HBaseRegionServer宕机数据恢复
本文由 网易云 发布
作者:范欣欣
本篇文章仅限内部分享,如需转载,请联系网易获取授权。
众所周知,HBase默认适用于写多读少的应用,正是依赖于它相当出色的写入性能:一个100台RS的集群可以轻松地支撑每天10T 的写入量。当然,为了支持更高吞吐量的写入,HBase还在不断地进行优化和修正,这篇文章结合0.98版本的源码全面地分析HBase的写入流程,全文分为三个部分,第一部分介绍客户端的写入流程,第二部分介绍服务器端的写入流程,最后再重点分析WAL的工作原理(注:从服务器端的角度理解,HBase写入分为两个阶段,第一阶段数据会被写入memstore,并且会执行WAL的写入;第二阶段会将memstore的中的数据集中flush到磁盘,本文主要集中分析第一阶段的相关细节)。
客户端流程解析
(1)用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用group commit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。
(2)在提交之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection 的locateRegion方法获得的。如果是批量请求的话还会把这些rowkey按照HRegionLocation分组,每个分组可以对应一次RPC请求。
( 3 )HBase 会为每个HRegionLocation 构造一个远程RPC 请求MultiServerCallable<Row> , 然后通过rpcCallerFactory.<MultiResponse> newCaller()执行调用,忽略掉失败重新提交和错误处理,客户端的提交操作到此结束。服务器端流程解析服务器端RegionServer接收到客户端的写入请求后,首先会反序列化为Put对象,然后执行各种检查操作,比如检查region是否是只读、memstore大小是否超过blockingMemstoreSize等。检查完成之后,就会执行如下核心操作:
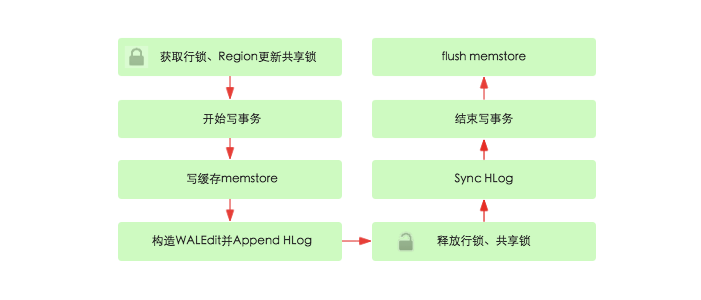
(1) 获取行锁、Region更新共享锁: HBase中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性,要么更新成功,要么失败。
(2) 开始写事务:获取write number,用于实现MVCC,实现数据的非锁定读,在保证读写一致性的前提下提高读取性能。
(3) 写缓存memstore:HBase中每个列族都会对应一个store,用来存储该列族数据。每个store都会有个写缓存memstore,用于缓存写入数据。HBase并不会直接将数据落盘,而是先写入缓存,等缓存满足一定大小之后再一起落盘。
(4) Append HLog:HBase使用WAL机制保证数据可靠性,即首先写日志再写缓存,即使发生宕机,也可以通过恢复HLog还原出原始数据。该步骤就是将数据构造为WALEdit对象,然后顺序写入HLog中,此时不需要执行sync操作。0.98版本采用了新的写线程模式实现HLog日志的写入,可以使得整个数据更新性能得到极大提升,具体原理见下一个章节。
(5)释放行锁以及共享锁
(6)Sync HLog真正sync到HDFS,在释放行锁之后执行sync操作是为了尽量减少持锁时间,提升写性能。如果Sync失败,执行回滚操作将memstore中已经写入的数据移除。
(7) 结束写事务:此时该线程的更新操作才会对其他读请求可见,更新才实际生效。具体分析见上一篇文章《HBase - 并发控制深度解析》
