6.824 Lab 3: Fault-tolerant Key/Value Service 3B
Part B: Key/value service with log compaction
Do a git pull to get the latest lab software.
As things stand now with your lab code, a rebooting server replays the complete Raft log in order to restore its state. However, it's not practical for a long-running server to remember the complete Raft log forever. Instead, you'll modify Raft and kvserver to cooperate to save space: from time to time kvserver will persistently store a "snapshot" of its current state, and Raft will discard log entries that precede the snapshot. When a server restarts (or falls far behind the leader and must catch up), the server first installs a snapshot and then replays log entries from after the point at which the snapshot was created. Section 7 of the extended Raft paper outlines the scheme; you will have to design the details.根据您的实验代码,重新启动的服务器将重播完整的筏日志以恢复其状态。但是,对于长时间运行的服务器来说,永远记住完整的筏日志是不现实的。相反,您将修改Raft和kvserver以节省空间:kvserver将持续地存储当前状态的“快照”,而Raft将丢弃快照之前的日志条目。当服务器重新启动(或远远落后于领先者,必须迎头赶上)时,服务器首先安装快照,然后从创建快照的位置开始重播日志条目。You should spend some time figuring out what the interface will be between your Raft library and your service so that your Raft library can discard log entries. Think about how your Raft will operate while storing only the tail of the log, and how it will discard old log entries. You should discard them in a way that allows the Go garbage collector to free and re-use the memory; this requires that there be no reachable references (pointers) to the discarded log entries.您应该花一些时间来确定您的Raft库和服务之间的接口,以便您的Raft库可以丢弃日志条目。考虑一下您的Raft将如何操作,而只存储日志的尾部,以及它将如何丢弃旧的日志条目。您应该以允许Go垃圾收集器释放和重用内存的方式丢弃它们;这要求对丢弃的日志条目没有可到达的引用(指针)。
The tester passes maxraftstate to your StartKVServer(). maxraftstate indicates the maximum allowed size of your persistent Raft state in bytes (including the log, but not including snapshots). You should compare maxraftstate to persister.RaftStateSize(). Whenever your key/value server detects that the Raft state size is approaching this threshold, it should save a snapshot, and tell the Raft library that it has snapshotted, so that Raft can discard old log entries. If maxraftstate is -1, you do not have to snapshot.当您的键/值服务器检测到Raft的状态大小接近这个阈值时,它应该保存一个快照,并告诉筏库它已经快照了,以便Raft可以丢弃旧的日志条目。如果maxraftstate为-1,则不必快照。
Your raft.go probably keeps the entire log in a Go slice. Modify it so that it can be given a log index, discard the entries before that index, and continue operating while storing only log entries after that index. Make sure you pass all the Raft tests after making these changes.
Modify your kvserver so that it detects when the persisted Raft state grows too large, and then hands a snapshot to Raft and tells Raft that it can discard old log entries. Raft should save each snapshot with persister.SaveStateAndSnapshot() (don't use files). A kvserver instance should restore the snapshot from the persister when it re-starts.kvserver实例应该在重新启动时从persister恢复快照。
- You can test your Raft and kvserver's ability to operate with a trimmed log, and its ability to re-start from the combination of a kvserver snapshot and persisted Raft state, by running the Lab 3A tests while artificially setting maxraftstate to 1.
- Think about when a kvserver should snapshot its state and what should be included in the snapshot. Raft must store each snapshot in the persister object using SaveStateAndSnapshot(), along with corresponding Raft state. You can read the latest stored snapshot using ReadSnapshot().
- Your kvserver must be able to detect duplicated operations in the log across checkpoints, so any state you are using to detect them must be included in the snapshots. Remember to capitalize all fields of structures stored in the snapshot.
- You are allowed to add methods to your Raft so that kvserver can manage the process of trimming the Raft log and manage kvserver snapshots.
Modify your Raft leader code to send an InstallSnapshot RPC to a follower when the leader has discarded the log entries the follower needs. When a follower receives an InstallSnapshot RPC, your Raft code will need to send the included snapshot to its kvserver. You can use the applyCh for this purpose, by adding new fields to ApplyMsg. Your solution is complete when it passes all of the Lab 3 tests.
The maxraftstate limit applies to the GOB-encoded bytes your Raft passes to persister.SaveRaftState().
- You should send the entire snapshot in a single InstallSnapshot RPC. You do not have to implement Figure 13's offset mechanism for splitting up the snapshot.
- Make sure you pass TestSnapshotRPC before moving on to the other Snapshot tests.
- A reasonable amount of time to take for the Lab 3 tests is 400 seconds of real time and 700 seconds of CPU time. Further, go test -run TestSnapshotSize should take less than 20 seconds of real time.
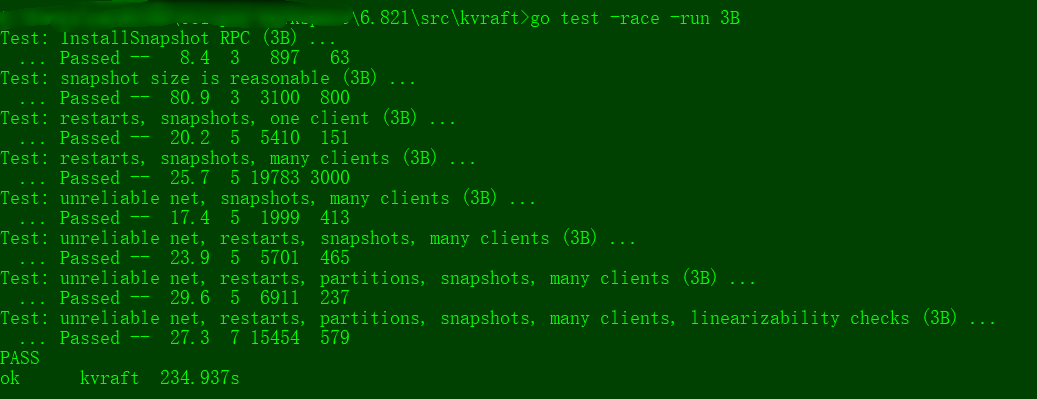
Your code should pass the 3B tests (as in the example here) as well as the 3A tests.
