KMP 算法实现
# coding=utf-8
def get_next_list(findding_str): # O(m)
# 求一个字符串序列每个位置的最长相等前、后缀
j = 0 # 最长相等前缀的末位
next = [0] # next 数组用于保存字符串每个位置的最长相等前、后缀的长度值
# i 是最长相等后缀的末位
for i in range(1, len(findding_str)):
while j > 0 and findding_str[i] != findding_str[j]:
# 如果当前 前缀末位(j)字符与当前i位置的字符不相等时,j回退 PS:j的值也表示findding_str[:i+1]最长相等前、后缀的长度值
j = next[j-1]
if findding_str[i] == findding_str[j]:
j += 1
next.append(j)
return next
def KMP(findding_str, next, parent_str): # O(n)
ind = 0
for i in range(len(parent_str)):
while parent_str[i] != findding_str[ind]:
if ind == 0:
break
# parent_str[i] != findding_str[ind] 且 ind != 0 时,从findding_str[ind] 左侧的字符串的最大相等前缀处开始比较
ind = next[ind-1]
if parent_str[i] == findding_str[ind]:
ind += 1
if ind == len(findding_str):
print(i, ind, parent_str[i - ind + 1: i+1])
ind = 0
# break
if __name__ == '__main__':
parent_str = 'aabafgggahaabaafaabaahatjhrtjabaafaabaahaabaafaabaahaabaaf'
findding_str = 'aabaaf'
KMP(findding_str, get_next_list(findding_str), parent_str)
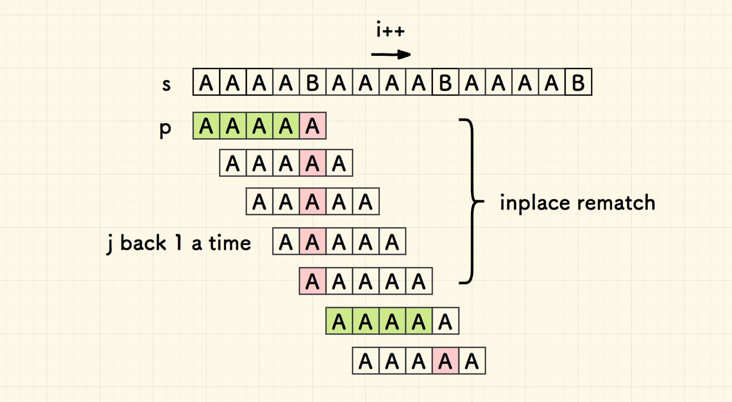
当在 j 处失配时,j -> next[j] 是说回溯到位置 next[j]
注意,next[j] 的位置的含义是什么?是对齐了已经匹配好的串的位置。
下图中,红色的方格是失配处。一旦失配,j 发生回溯跳转,
因为新位置左边的串已经是匹配好的(这正是 next 数组的含义,前后公共缀的长度),所以无需回溯到头。

按上面的图,数一数,绿色的是匹配上的字符,红色的是失配的地方,横向 n 个,
纵向 m 个,总共 m + n 次比对。
每次失配,子串回溯,对齐已匹配串,在失配处原地再匹配一次主串对应字符
所以,kmp 的比对次数是 (n + 失配次数)
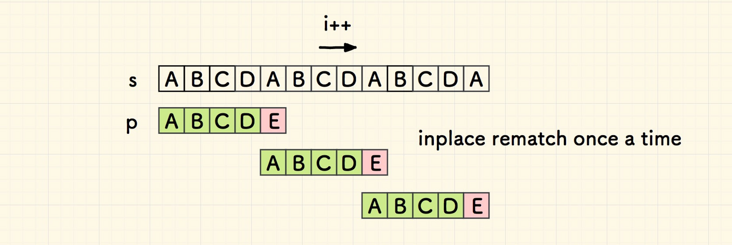
KMP 算法的最差情况的一个案例,n/m 个失配点位,每个点位重新匹配 m-1 次,此时总共比对 n+(m-1)*(n/m) 次,接近 2n 次。
如果不考虑搜索到的情况,最好情况如下,总共比对 n+1*(n/m) 次,如果 m 很小,也接近 2n 次,如果 m 比较大,就接近 n 次。
算上预处理阶段O(m),KMP 在最好、最坏的情况下的时间复杂度都是 O(m+n)
参考链接:https://segmentfault.com/q/1010000014560162
KMP 算法实现的更多相关文章
- 简单有效的kmp算法
以前看过kmp算法,当时接触后总感觉好深奥啊,抱着数据结构的数啃了一中午,最终才大致看懂,后来提起kmp也只剩下“奥,它是做模式匹配的”这点干货.最近有空,翻出来算法导论看看,原来就是这么简单(先不说 ...
- KMP算法
KMP算法是字符串模式匹配当中最经典的算法,原来大二学数据结构的有讲,但是当时只是记住了原理,但不知道代码实现,今天终于是完成了KMP的代码实现.原理KMP的原理其实很简单,给定一个字符串和一个模式串 ...
