MySQL-SQL语句查询关键字
1.SQL语句查询关键字
1.select:指定需要查找的字段信息,eg:select *,select name。同时select也支持对字段做处理,eg:select char_length(name)。
2.from:指定需要查询的表信息,from mysql.user,from 表名。
3.SQL语句中关键字的执行顺序和编写顺序并不是一致的,例如:select id,name from userinfo;我们先写的select在写的from,但是执行的时候是先执行的from在执行select,对应关键字的编写顺序和执行顺序我们没必要过多的在意,我们只需要把注意力放在每个关键字的功能上即可。
2.前期数据准备
我们用以下表以及数据来引出今天的知识点。
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
gender enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
#插入记录
#三个部门:教学,销售,运营
insert into emp(name,gender,age,hire_date,post,salary,office,depart_id) values
('jason','male',18,'20170301','浦东第一帅形象代言',7300.33,401,1), #以下是教学部
('tom','male',78,'20150302','teacher',1000000.31,401,1),
('kevin','male',81,'20130305','teacher',8300,401,1),
('tony','male',73,'20140701','teacher',3500,401,1),
('owen','male',28,'20121101','teacher',2100,401,1),
('jack','female',18,'20110211','teacher',9000,401,1),
('jenny','male',18,'19000301','teacher',30000,401,1),
('sank','male',48,'20101111','teacher',10000,401,1),
