淘宝商品信息定向爬虫.py(亲测有效)


import requests
import re def getHTMLText(url):
try:
kv = {
'cookie': '', #要换成自己网页的cookie
'user-agent':'Mozilla/5.0' # 请求头;指定访问浏览器为Mozilla5.0版本的浏览器
}
r = requests.get(url,timeout=30,headers=kv)
r.encoding = r.apparent_encoding
return r.text
except:
return "" def parsePage(ilt,html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1]) # eval函数去掉最外层的单引号,双引号
title = eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("") def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count,g[0],g[1])) def main():
goods = '书包'
depth = 2
start_url = 'https://s.taobao.com/search?q=' + goods infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList) main()
查找自己cookie的步骤如下:
(1)进入淘宝页面
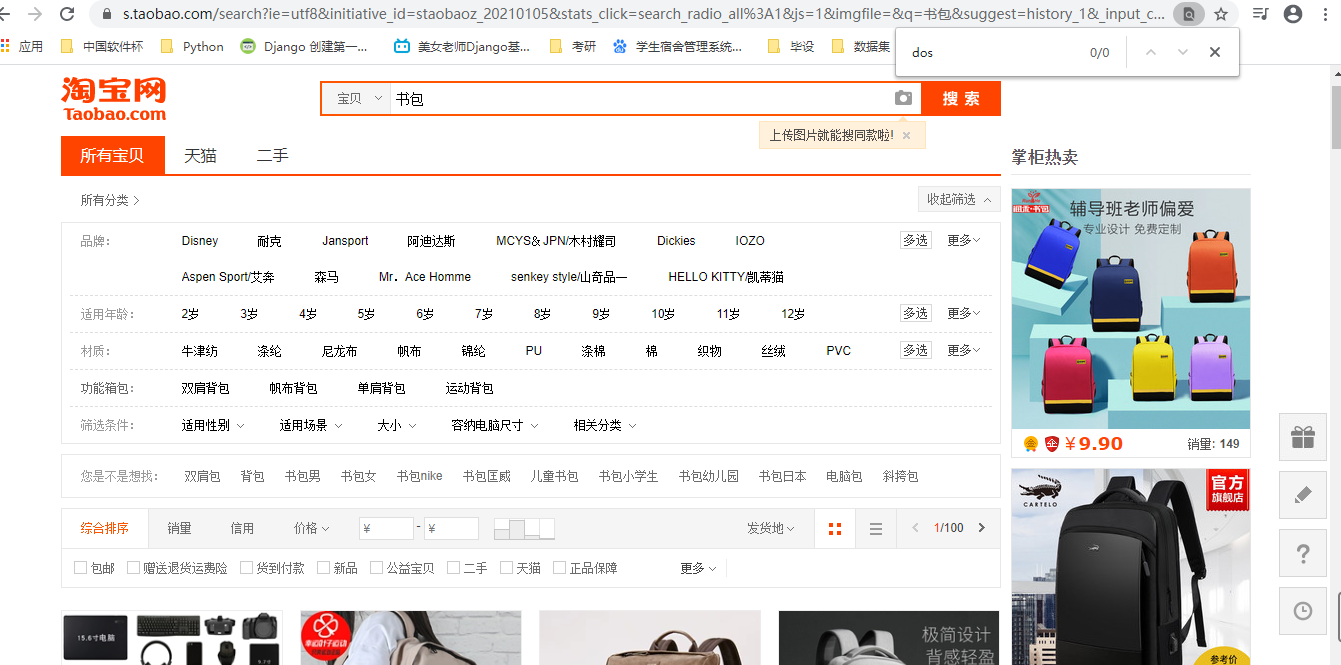
(2)按下F12,刷新页面,点击最上面的NetWork,找到下面文件
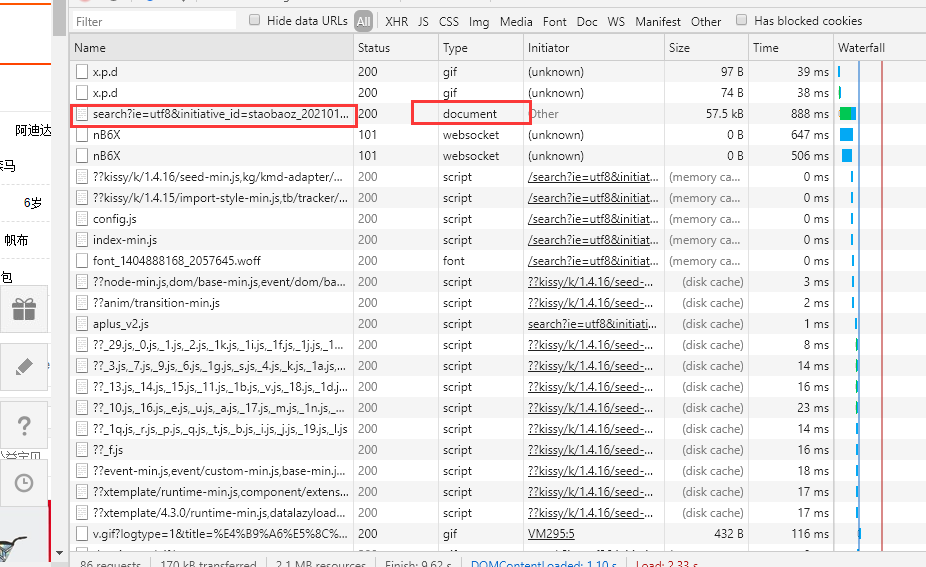
(3)找到RequestHeaders,找到里面的Cookie复制即可
淘宝商品信息定向爬虫.py(亲测有效)的更多相关文章
- python3编写网络爬虫16-使用selenium 爬取淘宝商品信息
一.使用selenium 模拟浏览器操作爬取淘宝商品信息 之前我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取.比如,淘宝,它的整个页面数据确实也是通过A ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- python 获取淘宝商品信息
python cookie 获取淘宝商品信息 # //get_goods_from_taobao import requests import re import xlsxwriter cok='' ...
