在Yarn集群上跑spark wordcount任务
- 准备的测试数据文件hello.txt
hello scalahello worldnihao helloi am scalathis is spark demogan jiu wan le
- 将文件上传到hdfs中
#创建hdfs测试目录hdfs dfs -mkdir /user/spark/input/#上传本地文件hello.txt到hdfshdfs dfs -put ./hello.txt /user/spark/input/
- 代码(改为读取hdfs上的数据,并写入hdfs)
package org.exampleimport org.apache.spark.{SparkConf, SparkContext}/*** spark-submit --master yarn --class org.example.SparkWordCountYarn /tmp/test/sparkwordcount2-1.0-SNAPSHOT.jar hdfs://hadoop1:8020/user/spark/input/hello.txt hdfs://hadoop1:8020/user/spark/output/helloOutput*/object SparkWordCountYarn {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("WordCount").setMaster("yarn")val srcFile = args(0)val outPutFile = args(1)val sc = new SparkContext(conf)val data = sc.textFile(srcFile)data.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).saveAsTextFile(outPutFile)}}
- 执行提交spark人物命令
spark-submit --master yarn --class org.example.SparkWordCountYarn /tmp/test/sparkwordcount2-1.0-SNAPSHOT.jar hdfs://hadoop1:8020/user/spark/input/hello.txt hdfs://hadoop1:8020/user/spark/output/helloOutput
- 执行结果
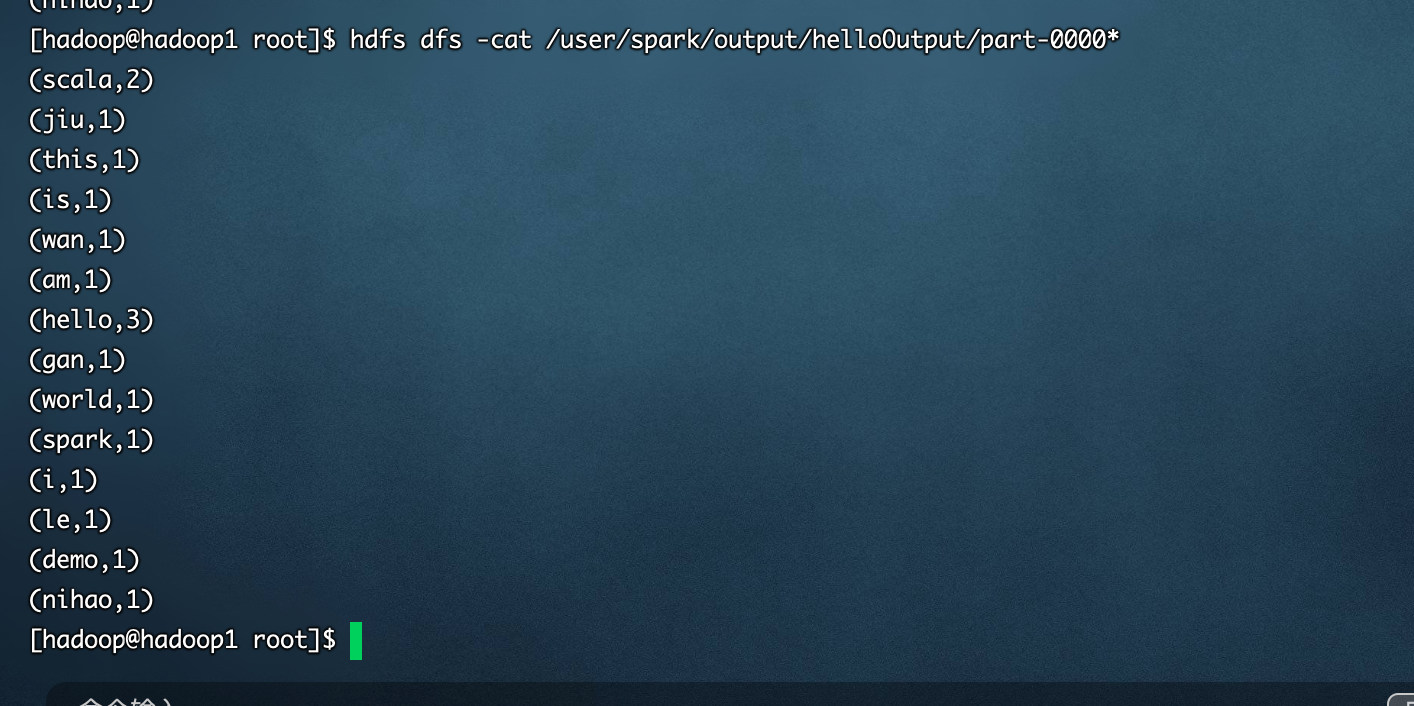
在Yarn集群上跑spark wordcount任务的更多相关文章
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- 在集群上运行Spark
Spark 可以在各种各样的集群管理器(Hadoop YARN.Apache Mesos,还有Spark 自带的独立集群管理器)上运行,所以Spark 应用既能够适应专用集群,又能用于共享的云计算环境 ...