('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('呵呵','female',38,'20101101','sale',2000.35,402,2),
('西西','female',18,'20110312','sale',1000.37,402,2),
('乐乐','female',18,'20160513','sale',3000.29,402,2),
('拉拉','female',28,'20170127','sale',4000.33,402,2),
('僧龙','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3);
"""
针对select后面的字段名可以先用*占位往后写,最后再回来修改,在实际应用中select后面很少直接写*,因为*表示所有,当表中字段和数据都特别多的情况下非常浪费数据库资源。
"""
3.查询关键字之where筛选
1.查询范围:查询id大于等于3小于等于6的数据
'''sql支持逻辑运算符'''
select * from emp where id >=3 and id <= 6;
'''或者使用between关键字,between m and n相当于 id >=m and id <=n(两端都包含)'''
select * from emp where id between 3 and 6;
2.查询薪资是20000或者18000或者17000的数据
select * from emp where salary=20000 or salary=18000 or salary=17000;
'''sql支持成员运算符'''
select * from emp where salary in (20000,18000,17000);
3.查询id小于3大于6的数据
select * from emp where id<3 or id>6;
select * from emp where id not between 3 and 6;
4.查询员工姓名中包含字母o的员工姓名与薪资
"""
条件不够精准的查询,称之为模糊查找,模糊查找的关键字是like。模糊查找的符号:
1.%:%可以查找到任意个数的字符(包括0),eg:%o%可以查找到jason,loo,o;%o可以查找到asdhgo,o;
