Netty之Page级别的内存分配
Page 级别的内存分配:
之前我们介绍过, netty 内存分配的单位是chunk, 一个chunk 的大小是16MB, 实际上每个chunk, 都以双向链表的形式保存在一个chunkList 中, 而多个chunkList, 同样也是双向链表进行关联的, 大概结构如下所示:
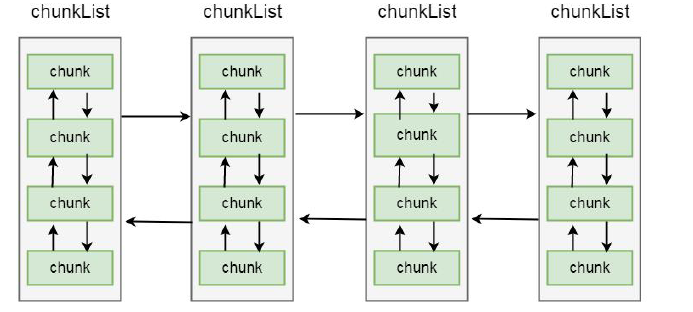
在chunkList 中, 是根据chunk 的内存使用率归到一个chunkList 中, 这样, 在内存分配时, 会根据百分比找到相应的chunkList, 在chunkList 中选择一个chunk 进行内存分配。我们来看PoolArena 中有关chunkList 的成员变量:
private final PoolChunkList<T> q050;
private final PoolChunkList<T> q025;
private final PoolChunkList<T> q000;
private final PoolChunkList<T> qInit;
private final PoolChunkList<T> q075;
private final PoolChunkList<T> q100;
这里总共定义了6 个chunkList, 并在构造方法将其进行初始化,我们跟到其构造方法中:
protected PoolArena(PooledByteBufAllocator parent, int pageSize, int maxOrder, int pageShifts, int chunkSize) {
.......
q100 = new PoolChunkList<T>(null, , Integer.MAX_VALUE, chunkSize);
q075 = new PoolChunkList<T>(q100, , , chunkSize);
q050 = new PoolChunkList<T>(q075, , , chunkSize);
q025 = new PoolChunkList<T>(q050, , , chunkSize);
q000 = new PoolChunkList<T>(q025, , , chunkSize);
qInit = new PoolChunkList<T>(q000, Integer.MIN_VALUE, , chunkSize);
//用双向链表的方式进行连接
q100.prevList(q075);
q075.prevList(q050);
q050.prevList(q025);
q025.prevList(q000);
q000.prevList(null);
qInit.prevList(qInit);
}
首先通过new PoolChunkList()这种方式将每个chunkList 进行创建, 我们以q050 = new PoolChunkList<T>(q075, 50,100, chunkSize) 为例进行简单的介绍。q075 表示当前q50 的下一个节点是q075, 刚才我们讲过ChunkList 是通过双向链表进行关联的, 所以这里不难理解。参数50 和100 表示当前chunkList 中存储的chunk 的内存使用率都在50%到100%之间, 最后chunkSize 为其设置大小。创建完ChunkList 之后, 再设置其上一个节点, q050.prevList(q025)为例, 这里代表当前chunkList 的上一个节点是q025。以这种方式创建完成之后, chunkList 的节点关系变成了如下图所示:

Netty 中, chunk 又包含了多个page, 每个page 的大小为8KB, 如果要分配16KB 的内存, 则在在chunk 中找到连续的两个page 就可以分配, 对应关系如下:

很多场景下, 为缓冲区分配8KB 的内存也是一种浪费, 比如只需要分配2KB 的缓冲区, 如果使用8KB 会造成6KB 的浪费, 这种情况, netty 又会将page 切分成多个subpage, 每个subpage 大小要根据分配的缓冲区大小而指定, 比如要分配2KB 的内存, 就会将一个page 切分成4 个subpage, 每个subpage 的大小为2KB, 如下图:

来看看PoolSubpage 的基本结构:
final class PoolSubpage<T> implements PoolSubpageMetric {
final PoolChunk<T> chunk;
private final int memoryMapIdx;
private final int runOffset;
private final int pageSize;
private final long[] bitmap;
PoolSubpage<T> prev;
PoolSubpage<T> next;
.....