$ go test -run 3B
Test: InstallSnapshot RPC (3B) ...
... Passed -- 1.5 3 163 63
Test: snapshot size is reasonable (3B) ...
... Passed -- 0.4 3 2407 800
Test: restarts, snapshots, one client (3B) ...
... Passed -- 19.2 5 123372 24718
Test: restarts, snapshots, many clients (3B) ...
... Passed -- 18.9 5 127387 58305
Test: unreliable net, snapshots, many clients (3B) ...
... Passed -- 16.3 5 4485 1053
Test: unreliable net, restarts, snapshots, many clients (3B) ...
... Passed -- 20.7 5 4802 1005
Test: unreliable net, restarts, partitions, snapshots, many clients (3B) ...
... Passed -- 27.1 5 3281 535
Test: unreliable net, restarts, partitions, snapshots, many clients, linearizability checks (3B) ...
... Passed -- 25.0 7 11344 748
PASS
ok kvraft 129.114s
my homework code:raft.go
package raft //
// this is an outline of the API that raft must expose to
// the service (or tester). see comments below for
// each of these functions for more details.
//
// rf = Make(...)
// create a new Raft server.
// rf.Start(command interface{}) (index, term, isleader)
// start agreement on a new log entry
// rf.GetState() (term, isLeader)
// ask a Raft for its current term, and whether it thinks it is leader
// ApplyMsg
// each time a new entry is committed to the log, each Raft peer
// should send an ApplyMsg to the service (or tester)
// in the same server.
// import (
"labrpc"
"math/rand"
"sync"
"time"
) import "bytes"
import "labgob" //
// as each Raft peer becomes aware that successive log entries are
// committed, the peer should send an ApplyMsg to the service (or
// tester) on the same server, via the applyCh passed to Make(). set
// CommandValid to true to indicate that the ApplyMsg contains a newly
// committed log entry.
//
// in Lab 3 you'll want to send other kinds of messages (e.g.,
// snapshots) on the applyCh; at that point you can add fields to
// ApplyMsg, but set CommandValid to false for these other uses.
//
type ApplyMsg struct {
CommandValid bool
Command interface{}
CommandIndex int // to send kv snapshot to kv server
CommandData []byte // 3B
} type LogEntry struct {
Command interface{}
Term int
} const (
Follower int =
Candidate int =
Leader int =
HEART_BEAT_TIMEOUT = //心跳超时,要求1秒10次,所以是100ms一次
) //
// A Go object implementing a single Raft peer.
//
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[] // Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
electionTimer *time.Timer // 选举定时器
heartbeatTimer *time.Timer // 心跳定时器
state int // 角色
voteCount int //投票数
applyCh chan ApplyMsg // 提交通道 snapshottedIndex int // 3B 归档位置 //Persistent state on all servers:
currentTerm int //latest term server has seen (initialized to 0 on first boot, increases monotonically)
votedFor int //candidateId that received vote in current term (or null if none)
log []LogEntry //log entries; each entry contains command for state machine, and term when entry was received by leader (first index is 1) //Volatile state on all servers:
commitIndex int //index of highest log entry known to be committed (initialized to 0, increases monotonically)
lastApplied int //index of highest log entry applied to state machine (initialized to 0, increases monotonically)
//Volatile state on leaders:(Reinitialized after election)
nextIndex []int //for each server, index of the next log entry to send to that server (initialized to leader last log index + 1)
matchIndex []int //for each server, index of highest log entry known to be replicated on server (initialized to 0, increases monotonically) } // return currentTerm and whether this server
// believes it is the leader.
func (rf *Raft) GetState() (int, bool) {
var term int
var isleader bool
// Your code here (2A).
rf.mu.Lock()
defer rf.mu.Unlock()
term = rf.currentTerm
isleader = rf.state == Leader
return term, isleader
} func (rf *Raft) encodeRaftState() []byte {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.log)
e.Encode(rf.snapshottedIndex)
return w.Bytes()
} func (rf *Raft) persist() {
// Your code here (2C).
// Example:
// w := new(bytes.Buffer)
// e := labgob.NewEncoder(w)
// e.Encode(rf.currentTerm)
// e.Encode(rf.votedFor)
// e.Encode(rf.log)
// e.Encode(rf.snapshottedIndex)
// data := w.Bytes()
rf.persister.SaveRaftState(rf.encodeRaftState())
}
func (rf *Raft) GetRaftStateSize() int {
return rf.persister.RaftStateSize()
} //
// restore previously persisted state.
//
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < { // bootstrap without any state?
return
}
// Your code here (2C).
// Example:
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm int
var votedFor int
var log []LogEntry
var snapshottedIndex int
if d.Decode(¤tTerm) != nil ||
d.Decode(&votedFor) != nil ||
d.Decode(&log) != nil ||
d.Decode(&snapshottedIndex) != nil {
// error...
panic("fail to decode state")
} else {
rf.currentTerm = currentTerm
rf.votedFor = votedFor
rf.log = log
rf.snapshottedIndex = snapshottedIndex
// for lab 3b, we need to set them at the first index
// i.e., 0 if snapshot is disabled
rf.commitIndex = snapshottedIndex
rf.lastApplied = snapshottedIndex
}
} //
// example RequestVote RPC arguments structure.
