MySQL进阶实战5,为什么查询速度会慢
一、先了解一下MySQL查询的执行过程
MySQL在查询时,它是由很多子任务组成的,每个子任务都会消耗一定的时间,如果要想优化查询,实际上要优化其子任务,可以消除一些子任务、减少子任务的执行次数、让子任务执行的更快。
MySQL查询的执行过程:从客户端到服务器、然后在服务器进行解析、生成执行计划、执行、返回结果给客户端。
执行是最重要的阶段,包括调用存储引擎检索数据、调用后的数据处理、排序、分组等;
查询需要在不同的地方花费时间,包括网络、CPU计算、生成统计信息、生成执行计划、锁等待等,尤其是向底层存储引擎检索数据的调用操作,这些调用需要在内存操作、CPU操作和内存不足时导致的IO操作上花费时间。根据存储引擎不同,可能还会产生大量的上下文切换以及系统调用。
不必要的额外操作、不必要的重复操作、某些操作执行的太慢都是查询慢的原因,优化查询的目的就是减少和消除这些操作所花费的时间。
二、是否查询了不需要的数据
有些查询会查询很多不需要的数据,查询之后,程序中并未使用,这样不但会给MySQL服务器带来额外的负担,还会增加网络开销,也会消耗应用服务器的CPU和内存资源,简而言之,吃多少拿多少。
千万不要有“把数据都查出来,用Java代码过滤”的想法。
禁止使用select * 进行查询。
三、衡量查询开销的几个重要指标
1、响应时间
响应时间可以分为服务时间和排序时间。
- 服务时间指数据库处理这个查询真正花费的时间;
- 排队时间指服务器因为等待某些资源而没有真正执行查询的时间,比如等待IO操作、等待行锁。
2、扫描的行数和返回的行数
较短的行的访问速度更快,内存中的行比磁盘中的行的访问速度要快得多。
理想情况下扫描的行数和返回的行数是相同的。但这种情况并不多见,比如关联查询的时候,服务器必须扫描更多的行才能得到结果,因此,越多的表关联,性能越低。
3、扫描的行数和访问类型
MySQL可以通过多种方式查询并返回结果集,速度从慢到快,扫描的行数由多到少,依次为全表扫描、索引扫描、范围扫描、唯一索引扫描、常数引用。
最常用的优化方式是为查询增加一个合适的索引,索引可以让MySQL以最高效、扫描行数最少的方式找到需要的记录。
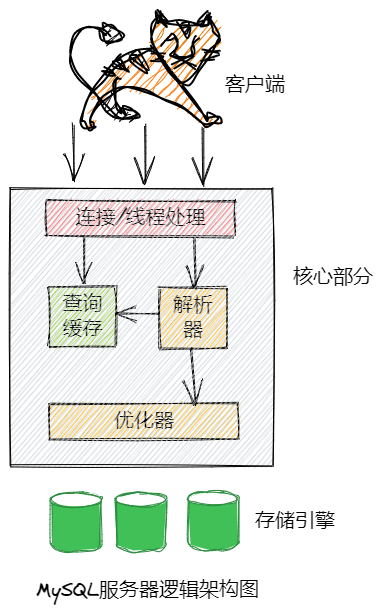
4、一般可以通过explain的Extra列查看查询的优劣
一般MySQL能够使用以下三种方式应用where条件,从好到坏依次为:
- 在索引中使用where条件过滤不匹配的记录,这是在存储引擎层完成的;
- 使用索引覆盖扫描,也就是Extra中出现
Using index,直接从索引中过滤不需要的记录并返回命中的结果,这是在MySQL服务器层完成的,无须再回表查询记录; - Extra中出现
Using where,这是在MySQL服务器层完成的,MySQL需要先从数据表读取记录,然后过滤。
Extra中出现Using where时,可以通过如下方式优化:
- 使用索引覆盖扫描,把所有需要的列都放到索引中,这样就不用回表查询了;
- 改变表结构,比如使用汇总表;
- 重写sql,让MySQL优化器能够以更优化的方式执行这个sql;
MySQL进阶实战5,为什么查询速度会慢的更多相关文章
- 提高MYSQL百万条数据的查询速度
提高MYSQL百万条数据的查询速度 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 nul ...
- mysql进阶(九)多表查询
MySQL多表查询 一 使用SELECT子句进行多表查询 SELECT 字段名 FROM 表1,表2 - WHERE 表1.字段 = 表2.字段 AND 其它查询条件 SELECT a.id,a.na ...