- <day003>登录+爬取淘宝商品信息+字典用json存储
任务1:利用cookie可以免去登录的烦恼(验证码) ''' 只需要有登录后的cookie,就可以绕过验证码 登录后的cookie可以通过Selenium用第三方(微博)进行登录,不需要进行淘宝的滑动 ...
- 爬取淘宝商品信息,放到html页面展示
爬取淘宝商品信息 import pymysql import requests import re def getHTMLText(url): kv = {'cookie':'thw=cn; hng= ...
- 使用Pyquery+selenium抓取淘宝商品信息
配置文件,配置好数据库名称,表名称,要搜索的产品类目,要爬取的页数 MONGO_URL = 'localhost' MONGO_DB = 'taobao' MONGO_TABLE = 'phone' ...
- 淘宝开放平台php-sdk测试 获取淘宝商品信息(转)
今天想使用淘宝开放平台的API获取商品详情,可是以前一直没使用过,看起来有点高深莫测,后然看开发入门,一步一步,还真有点感觉了,然后看示例,还真行了,记下来以后参考.其中遇到问题,后然解决了.因为我已 ...
- selenium+pyquery爬取淘宝商品信息
import re from selenium import webdriver from selenium.common.exceptions import TimeoutException fro ...
- selenium+phantomjs+pyquery 爬取淘宝商品信息
from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium ...
随机推荐
- 【七侠传】冲刺阶段--Day7
[七侠传]冲刺阶段--Day7 团队成员 20181221曾宇涛 20181202李祎铭 20181209沙桐 20181215薛胜瀚 20181216杨越麒 20181223何家豪 20181232 ...
- linux查看进程信息
top 实时查看进程信息,展示进程id,使用内存,占用cpu等信息,可以查看内容占用最多.cpu使用最多的进程,然后再根据进程id查看进程的详细信息.实时更新 ps 瞬时查看进程情况,ps -ef | ...
- go的相关包time、os、rand、fmt
time 1.time包 2.time.Time类型, 用来表示时间 3.取当前时间, now := time.Now() 4.time.Now().Day(),time.Now().Minute() ...
- linux系统分类
1.RedHat系列:Redhat.Centos.Fedora等 2.Debian系列:Debian.Ubuntu等 RedHat 系列 1 常见的安装包格式 rpm包,安装rpm包的命令是" ...
- 结对作业——考研咨询APP
结对作业--考研资讯系统 102陈同学105潘同学108苏同学 (排版:Markdown) 一.需求分析(NABCD模型) 1. N(Need 需求): 1)想知道每个专业考研可以考哪个专业2)想 ...
- jsp第十周
数据库test 中建个表 stu(stuid 主键 自动增长 ,用户名,密码,年龄) 1.设计一个注册页面,实现用户注册功能2.设计一个登陆页面,实现用户名密码登陆3.两个页面可以互相超链接 Base ...
- nodejs路由
Router与route: Route是一条路由: 如:/users - - > 调用 getAllUsers()函数 /users/count/ - - > 调用 getUsersCou ...
- 纯css实现卡券式半圆及阴影(整理)
<!-- html部分 --> <div class="a"> <!-- a这个大卡片里边分上下两个卡片,对应上边灰色和下边白色部分 --> & ...
- PHP做API开发该如何设计签名验证
前言 开发过程中,我们经常会与接口打交道,有的时候是调取别人网站的接口,有的时候是为他人提供自己网站的接口,但是在这调取的过程中都离不开签名验证. 我们在设计签名验证的时候,请注意要满足以下几点: 可 ...
- 基于Nginx以及web服务器搭建在线视频播放
安装Nginx Nginx官网下载地址 网址打开后如图 下载windows版本的Nginx,这里下载最新的1.18.0版本 Nginx在windows下的安装只需要将其解压缩即可.建议将解压后的目录移 ...