Hadoop(三)通过C#/python实现Hadoop MapReduce
MapReduce
Hadoop中将数据切分成块存在HDFS不同的DataNode中,如果想汇总,按照常规想法就是,移动数据到统计程序:先把数据读取到一个程序中,再进行汇总。
但是HDFS存的数据量非常大时,对汇总程序所在的服务器将产生巨大压力,并且网络IO也十分消耗资源。
为了解决这种问题,MapReduce提出一种想法:将统计程序移动到DataNode,每台DataNode(就近)统计完再汇总,充分利用DataNode的计算资源。YARN的调度决定了MapReduce程序所在的Node。
MapReduce过程
- 确保数据存在HDFS上
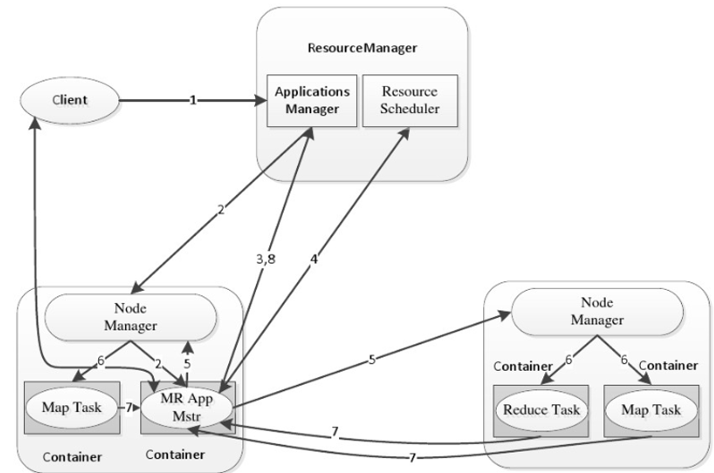
- MapReduce提交给ResourceManager(RM),RM创建一个Job。
- 文件分片,默认将一个数据块作为一个分片。
- Job提交给RM,RM根据Node状态选择一台合适的Node调度AM,AM向RM申请资源,RM调度合适的NM启动Container,Container执行Task。
- Map的输出放入环形内存缓冲区,缓存溢出时,写入磁盘,写入磁盘有以下步骤
- 默认根据Hash分区,分区数取决于Reduce Task的数,相同Key的记录被送到相同Reduce处理
- 将Map输出的结果排序
- 将Map数据合并
- MapTask处理后产生多个溢出文件,会将多个溢出文件合并,生成一个经过分区和排序的MapOutFile(MOF),这个过程称为Spill
- MOF输出到3%时开始进行Reduce Task
- MapTask与ReduceTask之间传输数据的过程称为Shuffle。
下面这个图描述了具体的流程
Hadoop Streaming
Hadoop中可以通过Java来编写MapReduce,针对不熟悉Java的开发者,Hadoop提供了通过可执行程序或者脚本的方式创建MapReduce的Hadoop Streaming。
Hadoop streaming处理步骤
hadoop streaming通过用户编写的map函数中标准输入读取数据(一行一行地读取),按照map函数的处理逻辑处理后,将处理后的数据由标准输出进行输出到下一个阶段,reduce函数也是按行读取数据,按照函数的处理逻辑处理完数据后将它们通过标准输出写到hdfs的指定目录中。不管使用的是何种编程语言,在map函数中,原始数据会被处理成<key,value>的形式,但是key与value之间必须通过\t分隔符分隔,分隔符左边的是key,分隔符右边的是value,如果没有使用\t分隔符,那么整行都会被当作Python编写MapReducer
C#版MapReduce
首先,新增测试数据
vi mpdata I love Beijing
I love China
Beijing is the capital of China
然后,将文件上传到hdfs
[root@localhost ~]# hadoop fs -put mrdata /chesterdata
新建dotnet6的console项目mapper,修改Program.cs
using System;
using System.Text.RegularExpressions; namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
发布mapper
cd /demo/dotnet/mapper/
dotnet publish -c Release -r linux-x64 /p:PublishSingleFile=true
新建dotnet6的console项目reducer,修改Program.cs
using System;
using System.Collections.Generic; namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>(); string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]); //Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
发布reducer
/demo/dotnet/reducer
dotnet publish -c Release -r linux-x64 /p:PublishSingleFile=true
执行mapepr reduce
hadoop jar /usr/local/hadoop323/hadoop-3.2.3/share/hadoop/tools/lib/hadoop-streaming-3.2.3.jar -input /chesterdata/mrdata -output /dotnetmroutput -mapper "./mapper" -reducer "./reducer" -file /demo/dotnet/mapper/bin/Release/net6.0/linux-x64/publish/mapper -f /demo/dotnet/reducer/bin/Release/net6.0/linux-x64/publish/reducer