2._:_可以查找到单个任意字符,eg:_o_可以查找到:aox,boe;o_可以查找到or,ok;
"""
select name,salary from emp where name like '%o%';
5.查询员工姓名是由四个字符组成的员工姓名与其薪资
select * from emp where name like '____';
select * from emp where char_length(name)=4;
6.查询岗位描述为空的员工名与岗位名
'''针对null不能用等号,只能用is'''
select name,post from emp where post_comment is NULL;
"""
在mysql中我们可以通过help 方法名的方式来学习方法的使用
"""
4.查询关键字之group by分组
1.分组:按照指定的条件将单个单个的数据组成一个个整体,比如:将班级学生按照性别分组,将全国人民按照民族分组。分组的目的是为了更好地统计相关数据。
2.聚合函数:专门用于分组之后的数据统计。max:最大值,min:最小值,sum:求和,avg:平均值,计数:count。
3.举例:将员工数据按照部门分组
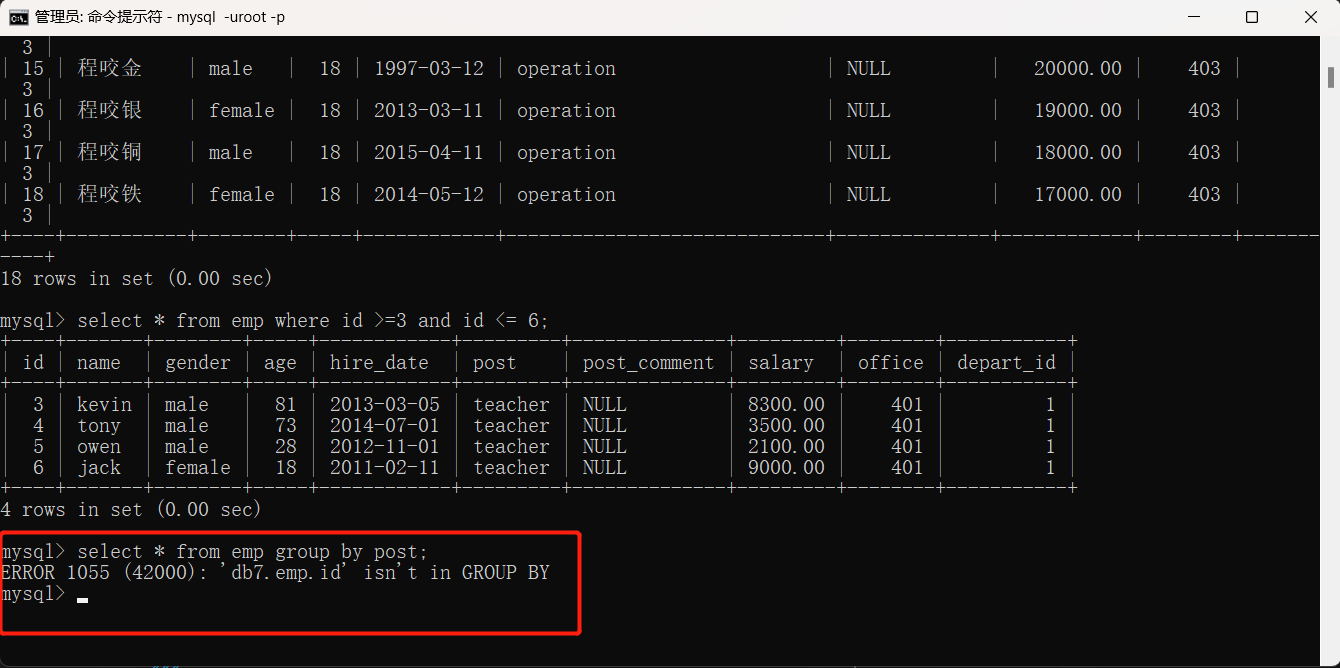
select * from emp group by post;
"""
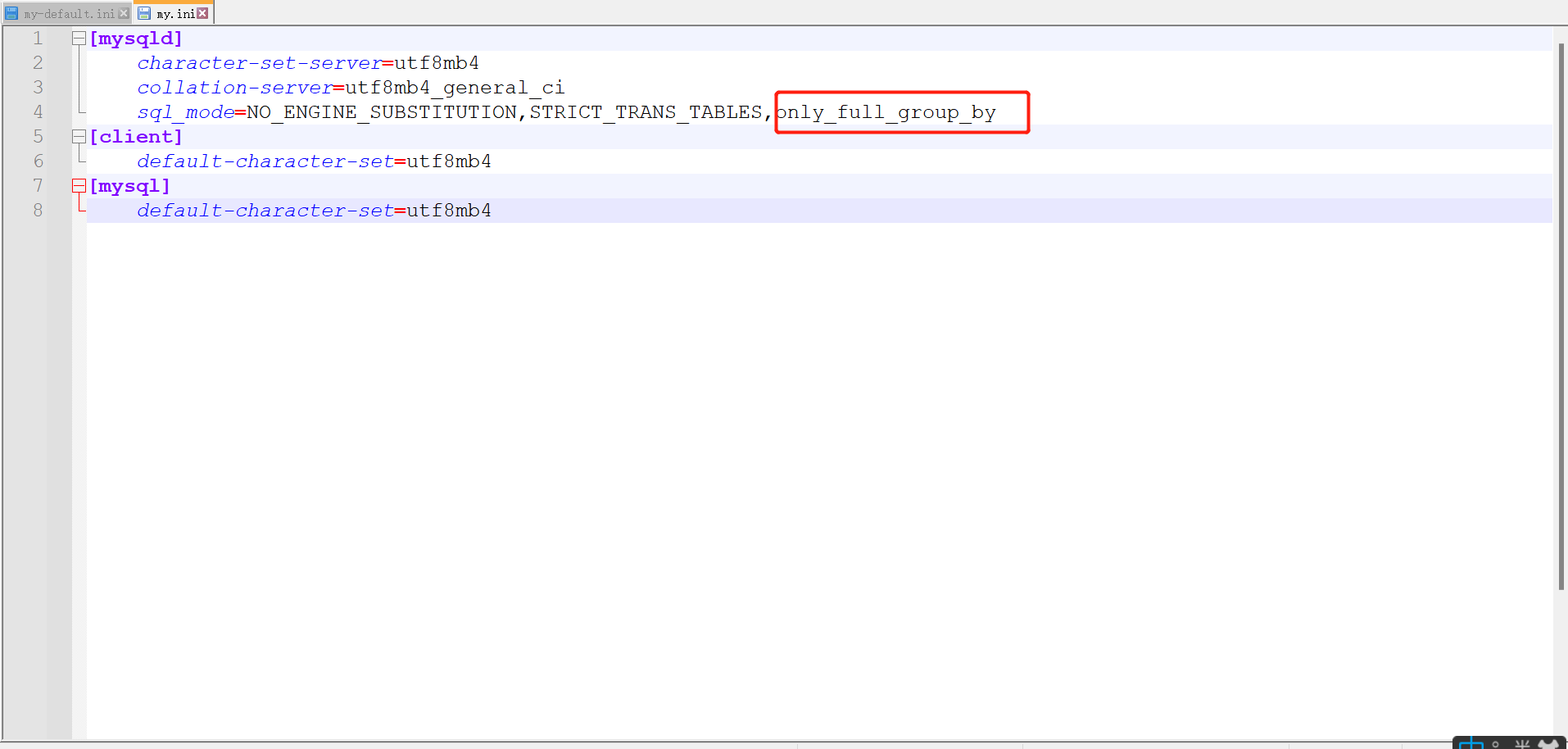
不同版本MySQLl针对上句话作出不同处理:MySQL5.6不会报错,5.7及8.0会报错,因为5.7以上版本认为最小单位就是组,而不应该再试组内单个数据单个字段,group by后面的字段名也应该写在select后面,eg:select post from emp group by post。
如果我们相对5.6最初改变实现上述效果,我们需要做以下操作:在my.ini中客户端添加以下内容:only_full_group_by。添加成功后可以看到效果会直接报错。
"""
4.获取每个部门的最高工资
'''要不要分组我们完全可以从题目的需求中分析出来尤其是出现关键字:每个 、平均'''
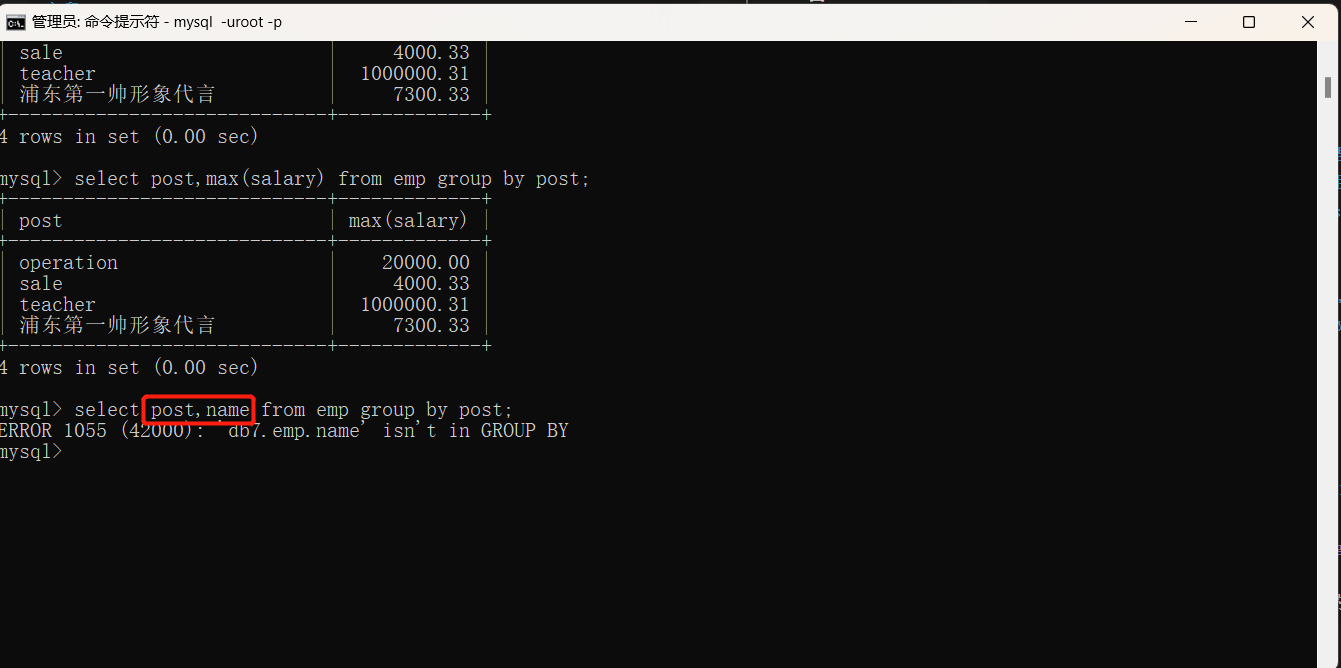
select post,max(salary) from emp group by post;
