1['age'] = 20
print(d1['age']) # 输出结果:20
# 如果赋值时key不存在于字典内,则会新增值
d1['sex'] = 'boy'
print(d1) # 输出结果:{'name': 'jason', 'age': 20, 'hobbies': ['play game', 'basketball'], 'sex': 'boy'}
计算字典长度
# len()计算长度,有按照key的数量计算
d1 = {
'name': 'jason',
'age': 18,
'hobbies': ['play game', 'basketball']
}
print(len(d1)) # 输出结果:3

成员运算
# in 和 not in,只能判断key是否存在,不能判断value
d1 = {
'name': 'jason',
'age': 18,
'hobbies': ['play game', 'basketball']
}
print('name' in d1) # 输出结果:True
删除元素
d1 = {
'name': 'jason',
'age': 18,
'hobbies': ['play game', 'basketball']
}
# del通用方式
del d1['hobbies']
print(d1) # 输出结果:{'name': 'jason', 'age': 18}
# pop(),括号内要有key值
print(d1.pop('age')) # 输出结果:18
获取元素
d1 = {
'name': 'jason',
'age': 18,
'hobbies': ['play game', 'basketball']
}
# 以下方法获取到的值都可以看作列表
# 获取所有的key
for key in d1.keys():
print(key)
# 获取所有的value
for value in d1.values():
print(value)
# 获取所有的key:value
for item in d1.items():
print(item)
更新字典
# update() 可以同时更新字典中多个数据
d = {'k1': 'jason', 'k2': 'Tony', 'k3': 'JY'}
# key存在则修改 key不存在则新增
d.update({'k1':'tom', 'k4':'aaa'})
print(d) # 输出结果:{'k1': 'tom', 'k2': 'Tony', 'k3': 'JY', 'k4': 'aaa'}
快速生成字典
# fromkeys()可以快速生成字典,但key都会对应同一个value
d = dict.fromkeys(['k1', 'k2', 'k3'], [11])
print(d) # 输出结果:{'k1': [11], 'k2': [11], 'k3': [11]}
d['k1'].append(22)
print(d) # 输出结果:{'k1': [11, 22], 'k2': [11, 22], 'k3': [11, 22]}
setdefault()方法
# key不存在则新增key:value,并且返回是新增的value
d = {'k1': 111, 'k2': 222}
print(d.setdefault('k3', 333)) # 输出结果:333
print(d) # 输出结果:{'k1': 111, 'k2': 222, 'k3': 333}
# key存在,则返回对应的value,不做修改
d = {'k1': 111, 'k2': 222}
print(d.setdefault('k1', '嘿嘿嘿')) # 输出结果:111
print(d) # 输出结果:{'k1': 111, 'k2': 222}

元组的内置方法
类型转换
# tuple()和list()一样
# tuple()可以将除整型、浮点型、布尔值以外的类型转换成元组
print(tuple('jason')) # 输出结果:('j', 'a', 's', 'o', 'n')
print(tuple({'name': 'jason', 'pwd': 123})) # 输出结果:('name', 'pwd')
print(tuple((11, 22, 33, 44, 55))) # 输出结果:(11, 22, 33, 44, 55)
print(tuple({1, 2, 3, 4, 5})) # 输出结果:(1, 2, 3, 4, 5)
索引与切片操作
t = ('jason', 'tom', 123, 'abc')
# 索引取值
print(t[2]) # 输出结果:123
print(t[-1]) # 输出结果:abc
# 切片操作
print(t[1:3]) # 输出结果:('tom', 123)