// field names must start with capital letters!
//
type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int //candidate’s term
CandidateId int //candidate requesting vote
LastLogIndex int //index of candidate’s last log entry (§5.4)
LastLogTerm int //term of candidate’s last log entry (§5.4)
} //
// example RequestVote RPC reply structure.
// field names must start with capital letters!
//
type RequestVoteReply struct {
// Your data here (2A).
Term int //currentTerm, for candidate to update itself
VoteGranted bool //true means candidate received vote
} //
// example RequestVote RPC handler.
//
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist() // 改动需要持久化
DPrintf("Candidate[raft%v][term:%v] request vote: raft%v[%v] 's term%v\n", args.CandidateId, args.Term, rf.me, rf.state, rf.currentTerm)
if args.Term < rf.currentTerm ||
(args.Term == rf.currentTerm && rf.votedFor != - && rf.votedFor != args.CandidateId) {
reply.Term = rf.currentTerm
reply.VoteGranted = false
return
} if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.switchStateTo(Follower)
} // 2B: candidate's vote should be at least up-to-date as receiver's log
// "up-to-date" is defined in thesis 5.4.1
lastLogIndex := len(rf.log) -
if args.LastLogTerm < rf.log[lastLogIndex].Term ||
(args.LastLogTerm == rf.log[lastLogIndex].Term &&
args.LastLogIndex < rf.getAbsoluteLogIndex(lastLogIndex)) {
// Receiver is more up-to-date, does not grant vote
reply.Term = rf.currentTerm
reply.VoteGranted = false
return
} rf.votedFor = args.CandidateId
reply.Term = rf.currentTerm
reply.VoteGranted = true
// reset timer after grant vote
rf.electionTimer.Reset(randTimeDuration())
} type AppendEntriesArgs struct {
Term int //leader’s term
LeaderId int //so follower can redirect clients
PrevLogIndex int //index of log entry immediately preceding new ones
PrevLogTerm int //term of prevLogIndex entry
Entries []LogEntry //log entries to store (empty for heartbeat; may send more than one for efficiency)
LeaderCommit int //leader’s commitIndex
} type AppendEntriesReply struct {
Term int //currentTerm, for leader to update itself
Success bool //true if follower contained entry matching prevLogIndex and prevLogTerm //Figure 8: A time sequence showing why a leader cannot determine commitment using log entries from older terms. In
// (a) S1 is leader and partially replicates the log entry at index
// 2. In (b) S1 crashes; S5 is elected leader for term 3 with votes
// from S3, S4, and itself, and accepts a different entry at log
// index 2. In (c) S5 crashes; S1 restarts, is elected leader, and
// continues replication. At this point, the log entry from term 2
// has been replicated on a majority of the servers, but it is not
// committed. If S1 crashes as in (d), S5 could be elected leader
// (with votes from S2, S3, and S4) and overwrite the entry with
// its own entry from term 3. However, if S1 replicates an entry from its current term on a majority of the servers before
// crashing, as in (e), then this entry is committed (S5 cannot
// win an election). At this point all preceding entries in the log
// are committed as well.
ConflictTerm int // 2C
ConflictIndex int // 2C
} func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist() // 改动需要持久化
DPrintf("leader[raft%v][term:%v] beat term:%v [raft%v][%v]\n", args.LeaderId, args.Term, rf.currentTerm, rf.me, rf.state)
reply.Success = true // 1. Reply false if term < currentTerm (§5.1)
if args.Term < rf.currentTerm {
reply.Success = false
reply.Term = rf.currentTerm
return
}
//If RPC request or response contains term T > currentTerm:set currentTerm = T, convert to follower (§5.1)
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.switchStateTo(Follower)
} // reset election timer even log does not match
// args.LeaderId is the current term's Leader
rf.electionTimer.Reset(randTimeDuration()) if args.PrevLogIndex <= rf.snapshottedIndex {
reply.Success = true // sync log if needed
if args.PrevLogIndex+len(args.Entries) > rf.snapshottedIndex {
// if snapshottedIndex == prevLogIndex, all log entries should be added.
startIdx := rf.snapshottedIndex - args.PrevLogIndex
// only keep the last snapshotted one
rf.log = rf.log[:]
rf.log = append(rf.log, args.Entries[startIdx:]...)
