mapreduce分区
本次分区是采用项目垃圾分类的csv文件,按照小于4的分为一个文件,大于等于4的分为一个文件
源代码:
PartitionMapper.java:
package cn.idcast.partition; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException;
/*
K1:行偏移量 LongWritable
v1:行文本数据 Text k2:行文本数据 Text
v2:NullWritable
*/ public class PartitionMapper extends Mapper<LongWritable,Text, Text, NullWritable> {
//map方法将v1和k1转为k2和v2
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
PartitionerReducer.java:
package cn.idcast.partition; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; /*
k2: Text
v2: NullWritable k3: Text
v3: NullWritable
*/
public class PartitionerReducer extends Reducer<Text, NullWritable,Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
MyPartitioner.java:
package cn.idcast.partition; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; public class MyPartitioner extends Partitioner<Text, NullWritable> {
/*
1:定义分区规则
2:返回对应的分区编号 */
@Override
public int getPartition(Text text, NullWritable nullWritable, int numPartitions) {
//1:拆分行文本数据(k2),获取垃圾分类数据的值
String[] split = text.toString().split(",");
String numStr=split[1]; //2:判断字段与15的关系,然后返回对应的分区编号
if(Integer.parseInt(numStr)>=4){
return 1;
}
else{
return 0;
}
}
}
JobMain.java:
package cn.idcast.partition; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.net.URI; public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//1:创建Job任务对象
Job job = Job.getInstance(super.getConf(), "partition_mapreduce");
//如果打包运行出错,则需要加该配置
job.setJarByClass(cn.idcast.mapreduce.JobMain.class);
//2:对Job任务进行配置(八个步骤)
//第一步:设置输入类和输入的路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node1:8020/input"));
//第二部:设置Mapper类和数据类型(k2和v2)
job.setMapperClass(PartitionMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//第三步:指定分区类
job.setPartitionerClass(MyPartitioner.class);
//第四、五、六步
//第七步:指定Reducer类和数据类型(k3和v3)
job.setReducerClass(PartitionerReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置ReduceTask的个数
job.setNumReduceTasks(2);
//第八步:指定输出类和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
Path path=new Path("hdfs://node1:8020/out/partition_out");
TextOutputFormat.setOutputPath(job,path);
//获取FileSystem
FileSystem fs = FileSystem.get(new URI("hdfs://node1:8020/partition_out"),new Configuration());
//判断目录是否存在
if (fs.exists(path)) {
fs.delete(path, true);
System.out.println("存在此输出路径,已删除!!!");
}
//3:等待任务结束
boolean bl = job.waitForCompletion(true);
return bl?0:1;
} public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动一个job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
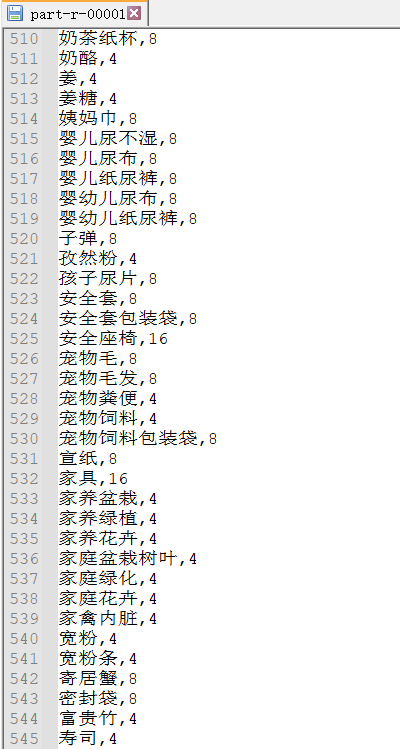
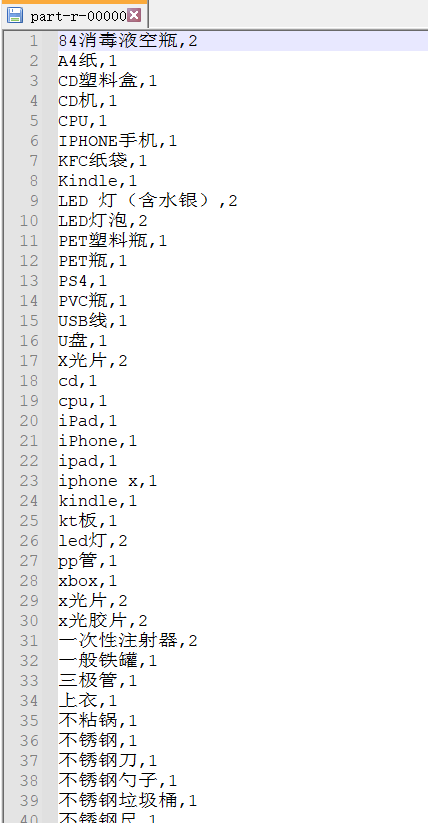
在hadoop或者本地运行结果:
1.均为4-16的文件
2.均为1-3的文件
mapreduce分区的更多相关文章
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- hadoop2.2.0 MapReduce分区
package com.my.hadoop.mapreduce.partition; import java.util.HashMap;import java.util.Map; import org ...
