一次spark任务提交参数的优化
起因
新接触一个spark集群,明明集群资源(core,内存)还有剩余,但是提交的任务却申请不到资源。
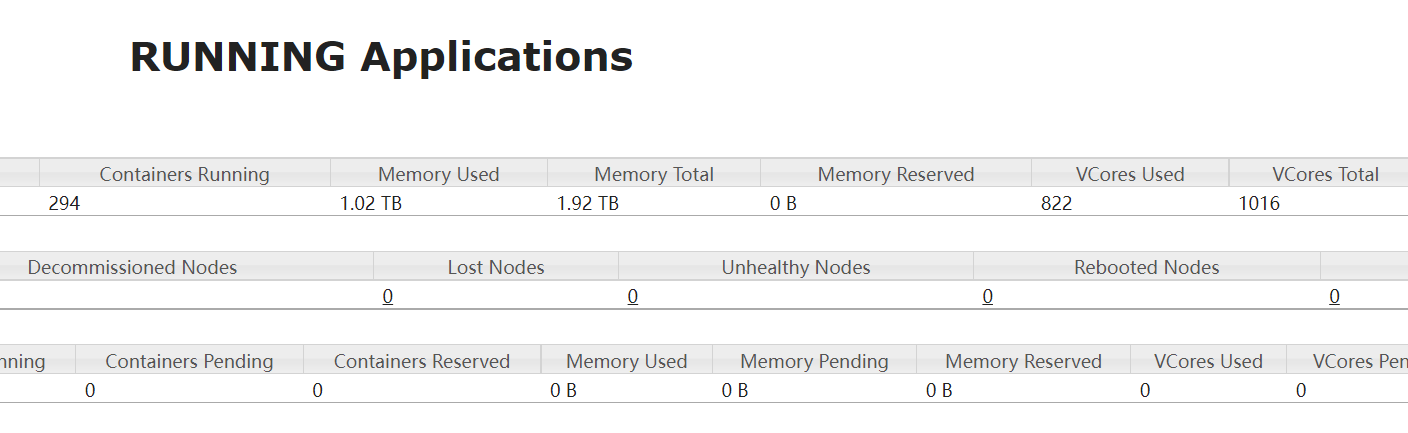
分析
环境
spark 2.2.0
基于yarn集群
参数
spark任务提交参数中最重要的几个:
spark-submit --master yarn --driver-cores 1 --driver-memory 5G --executor-cores 2 --num-executors 16 --executor-memory 4G
driver-cores driver端核数
driver-memory driver端内存大小
executor-cores 每个执行器的核数
num-executors 此任务申请的执行器总数
executor-memory 每个执行器的内存大小
那么,该任务将申请多少资源呢?
申请的执行器总内存数大小=num-executor * (executor-memory +spark.yarn.executor.memoryOverhead) = 16 * (4 + 2) = 96
申请的总内存=执行器总内存+dirver端内存=101
申请的总核数=num-executor*executor-core + yarn.AM(默认为1)=33
运行的总容器(contanier) = num-executor + yarn.AM(默认为1) = 17
所以这里还有一个关键的参数 spark.yarn.executor.memoryOverhead
这个参数是什么意思呢?
堆外内存,每个executor归spark 计算的内存为executor-memory,每个executor是一个单独的JVM,这个JAVA虚拟机本向在的内存大小即为spark.yarn.executor.memoryOverhead,不归spark本身管理。在spark集群中配置。也可在代码中指定
spark.set("spark.yarn.executor.memoryOverhead", 1)
这部份实际上是存放spark代码本身的究竟,在executor-memory内存不足的时候也能应应急顶上。
问题所在
假设一个节点16G的内存,每个executor-memory=4,理想情况下4x4=16,那么该节点可以分配出4个节点供spark任务计算所用。
1.但应考虑到spark.yarn.executor.memoryOverhead.