} return
} // 2. Reply false if log doesn’t contain an entry at prevLogIndex
// whose term matches prevLogTerm (§5.3)
lastLogIndex := rf.getAbsoluteLogIndex(len(rf.log) - )
if lastLogIndex < args.PrevLogIndex {
reply.Success = false
reply.Term = rf.currentTerm
// optimistically thinks receiver's log matches with Leader's as a subset
reply.ConflictIndex = len(rf.log)
// no conflict term
reply.ConflictTerm = -
return
} // 3. If an existing entry conflicts with a new one (same index
// but different terms), delete the existing entry and all that
// follow it (§5.3)
if rf.log[rf.getRelativeLogIndex(args.PrevLogIndex)].Term != args.PrevLogTerm {
reply.Success = false
reply.Term = rf.currentTerm
// receiver's log in certain term unmatches Leader's log
reply.ConflictTerm = rf.log[rf.getRelativeLogIndex(args.PrevLogIndex)].Term // expecting Leader to check the former term
// so set ConflictIndex to the first one of entries in ConflictTerm
conflictIndex := args.PrevLogIndex
// apparently, since rf.log[0] are ensured to match among all servers
// ConflictIndex must be > 0, safe to minus 1
for rf.log[rf.getRelativeLogIndex(conflictIndex-)].Term == reply.ConflictTerm {
conflictIndex--
if conflictIndex == rf.snapshottedIndex+ {
// this may happen after snapshot,
// because the term of the first log may be the current term
// before lab 3b this is not going to happen, since rf.log[0].Term = 0
break
}
}
reply.ConflictIndex = conflictIndex
return
} // 4. Append any new entries not already in the log
// compare from rf.log[args.PrevLogIndex + 1]
unmatch_idx := -
for idx := range args.Entries {
if len(rf.log) < rf.getRelativeLogIndex(args.PrevLogIndex++idx) ||
rf.log[rf.getRelativeLogIndex(args.PrevLogIndex++idx)].Term != args.Entries[idx].Term {
// unmatch log found
unmatch_idx = idx
break
}
} if unmatch_idx != - {
// there are unmatch entries
// truncate unmatch Follower entries, and apply Leader entries
rf.log = rf.log[:rf.getRelativeLogIndex(args.PrevLogIndex++unmatch_idx)]
rf.log = append(rf.log, args.Entries[unmatch_idx:]...)
} //5. If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
if args.LeaderCommit > rf.commitIndex {
rf.setCommitIndex(min(args.LeaderCommit, rf.getAbsoluteLogIndex(len(rf.log)-)))
} reply.Success = true
} //
// example code to send a RequestVote RPC to a server.
// server is the index of the target server in rf.peers[].
// expects RPC arguments in args.
// fills in *reply with RPC reply, so caller should
// pass &reply.
// the types of the args and reply passed to Call() must be
// the same as the types of the arguments declared in the
// handler function (including whether they are pointers).
//
// The labrpc package simulates a lossy network, in which servers
// may be unreachable, and in which requests and replies may be lost.
// Call() sends a request and waits for a reply. If a reply arrives
// within a timeout interval, Call() returns true; otherwise
// Call() returns false. Thus Call() may not return for a while.
// A false return can be caused by a dead server, a live server that
// can't be reached, a lost request, or a lost reply.
//
// Call() is guaranteed to return (perhaps after a delay) *except* if the
// handler function on the server side does not return. Thus there
// is no need to implement your own timeouts around Call().
//
// look at the comments in ../labrpc/labrpc.go for more details.
//
// if you're having trouble getting RPC to work, check that you've
// capitalized all field names in structs passed over RPC, and
// that the caller passes the address of the reply struct with &, not
// the struct itself.
//
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
return ok
} func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
return ok
} //
// the service using Raft (e.g. a k/v server) wants to start
// agreement on the next command to be appended to Raft's log. if this
// server isn't the leader, returns false. otherwise start the
// agreement and return immediately. there is no guarantee that this
// command will ever be committed to the Raft log, since the leader
// may fail or lose an election. even if the Raft instance has been killed,
// this function should return gracefully.
//
// the first return value is the index that the command will appear at
// if it's ever committed. the second return value is the current
// term. the third return value is true if this server believes it is
// the leader.
//
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -
term := -
isLeader := true // Your code here (2B).
rf.mu.Lock()
defer rf.mu.Unlock()
term = rf.currentTerm
isLeader = rf.state == Leader
if isLeader {
rf.log = append(rf.log, LogEntry{Command: command, Term: term})
rf.persist() // 改动需要持久化
index = rf.getAbsoluteLogIndex(len(rf.log) - )
rf.matchIndex[rf.me] = index
rf.nextIndex[rf.me] = index + 1
rf.heartbeats()
} return index, term, isLeader
} //
// the tester calls Kill() when a Raft instance won't
// be needed again. you are not required to do anything
// in Kill(), but it might be convenient to (for example)
// turn off debug output from this instance.
//
func (rf *Raft) Kill() {
// Your code here, if desired.
} //
// the service or tester wants to create a Raft server. the ports
// of all the Raft servers (including this one) are in peers[]. this
// server's port is peers[me]. all the servers' peers[] arrays
// have the same order. persister is a place for this server to
// save its persistent state, and also initially holds the most
// recent saved state, if any. applyCh is a channel on which the
// tester or service expects Raft to send ApplyMsg messages.
// Make() must return quickly, so it should start goroutines
// for any long-running work.
//
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me // Your initialization code here (2A, 2B, 2C).
