深入了解zookeeper(三)
一、ZooKeeper 的实现
1.1 ZooKeeper处理单点故障
我们知道可以通过ZooKeeper对分布式系统进行Master选举,来解决分布式系统的单点故障,如图所示。
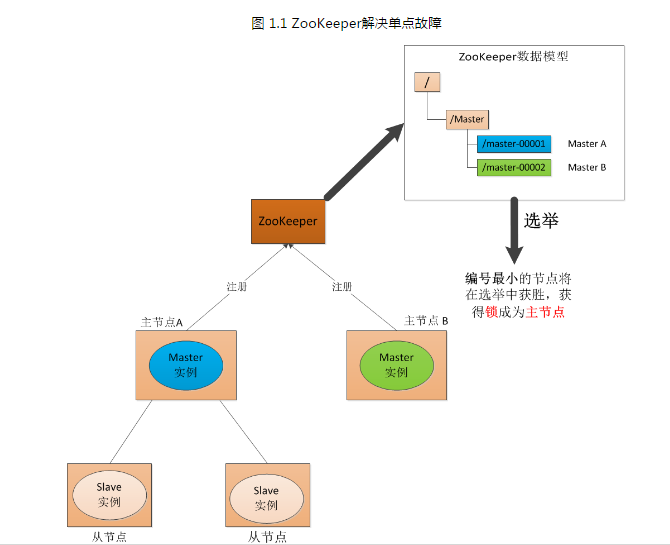
那么我们继续分析一下,ZooKeeper通过Master选举来帮助分布式系统解决单点故障, 保证该系统中每时每刻只有一个Master为分布式系统提供服务。也就是说分布式的单点问题交给了ZooKeeper来处理,不知道大家此时有没有发现一 个问题——"故障转移到了ZooKeeper身上"。大家看一下图就会发现,如果我们的ZooKeeper只用一台机器来提供服务,若这台机器挂了,那么 该分布式系统就直接变成双Master模式了,那么我们在分布式系统中引入ZooKeeper也就失去了意义。那么这也就意味着,ZooKeeper在其实现的过程中要做一些可用性和恢复性的保证。这样才能让我们放心的以ZooKeeper为起点来构建我们的分布式系统,来达到节省成本和减少bug的目的。
1.2 ZooKeeper运行模式
ZooKeeper服务有两种不同的运行模式。一种是"独立模式"(standalone mode),即只有一个ZooKeeper服务器。这种模式较为简单,比较适合于测试环境,甚至可以在单元测试中采用,但是不能保证高可用性和恢复性。在生产环境中的ZooKeeper通常以"复制模式"(replicated mode)运行于一个计算机集群上,这个计算机集群被称为一个"集合体"(ensemble)。
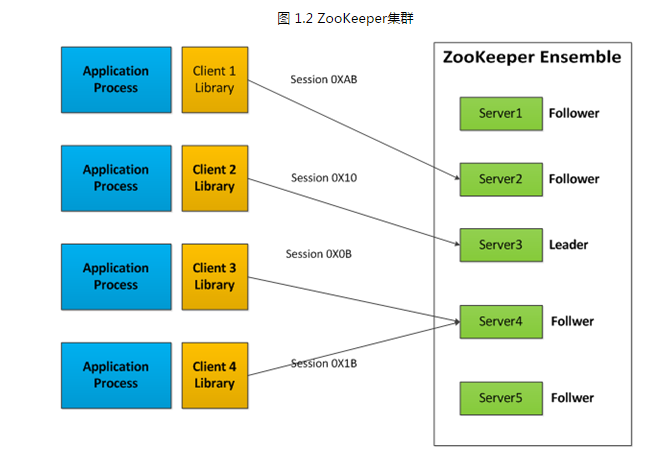
ZooKeeper通过复制来实现高可用性,只要集合体中半数以上的机器处于可用状态,它就能够提供服务。例如,在一个有5个节点的集合体中,每个Follower节点的数据都是Leader节点数据的副本,也就是说我们的每个节点的数据视图都是一样的,这样就可以有五个节点提供ZooKeeper服务。并且集合体中任意2台机器出现故障,都可以保证服务继续,因为剩下的3台机器超过了半数。
注意,6个节点的集合体也只能够容忍2台机器出现故障,因为如果3台机器出现故障,剩下的3台机器没有超过集合体的半数。出于这个原因,一个集合体通常包含奇数台机器。
从概念上来说,ZooKeeper它所做的就是确保对Znode树的每一个修改都会被复制到集合体中超过半数的 机器上。如果少于半数的机器出现故障,则最少有一台机器会保存最新的状态,那么这台机器就是我们的Leader。其余的副本最终也会更新到这个状态。如果 Leader挂了,由于其他机器保存了Leader的副本,那就可以从中选出一台机器作为新的Leader继续提供服务。
1.3 ZooKeeper的读写机制
(1) 概述
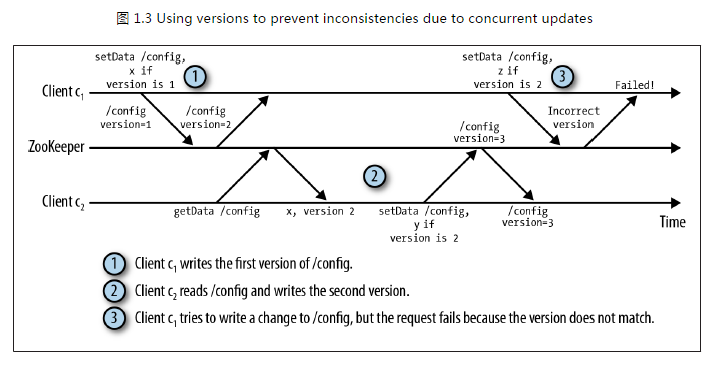
ZooKeeper的核心思想是,提供一个非锁机制的Wait Free的用于分布式系统同步的核心服务。提供简单的文件创建、读写操作接口,其系统核心本身对文件读写并不提供加锁互斥的服务,但是提供基于版本比对的更新操作,客户端可以基于此自己实现加锁逻辑。如下图1.3所示。
(2) ZK集群服务
Zookeeper是一个由多个Server组成的集群,该集群有一个Leader,多个Follower。客户端可以连接任意ZooKeeper服务节点来读写数据,如下图1.4所示。