5.统计每个部门的部门名称以及部门下的员工姓名
select post,name from emp group by post;我们发现该结果会直接报错,因为分组以外的字段名无法直接填写,需要借助于方法。
"""
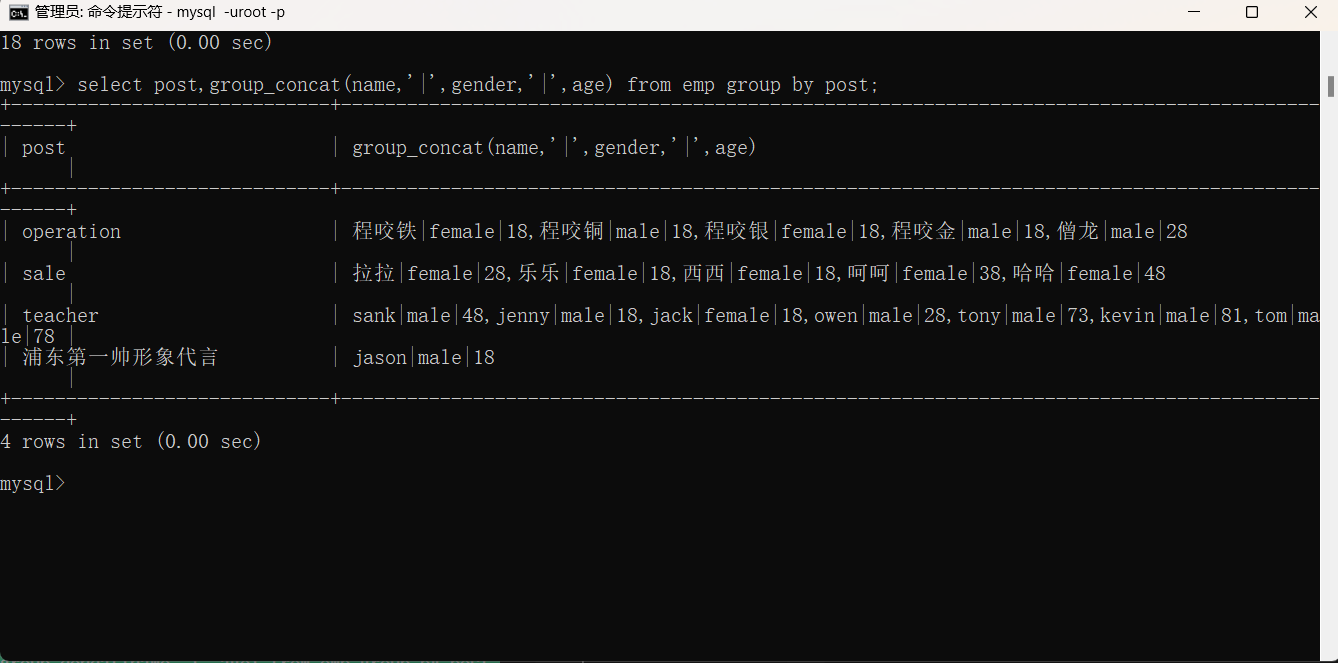
当分组时其他的字段我们没法直接用到,要么使用聚合函数来使用其它的字段,要么是用group_concat(其他字段名)来使用,同时我们也可以在字段之间添加一些特殊符号来分割数据
"""
select post,group_concat(name,age) from emp group by post;
select post,group_concat(name,'_NB') from emp group by post;
select post,group_concat(name,'|',gender,'|',age) from emp group by post;
5.查询关键字之having过滤
having与where本质是一样的,都是用来对数据做筛选,只不过where用在分组之前(首次筛选),having用在分组之后(二次筛选)。
1.统计各部门年龄在30岁以上的员工平均工资,并且保留大于10000的数据。
'''先统计出年龄在30岁以上的员工数据'''
select * from emp where age > 30;
'''再将筛选出来的数据按照部门分组,并统计平均薪资'''
select post,avg(salary) from emp where age > 30 group by post;
'''针对分组统之后的结果用having再一次删选'''
select post,avg(salary) from emp where age > 30 group by post having avg(salary) > 10000;
6.查询关键字之distinct去重
表中有很多字段下有重复的数据,或者是几个字段组合起来有重复的数据,我们如果想要去重需要用到distinct关键字,distinct后面如果跟一个字段名就是一个字段名下的数据去重,跟多个字段名就是组合去重。
select distinct age from emp;
select distinct name,age from emp;
7.查询关键字order by排序