- Hadoop Mapreduce分区、分组、二次排序
1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partitioner以将map的结果送往指定reducer的过程: map - partiti ...
- MapReduce分区和排序
一.排序 排序: 需求:根据用户每月使用的流量按照使用的流量多少排序 接口-->WritableCompareable 排序操作在hadoop中属于默认的行为.默认按照字典殊勋排序. 排序的分类 ...
- MapReduce分区的使用(Partition)
MapReduce中的分区默认是哈希分区,根据map输出key的哈希值做模运算,如下 int result = key.hashCode()%numReduceTask; 如果我们需要根据业务需求来将 ...
- Hadoop Mapreduce分区、分组、二次排序过程详解
转载:http://blog.tianya.cn/m/post.jsp?postId=53271442 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了 ...
- MapReduce分区数据倾斜
什么是数据倾斜? 数据不可避免的出现离群值,并导致数据倾斜,数据倾斜会显著的拖慢MR的执行速度 常见数据倾斜有以下几类 1.数据频率倾斜 某一个区域的数据量要远远大于其他区域 2.数据大小倾斜 ...
- YARN集群的mapreduce测试(五)
将user表计算后的结果分区存储 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryNameN ...
- spark shuffle:分区原理及相关的疑问
一.分区原理 1.为什么要分区?(这个借用别人的一段话来阐述.) 为了减少网络传输,需要增加cpu计算负载.数据分区,在分布式集群里,网络通信的代价很大,减少网络传输可以极大提升性能.mapreduc ...
随机推荐
- JZ-015-反转链表
反转链表 题目描述 输入一个链表,反转链表后,输出新链表的表头. 题目链接: 反转链表 代码 /** * 标题:反转链表 * 题目描述 * 输入一个链表,反转链表后,输出新链表的表头. * 题目链接: ...
- 『现学现忘』Docker基础 — 11、Docker安装的问题补充
目录 1.问题复现 2.解决冲突 3.重新安装docker-ce-selinux 4.安装Docker-ce 5.总结 通过yum安装Docker的时候,安装20版本的Docker没有出现问题,在安装 ...
- 制作CocoaPods公有库和私有库
认识公有库和私有库 公有库:开源自己封装的库供别人使用,且往cocoaPods的官方Repo仓库(即CocoaPods Master Repo)中新增自己库的索引,该库索引是以*.podspec.js ...
- Spring Cloud Gateway 不小心换了个 Web 容器就不能用了,我 TM 人傻了
个人创作公约:本人声明创作的所有文章皆为自己原创,如果有参考任何文章的地方,会标注出来,如果有疏漏,欢迎大家批判.如果大家发现网上有抄袭本文章的,欢迎举报,并且积极向这个 github 仓库 提交 i ...
- laravel 框架登录 参考
一.登录功能1.书写登录路由Route::view('login','login');2.书写登录页面 视图层<form action="{{route('loginDo')}}&q ...
- tp5 缩略图自写
1:php终端 安装扩展 使用Composer安装ThinkPHP5的图像处理类库: composer require topthink/think-image2:控制器代码: public func ...
- Owin + WebApi + OAuth2 搭建授权模式(授权码模式 Part I)
绪 最近想要整理自己代码封装成库,也十分想把自己的设计思路贴出来让大家指正,奈何时间真的不随人意. 想要使用 OWIN 做中间件服务,该服务中包含 管线.授权 两部分.于是决定使用 webapi .O ...
- LGP7580题解
设: \[g(x)=\prod_{i=1}^{k_i}\binom {m} {c_{d,i}+m} \] 那么很明显有: \[f= a * g \] 再看一眼 \(g\),我们发现 \(g\) 是积性 ...
- [源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑 目录 [源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑 1. 继承关系 1.1 角 ...
- 用注册表清除Office Word文档杀手病毒
不久前,笔者打开word文件时遇到了一件离奇的怪事,常用的Word文件怎么也打不开,总是出现提示框:"版本冲突:无法打开高版本的word文档".再仔细查看,文件夹里竟然有两个名字一 ...