}
chunk 代表其子页属于哪个chunk;bitmap 用于记录子页的内存分配情况;prev 和next, 代表子页是按照双向链表进行关联的, 这里分别指向上一个和下一个节点;elemSize 属性, 代表的就是这个子页是按照多大内存进行划分的, 如果按照1KB 划分, 则可以划分出8 个子页;简单介绍了内存分配的数据结构,我们开始看看Netty 在page 级别上分配内存的流程,还是回到PoolArena 的allocate 方法:
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
//规格化 reqCapacity=256
final int normCapacity = normalizeCapacity(reqCapacity);
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
//判断是不是tiny
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512//缓存分配
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}//通过tinyIdx 拿到tableIdx
tableIdx = tinyIdx(normCapacity);
//subpage 的数组
table = tinySubpagePools;
} else {
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
//拿到对应的节点
final PoolSubpage<T> head = table[tableIdx];
synchronized (head) {
final PoolSubpage<T> s = head.next;
//默认情况下, head 的next 也是自身
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= ;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
if (tiny) {
allocationsTiny.increment();
} else {
allocationsSmall.increment();
}
return;
}
}
allocateNormal(buf, reqCapacity, normCapacity);
return;
}
if (normCapacity <= chunkSize) {
//首先在缓存上进行内存分配
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}//分配不成功, 做实际的内存分配
allocateNormal(buf, reqCapacity, normCapacity);
} else {//大于这个值, 就不在缓存上分配
// Huge allocations are never served via the cache so just call allocateHuge
allocateHuge(buf, reqCapacity);
}
}
我们之前提到过过, 如果在缓存中分配不成功, 则会开辟一块连续的内存进行缓冲区分配, 这里我们先跳过isTinyOrSmall(normCapacity)往后的代码, 之后再来分析。首先if (normCapacity <= chunkSize) 说明其小于16MB, 然后首先在缓存中分配, 因为最初缓存中没有值, 所以会走到allocateNormal(buf, reqCapacity, normCapacity), 这里实际上就是在page 级别上进行分配, 分配一个或者多个page 的空间。我们跟进到allocateNormal()方法:
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
//首先在原来的chunk 上进行内存分配(1)
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
++allocationsNormal;
return;
}
//创建chunk 进行内存分配(2)
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
++allocationsNormal;
assert handle > ;
//初始化byteBuf(3)
c.initBuf(buf, handle, reqCapacity);
qInit.add(c);
}
这里主要拆解了如下步骤:
- 在原有的chunk 中进行分配;
- 创建chunk 进行分配;
- 初始化ByteBuf。
首先我们看第一步, 在原有的chunk 中进行分配,chunkList 是存储不同内存使用量的chunk 集合, 每个chunkList 通过双向链表的形式进行关联, 这里的q050.allocate(buf, reqCapacity, normCapacity)就代表首先在q050 这个chunkList 上进行内存分配。我们以q050 为例进行分析, 跟到q050.allocate(buf, reqCapacity, normCapacity)方法中:
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (head == null || normCapacity > maxCapacity) {
// Either this PoolChunkList is empty or the requested capacity is larger then the capacity which can
// be handled by the PoolChunks that are contained in this PoolChunkList.
