Pisa-Proxy 之 SQL 解析实践
SQL 语句解析是一个重要且复杂的技术,数据库流量相关的 SQL 审计、读写分离、分片等功能都依赖于 SQL 解析,而 Pisa-Proxy 作为 Database Mesh 理念的一个实践,对数据库流量的治理是其核心,因此实现 SQL 解析是一项很重要的工作。本文将以 Pisa-Proxy 实践为例,为大家展现 Pisa-Proxy 中的 SQL 解析实现,遇到的问题及优化。
一、背景
关于语法分析
语法分析一般通过词法分析器,如 Flex,生成相应的 token,语法分析器通过分析 token,来判断是否满足定义的语法规则。
语法分析器一般会通过解析生成器生成。
语法分析算法常用的有以下:
- LL(自上而下)
与上下文无关文法,从左到右扫描,从最左推导语法树,相比 LR 更容易理解,错误处理更友好。
- LR(自下而上)
与上下文无关文法,从左到右扫描,从最右节点推导语法树,相比 LL 速度快。
- LALR
与 LR 类似,在解析时比 LR 生成的状态更少,从而减少 Shift/Reduce 或者 Reduce/Reduce 冲突,被业界广泛使用的 bison/yacc 生成的就是基于 LALR 解析器。
关于调研
在开发 SQL 解析之初,我们从性能、维护性、开发效率、完成度四方面分别调研了 antlr_rust,sqlparser-rs,nom-sql 项目,但都存在一些问题。
ShardingSphere 实现了基于 Antlr 的不同的 SQL 方言解析,为了使用它的 Grammar,我们调研了 antlr_rust 项目,此项目不够活跃,成熟度不够高。
在 Rust 社区里,sqlparser-rs 项目是一个较为成熟的库,兼容各种 SQL 方言,Pisa-Proxy 在未来也会支持多种数据源,但是由于其词法和语法解析都是纯手工打造的,对我们来说会不易维护。
nom-sql 是基于 nom 库实现的 SQL 解析器,但是未实现完整,性能测试不如预期。
Grmtools 是在寻找 Rust 相关的 Yacc 实现时发现的库,该库实现了兼容绝大部分 Yacc 功能,这样就可以复用 MySQL 官方的语法文件,但是需要手写 Lex 词法解析,经过对开发效率及完成度权衡后,我们决定做难且正确的事,实现自己的 SQL 解析器,快速实现一个 Demo 进行测试。
编码完成后,测试效果还不错。
总结如下:
| 工具 | antlr_rust | sqlparser-rs | nom-sql | grmtools |
|---|---|---|---|---|
| 完成度 | ||||
| 性能 | ||||
| 维护性 | ||||
| 开发效率 |
最终我们选择了 Grmtools 来开发 Pisa-Proxy 中的 SQL 解析。
二、Grmtools 使用
使用 Grmtools 解析库大致分为两个步骤,下面以实现计算器为例。
- 编写 Lex 和 Yacc 文件
Lex:创建 calc.l,内容如下:
/%%
[0-9]+ "INT"
\+ "+"
\* "*"
\( "("
\) ")"
[\t ]+ ;
Grammar:创建 calc.y 内容如下:
%start Expr
%avoid_insert "INT"
%%
Expr -> Result<u64, ()>:
Expr '+' Term { Ok($1? + $3?) }
| Term { $1 }
;
Term -> Result<u64, ()>:
Term '*' Factor { Ok($1? * $3?) }
| Factor { $1 }
;
Factor -> Result<u64, ()>:
'(' Expr ')' { $2 }
| 'INT'
{
let v = $1.map_err(|_| ())?;
parse_int($lexer.span_str(v.span()))
}
;
%%
- 构造词法和语法解析器
Grmtools 需要在编译时生成词法和语法解析器,因此需要创建 build.rs,其内容如下:
use cfgrammar::yacc::YaccKind;
use lrlex::CTLexerBuilder;
fn main() -> Result<(), Box<dyn std::error::Error>> {
CTLexerBuilder::new()
.lrpar_config(|ctp| {
ctp.yacckind(YaccKind::Grmtools)
.grammar_in_src_dir("calc.y")
.unwrap()
})
.lexer_in_src_dir("calc.l")?