表中如果有数据需要我们进行排序的时候,可以用到order by 字段名来排序,order by后面的字段名就是排序的依据,默认升序。如果想要按照降序排列需要在后面加上desc(升序后面也有后缀,后缀为asc,但是通常情况下asc省略)。
1.单个字段排序:
select * from emp order by age; # 默认升序
select * from emp order by age desc; # 降序
2.多个字段排序:先按照前面的字段名排序,如果相同在按照后面的字段名排序
select * from emp order by age,salary;
select * from emp order by hire_date,age; # hire_date,age都按照升序
select * from emp order by age,salary desc; # 年龄按照升序,薪资按照降序
select * from emp order by age desc,salary desc; # 年龄、薪资都按照降序
3.统计各部门年龄在10岁以上的员工平均工资,并且保留平均工资大于1000的部门,然后对平均工资进行排序
针对上述题目我们显然无法一次写出,我们可以将题目拆解为以下几部:
1.找到10岁以上的员工,拿到他们的全部信息
select * from emp where age > 10;
2.再按照部门统计平均薪资
select post,avg(salary) from emp where age > 10 group by post;
3.保留平均工资大于1000的部门
select post,avg(salary) from emp where age > 10 group by post having avg(salary) > 1000;
4.对平均工资进行排序
select post,avg(salary) from emp where age > 10 group by post having avg(salary) > 1000 order by avg(salary);
"""
当一条SQL语句中很多地方都需要使用聚合函数计算之后的结果 我们可以节省操作(主要是节省了底层运行效率 代码看不出来)