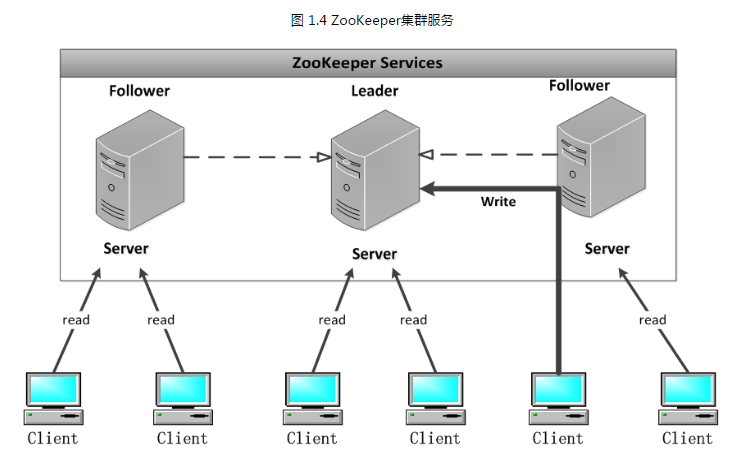
ZK集群中每个Server,都保存一份数据副本。Zookeeper使用简单的同步策略,通过以下两条基本保证来实现数据的一致性:
① 全局串行化所有的写操作
② 保证同一客户端的指令被FIFO执行(以及消息通知的FIFO)
所有的读请求由Zk Server 本地响应,所有的更新请求将转发给Leader,由Leader实施。
(3) ZK组件
ZK组件,如图1.5所示。ZK组件除了请求处理器(Request Processor)以外,组成ZK服务的每一个Server会复制这些组件的副本。
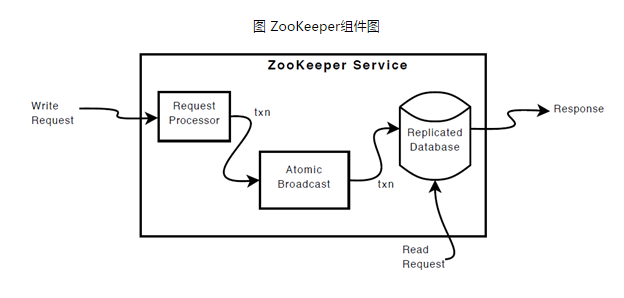
ReplicatedDatabase是一个内存数据库,它包含了整个Data Tree。为了恢复,更新会被记录到磁盘,并且写在被应用到内存数据库之前,先被序列化到磁盘。
每一个ZK Server,可服务于多个Client。Client可以连接到一台Server,来提交请求。读请求,由每台Server数据库的本地副本来进行服务。改变服务器的状态的写请求,需要通过一致性协议来处理。
作为一致性协议的一部分,来自Client的所有写请求,都要被转发到一个单独的Server,称作Leader。ZK集群中其他Server 称作Follower,负责接收Leader发来的提议消息,并且对消息转发达成一致。消息层处理leader失效,同步Followers和Leader。
ZooKeeper使用自定义的原子性消息协议。由于消息传送层是原子性的,ZooKeeper能够保证本地副本不产生分歧。当leader收到一个写请求,它会计算出当写操作完成后系统将会是什么状态,接着将之转变为一个捕获状态的事务。
(4) ZK性能
ZooKeeper被应用程序广泛使用,并有数以千计 的客户端同时的访问它,所以我们需要高吞吐量。我们为ZooKeeper 设计的工作负载的读写比例是 2:1以上。然而我们发现,ZooKeeper的高写入吞吐量,也允许它被用于一些写占主导的工作负载。ZooKeeper通过每台Server上的本地 ZK的状态副本,来提供高读取吞吐量。因此,容错性和读吞吐量是以添加到该服务的服务器数量为尺度。写吞吐量并不以添加到该服务的机器数量为尺度。
例如,在它的诞生地Yahoo公司,对于写占主导的工作负载来说,ZooKeeper的基准吞吐量已经超过每秒10000个操作;对于常规的以读为主导的工作负载来说,吞吐量更是高出了好几倍。
二、ZooKeeper的保证
经过上面的分析,我们知道要保证ZooKeeper服务的高可用性就需要采用分布式模式,来冗余数据写多份,写多份带来一致性问题,一致性问题又会带来性能问题,那么就此陷入了无解的死循环。那么在这,就涉及到了我们分布式领域的著名的CAP理论,在这就简单的给大家介绍一下,关于CAP的详细内容大家可以网上查阅。
2.1 CAP理论
(1) 理论概述
分布式领域中存在CAP理论:
① C:Consistency,一致性,数据一致更新,所有数据变动都是同步的。
② A:Availability,可用性,系统具有好的响应性能。
③ P:Partition tolerance,分区容错性。以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择,也就是说无论任何消息丢失,系统都可用。
该理论已被证明:任何分布式系统只可同时满足两点,无法三者兼顾。 因此,将精力浪费在思考如何设计能满足三者的完美系统上是愚钝的,应该根据应用场景进行适当取舍。
