tensorflow中常用激活函数和损失函数
激活函数
各激活函数曲线对比
常用激活函数:
tf.sigmoid()
tf.tanh()
tf.nn.relu()
tf.nn.softplus()
tf.nn.softmax()
tf.nn.dropout()
tf.nn.elu()
import numpy as np
import matplotlib.pyplot as plt
from scipy.misc import derivative
def sigmoid(x):
y = 1 / (1 + np.exp(-x))
return y
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x)+np.exp(-x))
def relu(x):
return [max(xi,0) for xi in x]
def elu(x,a=1):
y = []
for xi in x:
if xi >= 0:
y.append(xi)
else:
y.append(a*(np.exp(xi)-1))
return y
def softplus(x):
return np.log(1+np.exp(x))
def derivative_f(func,input,dx=1e-6):
y = [derivative(func,x,dx) for x in input]
return y
x = np.linspace(-5,5,1000)
flg = plt.figure(figsize=(15,5))
ax1 = flg.add_subplot(1,2,1)
ax1.axis([-5,5,-1,1])
plt.xlabel(r'active function',fontsize=18)
ax1.plot(x,sigmoid(x),'r-',label='sigmoid')
ax1.plot(x,tanh(x),'g--',label='tanh')
ax1.plot(x,relu(x),'b-',lw=1,label='relu')
ax1.plot(x,softplus(x),'y--',label='softplus')
ax1.plot(x,elu(x),'b--',label='elu')
ax1.legend()
ax2 = flg.add_subplot(1,2,2)
plt.xlabel(r'derivative',fontsize=18)
ax2.plot(x,derivative_f(sigmoid,x),'r-',label='sigmoid')
ax2.plot(x,derivative_f(tanh,x),'g--',label='tanh')
ax2.plot(x,derivative_f(softplus,x),'y-',label='softplus')
ax2.legend()
plt.show()
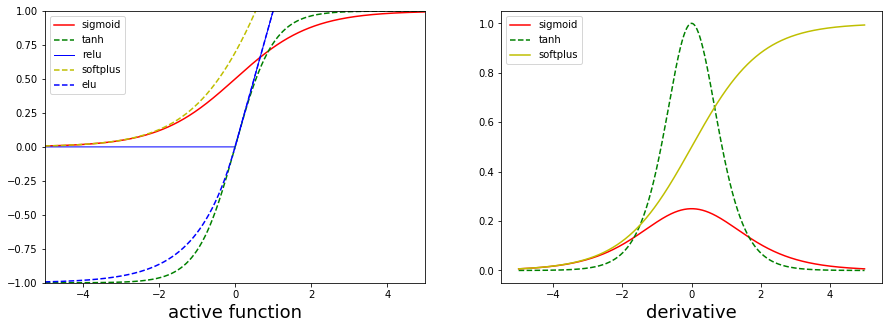
各激活函数优缺点
sigmoid函数
优点:在于输出映射在(0,1)范围内,单调连续,适合用作输出层,求导容易
缺点:一旦输入落入饱和区,一阶导数接近0,就可能产生梯度消失的情况
tanh函数
优点:输出以0为中心,收敛速度比sigmoid函数要快
缺点:存在梯度消失问题
relu函数
优点:目前最受欢迎的激活函数,在x<0时,硬饱和,在x>0时,导数为1,所以在x>0时保持梯度不衰减,从而可以缓解梯度消失的问题,能更快收敛,并提供神经网络的稀疏表达能力
缺点:随着训练的进行,部分输入或落入硬饱和区,导致无法更新权重,称为‘神经元死亡’
elu函数
优点:有一个非零梯度,这样可以避免单元消失的问题
缺点:计算速度比relu和它的变种慢,但是在训练过程中可以通过更快的收敛速度来弥补
softplus函数
该函数对relu做了平滑处理,更接近脑神经元的激活模型
softmax函数
除了用于二分类还可以用于多分类,将各个神经元的输出映射到(0,1空间)
dropout函数
tf.nn.dropout(x,keep_prob,noise_shape=None,seed=None,name=None)
一个神经元以概率keep_prob决定是否被抑制,如果被抑制,神经元的输出为0,如果不被抑制,该神经元将被放大到原来的1/keep_prob倍,默认情况下,每个神经元是否被抑制是相互独立的
一般规则
