[Python爬虫] 之十四:Selenium +phantomjs抓取媒介360数据
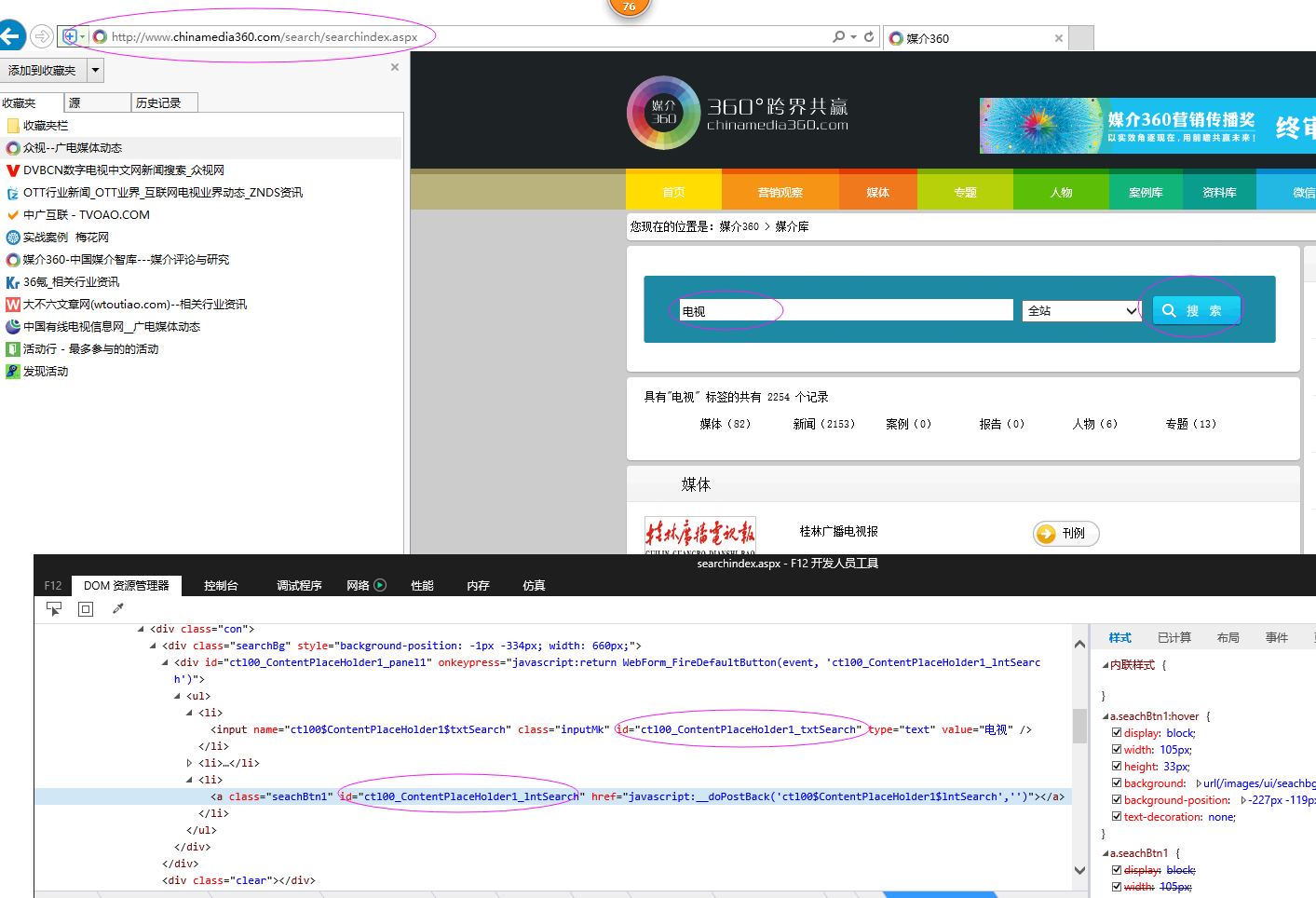

具体代码如下:
# coding=utf-8
import os
import re
from selenium import webdriver
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
import IniFile
from selenium.webdriver.common.keys import Keys
from threading import Thread
import thread
import LogFile
import urllib
import mongoDB
#抓取数据线程类
class ScrapyData_Thread(Thread):
#抓取数据线程类
def __init__(self,webSearchUrl,inputTXTIDLabel,searchlinkIDLabel,htmlLable,htmltime,keyword,invalid_day,db):
'''
构造函数
:param webSearchUrl: 搜索页url
:param inputTXTIDLabel: 搜索输入框的标签
:param searchlinkIDLabel: 搜索链接的标签
:param htmlLable: 要搜索的标签
:param htmltime: 要搜索的时间
:param invalid_day: 要搜索的关键字,多个关键字中间用分号(;)隔开
:param keywords: #资讯发布的有效时间,默认是3天以内
:param db: 保存数据库引擎
'''
Thread.__init__(self) self.webSearchUrl = webSearchUrl
self.inputTXTIDLabel = inputTXTIDLabel
self.searchlinkIDLabel = searchlinkIDLabel
self.htmlLable = htmlLable
self.htmltime = htmltime
self.keyword = keyword
self.invalid_day = invalid_day
self.db = db self.driver = webdriver.PhantomJS()
self.wait = ui.WebDriverWait(self.driver, 20)
self.driver.maximize_window() def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def run(self):
print '关键字:%s' % self.keyword self.driver.get(self.webSearchUrl)
time.sleep(1) # js = "var obj = document.getElementById('ctl00_ContentPlaceHolder1_txtSearch');obj.value='" + self.keyword + "';"
# self.driver.execute_script(js)
# 点击搜索链接
ss_elements = self.driver.find_element_by_id(self.inputTXTIDLabel)
ss_elements.send_keys(unicode(self.keyword,'utf8')) search_elements = self.driver.find_element_by_id(self.searchlinkIDLabel)
search_elements.click()
time.sleep(4) self.wait.until(lambda driver: self.driver.find_elements_by_xpath(self.htmlLable))
Elements = self.driver.find_elements_by_xpath(self.htmlLable) timeElements = self.driver.find_elements_by_xpath(self.htmltime)
urlList = []
for hrefe in Elements:
urlList.append(hrefe.get_attribute('href').encode('utf8')) index = 0
strMessage = ' '