(2) 一致性分类
一致性是指从系统外部读取系统内部的数据时,在一定约束条件下相同,即数据变动在系统内部各节点应该是同步的。根据一致性的强弱程度不同,可以将一致性级别分为如下几种:
① 强一致性(strong consistency)。任何时刻,任何用户都能读取到最近一次成功更新的数据。
② 单调一致性(monotonic consistency)。任何时刻,任何用户一旦读到某个数据在某次更新后的值,那么就不会再读到比这个值更旧的值。也就是说,可获取的数据顺序必是单调递增的。
③ 会话一致性(session consistency)。任何用户在某次会话中,一旦读到某个数据在某次更新后的值,那么在本次会话中就不会再读到比这个值更旧的值。会话一致性是在单调一致性的基础上进一步放松约束,只保证单个用户单个会话内的单调性,在不同用户或同一用户不同会话间则没有保障。
④ 最终一致性(eventual consistency)。用户只能读到某次更新后的值,但系统保证数据将最终达到完全一致的状态,只是所需时间不能保障。
⑤ 弱一致性(weak consistency)。用户无法在确定时间内读到最新更新的值。
2.2 ZooKeeper与CAP理论
我们知道ZooKeeper也是一种分布式系统,它在一致性上有人认为它提供的是一种强一致性的服务(通过sync操作),也有人认为是单调一致性(更新时的大多说概念),还有人为是最终一致性(顺序一致性),反正各有各的道理这里就不在争辩了。然后它在分区容错性和可用性上做了一定折中,这和CAP理论是吻合的。ZooKeeper从以下几点保证了数据的一致性
① 顺序一致性
来自任意特定客户端的更新都会按其发送顺序被提交。也就是说,如果一个客户端将Znode z的值更新为a,在之后的操作中,它又将z的值更新为b,则没有客户端能够在看到z的值是b之后再看到值a(如果没有其他对z的更新)。
② 原子性
每个更新要么成功,要么失败。这意味着如果一个更新失败,则不会有客户端会看到这个更新的结果。
③ 单一系统映像
一 个客户端无论连接到哪一台服务器,它看到的都是同样的系统视图。这意味着,如果一个客户端在同一个会话中连接到一台新的服务器,它所看到的系统状态不会比 在之前服务器上所看到的更老。当一台服务器出现故障,导致它的一个客户端需要尝试连接集合体中其他的服务器时,所有滞后于故障服务器的服务器都不会接受该 连接请求,除非这些服务器赶上故障服务器。
④ 持久性
一个更新一旦成功,其结果就会持久存在并且不会被撤销。这表明更新不会受到服务器故障的影响。
三、ZooKeeper原理
3.1 原理概述
Zookeeper的核心是原子广播机制,这个机制保证了各个server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式和广播模式。
(1) 恢复模式
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。
(2) 广播模式
一旦Leader已经和多数的Follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个Server加入ZooKeeper服务中,它会在恢复模式下启动,发现Leader,并和Leader进行状态同步。待到同步结束,它也参与消息广播。ZooKeeper服务一直维持在Broadcast状态,直到Leader崩溃了或者Leader失去了大部分的Followers支持。