rf.state = Follower
rf.votedFor = -
rf.heartbeatTimer = time.NewTimer(HEART_BEAT_TIMEOUT * time.Millisecond)
rf.electionTimer = time.NewTimer(randTimeDuration()) rf.applyCh = applyCh
rf.log = make([]LogEntry, ) // start from index 1 // initialize from state persisted before a crash
rf.mu.Lock()
rf.readPersist(persister.ReadRaftState())
rf.mu.Unlock() rf.nextIndex = make([]int, len(rf.peers))
//for persist
for i := range rf.nextIndex {
// initialized to leader last log index + 1
rf.nextIndex[i] = len(rf.log)
}
rf.matchIndex = make([]int, len(rf.peers)) //以定时器的维度重写background逻辑
go func() {
for {
select {
case <-rf.electionTimer.C:
rf.mu.Lock()
switch rf.state {
case Follower:
rf.switchStateTo(Candidate)
case Candidate:
rf.startElection()
}
rf.mu.Unlock() case <-rf.heartbeatTimer.C:
rf.mu.Lock()
if rf.state == Leader {
rf.heartbeats()
rf.heartbeatTimer.Reset(HEART_BEAT_TIMEOUT * time.Millisecond)
}
rf.mu.Unlock()
}
}
}() return rf
} func randTimeDuration() time.Duration {
return time.Duration(HEART_BEAT_TIMEOUT*+rand.Intn(HEART_BEAT_TIMEOUT)) * time.Millisecond
} //切换状态,调用者需要加锁
func (rf *Raft) switchStateTo(state int) {
if state == rf.state {
return
}
DPrintf("Term %d: server %d convert from %v to %v\n", rf.currentTerm, rf.me, rf.state, state)
rf.state = state
switch state {
case Follower:
rf.heartbeatTimer.Stop()
rf.electionTimer.Reset(randTimeDuration())
rf.votedFor = -
case Candidate:
//成为候选人后立马进行选举
rf.startElection() case Leader:
// initialized to leader last log index + 1
for i := range rf.nextIndex {
rf.nextIndex[i] = rf.getAbsoluteLogIndex(len(rf.log))
}
for i := range rf.matchIndex {
rf.matchIndex[i] = rf.snapshottedIndex //3B
} rf.electionTimer.Stop()
rf.heartbeats()
rf.heartbeatTimer.Reset(HEART_BEAT_TIMEOUT * time.Millisecond)
}
} // 发送心跳包,调用者需要加锁
func (rf *Raft) heartbeats() {
for i := range rf.peers {
if i != rf.me {
go rf.heartbeat(i)
}
}
} func (rf *Raft) heartbeat(server int) {
rf.mu.Lock()
if rf.state != Leader {
rf.mu.Unlock()
return
} prevLogIndex := rf.nextIndex[server] - if prevLogIndex < rf.snapshottedIndex {
// leader has discarded log entries the follower needs
// send snapshot to follower and retry later
rf.mu.Unlock()
rf.syncSnapshotWith(server)
return
} // use deep copy to avoid race condition
// when override log in AppendEntries()
entries := make([]LogEntry, len(rf.log[rf.getRelativeLogIndex(prevLogIndex+):]))
copy(entries, rf.log[rf.getRelativeLogIndex(prevLogIndex+):]) args := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLogIndex,
PrevLogTerm: rf.log[rf.getRelativeLogIndex(prevLogIndex)].Term,
Entries: entries,
LeaderCommit: rf.commitIndex,
}
rf.mu.Unlock() var reply AppendEntriesReply
if rf.sendAppendEntries(server, &args, &reply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != Leader {
return
}
// If last log index ≥ nextIndex for a follower: send
// AppendEntries RPC with log entries starting at nextIndex
// • If successful: update nextIndex and matchIndex for
// follower (§5.3)
// • If AppendEntries fails because of log inconsistency:
// decrement nextIndex and retry (§5.3)
if reply.Success {
// successfully replicated args.Entries
rf.matchIndex[server] = args.PrevLogIndex + len(args.Entries)
rf.nextIndex[server] = rf.matchIndex[server] + // If there exists an N such that N > commitIndex, a majority
// of matchIndex[i] ≥ N, and log[N].term == currentTerm:
// set commitIndex = N (§5.3, §5.4).
for N := rf.getAbsoluteLogIndex(len(rf.log) - ); N > rf.commitIndex; N-- {
count :=
for _, matchIndex := range rf.matchIndex {
if matchIndex >= N {
count +=
}
} if count > len(rf.peers)/ {
// most of nodes agreed on rf.log[i]
rf.setCommitIndex(N)
break
}
} } else {
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.switchStateTo(Follower)
rf.persist() // 改动需要持久化
} else {
//如果走到这个分支,那一定是需要前推(优化前推)
rf.nextIndex[server] = reply.ConflictIndex // if term found, override it to
// the first entry after entries in ConflictTerm
if reply.ConflictTerm != - {
for i := args.PrevLogIndex; i >= rf.snapshottedIndex+; i-- {
if rf.log[rf.getRelativeLogIndex(i-)].Term == reply.ConflictTerm {
// in next trial, check if log entries in ConflictTerm matches
rf.nextIndex[server] = i
break
}
}
}
//和等待下一轮执行相比,直接retry并没有明显优势,但对于3B有效
go rf.heartbeat(server)
}
}
// rf.mu.Unlock()
}
} // 开始选举,调用者需要加锁
func (rf *Raft) startElection() { // DPrintf("raft%v is starting election\n", rf.me)
rf.currentTerm +=
rf.votedFor = rf.me //vote for me
rf.persist() // 改动需要持久化
rf.voteCount =
rf.electionTimer.Reset(randTimeDuration()) for i := range rf.peers {
if i != rf.me {
go func(peer int) {
rf.mu.Lock()
lastLogIndex := len(rf.log) -
args := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: rf.getAbsoluteLogIndex(lastLogIndex),
LastLogTerm: rf.log[lastLogIndex].Term,
}
// DPrintf("raft%v[%v] is sending RequestVote RPC to raft%v\n", rf.me, rf.state, peer)
rf.mu.Unlock()
var reply RequestVoteReply
if rf.sendRequestVote(peer, &args, &reply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.switchStateTo(Follower)
rf.persist() // 改动需要持久化
}
if reply.VoteGranted && rf.state == Candidate {
rf.voteCount++
if rf.voteCount > len(rf.peers)/ {