查看mapreduce结果
[root@localhost reducer]# hadoop fs -ls /dotnetmroutput -rw-r--r-- 1 root supergroup 0 2022-05-01 16:40 /dotnetmroutput/_SUCCESS
-rw-r--r-- 1 root supergroup 55 2022-05-01 16:40 /dotnetmroutput/part-00000
查看part-00000内容
[root@localhost reducer]# hadoop fs -cat /dotnetmroutput/part-00000 Beijing 2
China 2
I 2
capital 1
is 1
love 2
of 1
the 1
可以看到dotnet模式的Hadoop Streaming已经执行成功。
Python版MapReduce
# mapper.py
import sys
import re
p = re.compile(r'\w+')
for line in sys.stdin:
words = line.strip().split(' ')
for word in words:
w = p.findall(word)
if len(w) < 1:
continue
s = w[0].strip().lower()
if s != "":
print("%s\t%s" % (s, 1))
编写reducer
# reducer.py
import sys
res = dict()
for word_one in sys.stdin:
word, one = word_one.strip().split('\t')
if word in res.keys():
res[word] = res[word] + 1
else:
res[word] = 1
print(res)
执行mapreduce
hadoop jar /usr/local/hadoop323/hadoop-3.2.3/share/hadoop/tools/lib/hadoop-streaming-3.2.3.jar -input /chesterdata/mrdata -output /mroutput -mapper "python3 mapper.py" -reducer "python3 reducer.py" -file /root/mapper.py -file /root/reducer.py
查看mapreduce结果
[root@localhost lib]# hadoop fs -ls /mroutput -rw-r--r-- 1 root supergroup 0 2022-05-01 05:00 /mroutput/_SUCCESS
-rw-r--r-- 1 root supergroup 89 2022-05-01 05:00 /mroutput/part-00000
查看part-00000内容
[root@localhost lib]# hadoop fs -cat /mroutput/part-00000
{'beijing': 2, 'capital': 1, 'china': 2, 'i': 2, 'is': 1, 'love': 2, 'of': 1, 'the': 1}
可以看到python模式的Hadoop Streaming已经执行成功。
Hadoop(三)通过C#/python实现Hadoop MapReduce的更多相关文章
- Python实现Hadoop MapReduce程序
1.概述 Hadoop Streaming提供了一个便于进行MapReduce编程的工具包,使用它可以基于一些可执行命令.脚本语言或其他编程语言来实现Mapper和 Reducer,从而充分利用Had ...
- [python]使用python实现Hadoop MapReduce程序:计算一组数据的均值和方差
这是参照<机器学习实战>中第15章“大数据与MapReduce”的内容,因为作者写作时hadoop版本和现在的版本相差很大,所以在Hadoop上运行python写的MapReduce程序时 ...
- Hadoop:使用原生python编写MapReduce
功能实现 功能:统计文本文件中所有单词出现的频率功能. 下面是要统计的文本文件 [/root/hadooptest/input.txt] foo foo quux labs foo bar quux ...
- 使用Python实现Hadoop MapReduce程序
转自:使用Python实现Hadoop MapReduce程序 英文原文:Writing an Hadoop MapReduce Program in Python 根据上面两篇文章,下面是我在自己的 ...
