Garbage First(G1)垃圾收集器
1. 概述
G1(Garbage First)垃圾收集器是当今垃圾回收技术最前沿的成果之一。早在JDK7就已加入JVM的收集器大家庭中,成为HotSpot重点发展的垃圾回收技术。同优秀的CMS垃圾回收器一样,G1也是关注最小时延的垃圾回收器。
G1最大的特点是引入分区的思路,弱化了分代的概念,合理利用垃圾收集各个周期的资源,解决了其他收集器甚至CMS的众多缺陷。
2. G1
2.1 特点
开启方式:-XX:+UseG1GC
串行、并行、CMS等收集器有如下共同点:
(1)年轻代、老年代是独立且连续的内存块;
(2)年轻代收集使用单Eden、双Survivor进行复制算法;
(3)老年代收集必须扫描整个老年代区域;
(4)都是以尽可能少而快执行GC为设计原则。
G1也有类似CMS的收集动作:初始标记、并发标记、重新标记、清除、转移回收(Region),并且也以一个串行收集器做担保机制。

G1的特点如下:
(1)G1的设计原则是“首先收集尽可能多的垃圾(Garbage First,名称的由来)”。因此,G1并不会等内存耗尽(串行、并行)或者快耗尽(CMS)的时候开始垃圾收集,而是在内部采用了启发式算法,在老年代找出具有高收集收益的分区进行收集。同时G1可以根据用户设置的暂停时间目标自动调整年轻代和总堆大小,暂停目标越短年轻代空间越小、总空间就越大;
(2)G1采用内存分区(Region)的思路,将内存划分为一个个相等大小的内存分区,回收时则以分区为单位进行回收,存活的对象复制到另一个空闲分区中。由于都是以相等大小的分区为单位进行操作,因此G1天然就是一种压缩方案(局部压缩);
(3)G1虽然也是分代收集器,但整个内存分区不存在物理上的年轻代与老年代的区别,也不需要完全独立的survivor(to space)堆做复制准备。G1只有逻辑上的分代概念,或者说每个分区都可能随G1的运行在不同代之间前后切换;
(4)G1收集都是STW的,但年轻代和老年代的收集界限比较模糊,采用了混合(mixed)收集的方式。即每次收集既可能只收集年轻代分区(年轻代收集),也可能在收集年轻代的同时,包含部分老年代分区(混合收集),这样即使堆内存很大时,也可以限制收集范围,从而降低停顿。
2.2 G1内存模型
2.2.1 分区Region
G1采用分区(Region)的思路,将整个堆空间分成若干个大小相等的内存区域,每次分配对象空间将逐段使用内存。因此,在堆的使用上,G1并不要求对象的存储一定是物理上连续的,只要逻辑上连续即可;每个分区也不会确定为某个代(年轻代、老年代)服务,可以按需在年轻代和老年代之间切换。参数-XX:G1HeapRegionSize=n可指定分区大小(1MB~32MB,必须是2的幂),默认将整个堆划分为2048个分区。

2.2.2 卡片Card
在每个分区内部被分成了若干个大小为512byte卡片(Card),标识堆内存最小可用粒度所有分区的卡片将会记录在全局卡片表(Global Card Table)中,分配的对象会占用物理上连续的若干个卡片,当查找对分区内对象的引用时便可通过记录卡片来查找该引用对象。每次对内存的回收,都是对指定分区的卡片进行处理。
2.2.3 堆Heap
G1同样可以通过-Xms、-Xmx指定堆空间大小,当发生年轻代收集或混合收集时,通过计算GC与应用的耗费时间比,自动调整堆空间大小。如果GC频率太高,则通过增加堆尺寸,来减少GC频率,相应地GC占用的时间也随之降低;目标参数-XX:GCTimeRatio即为GC与应用的耗费的时间比,G1默认为9。另外,当空间不足,如对象空间分配或转移失败时,G1会先尝试增加堆空间,如果扩容失败,则发起担保的Full GC。Full GC后,堆尺寸计算结果也会调整堆空间。
2.3 分代模型
2.3.2 分代