print(t[-4:-2]) # 输出结果:('jason', 'tom')
# 切片操作之步长
print(t[::2]) # 输出结果:('jason', 123)
print(t[3:1:-1]) # 输出结果:('abc', 123)
统计长度
# len()用来统计长度
t = ('jason', 'tom', 123, 'abc')
print(len(t)) # 输出结果:4
成员运算
# 成员运算
t = ('jason', 'tom', 123, 'abc')
print('j' in t) # 输出结果:False
print('jason' in t) # 输出结果:True
统计某个元素出现的次数
# 统计出现次数使用count()
l = (1, 2, 1, 5, 1, 4, 6, 7, 1)
print(l.count(1)) # 输出结果:4
元组特性
# 当元组内只有一个值时,数据类型会是括号内的数据类型
t2 = (11)
print(type(t2)) # 输出结果:<class 'int'>
t2 = (11.11)
print(type(t2)) # 输出结果:<class 'float'>
t2 = ('jason')
print(type(t2)) # 输出结果:<class 'str'>
# 所以我们在定义时会在值的后面加一个逗号
t2 = (11,)
print(type(t2)) # 输出结果:<class 'tuple'>
t2 = (11.11,)
print(type(t2)) # 输出结果:<class 'tuple'>
t2 = ('jason',)
print(type(t2)) # 输出结果:<class 'tuple'>
# 无法修改元组内的字符串、整型、浮点型、布尔值
# 但可以修改元素为可变类型的值
tt = (11, 22, 33, [11, 22])
tt[-1][0] = 33
print(tt) # 输出结果:(11, 22, 33, [33, 22])
集合内置方法
集合的用处比起其他的数据类型较少,主要还是用于去重和关系运算

类型转换
# set()和list()一样
# set()可以将除整型、浮点型、布尔值以外的类型转换成集合
print(set('jason')) # 输出结果:{'o', 'n', 's', 'j', 'a'}
print(set({'name': 'jason', 'pwd': 123})) # 输出结果:{'name', 'pwd'}
print(set((11, 22, 33, 44, 55))) # 输出结果:{33, 11, 44, 22, 55}
print(set({1, 2, 3, 4, 5})) # 输出结果:{1, 2, 3, 4, 5}
集合去重
因为集合内不能出现重复的元素,自带去重特性,所以集合可以用于去重
# 自带去重
s = {1,1,1,1,1,2,2,2,2,2,1,2,3,2,2,1,2,3,2,3,4,3,2,3}
print(s) # 输出结果:{1, 2, 3, 4}
# 列表去重
l = ['a', 'b', 1, 'a', 'a']
s = set(l)
l = list(s)
print(l) # 输出结果:['a', 1, 'b']
"""列表如果用转集合的方式去重,返回的值不会是列表原来的顺序"""
关系运算
# 判断两个群体内的差异,如:共同好友、共同关注、共同点赞
f1 = {'jason', 'kevin', 'tony', 'jerry'}
f2 = {'jason', 'tom', 'jerry', 'jack'}
# 查询共同元素
print(f1 & f2) # 输出结果:{'jason', 'jerry'}
# 查询f1中f2没有的元素
print(f1 - f2) # 输出结果:{'tony', 'kevin'}
# 查询f1和f2所有元素
print(f1 | f2) # 输出结果:{'jerry', 'kevin', 'jack', 'tom', 'tony', 'jason'}
# 查询各自的独立元素
print(f1 ^ f2) # 输出结果:{'jack', 'kevin', 'tom', 'tony'}
简单认识垃圾回收机制
前言
在有些其他的编程语言中,针对内存空间的操作都是需要程序员自己操作,而在python中,python底层针对空间的申请和释放都是设计好的,不需要程序员操心。
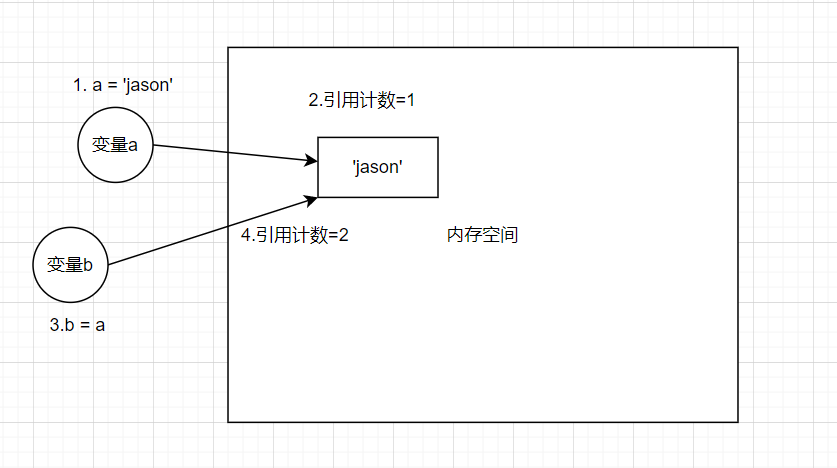
引用计数
在内存空间中,一个数据赋予一个变量时,这个数据身上的标记就会加1,这个标记就是引用计数,而python会清除引用计数为0的数据。
a = 'jason' # 'jason'引用计数+1
b = a # 'jason'引用计数+1
标记清除