rf.switchStateTo(Leader)
}
}
}
}(i)
}
}
} //
// several setters, should be called with a lock
//
func (rf *Raft) setCommitIndex(commitIndex int) {
rf.commitIndex = commitIndex
// apply all entries between lastApplied and committed
// should be called after commitIndex updated
if rf.commitIndex > rf.lastApplied {
DPrintf("%v apply from index %d to %d", rf, rf.lastApplied+, rf.commitIndex)
entriesToApply := append([]LogEntry{}, rf.log[rf.getRelativeLogIndex(rf.lastApplied+):rf.getRelativeLogIndex(rf.commitIndex+)]...) go func(startIdx int, entries []LogEntry) {
for idx, entry := range entries {
var msg ApplyMsg
msg.CommandValid = true
msg.Command = entry.Command
msg.CommandIndex = startIdx + idx
rf.applyCh <- msg
// do not forget to update lastApplied index
// this is another goroutine, so protect it with lock
rf.mu.Lock()
if rf.lastApplied < msg.CommandIndex {
rf.lastApplied = msg.CommandIndex
}
rf.mu.Unlock()
}
}(rf.lastApplied+, entriesToApply)
}
}
func min(x, y int) int {
if x < y {
return x
} else {
return y
}
} //3B
func (rf *Raft) ReplaceLogWithSnapshot(appliedIndex int, kvSnapshot []byte) {
rf.mu.Lock()
defer rf.mu.Unlock()
if appliedIndex <= rf.snapshottedIndex {
return
}
// truncate log, keep snapshottedIndex as a guard at rf.log[0]
// because it must be committed and applied
rf.log = rf.log[rf.getRelativeLogIndex(appliedIndex):]
rf.snapshottedIndex = appliedIndex
rf.persister.SaveStateAndSnapshot(rf.encodeRaftState(), kvSnapshot) // update for other nodes
for i := range rf.peers {
if i == rf.me {
continue
}
go rf.syncSnapshotWith(i)
}
} // invoke by Leader to sync snapshot with one follower
func (rf *Raft) syncSnapshotWith(server int) {
rf.mu.Lock()
if rf.state != Leader {
rf.mu.Unlock()
return
}
args := InstallSnapshotArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
LastIncludedIndex: rf.snapshottedIndex,
LastIncludedTerm: rf.log[].Term,
Data: rf.persister.ReadSnapshot(),
}
DPrintf("%v sync snapshot with server %d for index %d, last snapshotted = %d",
rf, server, args.LastIncludedIndex, rf.snapshottedIndex)
rf.mu.Unlock() var reply InstallSnapshotReply if rf.sendInstallSnapshot(server, &args, &reply) {
rf.mu.Lock()
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.switchStateTo(Follower)
rf.persist()
} else {
if rf.matchIndex[server] < args.LastIncludedIndex {
rf.matchIndex[server] = args.LastIncludedIndex
}
rf.nextIndex[server] = rf.matchIndex[server] +
}
rf.mu.Unlock()
}
} func (rf *Raft) getRelativeLogIndex(index int) int {
// index of rf.log
return index - rf.snapshottedIndex
} func (rf *Raft) getAbsoluteLogIndex(index int) int {
// index of log including snapshotted ones
return index + rf.snapshottedIndex
} type InstallSnapshotArgs struct {
// do not need to implement "chunk"
// remove "offset" and "done"
Term int // 3B
LeaderId int // 3B
LastIncludedIndex int // 3B
LastIncludedTerm int // 3B
Data []byte // 3B
} type InstallSnapshotReply struct {
Term int // 3B
} func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
// we do not need to call rf.persist() in this function
// because rf.persister.SaveStateAndSnapshot() is called reply.Term = rf.currentTerm
if args.Term < rf.currentTerm || args.LastIncludedIndex < rf.snapshottedIndex {
return
} if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.switchStateTo(Follower)
// do not return here.
} // step 2, 3, 4 is skipped because we simplify the "offset" // 6. if existing log entry has same index and term with
// last log entry in snapshot, retain log entries following it
lastIncludedRelativeIndex := rf.getRelativeLogIndex(args.LastIncludedIndex)
if len(rf.log) > lastIncludedRelativeIndex &&
rf.log[lastIncludedRelativeIndex].Term == args.LastIncludedTerm {
rf.log = rf.log[lastIncludedRelativeIndex:]
} else {
// 7. discard entire log
rf.log = []LogEntry{{Term: args.LastIncludedTerm, Command: nil}}
}
// 5. save snapshot file, discard any existing snapshot
rf.snapshottedIndex = args.LastIncludedIndex
// IMPORTANT: update commitIndex and lastApplied because after sync snapshot,
// it has at least applied all logs before snapshottedIndex
if rf.commitIndex < rf.snapshottedIndex {
rf.commitIndex = rf.snapshottedIndex
}
if rf.lastApplied < rf.snapshottedIndex {
rf.lastApplied = rf.snapshottedIndex
} rf.persister.SaveStateAndSnapshot(rf.encodeRaftState(), args.Data) if rf.lastApplied > rf.snapshottedIndex {
// snapshot is elder than kv's db
// if we install snapshot on kvserver, linearizability will break
return
} installSnapshotCommand := ApplyMsg{
CommandIndex: rf.snapshottedIndex,
Command: "InstallSnapshot",
CommandValid: false,
CommandData: rf.persister.ReadSnapshot(),
}
go func(msg ApplyMsg) {
rf.applyCh <- msg
}(installSnapshotCommand)
} func (rf *Raft) sendInstallSnapshot(server int, args *InstallSnapshotArgs, reply *InstallSnapshotReply) bool {
ok := rf.peers[server].Call("Raft.InstallSnapshot", args, reply)
return ok
}
server.go
package raftkv import (
"bytes"
"labgob"
"labrpc"
"log"
"raft"
"sync"
"time"
) const Debug = func DPrintf(format string, a ...interface{}) (n int, err error) {
if Debug > {
log.Printf(format, a...)