strsplit = '\n------------------------------------------------------------------------------------\n'
index = 0
# 每页中有用记录
recordCount = 0
usefulCount = 0
meetingList = []
kword = self.keyword
currentDate = time.strftime('%Y-%m-%d') for element in Elements: strDate = timeElements[index].text.encode('utf8')
# 日期在3天内并且搜索的关键字在标题中才认为是复合要求的数据
#因为搜索的记录是安装时间倒序,所以如果当前记录的时间不在3天以内,那么剩下的记录肯定是小于当前日期的,所以就退出
if self.Comapre_to_days(currentDate,strDate) < self.invalid_day:
usefulCount = 1
txt = element.text.encode('utf8')
if txt.find(kword) > -1:
dictM = {'title': txt, 'date': strDate,
'url': urlList[index], 'keyword': kword, 'info': txt}
meetingList.append(dictM) # print ' '
# print '标题:%s' % txt
# print '日期:%s' % strDate
# print '资讯链接:' + urlList[index]
# print strsplit # # log.WriteLog(strMessage)
recordCount = recordCount + 1
else:
usefulCount = 0 if usefulCount:
break
index = index + 1 self.db.SaveMeetings(meetingList)
print "共抓取了: %d 个符合条件的资讯记录" % recordCount self.driver.close()
self.driver.quit() if __name__ == '__main__': configfile = os.path.join(os.getcwd(), 'chinaMedia.conf')
cf = IniFile.ConfigFile(configfile)
webSearchUrl = cf.GetValue("section", "webSearchUrl")
inputTXTIDLabel = cf.GetValue("section", "inputTXTIDLabel")
searchlinkIDLabel = cf.GetValue("section", "searchlinkIDLabel")
htmlLable = cf.GetValue("section", "htmlLable")
htmltime = cf.GetValue("section", "htmltime") invalid_day = int(cf.GetValue("section", "invalid_day")) keywords= cf.GetValue("section", "keywords")
keywordlist = keywords.split(';')
start = time.clock()
db = mongoDB.mongoDbBase()
for keyword in keywordlist:
if len(keyword) > 0:
t = ScrapyData_Thread(webSearchUrl,inputTXTIDLabel,searchlinkIDLabel,htmlLable,htmltime,keyword,invalid_day,db)
t.setDaemon(True)
t.start()
t.join() end = time.clock()
print "整个过程用时间: %f 秒" % (end - start)
[Python爬虫] 之十四:Selenium +phantomjs抓取媒介360数据的更多相关文章
- [Python爬虫] 之十:Selenium +phantomjs抓取活动行中会议活动
一.介绍 本例子用Selenium +phantomjs爬取活动树(http://www.huodongshu.com/html/find_search.html?search_keyword=数字) ...