当内存空间即将溢出(满了)的时候,python会自动启动应急机制,停止程序的运行,挨个检查值的引用计数并给计数为0的数据打上标记,然后一次性清理掉
分代回收
根据值存在的时间长短,将值划分为三个等级,存在时间越长,等级越高,等级越高检查间隔时间越长。

作业
- 去重列表元素并保留原来的顺序
l = ['a', 'b', 1, 'a', 'a']
- 去重下列数据字典并保留原来的顺序
l = [
{'name': 'lili', 'age': 18, 'sex': 'male'},
{'name': 'jack', 'age': 73, 'sex': 'male'},
{'name': 'tom', 'age': 20, 'sex': 'female'},
{'name': 'lili', 'age': 18, 'sex': 'male'},
{'name': 'lili', 'age': 18, 'sex': 'male'},
]
- 有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'oscar', 'tony', 'gangdan'}
'''
要求:
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合
'''
答案
第一题
点击查看代码
l = ['a', 'b', 1, 'a', 'a']
# 用于存储新列表
final_list = []
# 遍历旧列表
for s in l:
# 如果新列表中没有这个值,则给新列表添加进去
if s not in final_list:
final_list.append(s)
print(final_list)
第二题
点击查看代码
l = [
{'name': 'lili', 'age': 18, 'sex': 'male'},
{'name': 'jack', 'age': 73, 'sex': 'male'},
{'name': 'tom', 'age': 20, 'sex': 'female'},
{'name': 'lili', 'age': 18, 'sex': 'male'},
{'name': 'lili', 'age': 18, 'sex': 'male'},
]
# 用于存储新列表
final_list = []
# 遍历旧列表
for s in l:
# 如果新列表中没有这个值,则给新列表添加进去
if s not in final_list:
final_list.append(s)
print(final_list)
第三题
点击查看代码
pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'oscar', 'tony', 'gangdan'}
'''
要求:
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合
'''
# 要求1
print("即报名python又报名linux课程的学员:{}".format((pythons & linuxs)))
# 要求2
print("所有报名的学生名字:{}".format((pythons | linuxs)))
# 要求3
print("只报名python课程的学员名字:{}".format((pythons - linuxs)))
# 要求4
print("没有同时这两门课程的学员名字集合:{}".format((pythons ^ linuxs)))
python之数据类型的内置方法(set、tuple、dict)与简单认识垃圾回收机制的更多相关文章
- python之数据类型的内置方法(str, list)
目录 字符串的内置方法 移除首尾指定字符 字母大小写相关操作 判断字符串的开头或结尾是否是指定字符 字符串特殊的输出方法 拼接字符串 替换指定字符 判断是否是纯数字 查找指定字符对应的索引值 文本位置 ...
- python 基本数据类型以及内置方法
一.数字类型 # 一.整型int # ======================================基本使用====================================== ...
- python 入门基础4 --数据类型及内置方法
今日目录: 零.解压赋值+for循环 一. 可变/不可变和有序/无序 二.基本数据类型及内置方法 1.整型 int 2.浮点型float 3.字符串类型 4.列表类型 三.后期补充内容 零.解压赋值+ ...
- day6 基本数据类型及内置方法
day6 基本数据类型及内置方法 一.10进制转其他进制 1. 十进制转二进制 print(bin(11)) #0b1011 2. 十进制转八进制 print(hex(11)) #0o13 3. 十进 ...