select post,avg(salary) as avg_salary from emp where age > 10 group by post having avg_salary>1000 order by avg_salary;
"""
"""
约束条件顺序可简单的记为:where,group,having,order
"""
8.查询关键字之limit分页
当网站数据较多时,我们无法一次全部呈现,我们需要将数据分页展示。我们能看到的大多数网站都做了分页处理,每页都只能存放固定数量的数据。下面用例子说明limit的用法。
1. select * from emp limit 5; limit后面跟一个参数时,按照顺序一次性展示5条数据。
2.select * from emp limit 3,5; 后面跟两个参数时,表示从第4条数据开始展示,展示5条数据。
3.查询工资最高的人的详细信息:
select * from emp order by salary limit 1 order by salary;(limit限制条件必须放在order by 后面)
9.查询关键字之regexp正则表达式
SQL语句的模糊匹配如果用不习惯 也可以自己写正则批量查询
select * from emp where name regexp '^j.*(n|y)$';
10.多表查询的思路
表数据准备
create table dep(
id int primary key auto_increment,
name varchar(20)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入数据
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营'),
(205,'财务');
insert into emp(name,sex,age,dep_id) values
('jason','male',18,200),
('dragon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
上述两个表格分别如下,我们的初衷是把它们合在一起,让第一个表格的dep_id和第二个表格的部门名称name对应,但是却出现了图2的效果:
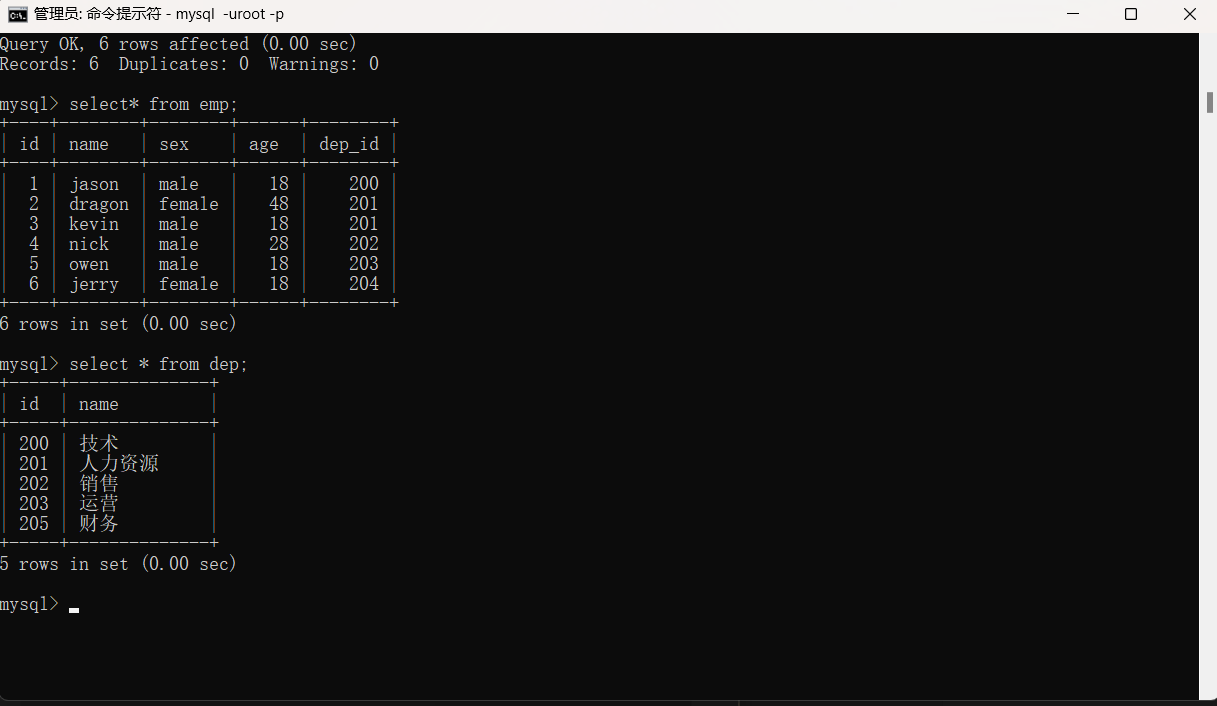
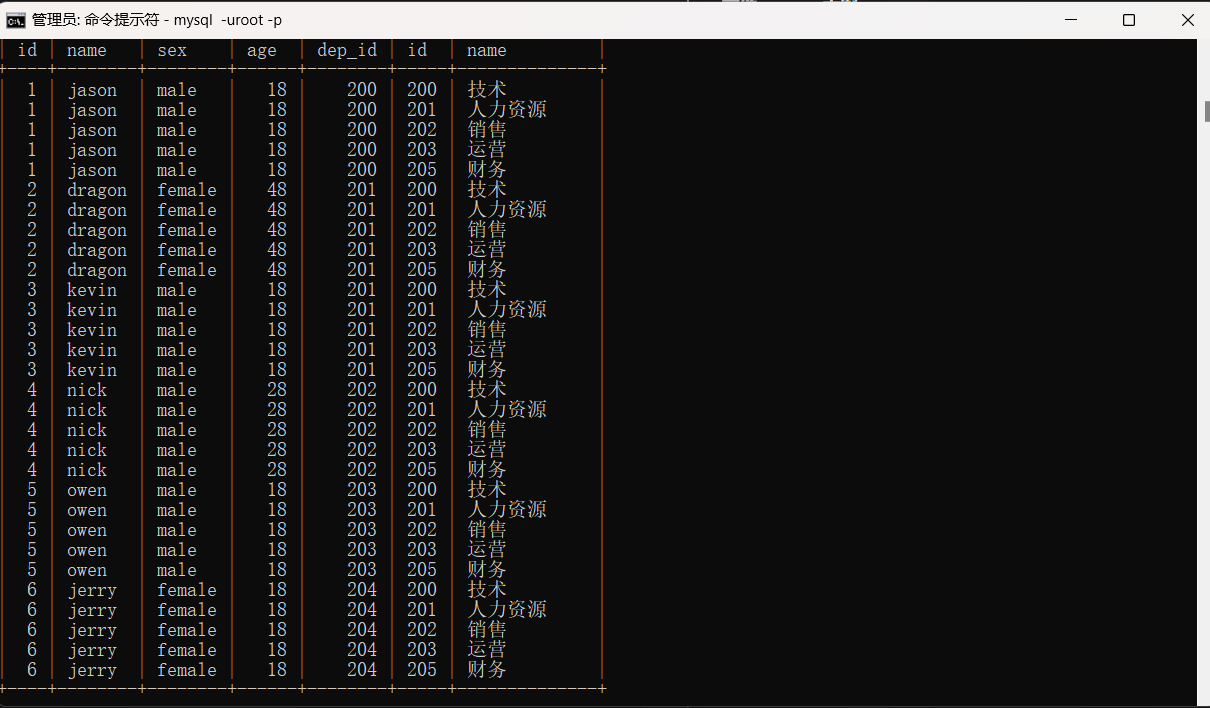