.build()?;
Ok(())
}
- 在应用中集成解析
use std::env;
use lrlex::lrlex_mod;
use lrpar::lrpar_mod;
// Using `lrlex_mod!` brings the lexer for `calc.l` into scope. By default the
// module name will be `calc_l` (i.e. the file name, minus any extensions,
// with a suffix of `_l`).
lrlex_mod!("calc.l");
// Using `lrpar_mod!` brings the parser for `calc.y` into scope. By default the
// module name will be `calc_y` (i.e. the file name, minus any extensions,
// with a suffix of `_y`).
lrpar_mod!("calc.y");
fn main() {
// Get the `LexerDef` for the `calc` language.
let lexerdef = calc_l::lexerdef();
let args: Vec<String> = env::args().collect();
// Now we create a lexer with the `lexer` method with which we can lex an
// input.
let lexer = lexerdef.lexer(&args[1]);
// Pass the lexer to the parser and lex and parse the input.
let (res, errs) = calc_y::parse(&lexer);
for e in errs {
println!("{}", e.pp(&lexer, &calc_y::token_epp));
}
match res {
Some(r) => println!("Result: {:?}", r),
_ => eprintln!("Unable to evaluate expression.")
}
}
上文已经提到,我们需要手写词法解析,是因为在原生的 Grmtools 中,词法解析是用正则匹配的,对于灵活复杂的 SQL 语句来说,不足以满足,因此需要手工打造词法解析,在 Grmtools 中实现自定义词法解析需要我们实现以下 Trait:
lrpar::NonStreamingLexer
另外也提供了一个方便的方法去实例化:
lrlex::LRNonStreamingLexer::new()
三、遇到的问题
基于以上,我们开发了 SQL 词法解析,复用了 MySQL 官方的 sql_yacc 文件,在开发过程中,也遇到了以下问题。
- Shift/Reduce 错误
Shift/Reduce conflicts:
State 619: Shift("TEXT_STRING") / Reduce(literal: "text_literal")
这是使用 LALR 算法经常出现的错误,错误成因一般通过分析相关规则解决,例如常见的 If-Else 语句,规则如下:
%nonassoc LOWER_THEN_ELSE
%nonassoc ELSE
stmt:
IF expr stmt %prec LOWER_THEN_ELSE
| IF expr stmt ELSE stmt
当 ELSE 被扫描入栈时,此时会有两种情况。
1)按第二条规则继续 Shift
2)按第一条规则进行 Reduce
这就是经典的 Shift/Reduce 错误。
回到我们的问题,有如以下规则:
literal -> String:
text_literal
{ }
| NUM_literal
{ }
...
text_literal -> String:
'TEXT_STRING' {}
| 'NCHAR_STRING' {}
| text_literal 'TEXT_STRING' {}
...
分析:
| stack | Input token | action |
|---|---|---|
| test | Shift test | |
| test | $ | Reduce: text_literal/Shift: TEXT_STRING |
方案:
需要设置优先级解决,给 text_literal 设置更低的优先级,如以下:
%nonassoc 'LOWER_THEN_TEXT_STRING'
%nonassoc 'TEXT_STRING'
literal -> String:
text_literal %prec 'LOWER_THEN_TEXT_STRING'
{ }
| NUM_literal
{ }
...
text_literal -> String:
'TEXT_STRING' {}
| 'NCHAR_STRING' {}
| text_literal 'TEXT_STRING' {}
...
