高性能mysql 附录D explain执行计划详解
EXPLAIN:
- extended关键字:在explain后使用extended关键字,可以显示filtered列和warning信息。在较旧的MySQL版本中,扩展信息是使用EXPLAIN EXTENDED生成的。 该语法仍然被识别为向后兼容,但扩展输出现在默认启用,因此EXTENDED关键字是多余的,已被弃用。 它的使用会导致警告,并且将在未来的MySQL版本中从EXPLAIN语法中删除。
- partitions关键字:显示查询将访问的分区,如果你的查询是基于分区表。
在5.6版本,如果要获取filtered列和warning信息,还要加上extended关键字的。
如:
- mysql> EXPLAIN EXTENDED
- *************************** 1. row ***************************
- id: 1
- select_type: PRIMARY
- table: t1
- type: index
- possible_keys: NULL
- key_len: 4
- ref: NULL
- rows: 4
- filtered: 100.00
- *************************** 2. row ***************************
- id: 2
- select_type: SUBQUERY
- table: t2
- type: index
- possible_keys: a
- key: a
- key_len: 5
- ref: NULL
- rows: 3
- filtered: 100.00
- mysql> SHOW WARNINGS\G
- *************************** 1. row ***************************
- Level: Note
- Code: 1003
- <in_optimizer>(`test`.`t1`.`a`,`test`.`t1`.`a` in
- ( <materialize> (/* select#2 */ select `test`.`t2`.`a`
- <primary_index_lookup>(`test`.`t1`.`a` in
SHOW WARNINGS中给出的是模拟执行计划的sql。里面有非常丰富的内容。可以提供给我们来参考。
show warnings的说明:https://dev.mysql.com/doc/refman/5.7/en/explain-extended.html
explain语法"尽量"不执行查询,但是如果为了获取执行计划需要查询(如要有子查询的结果才知道下一步的查询计划),那么explain其实是需要执行一些查询的。
EXPLAIN只是一个近似结果。以下有一些相关的限制:
- EXPLAIN不会告诉你触发器、存储过程或UDF会如何影响查询。
- EXPLAIN 不支持存储过程,尽管可以手动抽取查询并单独对其进行EXPLAIN操作。
- EXPLAIN不会告诉你MySQL在查询执行中所做的特定优化。
- EXPLAIN不会显示关于查询的执行计划的所有信息。
- EXPLAIN不区分具有相同名字的事物。例如,它对内存排序和临时文件都使用"filesort",并且对于磁盘上和内存中的临时表都显示"Using temporary"。
重写非select查询
explain只能解释select查询,无法解释存储过程、insert、delete、update等其他类似的语句,可以把非select语句转化为对等的 select 访问请求。
ps:5.6之后可以解释update insert。
EXPLAIN中的列:
id
id用来表示执行顺序,id相同的为一组,先执行id数字大的组,然后执行数字小的组。在id相同的一组内,顺序由上而下执行。子查询和union操作产生新的id,普通的join不会产生新id。
select type
|
val |
explain |
|
SIMPLE |
简单 SELECT(不使用 UNION 或子查询) |
|
PRIMARY |
查询中包含任何复杂查询,最外层的的SELECT |
|
SUBQUERY |
在 select 或 where 中包含的子查询 |
|
DERIVED |
FROM 子句的子查询; Mysql会将这种子查询执行并放在一个临时表中。 若 union 包含在 from 子句的子查询中,外层的 select被标记为 DERIVED。 |
|
UNION |
在 select 或 where 中包含的子查询 |
|
UNION RESULT |
UNION结果 |
|
DEPENDENT UNION |
UNION 中的第二个或后面的 SELECT 语句,取决于外面的查询 DEPENDENT SUBQUERY |
|
DEPENDENT SUBQUERY |
子查询中的第一个 SELECT,取决于外面的查询 |
ps:mysql5.6有MATERIALIZED,代表物化子查询
type
表示MySQL在表中找到所需行的方式,又称"访问类型",常见类型如下:
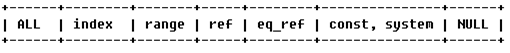
由左至右,由最差到最好。
ALL代表全表扫描(如果有limit,也会显示ALL,其实可能没有扫描全部的数据,扫描部分就停止了),
index代表索引全扫描(一般出现在where中没有索引的条件,但是order by中有索引。),他的性能甚至不如ALL,因为ALL直接通过聚簇索引来获取数据,如果id是连续的,那么数据也是连续的,而index需要通过二级索引来检索id,然后在根据id检索数据,会产生大量io,使用这个一般是为了避免排序。
range索引范围扫描(where中有索引的条件 如> between,或者in后面是固定的值,但是in和其他的有差别,in可以想象成是拆分成很多=),
ref是非唯一性索引扫描,常见的是作用在=的比较上,但是非唯一。
eq_ref:ref的唯一性索引扫描。
const, system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量。system是const类型的特例,当查询的表只有一行的情况下, 使用system。
5.6中还包含:
ref_or_null:此连接类型与ref一样,但除此之外,MySQL还会对包含NULL值的行进行额外的搜索。
如下SQ可以使用ref_or_null:
SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL;
index_merge:此连接类型表示使用索引合并优化。
unique_subquery:unique_subquery只是一个索引查找功能,可以完全替换子查询以提高效率。如:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery:此连接类型与unique_subquery类似。 它替换IN子查询,但它适用于以下形式的子查询中的非唯一索引。
possible_keys
指出MySQL能使用哪个索引在表中找到行,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用。注:如果使用覆盖索引扫描,此处为空。
key
显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
rows:
表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数。如果三张表的join,那么将三行的rows相乘,就是数据库大概要读取的所有行数。
ref:
记录使用key列标识的索引时,查找值使用的常数或者列。
extra列:
use index:这里并不是表示使用了索引的意思。使用了索引可以通过key列来查看,而且key列显示了使用索引的名称。use index表示使用覆盖索引扫描。就是说,没有访问数据文件,所有的数据都是从索引文件中获取。
use where:这里并不是表示使用了where条件的意思,而是说服务层从存储引擎获取数据之后再进行where过滤。
Using index condition:表示使用索引条件下推。
Using filesort:使用了排序(即使是内存中的排序也叫filesort)
Using temporary:使用了临时表
Impossible WHERE:出现在优化阶段,优化器根据表定义可以判断出where条件根本不可能成立,比如主健不可能为空
Using join buffer (Block Nested Loop):mysql使用了优化过的nest loop算法,一次读取多个块.