- while + else 使用,while死循环与while的嵌套,for循环基本使用,range关键字,for的循环补充(break、continue、else) ,for循环的嵌套,基本数据类型及内置方法
今日内容 内容概要 while + else 使用 while死循环与while的嵌套 for循环基本使用 range关键字 for的循环补充(break.continue.else) for循环的嵌 ...
- python今日分享(内置方法)
目录 一.习题详解 二.数据类型的内置方法理论 三.整型相关操作 四.浮点型相关操作 五.字符串相关操作 六.列表相关操作 今日详解 一.习题详解 1.计算1-100所有数据之和 all_num = ...
- Day 07 数据类型的内置方法[列表,元组,字典,集合]
数据类型的内置方法 一:列表类型[list] 1.用途:多个爱好,多个名字,多个装备等等 2.定义:[]内以逗号分隔多个元素,可以是任意类型的值 3.存在一个值/多个值:多个值 4.有序or无序:有序 ...
- if循环&数据类型的内置方法(上)
目录 if循环&数据类型的内置方法 for循环 range关键字 for+break for+continue for+else for循环的嵌套使用 数据类型的内置方法 if循环&数 ...
- wlile、 for循环和基本数据类型及内置方法
while + else 1.while与else连用 当while没有被关键字break主动结束的情况下 正常结束循环体代码之后执行else的子代码 """ while ...
随机推荐
- 使用 Blueprint 要注意 render_template 函数
此文章主要是为了记录在使用 Flask 的过程中遇到的问题.本章主要讨论 render_template 函数的问题. 使用 Flask 的同学都应该知道,项目中的 url 和视图函数是在字典里一一对 ...
- ES6-11学习笔记--函数的参数
参数的默认值 与解构赋值结合 length属性 作用域 函数的name属性 ES5设置函数参数默认值: function foo(x, y) { y = y || 'world'; console ...
- 一个好用的swagger第三方ui-xiaoymin
swagger自带的ui界面实在是看的难受 配置完默认访问地址:ip:port/swagger-ui.html 推荐一个好用的第三方ui,界面如图: 使用方法: 1.添加依赖 <dependen ...
- datetimepicker 设置日期格式、初始化
$('#datetimepicker').datetimepicker({ minView: "month", //选择日期后,不会再跳转去选择时分秒 language: 'zh- ...
- Python入门-面向对象三大特性-多态
Pyhon不支持多态并且也用不到多态,多态的概念是应用于Java和C#这一类强类型语言中,而Python崇尚"鸭子类型".
- k8s pod故障分类与排查
一.Pod故障状态基本有几种Pod状态 处于PendingPod状态 处于WaitingPod状态 处于ContainerCreatingPod状态 ImagePullBackOffPod状态 Cra ...
- 前端CSS浮动、定位、溢出、z-index、透明度
一.浮动float 在 CSS 中,任何元素都可以浮动. 浮动元素会生成一个块级框,而不论它本身是何种元素. 关于浮动的两个特点: 浮动的框可以向左或向右移动,直到它的外边缘碰到包含框或另一个浮动框的 ...
- Istio实践(2)-流量控制及服务间调用
前言:接上一篇istio应用部署,本文介绍通过virtualservice实现流量控制,并通过部署client端进行服务调用实例 1. 修改virtualservice组件,实现权重占比访问不同版本服 ...
- 2021.12.08 [SHOI2009]会场预约(平衡树游码表)
2021.12.08 [SHOI2009]会场预约(平衡树游码表) https://www.luogu.com.cn/problem/P2161 题意: 你需要维护一个 在数轴上的线段 的集合 \(S ...
- Linux的软件安装tomcat 以及jdk
因为tomcat的启动需要jdk,所以我们先安装jdk,安装完成后再安装tomcat 具体的文件大家可以到官网下载,下面介绍安装步骤 目录 jdk安装 1.通过xftp或者其他方式将安装包传到我们的L ...