- SQL 包含中文问题
在使用词法解析时,.chars() 生成字符串数组会出现数组长度和字符长度不一致的情况,导致解析出错,要更改为 .as_bytes() 方法。
四、优化
- 在空跑解析(测试代码见附录),不执行 action 的情况下,性能如下:
[mworks@fedora examples]$ time ./parser
real 0m4.788s
user 0m4.781s
sys 0m0.002s
尝试优化,以下是火焰图:

通过火焰图发现,大部分 CPU 耗时在序列化和反序列化,以下是定位到的代码:
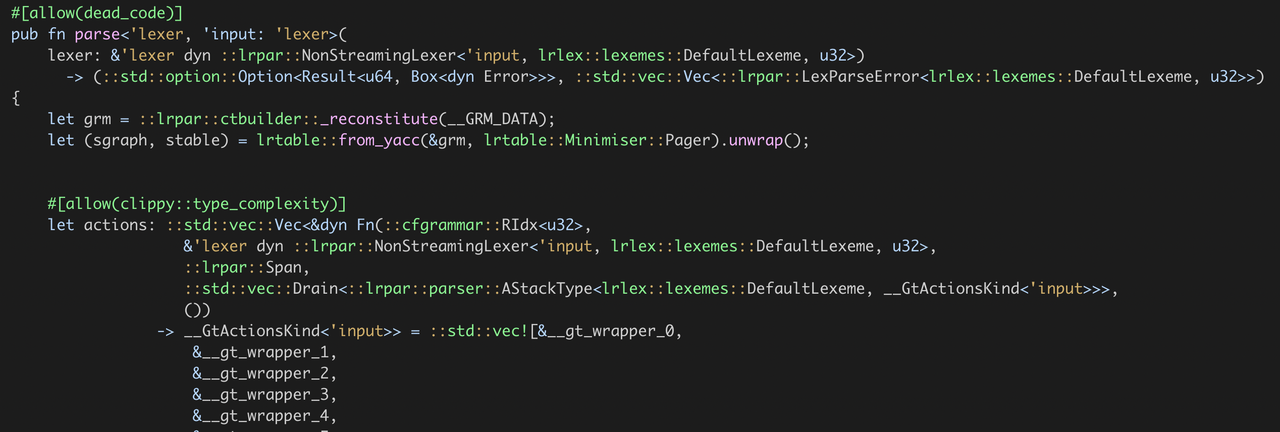
可以看出在每次解析的时候都需要反序列化数据,在编译完之后,__GRM_DATA 和 __STABLE_DATA 是固定不变的, 因此 grm,stable 这两个参数可以作为函数参数传递,更改为如下:
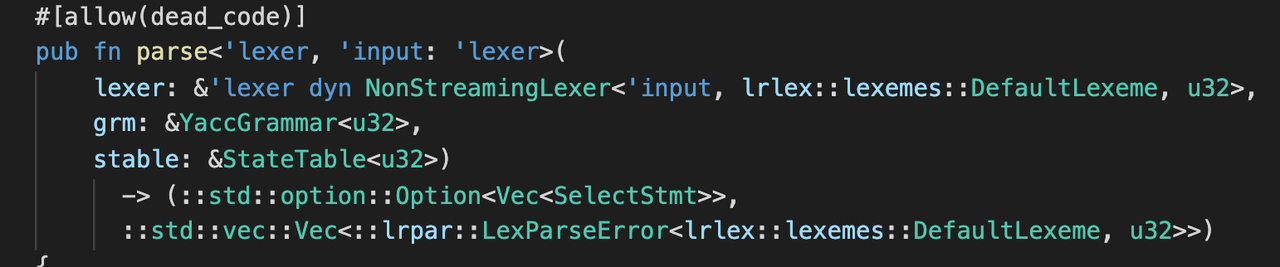
- 再分析,每次解析的时候,都会初始化一个 actions 的数组,随着 grammar 中语法规则的增多,actions 的数组也会随之增大,且数组元素类型是 dyn trait 的引用,在运行时是有开销的。
再看代码,发现 actions 数组是有规律的,如以下:
::std::vec![&__gt_wrapper_0,
&__gt_wrapper_1,
&__gt_wrapper_2,
...
