06 Spark SQL 及其DataFrame的基本操作
1.Spark SQL出现的 原因是什么?
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个叫作Data Frame的编程抽象结构数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrame API和Dataset API三种方式实现对结构化数据的处理。但无论是哪种API或者是编程语言,都是基于同样的执行引擎,因此可以在不同的API之间随意切换。
Spark SQL的前身是 Shark,Shark最初是美国加州大学伯克利分校的实验室开发的Spark生态系统的组件之一,它运行在Spark系统之上,Shark重用了Hive的工作机制,并直接继承了Hive的各个组件, Shark将SQL语句的转换从MapReduce作业替换成了Spark作业,虽然这样提高了计算效率,但由于 Shark过于依赖Hive,因此在版本迭代时很难添加新的优化策略,从而限制了Spak的发展,在2014年,伯克利实验室停止了对Shark的维护,转向Spark SQL的开发。
Shark Hive on Spark Hive即作为存储又负责sql的解析优化,Spark负责执行
SparkSQL Spark on Hive Hive只作为储存角色,Spark负责sql解析优化,执行
SparkSQL产生的根本原因是为了完全脱离Hive限制(解耦)
2.用spark.read 创建DataFrame
3.观察从不同类型文件创建DataFrame有什么异同?
txt文件:创建的DataFrame数据没有结构
json文件:创建的DataFrame数据有结构
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?
Spark SQL DataFrame的基本操作
spark.read.text()
file='file:///usr/local/spark/examples/src/main/resources/people.txt'
df=spark.read.text(file)

spark.read.json()
file='file:///usr/local/spark/examples/src/main/resources/people.json'
df1=spark.read.json(file)

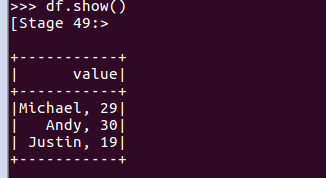
打印数据
df.show()默认打印前20条数据,df.show(n)

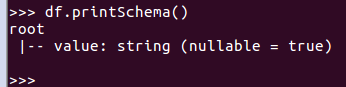
打印概要
df.printSchema()
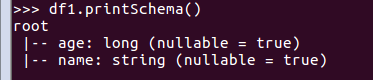
df1.printSchema()
查询总行数
df.count()
df1.count()

df.head(3) #list类型,list中每个元素是Row类
df.head(3)
df1.head(3)

输出全部行
df.collect() #list类型,list中每个元素是Row类
df.collect()
df1.collect()

查询概况
df.describe().show()

df1.describe().show()

取列
df[‘name’]
df1['name']
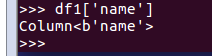
df.name
df1.name

df.select()
df1.select(df1.name).show()