- 萌新笔记——用KMP算法与Trie字典树实现屏蔽敏感词(UTF-8编码)
前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽. 基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成"* ...
- KMP算法实现
链接:http://blog.csdn.net/joylnwang/article/details/6778316 KMP算法是一种很经典的字符串匹配算法,链接中的讲解已经是很明确得了,自己按照其讲解 ...
- 数据结构与算法JavaScript (五) 串(经典KMP算法)
KMP算法和BM算法 KMP是前缀匹配和BM后缀匹配的经典算法,看得出来前缀匹配和后缀匹配的区别就仅仅在于比较的顺序不同 前缀匹配是指:模式串和母串的比较从左到右,模式串的移动也是从 左到右 后缀匹配 ...
- 扩展KMP算法
一 问题定义 给定母串S和子串T,定义n为母串S的长度,m为子串T的长度,suffix[i]为第i个字符开始的母串S的后缀子串,extend[i]为suffix[i]与字串T的最长公共前缀长度.求出所 ...
- 字符串模式匹配之KMP算法图解与 next 数组原理和实现方案
之前说到,朴素的匹配,每趟比较,都要回溯主串的指针,费事.则 KMP 就是对朴素匹配的一种改进.正好复习一下. KMP 算法其改进思想在于: 每当一趟匹配过程中出现字符比较不相等时,不需要回溯主串的 ...
- 算法:KMP算法
算法:KMP排序 算法分析 KMP算法是一种快速的模式匹配算法.KMP是三位大师:D.E.Knuth.J.H.Morris和V.R.Pratt同时发现的,所以取首字母组成KMP. 少部分图片来自孤~影 ...
- BF算法与KMP算法
BF(Brute Force)算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符:若不相等,则比较S的 ...
- KMP算法-next函数求解
KMP函数求解:一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为KMP算法.KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串 ...
随机推荐
- 巧用Fiddler开启运营商定制版路由器被阉割的功能,免去刷公版固件的风险
前言: 三大运营商都有自己的定制版路由器,一般会在自家营销活动中作为赠品送给用户 正巧我家里就有两台电信定制版的华为路由器,都是这两年双十一在某宝上买宽带时送的 两台路由器型号分别是TC7001和TC ...
- Serilog日志同步到redis中和自定义Enricher来增加额外的记录信息
Serilog 日志同步到redis队列中 后续可以通过队列同步到数据库.腾讯阿里等日志组件中,这里redis库用的新生命团队的NewLife.Redis组件 可以实现轻量级消息队列(轻量级消息队列R ...
- .Net Core Logging模块源码阅读
.Net Core Logging模块源码阅读 前言 在Asp.Net Core Webapi项目中经常会用到ILogger,于是在空闲的时候就clone了一下官方的源码库下来研究,这里记录一下. 官 ...
- [WPF]DataContext结果不显示
namespace DataContext_ItemSource_Demo { public class Person { public string Name; } public class Vie ...
- 普冉PY32系列(一) PY32F0系列32位Cortex M0+ MCU简介
目录 普冉PY32系列(一) PY32F0系列32位Cortex M0+ MCU简介 普冉PY32系列(二) Ubuntu GCC Toolchain和VSCode开发环境 PY32F0系列上市其实相 ...
- 图文并茂quasar2.6+vue3+ts+vite创建项目并引入mockjs,mockjs 拦截ajax请求的原理是什么,quasar为什么要使用boot?
每天都要开心(▽)哇: 首先呢,我们来创建项目 执行下面命令,开始创建项目啦 $ npm i -g @quasar/cli $ npm init quasar 下面是我的选项,仅供参考哇 √ What ...
- 【数据结构和算法】Trie树简介及应用详解
作者:京东物流 马瑞 1 什么是Trie树 1.1 Trie树的概念 Trie树,即字典树,又称单词查找树或键树,是一种树形结构,典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经 ...
- 腾讯出品小程序自动化测试框架【Minium】系列(六)常见组件的处理
写在前面 我发现一件神奇的事,当你学一门新技术或者新的知识点遇到不会的时候,真的可以先放一放,第二天再去学习,也许说不定也就会了. 为什么这么说? 昨天文章断断续续的写了近一天,有一个组件不认识,自然 ...
- AR Engine毫秒级平面检测,带来更准确的呈现效果
近年来,AR版块成为时下大热,这是一种将现实环境中不存在的虚拟物体融合到真实环境里的技术,用户借助显示设备可以拥有真实的感官体验.AR的应用场景十分广泛,涉及娱乐.社交.广告.购物.教育等领域:AR可 ...
- wsl 网络探究
省流:wsl2能否固定ip地址? - 豆腐干的回答 - 知乎 https://www.zhihu.com/question/387747506/answer/2764445888 割--------- ...