]
因此我们可以手动构造函数,以下是伪代码:
match idx {
0 => __gt_wrapper_0(),
1 => __gt_wrapper_1(),
2 => __gt_wrapper_2(),
....
}
通过 gobolt 查看汇编,发现差异还是很大,省去了数组的相关开销,也能极大地减少内存使用。

详见:https://rust.godbolt.org/z/zTjW479f6
但是随着 actions 数组的不断增大,会有大量的 je,jmp 指令,不清楚是否会影响 CPU 的分支预测,如影响是否可以通过 likely/unlikely 方式优化,目前还没有进行测试。
最终火焰图对比
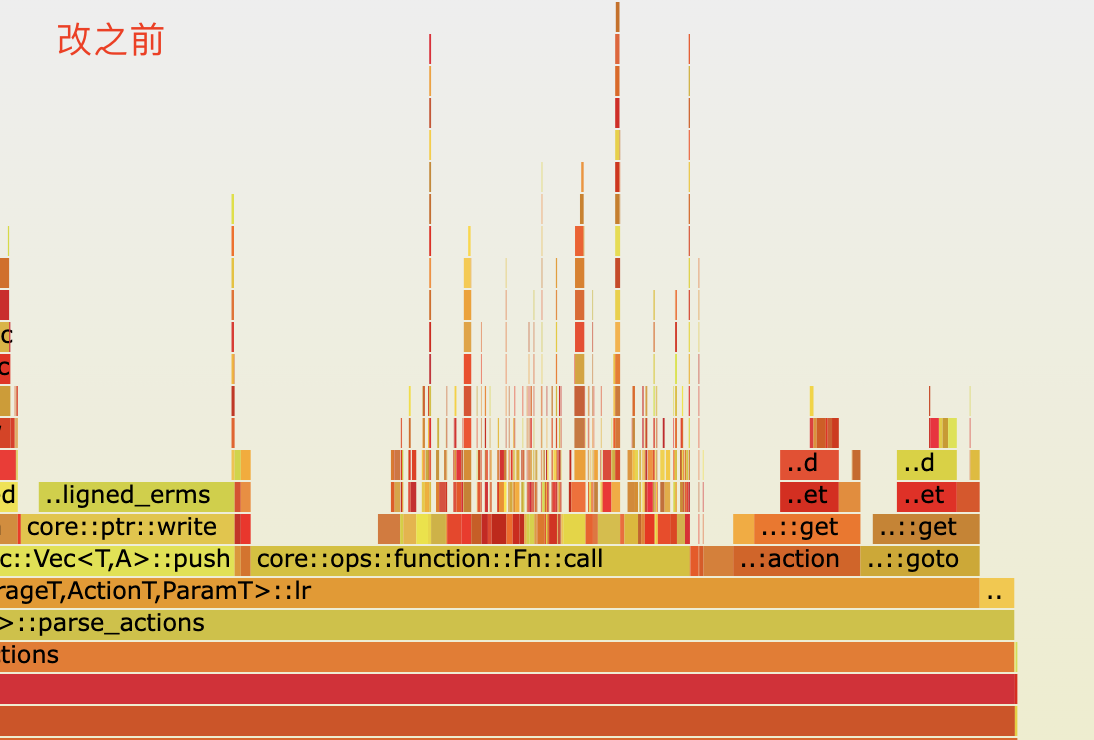
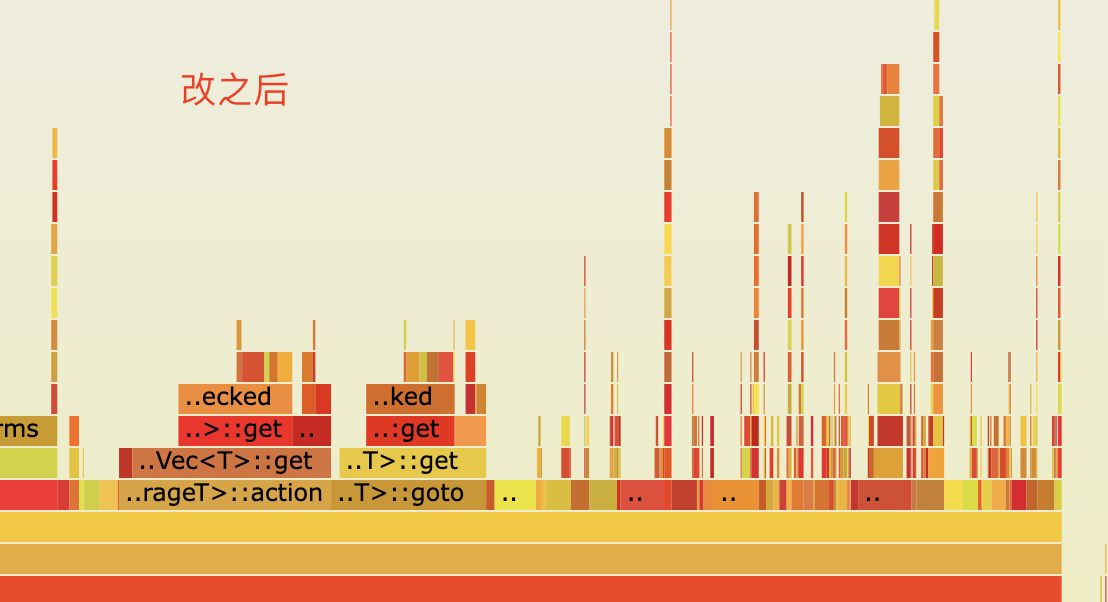
最终测试结果
[mworks@fedora examples]$ time ./parser
real 0m2.677s
user 0m2.667s
sys 0m0.007s
五、总结
本文为 Pisa-Proxy SQL 解析解读系列第一篇,介绍了在 Pisa-Proxy 中开发 SQL 解析背后的故事,后续我们会陆续为大家详细介绍 Yacc 语法规则的编写,Grmtools 中组件及实用工具等内容,敬请期待。
附录
Pisa-Proxy 的 SQL 解析代码:
pisanix/pisa-proxy/parser/mysql at master · database-mesh/pisan
测试代码
let input = "select id, name from t where id = ?;"
let p = parser::Parser::new();