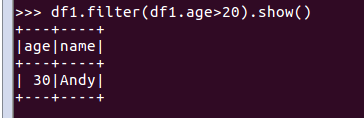
df.filter()
df1.filter(df1.age>20).show()
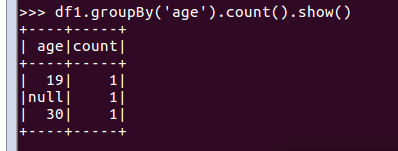
df.groupBy()
df1.groupBy('age').count().show()
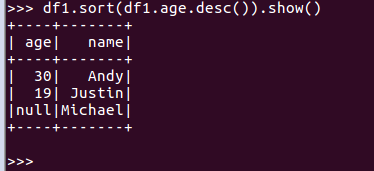
df.sort()
df1.sort(df1.age.desc()).show()
06 Spark SQL 及其DataFrame的基本操作的更多相关文章
- Spark SQL 之 DataFrame
Spark SQL 之 DataFrame 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述(Overview) Spark SQL是Spark的一个组件,用于结构化 ...
- spark结构化数据处理:Spark SQL、DataFrame和Dataset
本文讲解Spark的结构化数据处理,主要包括:Spark SQL.DataFrame.Dataset以及Spark SQL服务等相关内容.本文主要讲解Spark 1.6.x的结构化数据处理相关东东,但 ...
- Spark SQL、DataFrame和Dataset——转载
转载自: Spark SQL.DataFrame和Datase
- 转】Spark SQL 之 DataFrame
原博文出自于: http://www.cnblogs.com/BYRans/p/5003029.html 感谢! Spark SQL 之 DataFrame 转载请注明出处:http://www.cn ...
- Spark官方1 ---------Spark SQL和DataFrame指南(1.5.0)
概述 Spark SQL是用于结构化数据处理的Spark模块.它提供了一个称为DataFrames的编程抽象,也可以作为分布式SQL查询引擎. Spark SQL也可用于从现有的Hive安装中读取数据 ...
- Spark SQL and DataFrame Guide(1.4.1)——之DataFrames
Spark SQL是处理结构化数据的Spark模块.它提供了DataFrames这样的编程抽象.同一时候也能够作为分布式SQL查询引擎使用. DataFrames DataFrame是一个带有列名的分 ...
- Spark学习之路(八)—— Spark SQL 之 DataFrame和Dataset
一.Spark SQL简介 Spark SQL是Spark中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将SQL查询与Spark程序无缝混合,允许您使用SQL或DataFrame AP ...
- Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
一.Spark SQL简介 Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 Da ...
- spark sql 创建DataFrame
SQLContext是创建DataFrame和执行SQL语句的入口 通过RDD结合case class转换为DataFrame 1.准备:hdfs上提交一个文件,schema为id name age, ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
随机推荐
- 通过 HDU 2048 来初步理解动态规划
HDU 2048 数塔 问题描述: 题目链接-点我查看题目 给出一个数塔,要求从顶层走到底层,每一步只能从高层走到相邻的低层节点,求经过的结点的数字之和最大是多少? 动态规划的定义 dynam ...
- 南大ics-pa/PA0过程及感想
实验教程地址:https://nju-projectn.github.io/ics-pa-gitbook/ics2022/index.html 一.Ubuntu安装 在清华大学镜像站下载了Ubuntu ...
- Camstar代码:指定执行某函数
- SVN: E155004: THERE ARE UNFINISHED WORK ITEMS IN ''; RUN 'SVN CLEANUP' FIRST
eclipse的SVN更新或者还原都报错 使用clean up也不好用 解决办法 通过网址https://www.sqlite.org/download.html下载这个软件 解压放到.svn文件夹下 ...
- ipmitool for windows下载网址
ipmitool for windows版本下载网址 http://ipmiutil.sourceforge.net/
- jmeter 添加断言和查看断言结果
在对应的请求下添加响应断言,这里我们添加响应文本来作为检查点,来检查上面的这个请求是否成功 断言和断言结果是成对出现的,是为了检查我们添加的断言是否验证成功,如下图,如果成功,里面就会有对应的结果,且 ...
- CentOS 6.7 hadoop free版本Spark 1.6安装与使用
最近的工作主要围绕文本分类,当前的解决方案是用R语言清洗数据,用tm包生成bag of words,用libsvm与liblinear训练模型.这个方案可以hold住6/70万的训练集: LIBLIN ...
- kafka日志数据清理策略
vim /kafka/server.properties # 日志清理策略优先级是谁先满足条件. # 保留7天的日志数据 log.retention.hours=168 # 日志数据总大小保留100G ...
- nop 中创建任务(Task)
NopCommerce 中Task 原理是服务端开启线程定时跑. 1.在数据表ScheduleTask中添加一条数据, 2.自定义类,继承ITask 即可 using Data.Log4Net; us ...
- .Net Core WebApi 控制器自动创建文件夹上传图片
/// <summary> /// 异步图片或文件上传 /// </summary> /// <param name="formFile">&l ...