Broadcast模式极其类似于分布式事务中的2pc(two-phrase commit 两阶段提交):即Leader提起一个决议,由Followers进行投票,Leader对投票结果进行计算决定是否通过该决议,如果通过执行该决议(事务),否则什么也不做。

在广播模式ZooKeeper Server会接受Client请求,所有的写请求都被转发给领导者,再由领导者将更新广播给跟随者。当半数以上的跟随者已经将修改持久化之后,领导者才会提交这个更新,然后客户端才会收到一个更新成功的响应。这个用来达成共识的协议被设计成具有原子性,因此每个修改要么成功要么失败。
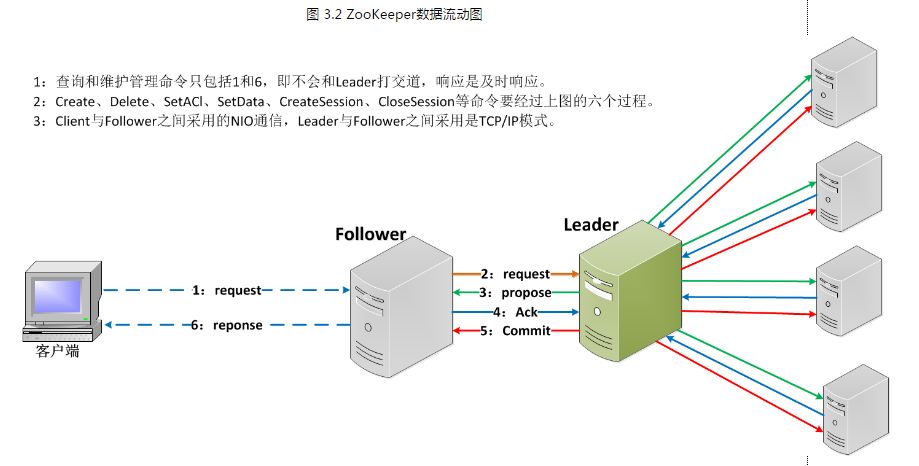
3.2 Zab协议详解
3.2.1 广播模式
广播模式类似一个简单的两阶段提交:Leader发起一个请求,收集选票,并且最终提交,图3.3演示了我们协议的消息流程。我们可以简化该两阶段提交协议,因为我们并没有"aborts"的情况。followers要么确认Leader的Propose,要么丢弃该Leader的Propose。没有"aborts"意味着,只要有指定数量的机器确认了该Propose,而不是等待所有机器的回应。

广播协议在所有的通讯过程中使用TCP的FIFO信道,通过使用该信道,使保持有序性变得非常的容易。通过FIFO信道,消息被有序的deliver。只要收到的消息一被处理,其顺序就会被保存下来。
Leader会广播已经被deliver的Proposal消息。在发出一个Proposal消息前,Leader会分配给Proposal一个单调递增的唯一id,称之为zxid。因为Zab保证了因果有序, 所以递交的消息也会按照zxid进行排序。广播是把Proposal封装到消息当中,并添加到指向Follower的输出队列中,通过FIFO信道发送到 Follower。当Follower收到一个Proposal时,会将其写入到磁盘,可以的话进行批量写入。一旦被写入到磁盘媒介当 中,Follower就会发送一个ACK给Leader。 当Leader收到了指定数量的ACK时,Leader将广播commit消息并在本地deliver该消息。当收到Leader发来commit消息 时,Follower也会递交该消息。
需要注意的是, 该简化的两阶段提交自身并不能解决Leader故障,所以我们 添加恢复模式来解决Leader故障。
3.2.2 恢复模式
(1) 恢复阶段概述
正常工作时Zab协议会一直处于广播模式,直到Leader故障或失去了指定数量的Followers。 为了保证进度,恢复过程中必须选举出一个新Leader,并且最终让所有的Server拥有一个正确的状态。对于Leader选举,需要一个能够成功高几 率的保证存活的算法。Leader选举协议,不仅能够让一个Leader得知它是leader,并且有指定数量的Follower同意该决定。如果 Leader选举阶段发生错误,那么Servers将不会取得进展。最终会发生超时,重新进行Leader选举。在我们的实现中,Leader选举有两种不同的实现方式。如果有指定数量的Server正常运行,快速选举的完成只需要几百毫秒。
(2)恢复阶段的保证
该恢复过程的复杂部分是在一个给定的时间内,提议冲突的绝对数量。最大数量冲突提议是一个可配置的选项,但是默认是1000。为了使该协议能够即使在Leader故障的情况下也能正常运作。我们需要做出两条具体的保证:
① 我们绝不能遗忘已经被deliver的消息,若一条消息在一台机器上被deliver,那么该消息必须将在每台机器上deliver。
② 我们必须丢弃已经被skip的消息。
(3) 保证示例
第一条:
若一条消息在一台机器上被deliver,那么该消息必须将在每台机器上deliver,即使那台机器故障了。例如,出现了这样一种情况:Leader发送了commit消息,但在该commit消息到达其他任何机器之前,Leader发生了故障。也就是说,只有Leader自己收到了commit消息。如图3.4中的C2。

图3.4是"第一条保证"(deliver消息不能忘记)的一个示例。在该图中Server1是一个Leader,我们用L1表示,Server2和Server3为Follower。首先Leader发起了两个Proposal,P1和P2,并将P1、P2发送给了Server1和Server2。然后Leader对P1发起了Commit即C1,之后又发起了一个Proposal即P3,再后来又对P2发起了commit即C2,就在此时我们的Leader挂了。那么这时候,P3和C2这两个消息只有Leader自己收到了。
因为Leader已经deliver了该C2消息,client能够在消息中看到该事务的结果。所以该事务必须能够在其他所有的Server中deliver,最终使得client看到了一个一致性的服务视图。
第二条:
一个被skip的消息,必须仍然需要被skip。例如,发生了这样一种情况:Leader发送了propose消息,但在该propose消息到达其他任何机器之前,Leader发生了故障。也就是说,只有Leader自己收到了propose消息。如图3.4中的P3所示。
在图3.4中没有任何一个server能够看到3号提议,所以在图3.5中当server 1恢复时他需要在系统恢复时丢弃三号提议P3。
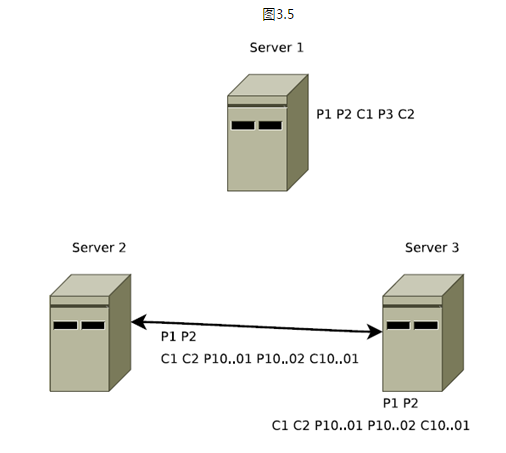
在图3.5是"第二条保证"(skip消息必须被丢弃)的一个示例。Server1挂掉以后,Server3被选举为Leader,我们用L2表示。L2中还有未被deliver的消息P1、P2,所以,L2在发出新提议P10000001、P10000002之前,L2先将P1、P2两个消息deliver。因此,L2先发出了两个commit消息C1、C2,之后L2才发出了新的提议P10000001和P10000002。
如果Server1 恢复之后再次成为了Leader,此时再次将P3在P10000001和P10000002之后deliver,那么将违背顺序性的保障。
(4) 保证的实现
如果Leader选举协议保证了新Leader在Quorum Server中具有最高的提议编号,即Zxid最高。那么新选举出来的leader将具有所有已deliver的消息。新选举出来的Leader,在提出一个新消息之前,首先要保证事务日志中的所有消息都由Quorum Follower已Propose并deliver。需要注意的是,我们可以让新Leader成为一个用最高zxid来处理事务的server,来作为一个优化。这样,作为新被选举出来的Leader,就不必去从一组Followers中找出包含最高zxid的Followers和获取丢失的事务。
① 第一条