for _ in 0..1_000_000
{
let _ = p.parse(input);
}
Pisanix
项目地址:https://github.com/database-mesh/pisanix
Database Mesh:https://www.database-mesh.io/
SphereEx 官网:https://www.sphere-ex.com
Pisa-Proxy 之 SQL 解析实践的更多相关文章
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序来 ...
- MySQL架构总览->查询执行流程->SQL解析顺序
Reference: https://www.cnblogs.com/annsshadow/p/5037667.html 前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后 ...
- 如何实现一个SQL解析器
作者:vivo 互联网搜索团队- Deng Jie 一.背景 随着技术的不断的发展,在大数据领域出现了越来越多的技术框架.而为了降低大数据的学习成本和难度,越来越多的大数据技术和应用开始支持SQL进 ...
- Spark之SQL解析(源码阅读十)
如何能更好的运用与监控sparkSQL?或许我们改更深层次的了解它深层次的原理是什么.之前总结的已经写了传统数据库与Spark的sql解析之间的差别.那么我们下来直切主题~ 如今的Spark已经支持多 ...
- 高大上技术之sql解析
Question: 为何sql解析和高大上有关系?Answer:因为数据库永远都是系统的核心,CRUD如此深入码农的内心...如果能把CRUD改造成高大上技术,如此不是造福嘛... CRUD就是Cre ...