分代垃圾收集可以将关注点集中在最近被分配的对象上,而无需整堆扫描,避免长命对象的拷贝,同时独立收集有助于降低响应时间。虽然分区使得内存分配不再要求紧凑的内存空间,但G1依然使用了分代的思想。G1强内存在逻辑上划分为年轻代和老年代,其中年轻代又划分为Eden空间和Survivor空间。当年轻代空间并不是固定不变的,当现有年轻代分区占满时,JVM会分配新的空闲分区加入到年轻代空间。
整个年轻代内存会在初始空间-XX:G1NewSizePercent(默认整堆5%)与最大空间-XX:G1MaxNewSizePercent(默认60%)之间动态变化。且由参数目标暂停时间-XX:MaxGCPauseMillis(默认200ms)、需要扩缩的大小以及分区的RSet计算得到。当然G1依然可以设置固定的年轻代大小(-XX:NewRatio、-Xmn),但同时暂停目标将失去意义。
2.4 分区模型
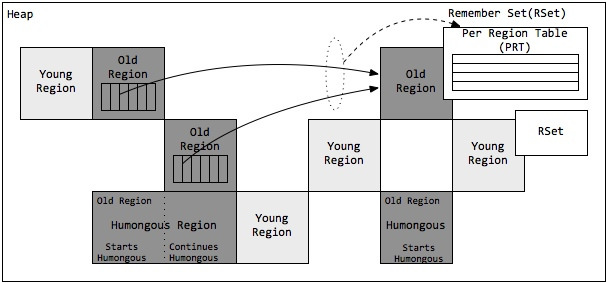
G1堆内存的使用以分区(Region)为单位,而对对象的分配则以卡片(Card)为单位。
2.4.1 巨型对象(Humongous Region)
一个大小达到甚至超过分区大小一半的对象称为巨型对象(Humongous Object)。
当线程为巨型分配空间时,不能简单在TLAB进行分配,因为巨型对象的移动成本很高,而且有可能一个分区不能容纳巨型对象。因此,巨型对象会直接在老年代分配,所占用的连续空间称为巨型分区(Humongous Region)。G1内部做了一个优化,一旦发现没有引用指向巨型对象,则可直接在年轻代收集周期中被回收。
巨型对象会独占一个、或多个连续分区,其中第一个分区被标记为开始巨型(StartsHumongous),相邻连续分区被标记为连续巨型(ContinuesHumongous)。由于无法享受Lab带来的优化,并且确定一片连续的内存空间需要扫描整堆,因此确定巨型对象开始位置的成本非常高,如果可以,应用程序应避免生成巨型对象。
2.4.2 记忆集合(Remember Set,RSet)
在串行和并行收集器中,GC通过整堆扫描,来确定对象是否处于可达路径中。然而G1为了避免STW式的整堆扫描,在每个分区记录了一个已记忆集合(RSet),内部类似一个反向指针,记录引用分区内对象的卡片索引。当要回收该分区时,通过扫描分区的RSet,来确定引用本分区内的对象是否存活,进而确定本分区内的对象存活情况。
事实上,并非所有的引用都需要记录在RSet中,如果一个分区确定需要扫描,那么无需RSet也可以无遗漏的得到引用关系。那么引用源自本分区的对象,当然不用落入RSet中;同时,G1 GC每次都会对年轻代进行整体收集,因此引用源自年轻代的对象,也不需要在RSet中记录。最后只有老年代的分区可能会有RSet记录,这些分区称为拥有RSet分区(an RSet’s owning region)。
2.4.3 收集集合(Collect Set,CSet)

收集集合(CSet)代表每次GC暂停时回收的一系列目标分区。在任意一次收集暂停中,CSet所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中。因此无论是年轻代收集,还是混合收集,工作的机制都是一致的。年轻代收集CSet只容纳年轻代分区,而混合收集会通过启发式算法,在老年代候选回收分区中,筛选出回收收益最高的分区添加到CSet中。
候选老年代分区的CSet准入条件,可以通过活跃度阈值-XX:G1MixedGCLiveThresholdPercent(默认85%)进行设置,从而拦截那些回收开销巨大的对象;同时,每次混合收集可以包含候选老年代分区,可根据CSet对堆的总大小占比-XX:G1OldCSetRegionThresholdPercent(默认10%)设置数量上限。
由上述可知,G1的收集都是根据CSet进行操作的,年轻代收集与混合收集没有明显的不同,最大的区别在于两种收集的触发条件。