(8) flush memstore:当写缓存满64M之后,会启动flush线程将数据刷新到硬盘。刷新操作涉及到HFile相关结构,后面会详细对此进行介绍。
WAL机制解析
WAL(Write-Ahead Logging)是一种高效的日志算法,几乎是所有非内存数据库提升写性能的不二法门,基本原理是在数据写入之前首先顺序写入日志,然后再写入缓存,等到缓存写满之后统一落盘。之所以能够提升写性能,是因为WAL将一次随机写转化为了一次顺序写加一次内存写。提升写性能的同时,WAL可以保证数据的可靠性,即在任何情况下数据不丢失。假如一次写入完成之后发生了宕机,即使所有缓存中的数据丢失,也可以通过恢复日志还原出丢失的数据。
WAL 持 久 化 等 级
HBase中可以通过设置WAL的持久化等级决定是否开启WAL机制、以及HLog的落盘方式。WAL的持久化等级分为如下四个等级:
1. SKIP_WAL:只写缓存,不写HLog日志。这种方式因为只写内存,因此可以极大的提升写入性能,但是数据有丢失的风险。在实际应用过程中并不建议设置此等级,除非确认不要求数据的可靠性。
2. ASYNC_WAL:异步将数据写入HLog日志中。
3. SYNC_WAL:同步将数据写入日志文件中,需要注意的是数据只是被写入文件系统中,并没有真正落盘。
4. FSYNC_WAL:同步将数据写入日志文件并强制落盘。最严格的日志写入等级,可以保证数据不会丢失,但是性能相对比较差。
5. USER_DEFAULT:默认如果用户没有指定持久化等级,HBase使用SYNC_WAL等级持久化数据。
用户可以通过客户端设置WAL持久化等级,代码:put.setDurability(Durability. SYNC_WAL );
HLog数据结构
HBase中,WAL的实现类为HLog,每个Region Server拥有一个HLog日志,所有region的写入都是写到同一个HLog。下图表示同一个Region Server中的3个 region 共享一个HLog。当数据写入时,是将数据对<HLogKey,WALEdit>按照顺序追加到HLog 中,以获取最好的写入性能。
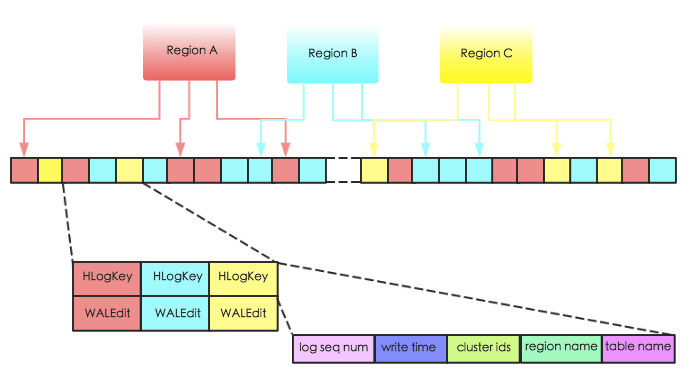
上图中HLogKey主要存储了log sequence number,更新时间 write time,region name,表名table name以及cluster ids。其中log sequncece number作为HFile中一个重要的元数据,和HLog的生命周期息息相关,后续章节会详细介绍;region name和table name分别表征该段日志属于哪个region以及哪张表;cluster ids用于将日志复制到集群中其他机器上。
WALEdit用来表示一个事务中的更新集合,在之前的版本,如果一个事务中对一行row R中三列c1,c2,c3分别做了修改,那么hlog中会有3个对应的日志片段如下所示:
<logseq3-for-edit3>:<keyvalue-for-edit-c3>
然而,这种日志结构无法保证行级事务的原子性,假如刚好更新到c2之后发生宕机,那么就会产生只有部分日志写入成功的现象。为此,hbase将所有对同一行的更新操作都表示为一个记录,如下:
<logseq#-for-entire-txn>:<WALEdit-for-entire-txn>
其中WALEdit会被序列化为格式<-1, # of edits, <KeyValue>, <KeyValue>, <KeyValue>>,比如<-1, 3, <keyvalue-for-edit- c1>, <keyvalue-for-edit-c2>, <keyvalue-for-edit-c3>>,其中-1作为标示符表征这种新的日志结构。