- sql 解析字符串添加到临时表中 sql存储过程in 参数输入
sql 解析字符串添加到临时表中 sql存储过程in 参数输入 解决方法 把字符串解析 添加到 临时表中 SELECT * into #临时表 FROM dbo.Func_SplitOneCol ...
- oracle 内存结构 share pool sql解析的过程
1.sql解析的过程 oracle首先将SQL文本转化为ASCII字符,然后根据hash函数计算其对应的hash值(hash_value).根据计算出的hash值到library cache中找到对应 ...
- 基于简单sql语句的sql解析原理及在大数据中的应用
基于简单sql语句的sql解析原理及在大数据中的应用 李万鸿 老百姓呼吁打土豪分田地.共同富裕,总有一天会实现. 全面了解你所不知道的外星人和宇宙真想:http://pan.baidu.com/s/1 ...
- 自己实现一个SQL解析引擎
自己实现一个SQL解析引擎 功能:将用户输入的SQL语句序列转换为一个可运行的操作序列,并返回查询的结果集. SQL的解析引擎包含查询编译与查询优化和查询的执行,主要包含3个步骤: 查询分析: 制定逻 ...
随机推荐
- 基于kubernetes的分布式限流
做为一个数据上报系统,随着接入量越来越大,由于 API 接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机 ...
- AcWing 【算法提高课】笔记02——搜索
搜索进阶 22.4.14 (PS:还有 字串变换 A*两题 生日蛋糕 回转游戏 没做) 感觉暂时用不上 BFS 1. Flood Fill 在线性时间复杂度内,找到某个点所在的连通块 思路 统计连通块 ...
- Java语言学习day31--8月06日
今日内容介绍1.正则表达式的定义及使用2.Date类的用法3.Calendar类的用法 ###01正则表达式的概念和作用 * A: 正则表达式的概念和作用 * a: 正则表达式的概述 * 正则表达式也 ...
- Java中时间类中的Data类与Time类
小简博客 - 小简的技术栈,专注Java及其他计算机技术.互联网技术教程 (ideaopen.cn) Data类 Data类中常用方法 boolean after(Date date) 若当调用此方法 ...
- GO 前后端分离开源后台管理系统 Gfast v2.0.4 版发布
更新内容:1.适配插件商城,开发环境从后台直接安装插件功能:2.代码生成细节修复及功能完善(支持生成上传文件.图片及富文本编辑器功能):3.增加swagger接口文档生成:4.更新goframe版本至 ...
- 关于fiddler抓包一键生成python脚本
本人贡献一篇关于抓包转换成脚本的文章 步骤一 打开fiddler,抓到包之后,保存成txt文件 步骤二 脚本里str_filename改成保存的文件名 步骤三 执行脚本一键转换 附上脚本,感谢关注~ ...
- BootstrapBlazor实战 Menu 导航菜单使用(1)
实战BootstrapBlazorMenu 导航菜单的使用, 以及整合Freesql orm快速制作菜单项数据库后台维护页面 demo演示的是Sqlite驱动,FreeSql支持多种数据库,MySql ...
- 新华三Gen10服务器ilo5中刷新bios固件
新华三Gen10服务器ilo5中刷新bios固件. 当前bios1.42 已经是最新了. 固件下载后解压缩. 选择刷新固件. 点击浏览.flash文件. 点击flash 点击ok确认 开始上传 刷新进 ...
- ReLabel:自动将ImageNet转化成多标签数据集,更准确地有监督训练 | 2021新文
人工标注数据集中普遍存在噪声,ReLabel能够自动且低成本地将原本的单标签数据集转化为多标签数据集,并且提出配合random crop使用的高效LabelPooling方法,能够更准确地指导分类网络 ...
- Keepalived入门学习
一个执着于技术的公众号 Keepalived简介 Keepalived 是使用C语言编写的路由热备软件,该项目软件起初是专门为LVS负载均衡设计的,用来管理并监控LVS集群系统中各个服务节点的状态,后 ...