大数据笔记(十五)——Hive的体系结构与安装配置、数据模型
一.常见的数据分析引擎
- Hive:Hive是一个翻译器,一个基于Hadoop之上的数据仓库,把SQL语句翻译成一个 MapReduce程序。可以看成是Hive到MapReduce的映射器。
Hive HDFS
表 目录
数据 文件
分区 目2
2.Pig
3.Impala
4.Spark SQL
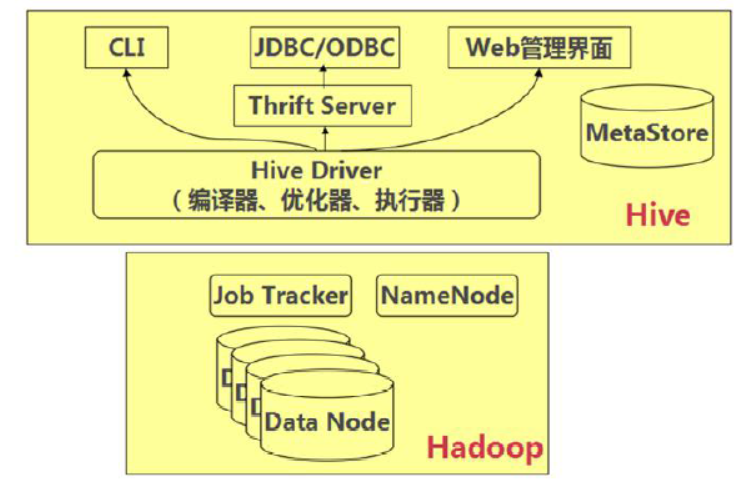
二.Hive 的体系结构
用户接口主要有三个:
1.CLI Shell命令行
2.JDBC/ODBC:Hive的Java,与传统JDBC相似
3.Web管理界面
三.Hive的安装和配置
1、安装模式:嵌入模式 ----> 需要Hive自带的一个关系型数据库:Derby
本地模式、远程模式 ----> 需要MySQL数据库的支持
tar -zxvf apache-hive-2.3.0-bin.tar.gz -C ~/training/
环境变量:vi ~/.bash_profile
HIVE_HOME=/root/training/apache-hive-2.3.0-bin export HIVE_HOME PATH=$HIVE_HOME/bin:$PATH export PATH
2、嵌入模式
(1)使用Hive自带的Derby数据库来存储元信息
(2)Hive只支持一个连接
创建 conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby:;databaseName=metastore_db;create=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>org.apache.derby.jdbc.EmbeddedDriver</value> </property> <property> <name>hive.metastore.local</name> <value>true</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>file:///root/training/apache-hive-2.3.0-bin/warehouse</value> </property> </configuration>
初始化MetaStore:
schematool -dbType derby -initSchema
日志:
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
3.远程模式:MySQL
(1)配置MySQL的数据库:http://www.mysqlfront.de/
(2)配置hive-site.xml: JDBC的参数
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hiveowner</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>Welcome_1</value> </property> </configuration>
(3)把MySQL数据库的驱动放到: Hive/lib下
(4)初始化MySQL数据库
老版本的Hive:第一次运行Hive
新版本的hive:schematool -dbType mysql -initSchema
四. Hive的数据模型
- 内部表:相当于MySQL(Oracle)中表,将数据保存到Hive自己的数据仓库的 目录中: /usr/hive/warehouse
建表:
create table emp (empno int, ename string, job string, mgr int, hiredate string, sal int, comm int, deptno int );
创建表,并且指定分隔符
create table emp1 (empno int, ename string, job string, mgr int, hiredate string, sal int, comm int, deptno int )row format delimited fields terminated by ',';
导入数据:load相当于ctrl+X
load data inpath '/scott/emp.csv' into table emp; ----> 导入HDFS
load data local inpath '/root/temp/***' into table emp; ----> 导入本地文件
创建部门表,保存部门数据
create table dept (deptno int, dname string, loc string )row format delimited fields terminated by ','; load data inpath '/scott/dept.csv' into table dept;
2.分区表:提高查询的效率----> 查看SQL的执行计划
分区 ----> 目录
(*)根据员工的部门号建立分区
create table emp_part (empno int, ename string, job string, mgr int, hiredate string, sal int, comm int )partitioned by (deptno int) row format delimited fields terminated by ',';
往分区表中导入数据:指明分区
insert into table emp_part partition(deptno=10) select empno,ename,job,mgr,hiredate,sal,comm from emp1 where deptno=10; insert into table emp_part partition(deptno=20) select empno,ename,job,mgr,hiredate,sal,comm from emp1 where deptno=20; insert into table emp_part partition(deptno=30) select empno,ename,job,mgr,hiredate,sal,comm from emp1 where deptno=30
3.外部表 external table 相对于内部表
(*)实验的数据
[root@bigdata11 ~]# hdfs dfs -cat /students/student01.txt
1,Tom,23
2,Mary,24
[root@bigdata11 ~]# hdfs dfs -cat /students/student02.txt
3,Mike,26
(*)定义:(1)表结构 (2)指向的路径
create external table students_ext (sid int,sname string,age int) row format delimited fields terminated by ',' location '/students';
4、桶表:本质也是一种分区表,类似Hash分区
桶 ----> 文件
创建一个桶表,按照员工的职位job分桶
