spark 执行架构
术语定义
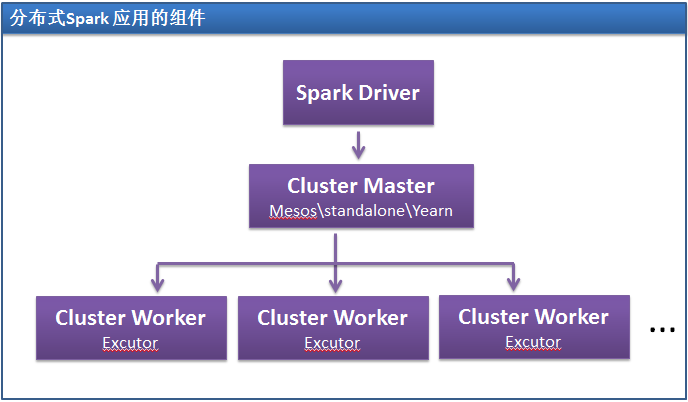
- Application:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个Driver 功能的代码和分布在集群中多个节点上运行的Executor代码;
- Driver:Spark中的Driver即运行上述Application的main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Drive;
- Executor:Application运行在Worker 节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor。在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutorBackend,类似于Hadoop MapReduce中的YarnChild。一个CoarseGrainedExecutorBackend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行Task的数量就取决于分配给它的CPU的个数了;
- Cluster Manager:指的是在集群上获取资源的外部服务,目前有:
- Ø Standalone:Spark原生的资源管理,由Master负责资源的分配;
- Ø Hadoop Yarn:由YARN中的ResourceManager负责资源的分配;
- Worker:集群中任何可以运行Application代码的节点,类似于YARN中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点;
- 作业(Job):包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation;
- 阶段(Stage):每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段;
- 任务(Task): 被送到某个Executor上的工作任务;
1、Spark分布式计算执行模型
RDD为Spark抽象了分布式计算的操作,即将任务进行分布式计算转成RDD的转换和行为上。通过spark-submit提交Driver应用程序给Spark集群,通过同Cluster Manager和Worker Node进行交互,
得到该Driver所需要的Executor资源,然后再由Spark应用程序通过分析RDD DAG依赖关系,以及各个RDD之间partition的依赖关系来生成不同的Stage,再将Stage中的任务,
按照RDD的partition个数生成相同数目的Task提交给Executor来执行,从而实现了Task在不同的Executor中进行分布式计算,最终实现整个Driver应用程序的分布式计算。
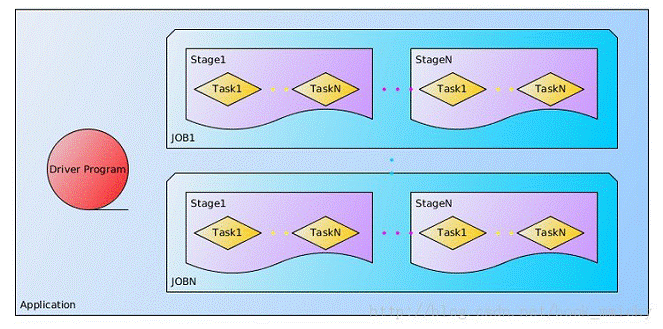
Spark执行模型分如下三步:
- 创建应用程序计算RDD DAG (Directed acyclic graph,有向无环图)
- 创建RDD DAG逻辑执行方案,即将整个计算过程对应到Stage上
- 获取到Executor来进行调度并执行各个Stage对应的ShuffleMapResult和ResultTask等任务。必须是执行一个Stage完成之后,才能往下执行接下来的Stage
RDD DAG
RDD DAG描述的是各个RDD之间的依赖关系。
举例从RDD DAG的角度来看如下:
即该RDD DAG主要是包括有MappedRDD->FlatMappedRDD->MappedRDD->ShuffledRDD四个RDD的转换(Transform), 根据Spark实现,RDD的转换操作是不会提交给Spark集群来执行的,
因此,上面的操作必须要由Spark的行为(Action)来触发,因此,在最后调用saveAsTextFile这个行为来将整个WordCount Job提交到Spark集群中来执行。
RDD DAG逻辑执行方案
RDD DAG只是从整体的RDD角度来查看整个Job的执行过程。在RDD DAG逻辑执行方案,需要查看各个RDD中各个Partition的情况,以及各个RDD的Partition的依赖情况来决定如何划分Stage。
在RDD中将依赖划分成了两种类型:
窄依赖(narrow dependencies)和宽依赖(wide dependencies)
窄依赖是指父RDD的每个分区都只被子RDD的一个分区所使用
宽依赖就是指父RDD的分区被多个子RDD的分区所依赖。例如,map就是一种窄依赖,而join则会导致宽依赖(除非父RDD是hash-partitioned)。
若在Job中存在有宽依赖,就划分为不同的Stage。
RDD Task执行
Spark通过分析各个RDD的依赖关系生成了RDD DAG,然后再通过分析各个RDD中的partition之间的依赖关系来将执行过程进行逻辑划分成不同的Stage。
有了这些Stage的依赖关系之后,从最parent stage开始执行,执行完了parent stage的所有的task再执行child stage中的所有的task,直到所有的Stage都执行完成。
RDD的Partition数目决定了执行过程中生成多少个Task,即决定于并行计算的数目,该参数是Spark应用程序中非常重要的参数,Partition设置的越大,并行度越高,