如果spark.yarn.executor.memoryOverhead=2,那么每个executor所需申请的资源为4+2=6G,那么该节点只能分配2个节点,剩余16-6x2=4G的内存,无法使用。
如果一个集群共100个节点,用户将在yarn集群主界面看到,集群内存剩余400G,但一直无法申请到资源。
2.core也是一样的道理。
很多同学容易忽略spark.yarn.executor.memoryOverhead此参数,然后陷入怀疑,怎么申请的资源对不上,也容易陷入优化的误区。
优化结果
最终优化结果,将spark.yarn.executor.memoryOverhead调小,并根据node节点资源合理优化executor-memory,executor-core大小,将之前经常1.6T的内存占比,降到1.1左右。并能较快申请到资源。
一次spark任务提交参数的优化的更多相关文章
- spark作业提交参数设置(转)
来源:https://www.cnblogs.com/arachis/p/spark_parameters.html 摘要 1.num-executors 2.executor-memory 3.ex ...
- Spark on Yarn:任务提交参数配置
当在YARN上运行Spark作业,每个Spark executor作为一个YARN容器运行.Spark可以使得多个Tasks在同一个容器里面运行. 以下参数配置为例子: spark-submit -- ...
- Spark性能调优篇一之任务提交参数调整
问题一:有哪些资源可以分配给spark作业使用? 答案:executor个数,cpu per exector(每个executor可使用的CPU个数),memory per exector(每个exe ...
- spark源码分析以及优化
第一章.spark源码分析之RDD四种依赖关系 一.RDD四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和O ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Spark学习(四) -- Spark作业提交
标签(空格分隔): Spark 作业提交 先回顾一下WordCount的过程: sc.textFile("README.rd").flatMap(line => line.s ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
- 【Spark-core学习之四】 Spark任务提交
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- spark任务提交到yarn上命令总结
spark任务提交到yarn上命令总结 1. 使用spark-submit提交任务 集群模式执行 SparkPi 任务,指定资源使用,指定eventLog目录 spark-submit --class ...
- Spark开发常用参数
Driver spark.driver.cores driver端分配的核数,默认为1,thriftserver是启动thriftserver服务的机器,资源充足的话可以尽量给多. spark.dri ...
随机推荐
- CIC滤波器
CIC滤波器是滑动平均滤波器的非常高效的迭代实现,只需要一个减法和一个加法,而滑动平均需要N-1个加法. cic滤波器相当于一个梳状滤波器y(n)=x(n)-x(n-D),H(z)=1-z-D,和一个 ...
- 算法与数据结构——AVL树(平衡二叉树)
定义 typedef struct AVLNode* Position; typedef Position AVLTree; /* AVL树类型 */ struct AVLNode { Element ...
- vue+element el-table有关Checkbox的一些功能
在做项目的时候会碰到一些表格操作的问题其中我归整了一下有关于多选功能的一些记录 一:默认选中其中一行 <el-table class="editTable" :data=&q ...
- 如何在微信小程序中使用ECharts图表
在微信小程序中使用ECharts 1. 下载插件 首先,下载 GitHub 上的 ecomfe/echarts-for-weixin 项目. 下载链接:ecomfe/echarts-for-weixi ...
- 中值滤波 ordfilt2函数
滤波是过滤掉信号中没用的波段 ordfilt2函数语法格式为:B=ordfilt2(A,order,domain)B=ordfilt2(A,order,domain,S)B=ordfilt2(..., ...
- postcss-px-to-viewport适配屏幕大小
1.postcss-px-to-viewport适配的介绍 postcss-px-to-viewport是一个插件,用起来非常方便,安装一下插件,搞个配置文件就可以直接用了. 2.postcss-px ...
- Synchronized和Lock有什么区别?用Lock有什么好处?
Synchronized 和 Lock 1.原始构成 Synchronized 是关键字属于JVM层面 (代码中以蓝色字体呈现) monitorenter .monitorexit Lock 是具体类 ...
- SQL相关知识点
一.基本概念 数据库术语 数据库(database) - 保存有组织的数据的容器(通常是一个文件或一组文件). 数据表(table) - 某种特定类型数据的结构化清单. 模式(schema) - 关于 ...
- css卡片样式
.view-1-user-card { margin: 20px 5% 10px 5%; height: 124px; width: 90%; background: linear-gradient( ...
- C/C++ 数据结构循环队列的实现
#include <iostream> #include <Windows.h> using namespace std; #define MAXSIZE 6 typedef ...