Spark 中的宽依赖和窄依赖
Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,而划分依据就是RDD之间的依赖关系。针对不同的转换函数,RDD之间的依赖关系分类窄依赖(narrow dependency)和宽依赖(wide dependency, 也称 shuffle dependency).
宽依赖与窄依赖
- 窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区(O(1),与数据规模无关)
- 相应的,宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区(O(n),与数据规模有关)
宽依赖和窄依赖如下图所示:
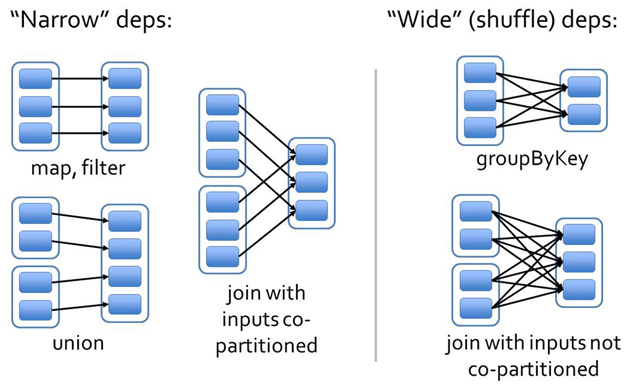
相比于宽依赖,窄依赖对优化很有利 ,主要基于以下两点:
宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
当RDD分区丢失时(某个节点故障),spark会对数据进行重算。
- 对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的;
- 对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
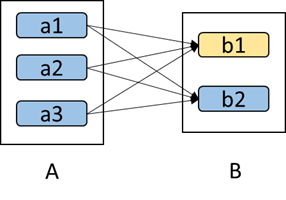
如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。
以下是文章 RDD:基于内存的集群计算容错抽象 中对宽依赖和窄依赖的对比。
区分这两种依赖很有用。首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
【误解】之前一直理解错了,以为窄依赖中每个子RDD可能对应多个父RDD,当子RDD丢失时会导致多个父RDD进行重新计算,所以窄依赖不如宽依赖有优势。而实际上应该深入到分区级别去看待这个问题,而且重算的效用也不在于算的多少,而在于有多少是冗余的计算。窄依赖中需要重算的都是必须的,所以重算不冗余。
窄依赖的函数有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
宽依赖的函数有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy
参考:
RDD:基于内存的集群计算容错抽象
Spark技术内幕:Stage划分及提交源码分析
Spark分布式计算和RDD模型研究
SPARK 阔依赖 和窄依赖 transfer action lazy策略之间的关系
Spark 中的宽依赖和窄依赖的更多相关文章
- Spark --【宽依赖和窄依赖】
前言 Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,暴力的理解就是stage的划分是按照有没有涉及到shuffle来划分的,没涉及的shuffle的都划 ...
- Spark宽依赖、窄依赖
在Spark中,RDD(弹性分布式数据集)存在依赖关系,宽依赖和窄依赖. 宽依赖和窄依赖的区别是RDD之间是否存在shuffle操作. 窄依赖 窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用 ...
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
- 大数据开发-从cogroup的实现来看join是宽依赖还是窄依赖
前面一篇文章提到大数据开发-Spark Join原理详解,本文从源码角度来看cogroup 的join实现 1.分析下面的代码 import org.apache.spark.rdd.RDD impo ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- 030 RDD Join中宽依赖与窄依赖的判断
1.规律 如果JoinAPI之前被调用的RDD API是宽依赖(存在shuffle), 而且两个join的RDD的分区数量一致,join结果的rdd分区数量也一样,这个时候join api是窄依赖 除 ...
- 小记--------spark的宽依赖与窄依赖分析
窄依赖: Narrow Dependency : 一个RDD对它的父RDD,只有简单的一对一的依赖关系.RDD的每个partition仅仅依赖于父RDD中的一个partition,父RDD和子RDD的 ...
- spark-宽依赖和窄依赖
一.窄依赖(Narrow Dependency,) 即一个RDD,对它的父RDD,只有简单的一对一的依赖关系.也就是说, RDD的每个partition ,仅仅依赖于父RDD中的一个partition ...
- spark 划分stage Wide vs Narrow Dependencies 窄依赖 宽依赖 解析 作业 job stage 阶段 RDD有向无环图拆分 任务 Task 网络传输和计算开销 任务集 taskset
每个job被划分为多个stage.划分stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个stage,从而避免多个stage之间的消息传递开销. http://spark. ...
随机推荐
- JSON中的坑
坑一. 在使用localStorage时,我们会给一个key存取一个value,这个value可以是一个普通的字符串,也可以是一个对象,如果是一个字符串,我们就需要通过JSON.stringify来转 ...
- 前端中用到的图片(png图片)
作为前端工程师,将设计师的设计稿转化为html页面,其中有一个必不可少的环节就是将psd文件中的一些图片随心所欲的使用,而我们经常用到的就是png图片. 第一部分:基本介绍 首先我们先对比几种图片: ...
- jreble安装 in idea
http://www.cnblogs.com/littlehb/archive/2013/04/19/3031045.html
- 【CSS】 一个简单的导航条
今天来做一个导航条! 首先写一个坯子: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" &quo ...
- SQL Cookbook—数字、日期
1.计算不包含最大值和最小值的均值2.把字母数字串转换为数值3.更改累计和中的值–显示存款或取款后的值4.加减日.月.年5.计算两个日期之间的天数6.确定两个日期之间的工作日数目表EMP中,计算BLA ...
- 常用工具说明--Maven使用说明
什么是Maven? 如今我们构建一个项目需要用到很多第三方的类库,如写一个使用Spring的Web项目就需要引入大量的jar包.一个项目Jar包的数量之多往往让我们瞠目结舌,并且Jar包之间的关系错综 ...
- php操作Excel
php操作Excel 1.new PHPExcel对象$objPHPExcel = new PHPExcel(); 2表的初始化设置$objPHPExcel->getProperties()-& ...
- C# WinForm API 改进单实例运行
在普通的单实例中,第二次点击软件快捷方式的时候,往往简单提示"系统已经运行",而不是把第一次打开的软件主窗体显示出来,下面演示如果主窗体已经打开则把第一次打开的主窗体放置到最前面; ...
- 移动端Push推送
移动端Push推送 移动端开发逃不掉要做推送,这里给出服务端一种省时省力的解决方案. iOS:PushSharp.Apple.苹果有自己的推送服务,我们按照规则推送数据就好.这里我选取PushShar ...
- Hibernate 学习(二)
一.Hibernate 核心 API 1.Configuration 对象(配置) 配置对象是你在任何 Hibernate 应用程序中创造的第一个 Hibernate 对象,并且经常只在应用程序初始化 ...