2.4.4 年轻代收集集合
年轻代收集集合 CSet of Young Collection:应用线程不断活动后,年轻代空间会被逐渐填满。当JVM分配对象到Eden区域失败(Eden区已满)时,便会触发一次STW式的年轻代收集。在年轻代收集中,Eden分区存活的对象将被拷贝到Survivor分区;原有Survivor分区存活的对象,将根据任期阈值(tenuring threshold)分别晋升到PLAB中,新的survivor分区和老年代分区。而原有的年轻代分区将被整体回收掉。
同时,年轻代收集还负责维护对象的年龄(存活次数),辅助判断老化(tenuring)对象晋升的时候是到Survivor分区还是到老年代分区。年轻代收集首先先将晋升对象尺寸总和、对象年龄信息维护到年龄表中,再根据年龄表、Survivor尺寸、Survivor填充容量-XX:TargetSurvivorRatio(默认50%)、最大任期阈值-XX:MaxTenuringThreshold(默认15),计算出一个恰当的任期阈值,凡是超过任期阈值的对象都会被晋升到老年代。
2.4.5 混合收集集合
混合收集集合 CSet of Mixed Collection:年轻代收集不断活动后,老年代的空间也会被逐渐填充。当老年代占用空间超过整堆比IHOP阈值-XX:InitiatingHeapOccupancyPercent(默认45%)时,G1就会启动一次混合垃圾收集周期。为了满足暂停目标,G1可能不能一口气将所有的候选分区收集掉,因此G1可能会产生连续多次的混合收集与应用线程交替执行,每次STW的混合收集与年轻代收集过程相类似。
为了确定包含到年轻代收集集合CSet的老年代分区,JVM通过参数混合周期的最大总次数-XX:G1MixedGCCountTarget(默认8)、堆废物百分比-XX:G1HeapWastePercent(默认5%)。通过候选老年代分区总数与混合周期最大总次数,确定每次包含到CSet的最小分区数量;根据堆废物百分比,当收集达到参数时,不再启动新的混合收集。而每次添加到CSet的分区,则通过计算得到的GC效率进行安排。
2.5 G1的收集周期

2.5.1 并发标记周期
并发标记周期是G1中非常重要的阶段,这个阶段将会为混合收集周期识别垃圾最多的老年代分区。整个周期完成根标记、识别所有(可能)存活对象,并计算每个分区的活跃度,从而确定GC效率等级。
当达到IHOP阈值-XX:InitiatingHeapOccupancyPercent(老年代占整堆比,默认45%)时,便会触发并发标记周期。整个并发标记周期将由初始标记(Initial Mark)、根分区扫描(Root Region Scanning)、并发标记(Concurrent Marking)、重新标记(Remark)、清除(Cleanup)几个阶段组成。其中,初始标记(随年轻代收集一起活动)、重新标记、清除是STW的,而并发标记如果来不及标记存活对象,则可能在并发标记过程中,G1又触发了几次年轻代收集。
2.5.2 初始标记(Initial Mark)
初始标记(Initial Mark)负责标记所有能被直接可达的根对象(原生栈对象、全局对象、JNI对象),根是对象图的起点,因此初始标记需要将Mutator线程(Java应用线程)暂停掉,也就是需要一个STW的时间段。事实上,当达到IHOP阈值时,G1并不会立即发起并发标记周期,而是等待下一次年轻代收集,利用年轻代收集的STW时间段,完成初始标记,这种方式称为借道(Piggybacking)。
2.5.3 根分区扫描(Root Region Scanning)
在初始标记暂停结束后,年轻代收集也完成的对象复制到Survivor的工作,应用线程开始活跃起来。此时为了保证标记算法的正确性,所有新复制到Survivor分区的对象,都需要被扫描并标记成根,这个过程称为根分区扫描(Root Region Scanning),同时扫描的Suvivor分区也被称为根分区(Root Region)。根分区扫描必须在下一次年轻代垃圾收集启动前完成(并发标记的过程中,可能会被若干次年轻代垃圾收集打断),因为每次GC会产生新的存活对象集合。