create table emp_bucket (empno int, ename string, job string, mgr int, hiredate string, sal int, comm int, deptno int )clustered by (job) into 4 buckets row format delimited fields terminated by ',';
使用桶表,需要打开一个开关
set hive.enforce.bucketing=true;
使用子查询插入数据
insert into emp_bucket select * from emp1;
5、视图:view
(*)视图是一个虚表,虚:视图是不存数据的
(*)优点:简化复杂的查询
(*)举例:查询部门名称、员工的姓名
create view myview as select dept.dname,emp1.ename from emp1,dept where emp1.deptno=dept.deptno; select * from myview;
6、Hive的查询
(1)查询所有的员工信息
select * from emp1;
(2)查询员工信息:员工号 姓名 薪水
select empno,ename,sal from emp1;
(3)多表查询:查询部门名称、员工的姓名
select dept.dname,emp1.ename
from emp1,dept
where emp1.deptno=dept.deptno;
(4)子查询:hive只支持:from和where后面的子查询
(5)内置函数:select max(sal) from emp1;
(6)n条件函数 就是一个if else: 做一个报表:涨工资,总裁1000 经理800 其他400
select empno,ename,job,sal,
case job when 'PRESIDENT' then sal+1000
when 'MANAGER' then sal+800
else sal+400
end
from emp1;
select empno,ename,job,sal,
case job when 'PRESIDENT' then sal+1000
when 'MANAGER' then sal+800
else sal+400
end
from emp;
大数据笔记(十五)——Hive的体系结构与安装配置、数据模型的更多相关文章
- 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例【转】
Kylin 麒麟官网:http://kylin.apache.org/cn/download/ 关键字:olap.Kylin Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的 ...
- 大数据笔记(五)——HDFS的高级特性
一.HDFS的回收站: recyclebin 1.HDFS的回收站默认是关闭的 2.启用回收站:去core-site.xml配置 路径:/root/training/hadoop-2.7.3/etc/ ...
- 大数据笔记(三)——Hadoop2.0的安装与配置
一.Hadoop安装部署的预备条件 准备:1.安装Linux和JDK. 安装JDK 解压:tar -zxvf jdk-8u144-linux-x64.tar.gz -C ~/training/ 设置环 ...
- 跟上节奏 大数据时代十大必备IT技能
跟上节奏 大数据时代十大必备IT技能 新的想法诞生新的技术,从而造出许多新词,云计算.大数据.BYOD.社交媒体……在互联网时代,各种新词层出不穷,让人应接不暇.这些新的技术,这些新兴应用和对应的IT ...
- 大数据工具篇之Hive与MySQL整合完整教程
大数据工具篇之Hive与MySQL整合完整教程 一.引言 Hive元数据存储可以放到RDBMS数据库中,本文以Hive与MySQL数据库的整合为目标,详细说明Hive与MySQL的整合方法. 二.安装 ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
- CentOS6安装各种大数据软件 第五章:Kafka集群的配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
随机推荐
- P1182 数列分段`Section II` 二分
https://www.luogu.org/problemnew/show/P1182 做了这个题才知道二分的强大 这个题可以假设我们有n个果子 m个容器 要能把果子全装进去 那么容器最小可以是多小 ...
- 线程中断:Thread类中interrupt()、interrupted()和 isInterrupted()方法详解
首先看看官方说明: interrupt()方法 其作用是中断此线程(此线程不一定是当前线程,而是指调用该方法的Thread实例所代表的线程),但实际上只是给线程设置一个中断标志,线程仍会继续运行. i ...
- 求大组合数mod p,(p不一定为质数)
#include<bits/stdc++.h> using namespace std; typedef long long ll; #define N 2000005 ll p; ll ...
- SpringBoot_04springDataJPA
说明:底层使用Hibernate 一.springDataJPA和mybatisPlus的使用区别 第一步: 把mybatisPlus的依赖.配置删除 包括:实体类的注解.引导类的mapperScan ...
- 简单的物流项目实战,WPF的MVVM设计模式(三)
往Services文件里面添加接口以及实现接口 IUserService接口 List<User> GetAllUser(); GetUserService类 ConnectToDatab ...
- Python 进程之间共享数据(全局变量)
进程之间共享数据(数值型): import multiprocessing def func(num): num.value=10.78 #子进程改变数值的值,主进程跟着改变 if __name__= ...
- linux 源码安装postgresql
下载源码包 --安装所需要的系统软件包 yum groupinstall -y "Development tools" yum install -y bison flex read ...
- Django开发环境配置(win10)
开发工具 pycharm专业版 安装Django pip install Django==2.0 如果不带版本号,默认安装最新版本查看Django 查看版本: python -m django --v ...
- 自然语言处理资源NLP
转自:https://github.com/andrewt3000/DL4NLP Deep Learning for NLP resources State of the art resources ...
- 强化学习(Reinfment Learning) 简介
本文内容来自以下两个链接: https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/ https: ...