- 有关python numpy pandas scipy 等 能在YARN集群上 运行PySpark
有关这个问题,似乎这个在某些时候,用python写好,且spark没有响应的算法支持, 能否能在YARN集群上 运行PySpark方式, 将python分析程序提交上去? Spark Applicat ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- Spark学习笔记——在集群上运行Spark
Spark运行的时候,采用的是主从结构,有一个节点负责中央协调, 调度各个分布式工作节点.这个中央协调节点被称为驱动器( Driver) 节点.与之对应的工作节点被称为执行器( executor) 节 ...
- 《Spark快速大数据分析》—— 第七章 在集群上运行Spark
- Spark程序提交到Yarn集群时所遇异常
Exception 1:当我们将任务提交给Spark Yarn集群时,大多会出现以下异常,如下: 14/08/09 11:45:32 WARN component.AbstractLifeCycle: ...
- Spark on Yarn 集群运行要点
实验版本:spark-1.6.0-bin-hadoop2.6 本次实验主要是想在已有的Hadoop集群上使用Spark,无需过多配置 1.下载&解压到一台使用spark的机器上即可 2.修改配 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
随机推荐
- Python Excel 操作
1.Excel Code import os import time import re import win32com.client def dealpath(pathname='') -> ...
- WPF开发随笔收录-本地日志LogUtil类
一.前言 生活中的日志是记录你生活的点点滴滴,让它把你内心的世界表露出来,更好的诠释自己的内心世界.而在开发者眼中的日志是我们排除问题的第一手资料,项目中的程序上线之后,一旦发生异常,第一件事就是先去 ...
- dubbox、zookeeper BUG记录
主要错误信息: dubbo:com.alibaba.dubbo.rpc.RpcException: Failed to invoke the method... Caused by: com.alib ...
- UiPath图片操作截图的介绍和使用
一.截图(Take Screenshot)的介绍 截取指定的UI元素屏幕截图的一种活动,输出量仅支持图像变量(image) 二.Take Screenshot在UiPath中的使用 1. 打开设计器, ...
- python小题目练习(九)
题目:将美元转化为人民币 需求:实现如图所示需求 代码展示: """Author:mllContent:将美元转化为人民币Date:2020-11-23"&q ...
- Windows 启动过程
引言 启动过程是我们了解操作系统的第一个环节.了解 Windows 的启动过程,可以帮助我们解决一些启动的问题,也能帮助我们了解 Windows 的整体结构. 以下内容将分为[加载内核].[内核初始化 ...
- 还在因为部署 Kubernetes 时,无法拉取 k8s.gcr.io/*** 镜像而头疼吗
拉取外网 Kubernetes 镜像 还在因为部署 Kubernetes 时,无法拉取 k8s.gcr.io/*** 镜像而头疼吗? 传送门 https://github.com/liamhao/pu ...
- 6 分钟看完 BGP 协议。
上一篇文章见 万字长文爆肝路由协议! 上面我们聊 RIP .OSPF 协议都是基于 AS 即自治系统内的协议,可以把它们认为是域内路由协议:而下面我们要聊的就是 AS 之间的协议了,这也叫做域间路由协 ...
- JavaScript进阶知识点——函数和对象详解
JavaScript进阶知识点--函数和对象详解 我们在上期内容中学习了JavaScript的基本知识点,今天让我们更加深入地了解JavaScript JavaScript函数 JavaScript函 ...
- 0基础就可以上手的Spark脚本开发-for Java
前言 最近由于工作需要,要分析大几百G的Nginx日志数据.之前也有过类似的需求,但那个时候数据量不多.一次只有几百兆,或者几个G.因为数据都在Hive里面,当时的做法是:把数据从Hive导到MySQ ...