2.5.4 并发标记
并发标记 Concurrent Marking和应用线程并发执行,并发标记线程在并发标记阶段启动,由参数-XX:ConcGCThreads(默认GC线程数的1/4,即-XX:ParallelGCThreads/4)控制启动数量,每个线程每次只扫描一个分区,从而标记出存活对象图。在这一阶段会处理Previous/Next标记位图,扫描标记对象的引用字段。同时,并发标记线程还会定期检查和处理STAB全局缓冲区列表的记录,更新对象引用信息。参数-XX:+ClassUnloadingWithConcurrentMark会开启一个优化,如果一个类不可达(不是对象不可达),则在重新标记阶段,这个类就会被直接卸载。所有的标记任务必须在堆满前就完成扫描,如果并发标记耗时很长,那么有可能在并发标记过程中,又经历了几次年轻代收集。如果堆满前没有完成标记任务,则会触发担保机制,经历一次长时间的串行Full GC。
2.5.5 重新标记
重新标记(Remark)是最后一个标记阶段。在该阶段中,G1需要一个暂停的时间,去处理剩下的SATB日志缓冲区和所有更新,找出所有未被访问的存活对象,同时安全完成存活数据计算。这个阶段也是并行执行的,通过参数-XX:ParallelGCThread可设置GC暂停时可用的GC线程数。同时,引用处理也是重新标记阶段的一部分,所有重度使用引用对象(弱引用、软引用、虚引用、最终引用)的应用都会在引用处理上产生开销。
2.5.6 清除
清除 Cleanup
紧挨着重新标记阶段的清除(Clean)阶段也是STW的。Previous/Next标记位图、以及PTAMS/NTAMS,都会在清除阶段交换角色。清除阶段主要执行以下操作:
- RSet梳理,启发式算法会根据活跃度和RSet尺寸对分区定义不同等级,同时RSet数理也有助于发现无用的引用。参数
-XX:+PrintAdaptiveSizePolicy可以开启打印启发式算法决策细节; - 整理堆分区,为混合收集周期识别回收收益高(基于释放空间和暂停目标)的老年代分区集合;
- 识别所有空闲分区,即发现无存活对象的分区。该分区可在清除阶段直接回收,无需等待下次收集周期。
2.6 年轻代收集、混合收集周期
年轻代收集和混合收集周期,是G1回收空间的主要活动。当应用运行开始时,堆内存可用空间还比较大,只会在年轻代满时,触发年轻代收集;随着老年代内存增长,当到达IHOP阈值-XX:InitiatingHeapOccupancyPercent(老年代占整堆比,默认45%)时,G1开始着手准备收集老年代空间。首先经历并发标记周期,识别出高收益的老年代分区,前文已述。但随后G1并不会马上开始一次混合收集,而是让应用线程先运行一段时间,等待触发一次年轻代收集。在这次STW中,G1将保准整理混合收集周期。接着再次让应用线程运行,当接下来的几次年轻代收集时,将会有老年代分区加入到CSet中,即触发混合收集,这些连续多次的混合收集称为混合收集周期(Mixed Collection Cycle)。
2.6.1 年轻代收集
年轻代收集 Young Collection
每次收集过程中,既有并行执行的活动,也有串行执行的活动,但都可以是多线程的。在并行执行的任务中,如果某个任务过重,会导致其他线程在等待某项任务的处理,需要对这些地方进行优化。
并行活动
- 外部根分区扫描 Ext Root Scanning:此活动对堆外的根(JVM系统目录、VM数据结构、JNI线程句柄、硬件寄存器、全局变量、线程对栈根)进行扫描,发现那些没有加入到暂停收集集合CSet中的对象。如果系统目录(单根)拥有大量加载的类,最终可能其他并行活动结束后,该活动依然没有结束而带来的等待时间。