return false;
}
//从head 节点往下遍历
for (PoolChunk<T> cur = head;;) {
long handle = cur.allocate(normCapacity);
if (handle < ) {
cur = cur.next;
if (cur == null) {
return false;
}
} else {
cur.initBuf(buf, handle, reqCapacity);
if (cur.usage() >= maxUsage) {
remove(cur);
nextList.add(cur);
}
return true;
}
}
}
首先会从head 节点往下遍历:long handle = cur.allocate(normCapacity) 表示对于每个chunk, 都尝试去分配;if (handle < 0) 说明没有分配到, 则通过cur = cur.next 找到下一个节点继续进行分配, 我们讲过chunk 也是通过双向链表进行关联的。如果handle 大于0 说明已经分配到了内存, 则通过cur.initBuf(buf,handle, reqCapacity)对byteBuf 进行初始化;if (cur.usage() >= maxUsage) 代表当前chunk 的内存使用率大于其最大使用率, 则通过remove(cur)从当前的chunkList 中移除, 再通过nextList.add(cur)添加到下一个chunkList 中。我们再回到PoolArena 的allocateNormal()方法中:看第二步PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize),这里的参数pageSize 是8192,也就是8KB。maxOrder 为11;pageShifts 为13, 2 的13 次方正好是8192, 也就是8KB;chunkSize 为16777216, 也就是16MB。因为我们分析的是堆外内存, newChunk(pageSize, maxOrder, pageShifts, chunkSize)所以会走到DirectArena 的newChunk()方法:
protected PoolChunk<ByteBuffer> newChunk(int pageSize, int maxOrder, int pageShifts, int chunkSize) {
return new PoolChunk<ByteBuffer>(
this, allocateDirect(chunkSize),
pageSize, maxOrder, pageShifts, chunkSize);
}
这里直接通过构造函数创建了一个chunk。allocateDirect(chunkSize)这里是通过jdk 的api 的申请了一块直接内存, 我们跟到PoolChunk 的构造函数中:
PoolChunk(PoolArena<T> arena, T memory, int pageSize, int maxOrder, int pageShifts, int chunkSize) {
unpooled = false;
this.arena = arena;
//memeory 为一个ByteBuf
this.memory = memory;
this.pageSize = pageSize;//8k
this.pageShifts = pageShifts;//13
this.maxOrder = maxOrder;//11
this.chunkSize = chunkSize;
unusable = (byte) (maxOrder + );
log2ChunkSize = log2(chunkSize);
subpageOverflowMask = ~(pageSize - );
freeBytes = chunkSize;
assert maxOrder < : "maxOrder should be < 30, but is: " + maxOrder;
maxSubpageAllocs = << maxOrder;
// Generate the memory map.节点数量为4096
memoryMap = new byte[maxSubpageAllocs << ];
//也是4096 个节点
depthMap = new byte[memoryMap.length];
int memoryMapIndex = ;
//d 相当于一个深度, 赋值的内容代表当前节点的深度
for (int d = ; d <= maxOrder; ++ d) { // move down the tree one level at a time
int depth = << d;
for (int p = ; p < depth; ++ p) {
// in each level traverse left to right and set value to the depth of subtree
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}