在Executor资源有限的情况下,任务之间调度开销会变大,同时若有Wide Dependencies的时候,Shuffle的代价也比较多。
Spark作者推荐的“比较合理的partition数目”为:
- 100-10000
- 最少要有2倍于申请的CPU核数
- 每个Partition对应的Task最少要运行100ms以上
2、Spark的shuffle实现
spark 执行架构的更多相关文章
- Spark 宏观架构&执行步骤
Spark 使用主从架构,有一个中心协调器和许多分布式worker. 中心协调器被称为driver.Driver 和被称为executor 的大量分布式worker 通信 Driver 运行在它自己的 ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark Streaming 架构
图 1 Spark Streaming 架构图 组件介绍: Network Input Tracker : 通 过 接 收 器 接 收 流 数 据, 并 将 流 数 据 映 射 为 输 入DSt ...
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- 【转载】Spark运行架构
1. Spark运行架构 1.1 术语定义 lApplication:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个 ...
- Spark运行架构
http://blog.csdn.net/pipisorry/article/details/52366288 1. Spark运行架构 1.1 术语定义 lApplication:Spark App ...
- Spark基本架构
Spark基本架构图如下: Client:客户端进程,负责提交作业. Driver:一个Spark作业有一个spark context,一个Spark Context对应一个Driver进程,作业的 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
- spark 运行架构
spark 运行架构基本由三部分组成,包括SparkContext(驱动程序),ClusterManager(集群资源管理器)和Executor(任务执行过程)组成. 其中SparkContext负责 ...
随机推荐
- Angular.js数据绑定时自动转义html标签及内容
angularJS在进行数据绑定时默认是以字符串的形式数据,也就是对你数据中的html标签不进行转义照单全收,这样提高了安全性,防止html标签的注入攻击,但有时候需要,特别是从数据库读取带格式的文本 ...
- ssm框架基本流程
题目,写的有点大了,其实就是 对一张表的基本处理,增删改查的基本操作演示. 好了,我们开始了. 假如,我们在做一个单表处理,就举例是 学院(某个大学的学院) 吧. 首先,我们分析 学校这样表有哪些属性 ...
- git忽略文件留存
##ignore this file##/target/ .classpath.project.settings /.settings/ ##filter databfile.sln file##*. ...
- A Gentle Introduction to Transfer Learning for Deep Learning | 迁移学习
by Jason Brownlee on December 20, 2017 in Better Deep Learning Transfer learning is a machine learni ...
- UITableViewCell在重用ID时为何加上Static关键字
UITableViewCell在重用ID时为何加上Static关键字 先回顾一下iOS各种变量作用域和生命周期相关知识: 1.方法中临时变量存储在栈区,出了该方法,临时变量会被自动销毁.但是如果给方法 ...
- [转]:理解 Linux 配置文件
简介: 本文说明了 Linux 系统的配置文件,在多用户.多任务环境中,配置文件控制用户权限.系统应用程序.守护进程.服务和其它管理任务.这些任务包括管理用户帐号.分配磁盘配 额.管理电子邮件和新闻组 ...
- Maven--archetypeCatalog笔记
当我们使用maven原型生成项目骨架时,经常会在[INFO] Generating project in Interactive mode这个地方特别慢,这里并不是什么出错卡住的原因,你打开mvn的d ...
- window下pip install Scrapy报错解决方案
1.首先打开https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted,找到对应版本的Twisted并下载到你的文件夹. 2.利用pip install命令 ...
- idea 聚合项目里如果子项目引用不到父类的maven应用
idea 聚合项目里如果子项目引用不到父类的maven应用,可以点看子类pom.xml文件,然后右键---->maven----->Reimport即可 点击右边子项目的maven---& ...
- Sass变量及嵌套
1. 变量:SASS允许使用变量,所有变量以$开头. 变量声明:$highlight-color: #000; 注意:变量可以在css规则块定义之外存在.如下例子: $nav-color: #F90; ...