- 更新已记忆集合 Update RS:并发优化线程会对脏卡片的分区进行扫描更新日志缓冲区来更新RSet,但只会处理全局缓冲列表。作为补充,所有被记录但是还没有被优化线程处理的剩余缓冲区,会在该阶段处理,变成已处理缓冲区(Processed Buffers)。为了限制花在更新RSet的时间,可以设置暂停占用百分比
-XX:G1RSetUpdatingPauseTimePercent(默认10%,即-XX:MaxGCPauseMills/10)。值得注意的是,如果更新日志缓冲区更新的任务不降低,单纯地减少RSet的更新时间,会导致暂停中被处理的缓冲区减少,将日志缓冲区更新工作推到并发优化线程上,从而增加对Java应用线程资源的争夺。 - RSet扫描 Scan RS:在收集当前CSet之前,考虑到分区外的引用,必须扫描CSet分区的RSet。如果RSet发生粗化,则会增加RSet的扫描时间。开启诊断模式
-XX:UnlockDiagnosticVMOptions后,通过参数-XX:+G1SummarizeRSetStats可以确定并发优化线程是否能够及时处理更新日志缓冲区,并提供更多的信息,来帮助为RSet粗化总数提供窗口。参数-XX:G1SummarizeRSetStatsPeriod=n可设置RSet的统计周期,即经历多少此GC后进行一次统计 - 代码根扫描 Code Root Scanning:对代码根集合进行扫描,扫描JVM编译后代码Native Method的引用信息(nmethod扫描),进行RSet扫描。事实上,只有CSet分区中的RSet有强代码根时,才会做nmethod扫描,查找对CSet的引用。
- 转移和回收 Object Copy:通过选定的CSet以及CSet分区完整的引用集,将执行暂停时间的主要部分:CSet分区存活对象的转移、CSet分区空间的回收。通过工作窃取机制来负载均衡地选定复制对象的线程,并且复制和扫描对象被转移的存活对象将拷贝到每个GC线程分配缓冲区GCLAB。G1会通过计算,预测分区复制所花费的时间,从而调整年轻代的尺寸。
- 终止 Termination:完成上述任务后,如果任务队列已空,则工作线程会发起终止要求。如果还有其他线程继续工作,空闲的线程会通过工作窃取机制尝试帮助其他线程处理。而单独执行根分区扫描的线程,如果任务过重,最终会晚于终止。
- GC外部的并行活动 GC Worker Other:该部分并非GC的活动,而是JVM的活动导致占用了GC暂停时间(例如JNI编译)。
串行活动
- 代码根更新 Code Root Fixup:根据转移对象更新代码根。
- 代码根清理 Code Root Purge:清理代码根集合表。
- 清除全局卡片标记 Clear CT:在任意收集周期会扫描CSet与RSet记录的PRT,扫描时会在全局卡片表中进行标记,防止重复扫描。在收集周期的最后将会清除全局卡片表中的已扫描标志。
- 选择下次收集集合 Choose CSet:该部分主要用于并发标记周期后的年轻代收集、以及混合收集中,在这些收集过程中,由于有老年代候选分区的加入,往往需要对下次收集的范围做出界定;但单纯的年轻代收集中,所有收集的分区都会被收集,不存在选择。
- 引用处理 Ref Proc:主要针对软引用、弱引用、虚引用、final引用、JNI引用。当Ref Proc占用时间过多时,可选择使用参数
-XX:ParallelRefProcEnabled激活多线程引用处理。G1希望应用能小心使用软引用,因为软引用会一直占据内存空间直到空间耗尽时被Full GC回收掉;即使未发生Full GC,软引用对内存的占用,也会导致GC次数的增加。 - 引用排队 Ref Enq:此项活动可能会导致RSet的更新,此时会通过记录日志,将关联的卡片标记为脏卡片。
- 卡片重新脏化 Redirty Cards:重新脏化卡片。