- 让python在hadoop上跑起来
duang~好久没有更新博客啦,原因很简单,实习啦-好吧,我过来这边上班表示觉得自己简直弱爆了.第一周,配置环境:第二周,将数据可视化,包括学习了excel2013的一些高大上的技能,例如数据透视表和 ...
- Hadoop三种安装模式:单机模式,伪分布式,真正分布式
Hadoop三种安装模式:单机模式,伪分布式,真正分布式 一 单机模式standalone单 机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守 ...
- [Hadoop源码解读](六)MapReduce篇之MapTask类
MapTask类继承于Task类,它最主要的方法就是run(),用来执行这个Map任务. run()首先设置一个TaskReporter并启动,然后调用JobConf的getUseNewAPI()判断 ...
- [Hadoop源码解读](一)MapReduce篇之InputFormat
平时我们写MapReduce程序的时候,在设置输入格式的时候,总会调用形如job.setInputFormatClass(KeyValueTextInputFormat.class);来保证输入文件按 ...
- 深入浅出Hadoop实战开发(HDFS实战图片、MapReduce、HBase实战微博、Hive应用)
Hadoop是什么,为什么要学习Hadoop? Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运 ...
随机推荐
- 运筹学之"简单平均预测法"和"加权滑动平均预测法"和"确定平滑系数"
1.简单滑动平均预测法就是将所有的售价加起来除以总数 665/5=133 2.加权滑动平均预测法:需要将售价分别乘以权之和,并除以权之和 1771/13≈136.23 二.某木材公司销售房架构件,其中 ...
- 『现学现忘』Docker基础 — 37、ONBUILD指令介绍
目录 1.ONBUILD指令说明 2.演示ONBUILD指令的使用 3.补充:crul命令解释 1.ONBUILD指令说明 ONBUILD是一个特殊的指令,它后面跟的是其它指令,比如 RUN, COP ...
- 安装Backstage.io应用
Backstage介绍 What's Backstage? Backstage is an open platform for building developer portals. Powered ...
- 微信小程序实时通讯(websocket)问题
这几天值班忙的不要不要,人工智能这块看的都是零零散散,今天就来写写小程序的实时通讯吧.小程序端://这个是连接 lianjie:function(){ var socketOpen = false / ...
- h5 ios输入框与键盘 兼容性优化
起因 h5的输入框引起键盘导致体验不好,目前就算微信.知乎.百度等产品也没有很好的技术方案实现,尤其底部固定位置的输入框各种方案都用的前提下体验也并没有很好,这个问题也是老大难问题了.目前在准备一套与 ...
- vue+koa2即时聊天,实时推送比特币价格,爬取电影网站
技术栈 vue+vuex+vue-router+socket.io+koa2+mongodb+pm2自动化部署+图灵机器人+[npm script打包,cdn同步,服务器上传一个命令全搞定] 功能清单 ...
- python-蒙特·卡罗法计算圆周率
[题目描述]蒙特·卡罗方法是一种通过概率来得到问题近似解的方法,在很多领域都有重要的应用,其中就包括圆周率近似值的计问题.假设有一块边长为2的正方形木板,上面画一个单位圆,然后随意往木板上扔飞镖,落点 ...
- String能变化吗?和StringBuffer的区别是什么
[新手可忽略不影响继续学习]看 过上面例子的童鞋一定会觉得很奇怪,s = s + s1.charAt(i); 马克-to-win, s不是老在变化吗?其实s = "";时,虚拟机会 ...
- OllyDbg---call和ret指令
call和ret call指令 cal指令是转移到指定的子程序处,后面紧跟的操作数就是给定的地址. 例如,call 401362表示转移到地址401362处,调用401362处的子程序,当子程序调用完 ...
- Java中有关clone方法的用法
一.clone在数组基本数据类型中的使用 public class Main { public static void main(String[] args) { int[] arr= {7,8,9} ...