WAL写入模型
了解了HLog 的结构之后, 我们就开始研究HLog 的写入模型。 HLog 的写入可以分为三个阶段, 首先将数据对<HLogKey,WALEdit>写入本地缓存,然后再将本地缓存写入文件系统,最后执行sync操作同步到磁盘。在以前老的写入模型中, 上述三步都由工作线程独自完成,如下图所示:
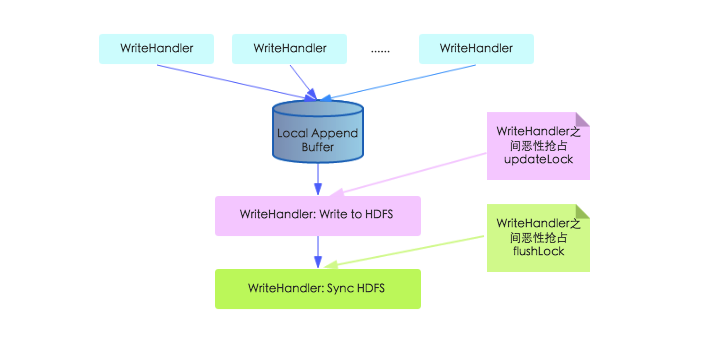
上图中,本地缓存写入文件系统那个步骤工作线程需要持有updateLock执行,不同工作线程之间必然会恶性竞争;不仅如此,在Sync HDFS这步中,工作线程之间需要抢占flushLock,因为Sync操作是一个耗时操作,抢占这个锁会导致写入性能大幅降低。
所幸的是,来自中国(准确的来说,是来自小米,鼓掌)的3位工程师意识到了这个问题,进而提出了一种新的写入模型并被官方 采纳。根据官方测试,新写入模型的吞吐量比之前提升3倍多,单台RS写入吞吐量介于12150~31520,5台RS组成的集群写入吞吐量介于22000~70000(见HBASE-8755)。下图是小米官方给出来的对比测试结果:
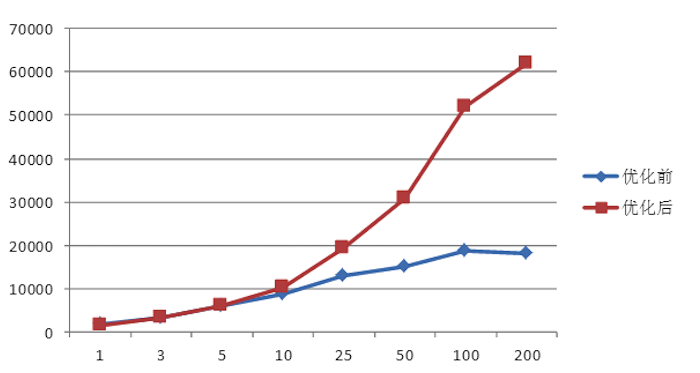
在新写入模型中,本地缓存写入文件系统以及Sync HDFS都交给了新的独立线程完成,并引入一个Notify线程通知工作线程是否已经Sync成功,采用这种机制消除上述锁竞争,具体如下图所示:
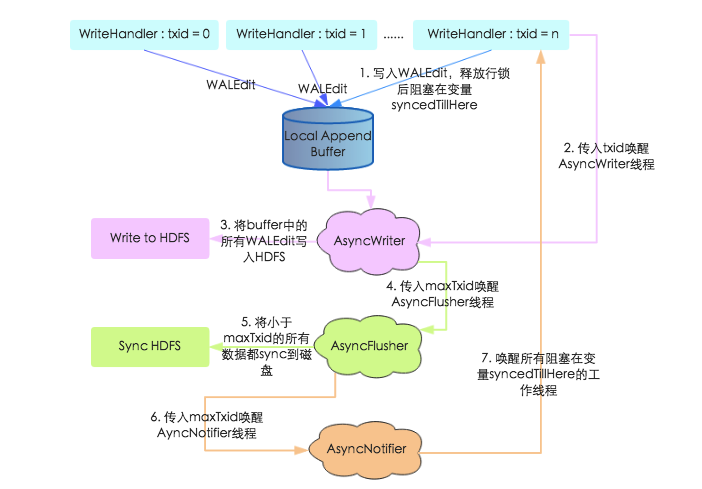
1. 上文中提到工作线程在写入WALEdit 之后并没有进行Sync , 而是等到释放行锁阻塞在syncedTillHere 变量上, 等待AsyncNotifier线程唤醒。
2. 工作线程将WALEdit写入本地Buffer之后,会生成一个自增变量txid,携带此txid唤醒AsyncWriter线程
3. AsyncWriter 线程会取出本地Buffer 中的所有WALEdit , 写入HDFS 。注意该线程会比较传入的txid 和已经写入的最大txid(writtenTxid),如果传入的txid小于writteTxid,表示该txid对应的WALEdit已经写入,直接跳过
4. AsyncWriter线程将所有WALEdit写入HDFS之后携带maxTxid唤醒AsyncFlusher线程
5. AsyncFlusher线程将所有写入文件系统的WALEdit统一Sync刷新到磁盘
6. 数据全部落盘之后调用setFlushedTxid方法唤醒AyncNotifier线程
7. AyncNotifier线程会唤醒所有阻塞在变量syncedTillHere的工作线程,工作线程被唤醒之后表示WAL写入完成,后面再执行MVCC结束写事务,推进全局读取点,本次更新才会对用户可见
通过上述过程的梳理可以知道,新写入模型采取了多线程模式独立完成写文件系统、sync磁盘操作,避免了之前多工作线程恶性抢占锁的问题。同时,工作线程在将WALEdit写入本地Buffer之后并没有马上阻塞,而是释放行锁之后阻塞等待WALEdit落盘,这样可以尽可能地避免行锁竞争,提高写入性能。
总结
文章刚开始就提到HBase写入分为两个阶段,本文主要集中分析第一阶段的相关细节,首先介绍了HBase的写入memstore的流程,之后重点分析了WAL的写入模型以及相关优化。后面一篇文章会接着介绍写入到memstore的数据落盘的相关知识点,敬请期待!