}
return
} type Op struct {
// Your definitions here.
// Field names must start with capital letters,
// otherwise RPC will break.
Key string
Value string
Name string ClientId int64
RequestId int
} type KVServer struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg maxraftstate int // snapshot if log grows this big // Your definitions here.
db map[string]string // 3A
dispatcher map[int]chan Notification // 3A
lastAppliedRequestId map[int64]int // 3A appliedRaftLogIndex int // 3B
} // 3B
func (kv *KVServer) shouldTakeSnapshot() bool {
if kv.maxraftstate == - {
return false
} if kv.rf.GetRaftStateSize() >= kv.maxraftstate {
return true
}
return false
} func (kv *KVServer) takeSnapshot() {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
kv.mu.Lock()
e.Encode(kv.db)
e.Encode(kv.lastAppliedRequestId)
appliedRaftLogIndex := kv.appliedRaftLogIndex
kv.mu.Unlock() kv.rf.ReplaceLogWithSnapshot(appliedRaftLogIndex, w.Bytes())
} //3A
type Notification struct {
ClientId int64
RequestId int
} func (kv *KVServer) Get(args *GetArgs, reply *GetReply) {
// Your code here.
op := Op{
Key: args.Key,
Name: "Get",
ClientId: args.ClientId,
RequestId: args.RequestId,
} // wait for being applied
// or leader changed (log is overrided, and never gets applied)
reply.WrongLeader = kv.waitApplying(op, *time.Millisecond) if reply.WrongLeader == false {
kv.mu.Lock()
value, ok := kv.db[args.Key]
kv.mu.Unlock()
if ok {
reply.Value = value
return
}
// not found
reply.Err = ErrNoKey
}
} func (kv *KVServer) PutAppend(args *PutAppendArgs, reply *PutAppendReply) {
// Your code here.
op := Op{
Key: args.Key,
Value: args.Value,
Name: args.Op,
ClientId: args.ClientId,
RequestId: args.RequestId,
} // wait for being applied
// or leader changed (log is overrided, and never gets applied)
reply.WrongLeader = kv.waitApplying(op, *time.Millisecond)
} //
// the tester calls Kill() when a KVServer instance won't
// be needed again. you are not required to do anything
// in Kill(), but it might be convenient to (for example)
// turn off debug output from this instance.
//
func (kv *KVServer) Kill() {
kv.rf.Kill()
// Your code here, if desired.
} //
// servers[] contains the ports of the set of
// servers that will cooperate via Raft to
// form the fault-tolerant key/value service.
// me is the index of the current server in servers[].
// the k/v server should store snapshots through the underlying Raft
// implementation, which should call persister.SaveStateAndSnapshot() to
// atomically save the Raft state along with the snapshot.
// the k/v server should snapshot when Raft's saved state exceeds maxraftstate bytes,
// in order to allow Raft to garbage-collect its log. if maxraftstate is -1,
// you don't need to snapshot.
// StartKVServer() must return quickly, so it should start goroutines
// for any long-running work.
//
func StartKVServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister, maxraftstate int) *KVServer {
// call labgob.Register on structures you want
// Go's RPC library to marshall/unmarshall.
labgob.Register(Op{}) kv := new(KVServer)
kv.me = me
kv.maxraftstate = maxraftstate // You may need initialization code here.
kv.db = make(map[string]string)
kv.dispatcher = make(map[int]chan Notification)
kv.lastAppliedRequestId = make(map[int64]int) kv.applyCh = make(chan raft.ApplyMsg)
kv.rf = raft.Make(servers, me, persister, kv.applyCh) // 3B: recover from snapshot
snapshot := persister.ReadSnapshot()
kv.installSnapshot(snapshot) // You may need initialization code here.
go func() {
for msg := range kv.applyCh {
if msg.CommandValid == false {
//3B
switch msg.Command.(string) {
case "InstallSnapshot":
kv.installSnapshot(msg.CommandData)
}
continue
} op := msg.Command.(Op)
DPrintf("kvserver %d start applying command %s at index %d, request id %d, client id %d",
kv.me, op.Name, msg.CommandIndex, op.RequestId, op.ClientId)
kv.mu.Lock()
if kv.isDuplicateRequest(op.ClientId, op.RequestId) {
kv.mu.Unlock()
continue
}
switch op.Name {
case "Put":
kv.db[op.Key] = op.Value
case "Append":
kv.db[op.Key] += op.Value
// Get() does not need to modify db, skip
}
kv.lastAppliedRequestId[op.ClientId] = op.RequestId
// 3B
kv.appliedRaftLogIndex = msg.CommandIndex if ch, ok := kv.dispatcher[msg.CommandIndex]; ok {
notify := Notification{
ClientId: op.ClientId,
RequestId: op.RequestId,
}
ch <- notify
} kv.mu.Unlock()