- 回收空闲巨型分区 Humongous Reclaim:G1做了一个优化:通过查看所有根对象以及年轻代分区的RSet,如果确定RSet中巨型对象没有任何引用,则说明G1发现了一个不可达的巨型对象,该对象分区会被回收。
- 释放分区 Free CSet:回收CSet分区的所有空间,并加入到空闲分区中。
- 其他活动 Other:GC中可能还会经历其他耗时很小的活动,如修复JNI句柄等。
2.6.2 混合收集
单次的混合收集与年轻代收集并无二致。根据暂停目标,老年代的分区可能不能一次暂停收集中被处理完,G1会发起连续多次的混合收集,称为混合收集周期(Mixed Collection Cycle)。G1会计算每次加入到CSet中的分区数量、混合收集进行次数,并且在上次的年轻代收集、以及接下来的混合收集中,G1会确定下次加入CSet的分区集(Choose CSet),并且确定是否结束混合收集周期。
2.7 转移失败的担保机制Full GC
转移失败(Evacuation Failure)是指当G1无法在堆空间中申请新的分区时,G1便会触发担保机制,执行一次STW式的、单线程的Full GC。Full GC会对整堆做标记清除和压缩,最后将只包含纯粹的存活对象。参数-XX:G1ReservePercent(默认10%)可以保留空间,来应对晋升模式下的异常情况,最大占用整堆50%,更大也无意义。
G1在以下场景中会触发Full GC,同时会在日志中记录to-space-exhausted以及Evacuation Failure:
- 从年轻代分区拷贝存活对象时,无法找到可用的空闲分区
- 从老年代分区转移存活对象时,无法找到可用的空闲分区
- 分配巨型对象时在老年代无法找到足够的连续分区
由于G1的应用场合往往堆内存都比较大,所以Full GC的收集代价非常昂贵,应该避免Full GC的发生。
3. 总结
G1是一款非常优秀的垃圾收集器,不仅适合堆内存大的应用,同时也简化了调优的工作。通过主要的参数初始和最大堆空间、以及最大容忍的GC暂停目标,就能得到不错的性能;同时,我们也看到G1对内存空间的浪费较高,但通过首先收集尽可能多的垃圾(Garbage First)的设计原则,可以及时发现过期对象,从而让内存占用处于合理的水平。
x. 参考资料
https://blog.csdn.net/coderlius/article/details/79272773
Garbage First(G1)垃圾收集器的更多相关文章
- 详解 JVM Garbage First(G1) 垃圾收集器(转载)
前言 Garbage First(G1)是垃圾收集领域的最新成果,同时也是HotSpot在JVM上力推的垃圾收集器,并赋予取代CMS的使命.如果使用Java 8/9,那么有很大可能希望对G1收集器进行 ...
- 转:详解G1垃圾收集器
G1垃圾收集器入门 说明 concurrent: 并发, 多个线程协同做同一件事情(有状态) parallel: 并行, 多个线程各做各的事情(互相间无共享状态) 参考: What’s the dif ...
- 深入理解 Java G1 垃圾收集器--转
原文地址:http://blog.jobbole.com/109170/?utm_source=hao.jobbole.com&utm_medium=relatedArticle 本文首先简单 ...
- G1垃圾收集器和CMS垃圾收集器 (http://mm.fancymore.com/reading/G1-CMS%E5%9E%83%E5%9C%BE%E7%AE%97%E6%B3%95.html#toc_8)
参考来源 JVM 体系架构 堆/栈的内存分配 静态和非静态方法的内存分配 CMS 回收算法 应用场景 CMS 垃圾收集阶段划分(Collection Phases) CMS什么时候启动 CMS缺点 G ...