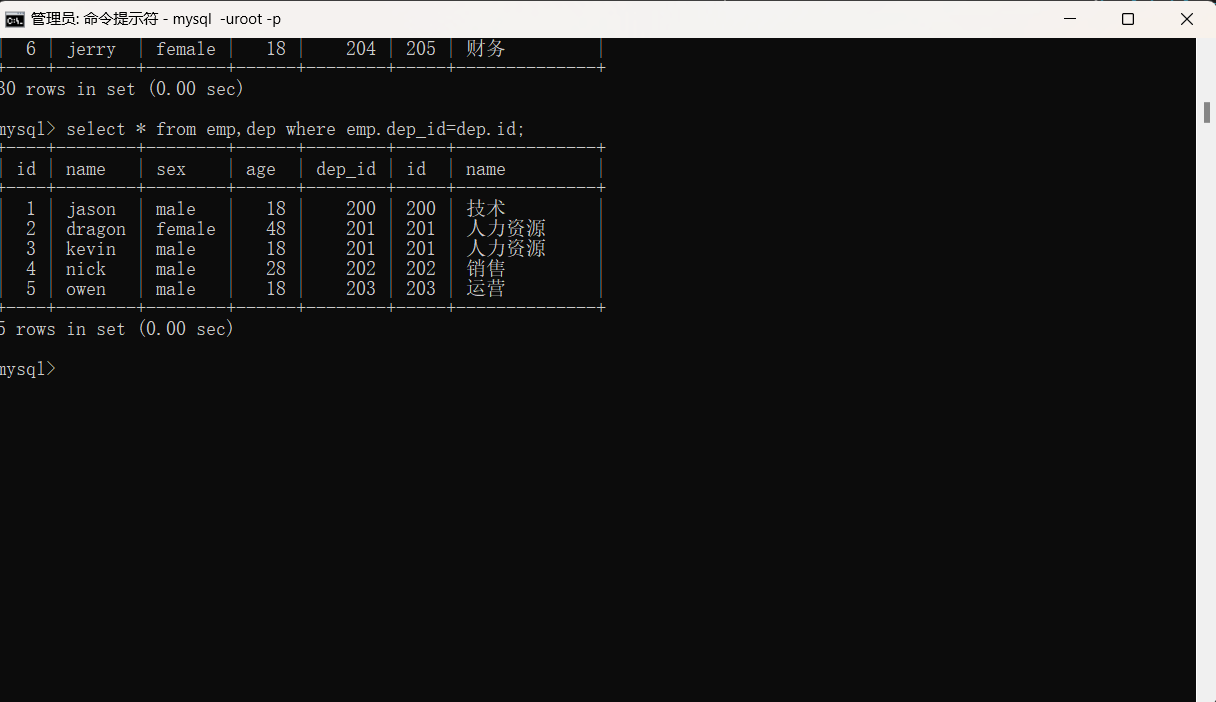
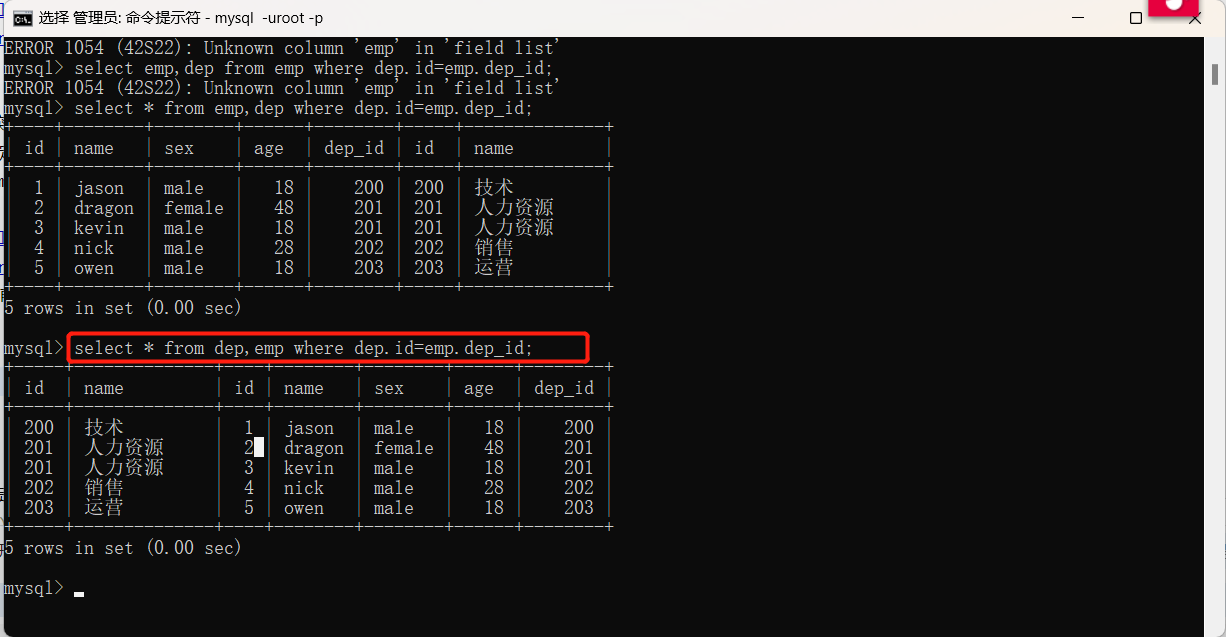
涉及到两张表对应时,字段很容易冲突,针对上述情况我们称之为'笛卡尔积'。解决笛卡尔积的办法是我们在字段前面加上表名来指定。
select * from emp,dep where emp.dep_id=dep.id;
emp,dep的顺序不能颠倒,如果dep在前就是查看字段dep并且把emp中匹配的数据匹配进去
作业
1. 查询岗位名以及岗位包含的所有员工名字
select post,group_concat(name) from emp group by post;
2. 查询岗位名以及各岗位内包含的员工个数
select post,count(name) from emp group by post;
3. 查询公司内男员工和女员工的个数
select gender,count(gender) from emp group by gender;
4. 查询岗位名以及各岗位的平均薪资
select post,avg(salary) from emp group by post;
5. 查询岗位名以及各岗位的最高薪资
select post,max(salary) from emp group by post;
6. 查询岗位名以及各岗位的最低薪资
select post,min(salary) from emp group by post;
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select gender,avg(salary) from emp group by gender;
8. 统计各部门年龄在30岁以上的员工平均工资
select post,avg(salary) from emp where age > 30 group by post;
MySQL-SQL语句查询关键字的更多相关文章
- SQL语句查询关键字中含有特殊符号怎么处理, 例如 'SMI_'
SQL语句查询关键字中含有特殊符号怎么处理, 例如 'SMI_' 错误:select * from emp where ename like '%SML_%' 正确:select * from em ...