subpages = newSubpageArray(maxSubpageAllocs);
}
首先将参数传入的值进行赋值this.memory = memory 就是将参数中创建的堆外内存进行保存, 就是chunk 所指向的那块连续的内存, 在这个chunk 中所分配的ByteBuf, 都会在这块内存中进行读写。我们重点关注memoryMap = new byte[maxSubpageAllocs << 1] 和depthMap = new byte[memoryMap.length]这两步:首先看memoryMap = new byte[maxSubpageAllocs << 1];这里初始化了一个字节数组memoryMap, 大小为maxSubpageAllocs << 1, 也就是4096;depthMap = new byte[memoryMap.length] 同样也是初始化了一个字节数组, 大小为memoryMap 的大小, 也就是4096。继续往下分析之前, 我们看chunk 的一个层级关系。
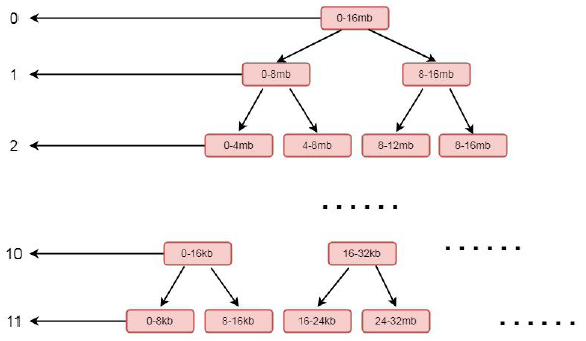
这是一个二叉树的结构, 左侧的数字代表层级, 右侧代表一块连续的内存, 每个父节点下又拆分成多个子节点, 最顶层表示的内存范围为0-16MB, 其又下分为两层, 范围为0-8MB, 8-16MB, 以此类推, 最后到11 层, 以8k 的大小划分, 也就是一个page 的大小。如果我们分配一个8mb 的缓冲区, 则会将第二层的第一个节点, 也就是0-8 这个连续的内存进行分配, 分配完成之后,会将这个节点设置为不可用。结合上面的图, 我们再看构造方法中的for 循环:
for (int d = ; d <= maxOrder; ++ d) { // move down the tree one level at a time
int depth = << d;
for (int p = ; p < depth; ++ p) {
// in each level traverse left to right and set value to the depth of subtree
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}
实际上这个for 循环就是将上面的结构包装成一个字节数组memoryMap, 外层循环用于控制层数, 内层循环用于控制里面每层的节点, 这里经过循环之后, memoryMap 和depthMap 内容为以下表现形式:[0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4...........]这里注意一下, 因为程序中数组的下标是从1 开始设置的, 所以第零个节点元素为默认值0。这里数字代表层级, 同时也代表了当前层级的节点, 相同的数字个数就是这一层级的节点数。其中0 为2 个(因为这里分配时下标是从1 开始的, 所以第0 个位置是默认值0, 实际上第零层元素只有一个, 就是头结点), 1 为2 个, 2 为4 个, 3 为8 个, 4 为16 个, n 为2 的n 次方个, 直到11, 也就是11 有2 的11 次方个。我们再回到PoolArena 的allocateNormal()方法继续来看 long handle = c.allocate(normCapacity) 这步,跟到allocate(normCapacity)中:
long allocate(int normCapacity) {
if ((normCapacity & subpageOverflowMask) != ) { // >= pageSize
return allocateRun(normCapacity);
} else {
return allocateSubpage(normCapacity);
}
}
如果分配是以page 为单位, 则走到allocateRun(normCapacity)方法中, 跟进去:
private long allocateRun(int normCapacity) {
int d = maxOrder - (log2(normCapacity) - pageShifts);
int id = allocateNode(d);
if (id < ) {
return id;
}
freeBytes -= runLength(id);
return id;
}
int d = maxOrder - (log2(normCapacity) - pageShifts) 表示根据normCapacity 计算出第几层;int id = allocateNode(d) 表示根据层级关系, 去分配一个节点, 其中id 代表memoryMap 中的下标。我们跟到allocateNode()方法中:
private int allocateNode(int d) {
//下标初始值为1
int id = ;
//代表当前层级第一个节点的初始下标
int initial = - ( << d);
//获取第一个节点的值
byte val = value(id);