- [Python爬虫] 之九:Selenium +phantomjs抓取活动行中会议活动(单线程抓取)
思路是这样的,给一系列关键字:互联网电视:智能电视:数字:影音:家庭娱乐:节目:视听:版权:数据等.在活动行网站搜索页(http://www.huodongxing.com/search?city=% ...
- [Python爬虫] 之十一:Selenium +phantomjs抓取活动行中会议活动信息
一.介绍 本例子用Selenium +phantomjs爬取活动行(http://www.huodongxing.com/search?qs=数字&city=全国&pi=1)的资讯信息 ...
- [Python爬虫] 之十三:Selenium +phantomjs抓取活动树会议活动数据
抓取活动树网站中会议活动数据(http://www.huodongshu.com/html/index.html) 具体的思路是[Python爬虫] 之十一中抓取活动行网站的类似,都是用多线程来抓取, ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- PYTHON 爬虫笔记十:利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB(实战项目三)
利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB 目标站点分析 淘宝页面信息很复杂的,含有各种请求参数和加密参数,如果直接请求或者分析Ajax请求的话会很繁琐.所以我们可 ...
- C#使用Selenium+PhantomJS抓取数据
本文主要介绍了C#使用Selenium+PhantomJS抓取数据的方法步骤,具有很好的参考价值,下面跟着小编一起来看下吧 手头项目需要抓取一个用js渲染出来的网站中的数据.使用常用的httpclie ...
- selenium+PhantomJS 抓取淘宝搜索商品
最近项目有些需求,抓取淘宝的搜索商品,抓取的品类还多.直接用selenium+PhantomJS 抓取淘宝搜索商品,快速完成. #-*- coding:utf-8 -*-__author__ =''i ...
- [Python爬虫] 之十二:Selenium +phantomjs抓取中的url编码问题
最近在抓取活动树网站 (http://www.huodongshu.com/html/find.html) 上数据时发现,在用搜索框输入中文后,点击搜索,phantomjs抓取数据怎么也抓取不到,但是 ...
随机推荐
- 手动安装gcc 4.8.5
# 下载gcc wget ftp://ftp.gnu.org/gnu/gcc/gcc-4.8.5/gcc-4.8.5.tar.gz # 解压并进入目录 tar -zxvf gcc-.tar.gz cd ...
- Go语言的web程序写法
一切来自于扩展... 核心也即处理输入输出... // helloworld project main.go package main import ( "fmt" "h ...
- 《The art of software testing》的一个例子
这几天一直在看一本书,<The art of software testing>,里面有一个例子挺有感触地,写出来和大家分享一下: [问题] 从输入对话框中读取三个整数值,这三个整数值代表 ...
- sqlserver 构架与性能优化
太阳底下没有新鲜事 一.sqlserver 构架结构 1.查询优化器三阶段 1).找计划缓存如果找到直接使用 2).简单语句生成0开销的执行计划 3).正式优化 一般情况下优化到开销小于1.0就会停止 ...
- hdu 5117 数学公式展开 + dp
题目大意:有n个灯泡,m个按钮,(1 <= n, m <= 50),每个按钮和ki 个灯泡相关, 按下后,转换这些灯泡的状态,问你所有2^m的按下按钮的 组合中亮着的灯泡的数量的三次方的和 ...
- 图片乱码问题 解决方法 php
两个开发者都是下载同一个项目的git代码,但到本地环境,一个可以正常显示图片验证码,一个不行,找个半天开始以为环境问题 找了半天 不是 很多没说到重点 其实不只是当前文件格式问题 也要考虑其他调用文件 ...
- Codeforces 1099 D. Sum in the tree-构造最小点权和有根树 贪心+DFS(Codeforces Round #530 (Div. 2))
D. Sum in the tree time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- HDU 1011 Starship Troopers【树形DP/有依赖的01背包】
You, the leader of Starship Troopers, are sent to destroy a base of the bugs. The base is built unde ...
- Web开发中的路径问题总结
原文地址:http://zzqrj.iteye.com/blog/806909 路径问题在Web开发中算是令人比较蛋疼的问题,尤其是用相对地址时,同样的代码,在不同的目录结构中竟然会出现有对有错的结果 ...
- 【kubernetes】ubuntu14.04 64位 搭建kubernetes过程
背景: Kubernetes介绍:http://kubernetes.io/docs/getting-started-guides/ github地址:https://github.com/kuber ...