filtered 列
这一列在使用EXPLAIN EXTENDED时出现。它显示的是针对表里符合某个条件(where子句或联接条件)的记录数的百分比所做的一个悲观估算。如果将rows列和这个百分比相乘,就能看到MySQL估算它将和查询计划里前一个表关联的行数。
ps:如果filtered比例太大,那么mysql将会舍弃使用索引,而选择ALL。
扩展:
http://www.jianshu.com/p/fa37e037aa5f 有列子
http://www.cnblogs.com/jxlwqq/p/5391232.html
高性能mysql 附录D explain执行计划详解的更多相关文章
- ( 转 ) MySQL高级 之 explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- MySQL高级 之 explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- MySQL高级 之 explain执行计划详解(转)
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- Mysql探索之Explain执行计划详解
前言 如何写出效率高的SQL语句,提到这必然离不开Explain执行计划的分析,至于什么是执行计划,如何写出高效率的SQL,本篇文章将会一一介绍. 执行计划 执行计划是数据库根据 SQL 语句和相关表 ...
- MySQL — 优化之explain执行计划详解(转)
EXPLAIN简介 EXPLAIN 命令是查看查询优化器如何决定执行查询的主要方法,使用EXPLAIN,只需要在查询中的SELECT关键字之前增加EXPLAIN这个词即可,MYSQL会在查询上设置一个 ...
- MySQL性能分析, mysql explain执行计划详解
MySQL性能分析 MySQL性能分析及explain用法的知识是本文我们主要要介绍的内容,接下来就让我们通过一些实际的例子来介绍这一过程,希望能够对您有所帮助. 1.使用explain语句去查看分析 ...
- MySql——Explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- 【夯实Mysql基础】mysql explain执行计划详解
原文地址 1).id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. 2).select_type列常见的有: A ...
- mysql explain执行计划详解
1).id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. 2).select_type列常见的有: A:simp ...
随机推荐
- eclipse搭建简单的web服务,使用tomcat服务
打开eclipse,新建web project, 若本机安装的eclipse版本高,jdk版本低,提示当前版本不适合,解决方法,通过Windows搜索Java,点击配置Java,之后如下图:
- spring-boot集成5:集成jrebel实现热加载
Why Jrebel? 使用jrebel可以方便的实现spring-boot项目的热部署,直接reload更改的class,无需重启,提升开发效率. 1.安装jrebel插件 在idea中安装jreb ...
- HCL试验八
pc1:配置静态ip地址,掩码,网关 路由器R1:配置ip地址192.168.1.254 24;配置dhcp int gi 0/0 ip add 192.168.1.254 24 qu dhcp en ...
- 防火墙之iptables
Netfilter/Iptables(以下简称Iptables)是unix/linux自带的一款优秀且开放源代码的完全自由的基于包过滤的防火墙工具,它的功能十分强大,使用非常灵活,可以对流入和流出服务 ...
- Spring 启动时加载资源
Spring加载资源文件目前了解三种, @PostConstruct在Context加载完成之后加载.在创建各个Bean对象之前加载. 实现ApplicationRunner的run方法,Bean加载 ...
- python并发编程-进程池线程池-协程-I/O模型-04
目录 进程池线程池的使用***** 进程池/线程池的创建和提交回调 验证复用池子里的线程或进程 异步回调机制 通过闭包给回调函数添加额外参数(扩展) 协程*** 概念回顾(协程这里再理一下) 如何实现 ...
- Python sqlalchemy 高级用法
一. 关联查询 sys_user_list = SysPermission.query.join(OrgRolePermission, OrgRolePermission.sys_permission ...
- Java小程序—录屏小程序(上半场)
做软件的三个步骤: (1)做什么? (2)怎么做? (3)动手做! ok,我们今天要做的是一个录屏软件,那怎么做呢?首先,我们小时候都玩过一种小人书,就是当你快速翻动书页时,书中的人物就会活灵活现的动 ...
- 通过PlayBook部署Zabbix
编写Linux初始化剧本 初始化剧本环节,主要用户实现关闭Selinux关闭防火墙,一起配置一下阿里云的YUM源地址,和安装EPEL源,为后期的zabbix安装做好铺垫工作. 1.在安装Zabbix之 ...
- Box-shadow制作漂亮的外阴影输入框
背景:之前做项目中的一个移动端页面,关于在搜索框中输入信息查找对应的照片 改了几次ui图之后,最终的搜索框的设计图如下: 开始做页面的时候,就想到了用box-shadow 来实现外阴影边框.用bord ...