当输入数据特征相差明显时,用tanh效果很好,当特征相差不明显时用sigmoid效果比较好,sigmoid和tanh作为激活函数需要对输入进行规范化,否则激活后的值进入平坦区,而relu不会出现这种情况,有时也不需要输入规范化,因此85%-90%的神经网络会使用relu函数
损失函数
sigmoid_cross_entropy_with_logits函数
tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None)
该函数不仅可以用于二分类,也可以用于多分类,例如:判断图片中是否包含几种动物中的一种或多种
二分类logstic损失函数梯度推导
二项逻辑斯蒂回归模型是一种分类模型,由条件概率p(y|x)表示,形式未参数化的逻辑斯蒂分布,这里的变量X为实数,随机变量y取值为1或0,逻辑斯蒂模型条件概率分布如下:$$p(y=1|x) = \frac{\exp(w{\bullet}x+b)}{1+\exp(w{\bullet}x+b)}$$
\]
假设$$p(y = 1|x) = \theta(x),p(y=0|x) = 1 - \theta(x)$$
损失函数:$$L(\theta(x)) = -\prod_{i=1}N[\theta(x_i)]{y_i}[1-\theta(x_i)]^{1-y_i}$$
对数似然函数:$$L(\theta(x)) = -\sum_{i=1}^Ny_i * \log\theta(x_i)+(1-y_i)\log(1-\theta(x_i))$$
求\(L(\theta(x))\)的极大值,得到w的估计值,由于\(L(\theta(x))\)为凸函数,可以直接求损失函数的一阶偏导:
\]
由于\(\frac{\delta{\theta(x)}}{\delta{w}} = \theta(x_i) * (1 - \theta(x_i))*x_j^i\)
得到:$$\frac{\delta{L}}{\delta{w_j}} = -\sum_{i=1}N(y_i-\theta(x_i))*x_ji$$
weighted_cross_entropy_with_logits函数
tf.nn.weighted_cross_entropy_with_logits(targets,logits,pos_weight,name=None)
pos_weight正样本的一个系数
该函数在sigmoid_cross_entropy_with_logits函数的基础上为每个正样本添加了一个权重,其损失函数如下:
\]
softmax_cross_entropy_with_logits函数
tf.nn.softmax_cross_entropy_with_logits(_sentinel,labels,logits,name)
适用于每个类别相互独立且排斥的情况,例如,判断的图片只能属于一个种类而不能同时包含多个种类
损失函数:
\]
\]
sparse_softmax_cross_entropy_with_logits函数
tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel,labels,logits,name)
该函数与softmax_cross_entropy_with_logits的唯一区别在于labels,该函数的标签要求排他性的即只有一个正确类型,labels的形状要求是[batch_size]而值必须是从0开始编码的int32或int64,而且范围是[0,num_class],该函数没用过tensorflow中常用激活函数和损失函数的更多相关文章
- tensorflow中常用学习率更新策略
神经网络训练过程中,根据每batch训练数据前向传播的结果,计算损失函数,再由损失函数根据梯度下降法更新每一个网络参数,在参数更新过程中使用到一个学习率(learning rate),用来定义每次参数 ...
- 在TensorFlow中基于lstm构建分词系统笔记
在TensorFlow中基于lstm构建分词系统笔记(一) https://www.jianshu.com/p/ccb805b9f014 前言 我打算基于lstm构建一个分词系统,通过这个例子来学习下 ...
- TensorFlow常用激活函数及其特点和用法(6种)详解
http://c.biancheng.net/view/1911.html 每个神经元都必须有激活函数.它们为神经元提供了模拟复杂非线性数据集所必需的非线性特性.该函数取所有输入的加权和,进而生成一个 ...