- G1 垃圾收集器入门
最近在复习Java GC,因为G1比较新,JDK1.7才正式引入,比较艰难的找到一篇写的很棒的文章,粘过来mark下.总结这篇文章和其他的资料,G1可以基本稳定在0.5s到1s左右的延迟,但是并不能保 ...
- 转 G1垃圾收集器入门
转自:http://blog.csdn.net/zhanggang807/article/details/45956325 最近在复习Java GC,因为G1比较新,JDK1.7才正式引入,比较艰难的 ...
- G1垃圾收集器入门-原创译文
G1垃圾收集器入门-原创译文 原文地址 Getting Started with the G1 Garbage Collector 概览 目的 本文介绍了如何使用G1垃圾收集器以及如何与Hotspot ...
- G1 垃圾收集器架构和如何做到可预测的停顿(阿里)
CMS垃圾回收机制 参考:图解 CMS 垃圾回收机制原理,-阿里面试题 CMS与G1的区别 参考:CMS收集器和G1收集器优缺点 写这篇文章是基于阿里面试官的一个问题:众所周期,G1跟其他的垃圾回收算 ...
- G1垃圾收集器系统化说明【官方解读】
还是继续G1官网解读,上一次已经将这三节的东东读完了,如下: 所以接一来则继续往下读: Reviewing Generational GC and CMS[回顾一下CMS收集器] The Concur ...
随机推荐
- new placement 的使用
#include <iostream> #include "TModel.h" int main() { ]; std::cout<<"Sourc ...
- FIS常用功能之资源压缩
fis server start后 资源压缩,只需要使用命令,不需要添加任何配置 fis release --optimize 或: fis release -o 在浏览器访问按F12,观看压缩前后文 ...
- python笔记5-python2写csv文件中文乱码问题
前言 python2最大的坑在于中文编码问题,遇到中文报错首先加u,再各种encode.decode. 当list.tuple.dict里面有中文时,打印出来的是Unicode编码,这个是无解的. 对 ...
- iOS:延时执行的三种方式
延时执行的三种方式:performSelectorXXX方法.GCD中延时函数.创建定时器 第一种方式:NSObject分类当中的方法,延迟一段时间调用某一个方法 @interface NSObj ...
- oe7升级到oe8中import的使用
oe 7.0到oe 8.0 切换的时候发现我们系统的很多的module 无法load , import的时候出错, 后来发现oe 8.0自己的addons 也都做了修改在import自己的addon ...
- vector relation
::std::vector<> 的存储管理 以下成员函数用于存储管理: void reserve( size_t n ); size_t capacity() const; void re ...
- mysql索引处理
1.索引作用在索引列上,除了上面提到的有序查找之外,数据库利用各种各样的快速定位技术,能够大大提高查询效率.特别是当数据量非常大,查询涉及多个表时,使用索引往往能使查询速度加快成千上万倍.例如,有3个 ...
- 【Python】装饰器实现日志记录
好的日志对一个软件的重要性是显而易见的.如果函数的入口都要写一行代码来记录日志,这种方式实在是太低效了,但一直没有找到更好的方法.后来用python写一些软件,了解到python的装饰器功能时,突然人 ...
- MVVM和MVC的区别,以及MVVM的缺点
MVVM和MVC的区别 MVC和MVVM的区别其实并不大.都是一种设计思想. 主要就是MVC中Controller演变成MVVM中的viewModel. MVVM主要解决了MVC中大量的DOM操作使页 ...
- Tomcat 没有自动解压webapp下的war项目文件问题
默认选择的tomcat安装在了C盘下的C:\Program Files下 所以webapp文件也在C盘下 选择启动tomcat时 我选择了 bin下的 Tomcat.exe 显示成功启动 打开项目网站 ...