HBaseRegionServer宕机数据恢复的更多相关文章
- Hadoop错误之namenode宕机的数据恢复
情景再现: 在修复hadoop集群某一个datanode无法启动的问题时,搜到有一个答案说要删除hdfs-site.xml中dfs.data.dir属性所配置的目录,再重新单独启动该datanode即 ...
- Vertica节点宕机处理一例
Vertica节点宕机处理一例: 查询数据库版本和各节点状态 常规方式启动宕机节点失败 进一步查看宕机节点的详细日志 定位问题并解决 1. 查询数据库版本和各节点状态 dbadmin=> sel ...
- 服务器宕机,mysql无法启动,job for mysql.service failed because the process exited with error code,数据库备份与恢复
[问题现象] 服务器在运行过程中,因人为意外导致电源被拔,服务器宕机,mysql重启不成功,报错如下 根据提示,输入systemctl status mysql.service和journalctl ...
- 宕机了,Redis数据丢了怎么办?
持续原创输出,点击上方蓝字关注我 目录 前言 什么是AOF? 三种写回策略 日志文件太大怎么办? AOF重写会阻塞主线程吗? AOF的缺点 总结 什么是RDB? 给哪些数据做快照? 快照时能够修改数据 ...
- Redis 日志篇:无畏宕机快速恢复的杀手锏
特立独行是对的,融入圈子也是对的,重点是要想清楚自己向往怎样的生活,为此愿意付出怎样的代价. 我们通常将 Redis 作为缓存使用,提高读取响应性能,一旦 Redis 宕机,内存中的数据全部丢失,假如 ...
- Vertica集群单节点宕机恢复方法
Vertica集群单节点宕机恢复方法 第一种方法: 直接通过admintools -> 5 Restart Vertica on Host 第二种方法: 若第一种方法无法恢复,则清空宕机节点的c ...
- VmWare平台Windows Server 2012 无响应宕机
我们生产服务器都部署在VMware ESXi 5.5平台上,最近大半年的时间,偶尔就会出现操作系统为Windows Servre 2012的服务器出现没有任何响应(unresponsive)的情况,出 ...
- Linux服务器宕机案例一则
案例环境 操作系统 :Oracle Linux Server release 5.7 64bit 虚拟机 硬件配置 : 物理机型号为DELL R720 资源配置 :RAM 8G Intel(R) Xe ...
- 由于某IP大频率提交评论导致服务器宕机
早上突然收到dnspod的宕机通知(好久没收到了,有点手足无措). 服务器在上午10:40时达到85%.uptime显示cpu利用率达到35.不宕才怪. 按照之前的经验,应该是触发一个特别耗CPU的处 ...
随机推荐
- php提交表单时如何保留多个空格及换行的文本样式
需求是:用户提交表单时屏蔽敏感词的功能.其中敏感词来自服务器端同一路径下的ciku.txt,敏感词通过"|"连接,例如"g|c|a",提交表单时替换敏感词,更重 ...
- python爬取企业登记业务
import requests from lxml import etree import csv for i in range(10, 990, 10): url = "http://12 ...
- SpringCloud-Eureka-Provider&Consumer
Eureka-Provider 服务的提供者 新建一个服务提供者项目 1.导入pom文件 <properties> <java.version>1.8</java.ver ...
- Django学习——开发你的第一个Django应用1
突然对Django热情似火,所以就开学习了,我是根据官方文档学习的,所以我打算把官方文档翻译一遍,全当学习,首先贴官方文档的地址:https://docs.djangoproject.com/en/1 ...
- canvas 画正方形和圆形
绘制正方形 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- rabbitmq3.7集群搭建实战
环境: 3台 centos7.4rabbitmq3.7erlang 22 1. 有几种方式安装,这里使用的yum安装(官方推荐)2. 使用rabbitmq时需要安装erlang,在各个节点上使用vim ...
- javascript中数组元素删除方法splice,用在for循环中巨坑
一.demo splice: 该方法会改变自动原始数组长度 实例: var array = ["aa","dd","cc","aa ...
- mongodb Access control is not enabled for the database 无访问控制解决方案
转载:https://blog.csdn.net/q1056843325/article/details/70941697 今天使用MongoDB时遇到了一些问题 建立数据库连接时出现了warning ...
- Struts和Hibernate的jar包
这几天做了一个javaee关于struts框架和Hibernate框架的实践,实践内容倒是没什么,关键是找框架的配置花了许多时间 于是在这里把这两个框架的有关jar上传分享一下 链接: https:/ ...
- 每天一个linux命令:which(17)
which which命令用于查找并显示给定命令的绝对路径,环境变量PATH中保存了查找命令时需要遍历的目录.which指令会在环境变量$PATH设置的目录里查找符合条件的文件.也就是说,使用whic ...