- TensorFlow从0到1之TensorFlow常用激活函数(19)
每个神经元都必须有激活函数.它们为神经元提供了模拟复杂非线性数据集所必需的非线性特性.该函数取所有输入的加权和,进而生成一个输出信号.你可以把它看作输入和输出之间的转换.使用适当的激活函数,可以将输出 ...
- 机器学习之路:tensorflow 深度学习中 分类问题的损失函数 交叉熵
经典的损失函数----交叉熵 1 交叉熵: 分类问题中使用比较广泛的一种损失函数, 它刻画两个概率分布之间的距离 给定两个概率分布p和q, 交叉熵为: H(p, q) = -∑ p(x) log q( ...
- SELU︱在keras、tensorflow中使用SELU激活函数
arXiv 上公开的一篇 NIPS 投稿论文<Self-Normalizing Neural Networks>引起了圈内极大的关注,它提出了缩放指数型线性单元(SELU)而引进了自归一化 ...
- Pytorch_第九篇_神经网络中常用的激活函数
神经网络中常用的激活函数 Introduce 理论上神经网络能够拟合任意线性函数,其中主要的一个因素是使用了非线性激活函数(因为如果每一层都是线性变换,那有啥用啊,始终能够拟合的都是线性函数啊).本文 ...
- TensorFlow笔记-06-神经网络优化-损失函数,自定义损失函数,交叉熵
TensorFlow笔记-06-神经网络优化-损失函数,自定义损失函数,交叉熵 神经元模型:用数学公式比表示为:f(Σi xi*wi + b), f为激活函数 神经网络 是以神经元为基本单位构成的 激 ...
- 使用TensorFlow中的Batch Normalization
问题 训练神经网络是一个很复杂的过程,在前面提到了深度学习中常用的激活函数,例如ELU或者Relu的变体能够在开始训练的时候很大程度上减少梯度消失或者爆炸问题.但是却不能保证在训练过程中不出现该问题, ...
随机推荐
- ASYNCAPI
https://www.asyncapi.com Introduction AsyncAPI provides a specification that allows you to define Me ...
- 【转】PCA与Whitening
PCA: PCA的具有2个功能,一是维数约简(可以加快算法的训练速度,减小内存消耗等),一是数据的可视化. PCA并不是线性回归,因为线性回归是保证得到的函数是y值方面误差最小,而PCA是保证得到的函 ...
- rpm命令,yum命令大全
rpm 执行安装包二进制包(Binary)以及源代码包(Source)两种.二进制包可以直接安装在计算机中,而源代码包将会由RPM自动编译.安装.源代码包经常以src.rpm作为后缀名. 常用命令组合 ...
- MySQL数据库表分区功能详解
1.什么是表分区? mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表 ...
- 20145235李涛《网络对抗》Exp2 后门原理与实践
Windows获得Linux Shell Linux获得windows shell 实验内容 使用netcat获取主机操作shell,cron启动 使用socat获取主机shell,任务计划启动 使用 ...
- ES6 实现阶乘
// 实现一个5的阶乘function factorial(n, acc = 1) { console.log(`n=${n};acc=${acc}`) if(n <= 1) return ac ...
- 关于阿里云Symantec免费DV证书部署HTTPS
获取阿里云Symantec免费DV证书: 官方文件说明: 证书文件214188487290026.pem,包含两段内容,请不要删除任何一段内容. 如果是证书系统创建的CSR,还包含:证书私钥文件214 ...
- windows远程登录最大连接数
- Android开发——View的生命周期总结
0.前言 今天看到一个概念是View的生命周期,有点懵逼,听说过Activity的生命周期,Fragment的生命周期,对View的生命周期好像没什么概念啊.难道layout.draw这些也算是生命周 ...
- javascript异步编程的几种方法
目前工作中用的比较多的异步模式编程有如下几种方法 一 回调函数 这是异步编程最基本的方法,假设有两个函数f1和f2,后者等待前者的执行结果 f1(); f2(); 如果f1是一个很耗时的任务,可以考虑 ...