DPrintf("kvserver %d applied command %s at index %d, request id %d, client id %d",
kv.me, op.Name, msg.CommandIndex, op.RequestId, op.ClientId)
}
}() return kv
} // should be called with lock
func (kv *KVServer) isDuplicateRequest(clientId int64, requestId int) bool {
appliedRequestId, ok := kv.lastAppliedRequestId[clientId]
if ok == false || requestId > appliedRequestId {
return false
}
return true
} func (kv *KVServer) waitApplying(op Op, timeout time.Duration) bool {
// return common part of GetReply and PutAppendReply
// i.e., WrongLeader
index, _, isLeader := kv.rf.Start(op)
if isLeader == false {
return true
} // 3B
if kv.shouldTakeSnapshot() {
kv.takeSnapshot()
} var wrongLeader bool kv.mu.Lock()
if _, ok := kv.dispatcher[index]; !ok {
kv.dispatcher[index] = make(chan Notification, )
}
ch := kv.dispatcher[index]
kv.mu.Unlock()
select {
case notify := <-ch:
if notify.ClientId != op.ClientId || notify.RequestId != op.RequestId {
// leader has changed
wrongLeader = true
} else {
wrongLeader = false
} case <-time.After(timeout):
kv.mu.Lock()
if kv.isDuplicateRequest(op.ClientId, op.RequestId) {
wrongLeader = false
} else {
wrongLeader = true
}
kv.mu.Unlock()
}
DPrintf("kvserver %d got %s() RPC, insert op %+v at %d, reply WrongLeader = %v",
kv.me, op.Name, op, index, wrongLeader) kv.mu.Lock()
delete(kv.dispatcher, index)
kv.mu.Unlock()
return wrongLeader
} // 3B
func (kv *KVServer) installSnapshot(snapshot []byte) {
kv.mu.Lock()
defer kv.mu.Unlock()
if snapshot != nil {
r := bytes.NewBuffer(snapshot)
d := labgob.NewDecoder(r)
if d.Decode(&kv.db) != nil ||
d.Decode(&kv.lastAppliedRequestId) != nil {
DPrintf("kvserver %d fails to recover from snapshot", kv.me)
}
}
}
go test -run 3B

go test -race -run 3B
6.824 Lab 3: Fault-tolerant Key/Value Service 3B的更多相关文章
- 6.824 Lab 3: Fault-tolerant Key/Value Service 3A
6.824 Lab 3: Fault-tolerant Key/Value Service Due Part A: Mar 13 23:59 Due Part B: Apr 10 23:59 Intr ...
- 6.824 Lab 2: Raft 2A
6.824 Lab 2: Raft Part 2A Due: Feb 23 at 11:59pm Part 2B Due: Mar 2 at 11:59pm Part 2C Due: Mar 9 at ...
- FTH: (7156): *** Fault tolerant heap shim applied to current process. This is usually due to previous crashes. ***
这两天在Qtcreator上编译程序的时候莫名其妙的出现了FTH: (7156): *** Fault tolerant heap shim applied to current process. T ...
- MIT-6.824 Lab 3: Fault-tolerant Key/Value Service
概述 lab2中实现了raft协议,本lab将在raft之上实现一个可容错的k/v存储服务,第一部分是实现一个不带日志压缩的版本,第二部分是实现日志压缩.时间原因我只完成了第一部分. 设计思路 如上图 ...
- 6.824 Lab 2: Raft 2C
Part 2C Do a git pull to get the latest lab software. If a Raft-based server reboots it should resum ...
- Akka的fault tolerant
要想容错,该怎么办? 父actor首先要获知子actor的失败状态,然后确定该怎么办, “怎么办”这回事叫做“supervisorStrategy". // Restart the st ...
- 6.824 Lab 5: Caching Extents
Introduction In this lab you will modify YFS to cache extents, reducing the load on the extent serve ...
- 6.824 Lab 2: Raft 2B
Part 2B We want Raft to keep a consistent, replicated log of operations. A call to Start() at the le ...
- 解决Qt4.8.6+VS2010运行程序提示 FTH: (6512): *** Fault tolerant heap shim applied to current process. This is usually due to previous crashes
这个问题偶尔碰到两次,现在又遇上了,解决办法如下: 打开注册表,设置HKLM\Software\Microsoft\FTH\Enabled 为0 打开CMD,运行Rundll32.exe fthsvc ...
随机推荐
- matlab 中figure的图像 抗锯齿
linehandle = plot(xxxxxx); set( linehandle, 'linesmoothing', 'on' );
- Big Data(七)MapReduce计算框架(PPT截图)
一.为什么叫MapReduce? Map是以一条记录为单位映射 Reduce是分组计算
- ACR095 删一个求中位数 贪心求最大组合数 行列变换模拟(搜索)
A B #include <bits/stdc++.h> #define PI acos(-1.0) #define mem(a,b) memset((a),b,sizeof(a)) #d ...
- python实现学生信息系统
要求:不能重名 ''' 一.需求:进入系统显示系统功能界面,功能如下: 1.添加学员 2.删除学员 3.修改学员信息 4.查询学员信息 5.显示所有学员信息 6.退出功能 ''' # 定义功能界面函数 ...
- 如何创建DLL,以及注入DLL
为了防止忘记,特记下 DLL的创建,在VS2017中选择dll的创建 // dllmain.cpp : Defines the entry point for the DLL application. ...
- 第三篇:解析库之re、beautifulsoup、pyquery
BeatifulSoup模块 一.介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Be ...
- MegaPixImage插件代码(new MegaPixImage)
/** * Mega pixel image rendering library for iOS6 Safari * * Fixes iOS6 Safari's image file renderin ...
- 工作流学习之入门demo
/** * Copyright (C), 2015-2018, XXX有限公司 * FileName: DemoMain * Author: happy * Date: 2018/6/23 16:33 ...
- 一个不错的vue项目
项目演示: https://www.xiaohuochai.cc 项目地址:https://github.com/littlematch0123/blog-client
- java 流操作对文件的分割和合并的实例详解_java - JAVA
文章来源:嗨学网 敏而好学论坛www.piaodoo.com 欢迎大家相互学习 java 流操作对文件的分割和合并的实例详解 学习文件的输入输出流,自己做一个小的示例,对文件进行分割和合并. 下面是代 ...