- python 3 mysql sql逻辑查询语句执行顺序
python 3 mysql sql逻辑查询语句执行顺序 一 .SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_t ...
- mysql统计类似SQL语句查询次数
mysql统计类似SQL语句查询次数 vc-mysql-sniffer 工具抓取的sql分析. 1.先用shell脚本把所有enter符号替换为null,再根据语句前后的字符分隔语句 grep -Ev ...
- mysql / pgsql 使用sql语句查询数据库所有表注释已经表字段注释
mysql使用sql语句查询数据库所有表注释已经表字段注释(转载) 场景: 1. 要查询数据库 "mammothcode" 下所有表名以及表注释 /* 查询数据库 ‘mammo ...
- 浅谈MySQL中优化sql语句查询常用的30种方法 - 转载
浅谈MySQL中优化sql语句查询常用的30种方法 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中使 ...
- 程序员实用的 MySQL sql 语句
这儿只讲究实用, 程序员编程时常用到的 MySQL的 sql语句(不包括基本的 select, update, delete 等语句). 1. 添加一个用户build,并赋予所有权限的命令 gran ...
- MYSQL SQL语句技巧初探(一)
MYSQL SQL语句技巧初探(一) 本文是我最近了解到的sql某些方法()组合实现一些功能的总结以后还会更新: rand与rand(n)实现提取随机行及order by原理的探讨. Bit_and, ...
- 怎样用SQL语句查询一个数据库中的所有表?
怎样用SQL语句查询一个数据库中的所有表? --读取库中的所有表名 select name from sysobjects where xtype='u'--读取指定表的所有列名select nam ...
- mysql sql语句大全(转载)
1.说明:创建数据库 CREATE DATABASE database-name 2.说明:删除数据库 drop database dbname 3.说明:备份sql server --- 创建 ...
- [转]关于oracle sql语句查询时表名和字段名要加双引号的问题
oracle初学者一般会遇到这个问题. 用navicat可视化创建了表,可是就是不能查到! 后来发现②语句可以查询到 ①select * from user; 但是,我们如果给user加上双引 ...
随机推荐
- Mp3文件标签信息读取和写入(Kotlin)
原文:Mp3文件标签信息读取和写入(Kotlin) - Stars-One的杂货小窝 最近准备抽空完善了自己的星之小说下载器(JavaFx应用 ),发现下载下来的mp3文件没有对应的标签 也是了解可以 ...
- SpringBoot启动流程源码分析
前言 SpringBoot项目的启动流程是很多面试官面试中高级Java程序员喜欢问的问题.这个问题的答案涉及到了SpringBoot工程中的源码,也许我们之前看过别的大牛写过的有关SpringBoot ...
- perl使用print输入数据到文件
#!usr/bin/perl use utf8; #引入utf8模块 脚本内的字符串使用utf8作为编码格式 binmode(STDOUT,":encoding(gbk)"); # ...
- Java 中经常被提到的 SPI 到底是什么?
layout: post categories: Java title: Java 中经常被提到的 SPI 到底是什么? tagline: by 子悠 tags: - 子悠 Java 程序员在日常工作 ...
- python仿写js算法二
前言 之前写过一篇用python 仿写 js 算法,当时以为大部分语法都已经能很好的在python找到对应的语法结构,直到前几天我用 python 仿写了 慕课网解析视频加密的算法,我发现很多之前没遇 ...
- oracle 内置函数(二)字符函数
主要函数: 大小写转换函数 获取子字符串函数(字符串截取) 获取字符串长度函数 字符串连接函数 去除子字符串函数 字符替换函数 字符串出现次数 字符串按照特定符号拆分多行 一.大小写转换 1.uppe ...
- [.NET学习]EFCore学习之旅 -2 简单的增删改查
1.实例化创建数据库上下文类 首先实例化一个数据库操作上下文类,注意到DbContext实现了IDisposable接口,所以使用using语句,避免内存泄露. 2.插入 以Person类为例,先生成 ...
- 【Java EE】Day05 JDBC概念、对象、控制事务
一.基本概念 1.概念 Java Database Connectivity:Java数据库连接 2.本质 SUN公司提供的操作所有关系型数据库的规则,是一套接口 各厂商实现此接口,提供相应的驱动ja ...
- bug处理记录:Error running 'WorkflowApplication': Command line is too long. Shorten command line for WorkflowApplication or also for Spring Boot default configuration?
1.报错信息 Error running 'WorkflowApplication': Command line is too long. Shorten command line for Workf ...
- python循环结构之while循环
在python中,除了for循环,还有一个while循环 for循环:循环次数是明确了的 while循环:循环次数不确定,循环停止条件由用户自定义 # while语句结构 while 判断条件: 执行 ...