//如果值大于层级, 说明chunk 不可用
if (val > d) {
return -;
}//当前下标对应的节点值如果小于层级, 或者当前下标小于层级的初始下标
while (val < d || (id & initial) == ) {
//当前下标乘以2, 代表下当前节点的子节点的起始位置
id <<= ;
//获得id 位置的值
val = value(id);
//如果当前节点值大于层数(节点不可用)
if (val > d) {
//id 为偶数则+1, id 为奇数则-1(拿的是其兄弟节点)
id ^= ;
//获取id 的值
val = value(id);
}
}
byte value = value(id);
assert value == d && (id & initial) == << d : String.format("val = %d, id & initial = %d, d = %d",
value, id & initial, d);
//将找到的节点设置为不可用
setValue(id, unusable);
//逐层往上标记被使用
updateParentsAlloc(id);
return id;
}
这里是实际上是从第一个节点往下找, 找到层级为d 未被使用的节点, 我们可以通过注释体会其逻辑。找到相关节点后通过setValue 将当前节点设置为不可用, 其中id 是当前节点的下标, unusable 代表一个不可用的值, 这里是12, 因为我们的层级只有12 层, 所以设置为12 之后就相当于标记不可用。设置成不可用之后, 通过updateParentsAlloc(id)逐层设置为被使用。我们跟进updateParentsAlloc()方法:
private void updateParentsAlloc(int id) {
while (id > ) {
//取到当前节点的父节点的id
int parentId = id >>> ;
//获取当前节点的值
byte val1 = value(id);
//找到当前节点的兄弟节点
byte val2 = value(id ^ );
//如果当前节点值小于兄弟节点, 则保存当前节点值到val, 否则, 保存兄弟节点值到val
//如果当前节点是不可用, 则当前节点值是12, 大于兄弟节点的值, 所以这里将兄弟节点的值进行保存
byte val = val1 < val2 ? val1 : val2;
//将val 的值设置为父节点下标所对应的值
setValue(parentId, val);
//id 设置为父节点id, 继续循环
id = parentId;
}
}
这里其实是将循环将兄弟节点的值替换成父节点的值, 我们可以通过注释仔细的进行逻辑分析。如果实在理解有困难,我通过画图帮助大家理解,简单起见, 我们这里只设置三层:
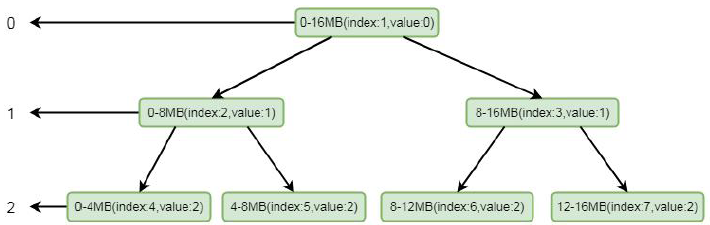
我们模拟其分配场景, 假设只有三层, 其中index 代表数组memoryMap 的下标, value 代表其值, memoryMap 中的值就为[0, 0, 1, 1, 2, 2, 2, 2]。我们要分配一个4MB 的byteBuf, 在我们调用allocateNode(int d)中传入的d 是2, 也就是第二层。根据我们上面分分析的逻辑这里会找到第二层的第一个节点, 也就是0-4mb 这个节点, 找到之后将其设置为不可用, 这样memoryMap 中的值就为[0, 0, 1, 1, 12, 2, 2, 2],二叉树的结构就会变为:
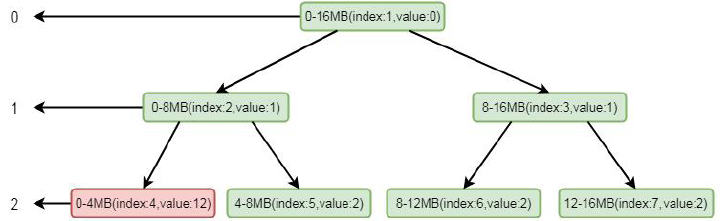
注意标红部分, 将index 为4 的节点设置为了不可用。将这个节点设置为不可用之后, 则会将进行向上设置不可用, 循环将兄弟节点数值较小的节点替换到父节点, 也就是将index 为2 的节点的值替换成了index 的为5 的节点的值, 这样数组的值就会变为[0, 1, 2, 1, 12, 2, 2, 2],二叉树的结构变为:
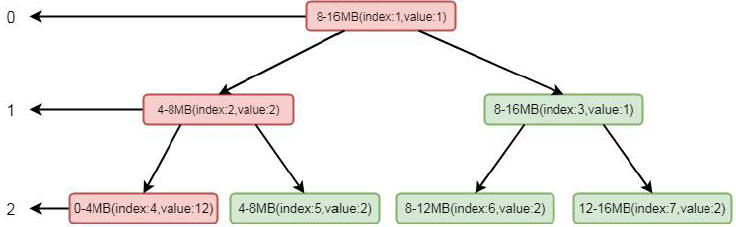
这里节点标红仅仅代表节点变化, 并不是当前节点为不可用状态, 真正不可用状态的判断依据是value 值为12。
这样, 如果再次分配一个4MB 内存的ByteBuf, 根据其逻辑, 则会找到第二层的第二个节点, 也就是4-8MB。再根据我们的逻辑, 通过向上设置不可用, index 为2 就会设置成不可用状态, 将value 的值设置为12, 数组数值变为[0, 1, 12, 1, 12,12, 2, 2]二叉树如下图所示:
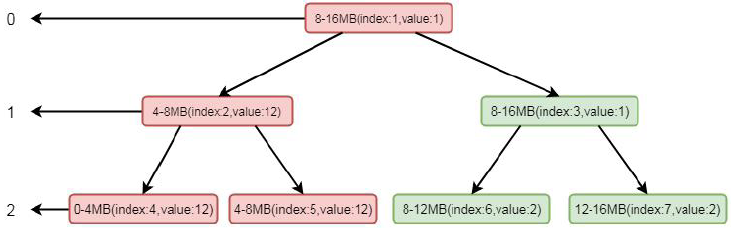
这样我们看到, 通过分配两个4mb 的byteBuf 之后, 当前节点和其父节点都会设置成不可用状态, 当index=2 的节点设置为不可用之后, 将不会再找这个节点下的子节点。以此类推, 直到所有的内存分配完毕的时候, index 为1 的节点,也会变成不可用状态, 这样所有的page 就分配完毕, chunk 中再无可用节点。现在再回到PoolArena 的allocateNormal()方法:
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
//首先在原来的chunk 上进行内存分配(1)
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
++allocationsNormal;
return;
}
//创建chunk 进行内存分配(2)
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
++allocationsNormal;
assert handle > ;
//初始化byteBuf(3)
c.initBuf(buf, handle, reqCapacity);
qInit.add(c);
}
通过以上逻辑我们知道, long handle = c.allocate(normCapacity)这一步, 其实返回的就是memoryMap 的一个下标,通过这个下标, 我们能唯一的定位一块内存。继续往下跟, 通过c.initBuf(buf, handle, reqCapacity)初始化ByteBuf 之后,通过qInit.add(c)将新创建的chunk 添加到chunkList 中,我们跟到initBuf 方法中去:
void initBuf(PooledByteBuf<T> buf, long handle, int reqCapacity) {
int memoryMapIdx = memoryMapIdx(handle);
int bitmapIdx = bitmapIdx(handle);
if (bitmapIdx == ) {
byte val = value(memoryMapIdx);
assert val == unusable : String.valueOf(val);
buf.init(this, handle, runOffset(memoryMapIdx), reqCapacity, runLength(memoryMapIdx),
arena.parent.threadCache());
} else {
initBufWithSubpage(buf, handle, bitmapIdx, reqCapacity);
}
}
从上面代码中,看出通过memoryMapIdx(handle)找到memoryMap 的下标, 其实就是handle 的值。bitmapIdx(handle)是有关subPage 中使用到的逻辑, 如果是page 级别的分配, 这里只返回0, 所以进入到if 块中。if 中首先断言当前节点是不是不可用状态, 然后通过init 方法进行初始化。其中runOffset(memoryMapIdx)表示偏移量, 偏移量相当于分配给缓冲区的这块内存相对于chunk 中申请的内存的首地址偏移了多少。参数runLength(memoryMapIdx), 表示根据下标获取可分配的最大长度。我们跟到init()方法中, 这里会走到PooledByteBuf 的init()方法:
void init(PoolChunk<T> chunk, long handle, int offset, int length, int maxLength, PoolThreadCache cache) {
//初始化
assert handle >= ;
assert chunk != null;
//在哪一块内存上进行分配的
this.chunk = chunk;
//这一块内存上的哪一块连续内存
this.handle = handle;
memory = chunk.memory;
this.offset = offset;
this.length = length;
this.maxLength = maxLength;
tmpNioBuf = null;
this.cache = cache;
}
这段代码又是我们熟悉的部分, 将属性进行了初始化。以上就是完整的DirectUnsafePooledByteBuf 在Page 级别的完整分配的流程, 逻辑也是非常的复杂, 想真正的掌握熟练, 还需要小伙伴们多下功夫进行调试和剖析。
Netty之Page级别的内存分配的更多相关文章
- Netty源码分析第5章(ByteBuf)---->第7节: page级别的内存分配
Netty源码分析第五章: ByteBuf 第六节: page级别的内存分配 前面小节我们剖析过命中缓存的内存分配逻辑, 前提是如果缓存中有数据, 那么缓存中没有数据, netty是如何开辟一块内存进 ...
- Netty之SubPage级别的内存分配
SubPage 级别的内存分配: 通过之前的学习我们知道, 如果我们分配一个缓冲区大小远小于page, 则直接在一个page 上进行分配则会造成内存浪费, 所以需要将page 继续进行切分成多个子块进 ...
- Netty源码分析第5章(ByteBuf)---->第8节: subPage级别的内存分配
Netty源码分析第五章: ByteBuf 第八节: subPage级别的内存分配 上一小节我们剖析了page级别的内存分配逻辑, 这一小节带大家剖析有关subPage级别的内存分配 通过之前的学习我 ...