- 小白也能看懂的mySQL进阶【单表查询】
目录 1.查询基础 SELECT语句基础 列的查询 为列设定别名 常数的查询 过滤表中重复数据 根据WHERE语句来选择记录 注释的书写方法 算术运算符和比较运算符 算术运算符 需要注意NULL 比较 ...
- MySQL进阶篇(03):合理的使用索引结构和查询
本文源码:GitHub·点这里 || GitEE·点这里 一.高性能索引 1.查询性能问题 在MySQL使用的过程中,所谓的性能问题,在大部分的场景下都是指查询的性能,导致查询缓慢的根本原因是数据量的 ...
- mysql处理海量数据时的一些优化查询速度方法
最近一段时间由于工作需要,开始关注针对Mysql数据库的select查询语句的相关优化方法. 由于在参与的实际项目中发现当mysql表的数据量达到百万级时,普通SQL查询效率呈直线下降,而且如果w ...
- mysql处理大数据量的查询速度究竟有多快和能优化到什么程度
mysql处理大数据量的查询速度究竟有多快和能优化到什么程度 深圳-ftx(1433725026) 18:10:49 mysql有没有排名函数啊 横瓜(601069289) 18:13:06 无 ...
- 相似度到大数据查找之Mysql 文章匹配的一些思路与提高查询速度
文章相关度匹配的一些思路---"压缩"预料库,即提取用特征词或词频,量化后以“列向量”形式保存到数据库:按前N组词拼为向量组供查询使用,即组合为1到N字的组合,量化后以“行向量”形 ...
- (已实现)相似度到大数据查找之Mysql 文章匹配的一些思路与提高查询速度
需求,最近实现了文章的原创度检测功能,处理思路一是分词之后做搜索引擎匹配飘红,另一方面是量化词组,按文章.段落.句子做数据库查询,功能基本满足实际需求. 接下来,还需要在海量大数据中快速的查找到与一句 ...
- 提高MySQL查询速度
参考百度知道 关于mysql处理百万级以上的数据时如何提高其查询速度的方法 最近一段时间由于工作需要,开始关注针对Mysql数据库的select查询语句的相关优化方法. 由于在参与的实际项目中发现当m ...
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
随机推荐
- 【ceph】理解Ceph的三种存储接口:块设备、文件系统、对象存储
文章转载自:https://blog.51cto.com/liangchaoxi/4049104
- EFK-5: ES集群开启用户认证
转载自:https://mp.weixin.qq.com/s?__biz=MzUyNzk0NTI4MQ==&mid=2247483826&idx=1&sn=583e9a5260 ...
- kvm里的虚拟机硬盘和网卡使用virtio驱动
1.首先从虚拟机的xml文件中找到已经使用virtio驱动的硬件,复制里面的address这行参数出来 <address type='pci' domain='0x0000' bus='0x00 ...
- 使用kuboard界面配置springcloud的其中一个模块设置环境变量,使用nacos配置地址等有关设置
总结: 工作负载类型是StatefulSet的pod,不论其上层的service是nodeport还是Headless, 对外提供的地址格式是: <pod name>.<servic ...
- service的dns记录
当您创建一个 Service 时,Kubernetes 为其创建一个对应的 DNS 条目.该 DNS 记录的格式为 ..svc.cluster.local,也就是说,如果在容器中只使用 ,其DNS将解 ...
- 适用于纯64位Linux系统无需multilib运行win32软件的Wine
链接: https://pan.baidu.com/s/1qbDGz8mI-TtZLOFvEQetbg 提取码: uk6u 食用方法:解包到~ export HOQEMU=$HOME/hangover ...
- Bootstrap5 如何创建多媒体对象
一.在Bootstra5中使用媒体对象 Bootstrap 媒体对象在版本 5 中已经停止支持了.但是,我们仍然可以使用 flex 和 margin 创建包含左对齐或右对齐媒体对象(如图像或视频)以及 ...
- Ubuntu转到root用户后用户名路径没有颜色
看到好多都直接把普通会用户的.bashrc配置复制到root家目录下,由于本人小白,很多.bashrc配置看不懂,也不敢随便修改.于是找到别的配置方法. 普通用户的os@a:~$和root用户的roo ...
- 如何编写 Pipeline 脚本
前言 Pipeline 编写较为麻烦,为此,DataKit 中内置了简单的调试工具,用以辅助大家来编写 Pipeline 脚本. 调试 grok 和 pipeline 指定 pipeline 脚本名称 ...
- 后端框架的学习----mybatis框架(9、多对一处理和一对多处理)
9.多对一处理和一对多处理 #多对一 <!--按照结果集嵌套查询--> <select id="getAllStudent1" resultMap="S ...