所有的正确启动的Servers,将会成为Leader或者跟随一个Leader。Leader能够确保它的Followers看到所有的提议,并deliver所有已经deliver的消息。通过将新连接上的Follower所没有见过的所有PROPOSAL进行排队,并之后对该Proposals的COMMIT消息进行排队,直到最后一个COMMIT消息。在所有这样的消息已经排好队之后,Leader将会把Follower加入到广播列表,以便今后的提议和确认。这一条是为了保证一致性,因为如果一条消息P已经在旧Leader-Server1中deliver了,即使它刚刚将消息P deliver之后就挂了,但是当旧Leader-Server1重启恢复之后,我们的Client就可以从该Server中看到该消息P deliver的事务,所以为了保证每一个client都能看到一个一致性的视图,我们需要将该消息在每个Server上deliver。
② 第二条
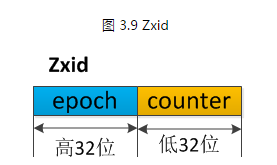
skip已经Propose,但不能deliver的消息,处理起来也比较简单。在我们的实现中,Zxid是由64位数字组成的,低32位用作简单计数器。高32位是一个epoch。每当新Leader接管它时,将获取日志中Zxid最大的epoch,新Leader Zxid的epoch位设置为epoch+1,counter位设置0。用epoch来标记领导关系的改变,并要求Quorum Servers 通过epoch来识别该leader,避免了多个Leader用同一个Zxid发布不同的提议。
这 个方案的一个优点就是,我们可以skip一个失败的领导者的实例,从而加速并简化了恢复过程。如果一台宕机的Server重启,并带有未发布的 Proposal,那么先前的未发布的所有提议将永不会被deliver。并且它不能够成为一个新leader,因为任何一种可能的 Quorum Servers ,都会有一个Server其Proposal 来自与一个新epoch因此它具有一个较高的zxid。当Server以Follower的身份连接,领导者检查自身最后提交的提议,该提议的epoch 为Follower的最新提议的epoch(也就是图3.5中新Leader-Server2中deliver的C2提议),并告诉Follower截断 事务日志直到该epoch在新Leader中deliver的最后的Proposal即C2。在图3.5中,当旧Leader-Server1连接到了新leader-Server2,leader将告诉他从事务日志中清除3号提议P3,具体点就是清除P2之后的所有提议,因为P2之后的所有提议只有旧Leader-Server1知道,其他Server不知道。
(5) Paxos与Zab
① Paxos一致性
Paxos的一致性不能达到ZooKeeper的要求,我们可以下面一个例子。我们假设ZK集群由三台机器组成,Server1、Server2、Server3。Server1为Leader,他生成了 三条Proposal,P1、P2、P3。但是在发送完P1之后,Server1就挂了。如下图3.6所示。

Server1挂掉之后,Server3被选举成为Leader,因为在Server3里只有一条Proposal—P1。所以,Server3在P1的基础之上又发出了一条新Proposal—P2',P2'的Zxid为02。如下图3.7所示。

Server2发送完P2'之后,它也挂了。此时Server1已经重启恢复,并再次成为了Leader。那么,Server1将发送还没有被deliver的Proposal—P2和P3。由于Follower-Server2中P2'的Zxid为02和Leader-Server1中P2的Zxid相等,所以P2会被拒绝。而P3,将会被Server2接受。如图3.8所示。