- Netty源码—五、内存分配概述
Netty中的内存管理应该是借鉴了FreeBSD内存管理的思想--jemalloc.Netty内存分配过程中总体遵循以下规则: 优先从缓存中分配 如果缓存中没有的话,从内存池看看有没有剩余可用的 如果 ...
- Netty 中的内存分配浅析-数据容器
本篇接续前一篇继续讲 Netty 中的内存分配.上一篇 先简单做一下回顾: Netty 为了更高效的管理内存,自己实现了一套内存管理的逻辑,借鉴 jemalloc 的思想实现了一套池化内存管理的思路: ...
- Netty 中的内存分配浅析
Netty 出发点作为一款高性能的 RPC 框架必然涉及到频繁的内存分配销毁操作,如果是在堆上分配内存空间将会触发频繁的GC,JDK 在1.4之后提供的 NIO 也已经提供了直接直接分配堆外内存空间的 ...
- Netty - 3 内存分配
https://www.cnblogs.com/gaoxing/p/4253833.html netty的buffer引入了缓冲池.该缓冲池实现使用了jemalloc的思想 内存分配是面向虚拟内存的而 ...
- Netty源码—六、tiny、small内存分配
tiny内存分配 tiny内存分配流程: 如果申请的是tiny类型,会先从tiny缓存中尝试分配,如果缓存分配成功则返回 否则从tinySubpagePools中尝试分配 如果上面没有分配成功则使用a ...
- Netty内存管理器ByteBufAllocator及内存分配
ByteBufAllocator 内存管理器: Netty 中内存分配有一个最顶层的抽象就是ByteBufAllocator,负责分配所有ByteBuf 类型的内存.功能其实不是很多,主要有以下几个重 ...
随机推荐
- 浏览器是怎样工作的(一):基础知识 转载http://ued.ctrip.com/blog/how-browsers-work-i-basic-knowledge.html
译注: 前两天看到一篇不错的英文文章,叫做 How browsers work,该文概要的介绍了浏览器从头到尾的工作机制,包括HTML等的解析,DOM树的生成,节点与CSS的渲染等等,对于想学习浏览器 ...
- ListView鼠标拖
private Point Position = new Point(0, 0); private void treeFileView_ItemDrag(object sender, ItemDrag ...
- 基于Xilinx Kintex-7 FPGA K7 XC7K325T PCIeX8 四路光纤卡
基于Xilinx Kintex-7 FPGA K7 XC7K325T PCIeX8 四路光纤卡 1. 板卡概述 板卡主芯片采用Xilinx公司的XC7K325T-2FFG900 FPGA,pin_ ...
- CentOS 7系统安装nginx+php
安装介绍1.系统环境CentOS7 2.nginx版本1.12 3.PHP版本7.2 下载地址 4.MySQL版本5.7 安装nginx添加centos7的 nginx yum源 然后执行安装 sud ...
- 1.Linux安装redis
Linux安装redis 操作系统是Centos7 1.下载压缩包 2.解压 3.编译 4.启动redis 5.设置redis.conf和防火墙端口开放,外网可以访问 1.下载压缩包 下载地址:htt ...
- gitignore 忽略文件
*.project*.prefs*.classpath*.gitignore#ignore thumbnails created by windowsThumbs.db#Ignore files bu ...
- frugally-deep: Header-only library for using Keras models in C++
// Convenience wrapper around predict for models with // single tensor outputs of shape (1, 1, 1), / ...
- BZOJ 3675: [Apio2014]序列分割 动态规划 + 斜率优化 + 卡精度
Code: #include<bits/stdc++.h> #define N 100006 #define M 205 #define ll long long #define setI ...
- 洛谷 P4300 BZOJ 1266 [AHOI2006]上学路线route
题目描述 可可和卡卡家住合肥市的东郊,每天上学他们都要转车多次才能到达市区西端的学校.直到有一天他们两人参加了学校的信息学奥林匹克竞赛小组才发现每天上学的乘车路线不一定是最优的. 可可:“很可能我们在 ...
- C# WinFrom 发送邮件
C# WinFrom 发送邮件 C# Winforms 发送邮件 发送邮件时用到以下来个命名空间: using System.Net; using System.Net.Mail; 发送邮件的发信人邮 ...