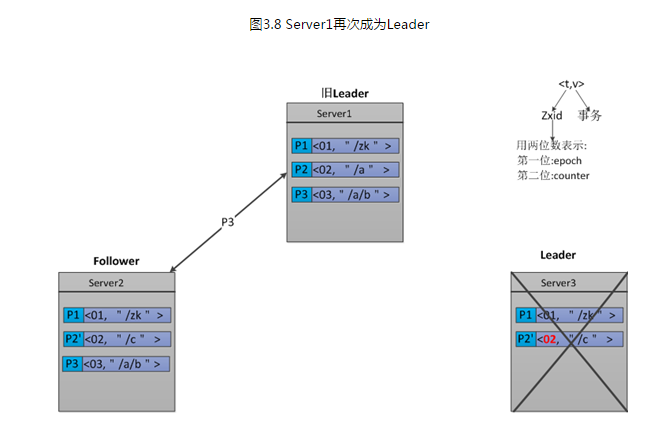
我们分析一下Follower-Server2中的Proposal,由于P2'将P2的内容覆盖了。所以导致,Server2中的Proposal-P3无法生效,因为他的父节点并不存在。
② Zab一致性
首先来分析一下,上面的示例中为什么不满足ZooKeeper需求。ZooKeeper是一个树形结构,很多操作都要先检查才能确定能不能执行,比如,在图3.8中Server2有三条Proposal。P1的事务是创建节点"/zk",P2'是创建节点"/c",而P3是创建节点"/a/b",由于"/a"还没建,创建"a/b"就搞不定了。那么,我们就能从此看出Paxos的一致性达不到ZooKeeper一致性的要求。
为了达到ZooKeeper所需要的一致性,ZooKeeper采用了Zab协议。Zab做了如下几条保证,来达到ZooKeeper要求的一致性。
(a) Zab要保证同一个leader的发起的事务要按顺序被apply,同时还要保证只有先前的leader的所有事务都被apply之后,新选的leader才能在发起事务。
(b) 一些已经Skip的消息,需要仍然被Skip。
我想对于第一条保证大家都能理解,它主要是为了保证每 个Server的数据视图的一致性。我重点解释一下第二条,它是如何实现。为了能够实现,Skip已经被skip的消息。我们在Zxid中引入了 epoch,如下图所示。每当Leader发生变换时,epoch位就加1,counter位置0。
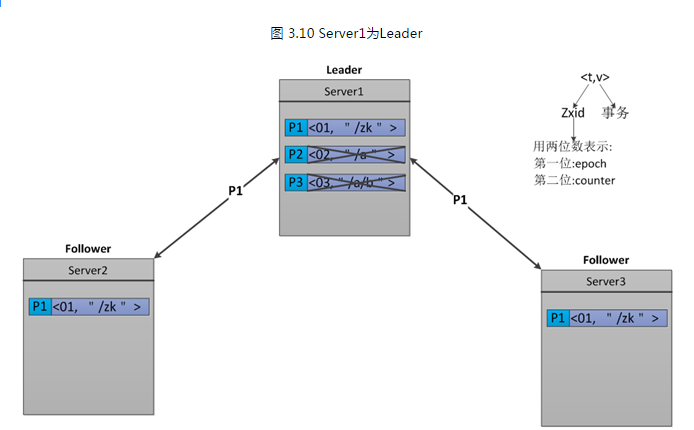
我们继续使用上面的例子,看一下他是如何实现Zab的 第二条保证的。我们假设ZK集群由三台机器组成,Server1、Server2、Server3。Server1为Leader,他生成了三条 Proposal,P1、P2、P3。但是在发送完P1之后,Server1就挂了。如下图3.10所示。
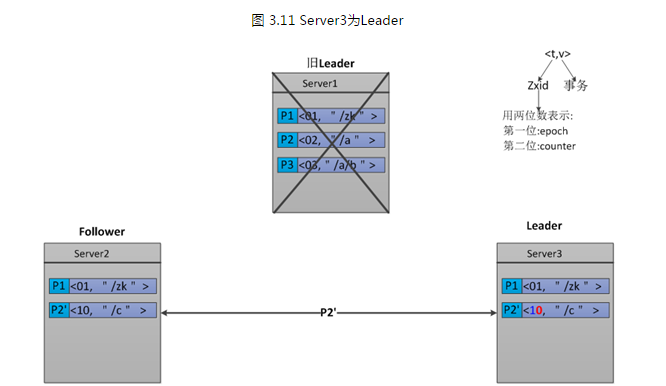
Server1挂掉之后,Server3被选举成为 Leader,因为在Server3里只有一条Proposal—P1。所以,Server3在P1的基础之上又发出了一条新Proposal—P2', 由于Leader发生了变换,epoch要加1,所以epoch由原来的0变成了1,而counter要置0。那么,P2'的Zxid为10。如下图3.11所示。
Server2发送完P2'之后,它也挂了。此时Server1已经重启恢复,并再次成为了Leader。那么,Server1将发送还没有被deliver的Proposal—P2和P3。由于Server2中P2'的Zxid为10,而Leader-Server1中P2和P3的Zxid分别为02和03,P2'的epoch位高于P2和P3。所以此时Leader-Server1的P2和P3都会被拒绝,那么我们Zab的第二条保证也就实现了。如图3.12所示。

深入了解zookeeper(三)的更多相关文章
- zookeeper三种模式安装详解(centos 7+zookeeper-3.4.9)
zookeeper有单机.伪集群.集群三种部署方式,可根据自己实际情况选择合适的部署方式.下边对这三种部署方式逐一进行讲解. 一 单机模式 1.下载 进入要下载的版本的目录,选择.tar.gz文件下载 ...
- Zookeeper三个监听案例
一.监听某一节点内容 /** * @author: PrincessHug * @date: 2019/2/25, 14:28 * @Blog: https://www.cnblogs.com/Hel ...
- Zookeeper(三) Zookeeper原理与应用
一.zookeeper原理解析 1.进群角色描述 2.Paxos 算法概述( ZAB 协议) 分布式一致性算法 3.Zookeeper 的选主(恢复模式) 以一个简单的例子来说明整个选举的过程. ...
- Zookeeper,Hbase 伪分布,集群搭建
工作中一般使用的都是zookeeper和Hbase的分布式集群. more /etc/profile cd /usr/local zookeeper-3.4.5.tar.gz zookeeper在安装 ...
- kafka环境搭建2-broker集群+zookeeper集群(转)
原文地址:http://www.jianshu.com/p/dc4770fc34b6 zookeeper集群搭建 kafka是通过zookeeper来管理集群.kafka软件包内虽然包括了一个简版的z ...
- zookeeper集群环境安装配置
众所周知,Zookeeper有三种不同的运行环境,包括:单机环境.集群环境和集群伪分布式环境 在此介绍的是集群环境的安装配置 一.下载: http://apache.fayea.com/zookeep ...
- ZooKeeper安装、部署
一.简介 ZK的安装和配置十分简单,既可以配置成单机模式,也可以配置成集群模式,zk使用java编写的运行在java环境上,3个ZK服务进程是建议的最小进程数量,而且建议部署在不通的物理机 ...
- SolrCloud(一)搭建Zookeeper
搭建Zookeeper 三台服务器: AMouse: 192.168.3.201 BCattle : 192.168.3.202 Ctiger : 192.168.3.203 一 下载Zookee ...
- windows环境下zookeeper安装和使用
一.简介 zooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一 ...
- java 操作zookeeper
java 操作zookeeper(一) 首先要使用java操作zookeeper,zookeeper的javaclient 使我们更轻松的去对zookeeper进行各种操作,我们引入zookeeper ...
随机推荐
- Web开发相关笔记 #01#
前端学习纲要 ※jQuery 参考 ※ 整理 Chrome 收藏夹的小技巧 ※ 解决 AJAX 跨域获取 cookie ※ 记一次 MyBatis 相关的 debug [1] 前端学习纲要: ♦ 第一 ...
- [国家集训队] calc(动规+拉格朗日插值法)
题目 P4463 [国家集训队] calc 集训队的题目真是做不动呀\(\%>\_<\%\) 朴素方程 设\(f_{i,j}\)为前\(i\)个数值域\([1,j]\),且序列递增的总贡献 ...
- jQuery动画二级下拉菜单
在线演示 本地下载
- CSS3鼠标悬停边框线条动画按钮
在线演示 本地下载
- Number使用笔记
Numbe函数用于将对象转换为数字 0 0 null 0 空 0 "" 0 true 1 false 0 date ...
- 比较好的SQL语句
批次导数据表头 SELECT [运单号] , [运单号] AS [订单号] , [运单号] AS [订单号] , [运单号] , SUM([price] * [ProductNum]) AS [订单总 ...
- JQuery -- Validate, Jquery 表单校验
1. Jquery 表单验证需要插件 jQuery validation 1.7 ---验证插件需要:jQuery 1.3.2 或 1.4.2版本 http://jquery.bassistance ...
- javascrip函数简单介绍
JavaScript 函数定义JavaScript 使用关键字 function 定义函数.函数可以通过声明定义,也可以是一个表达式.函数声明在之前的教程中,你已经了解了函数声明的语法 :functi ...
- 【scala】Option类型
一般来说,对于每种语言都会有一个关键字来表示一个对象引用的“无”.在Java中使用的是null. 而Scala则融合了函数式编程的风格,当预计到变量或者函数返回值可能不会引用任何值的时候,使用Opti ...
- opencv:图像的创建和储存
示例代码: #include <opencv.hpp> #include <vector> using namespace std; using namespace cv; v ...