ELK(elasticsearch+logstash+kibana)入门到熟练-从0开始搭建日志分析系统教程
#此文篇幅较长,涵盖了elk从搭建到运行的知识,看此文档,你需要会点linux,还要看得懂点正则表达式,还有一个聪明的大脑,如果你没有漏掉步骤的话,还搭建不起来elk,你来打我。 ELK使用elasticsearch+logstash+kibana三个开源插件实现,logstash负责收取日志信息,并将收取到的日志信息进行过滤,格式化,后存储到elasticserch中,kibana负责从elasticsearch中读取数据,并将数据以图形化的方式展现出来
解决了在机器众多,日志数据难以统计的问题,使用elk,在多机器环境中,只需要在每台机器上定义好日志格式,统一的logstash配置,让logstash获取日志,并存储到单台es或者es集群中,kibana读取数据即可。
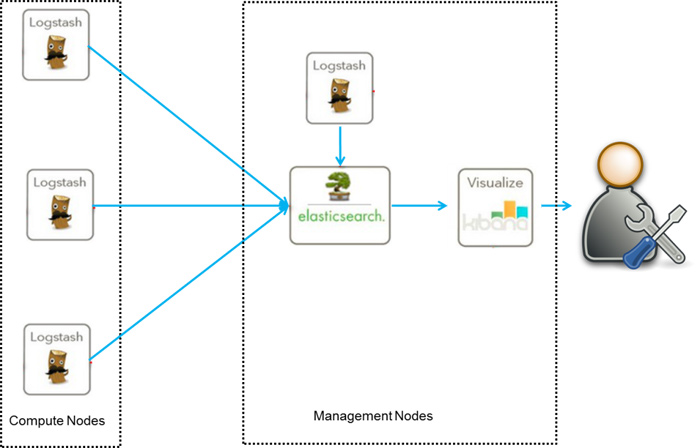
当前环境:
host1 192.168.100.2 es,kibana
host2 192.168.100.3 logstash
elasticsearch介绍安装等插件安装:https://www.cnblogs.com/xiaodai12138/p/10084465.html
logstash: 一款日志收集工具,主要功能是将日志收集出来,并可以对收集到的日志进行一些格式化输出等类似的操作后输出到某些地方,总体分为三大块,Input Filter Output 以下为处理顺序以及各个块的介绍 Input:定义从哪儿获取日志数据,支持从很多地方获取,如在文件中读取日志数据,在redis中读取存储的日志数据,tcp连接中,队列中等... || V filter:对收到的日志数据进行操作,可删除字段,更改名称,正则匹配某些需要的数据并格式化的功能等 || V output:将经过filter处理后的数据输出(发送)到es中存储,发送到当前终端,发送到redis,队列中等
kibana:基于web的图形界面,在elasticsearch中搜索数据,并以图形化报表的形式展现出来,支持自定义报表,根据存储在es中的某个字段做过滤
logstash (logstash-6.5.1.tar.gz)下载安装:
链接:https://pan.baidu.com/s/1ndBZOs7RLoTuevIKI1GQPQ
提取码:dn2i
下载好tar包后进行解压操作
[root@host2 [::]/usr/src]#tar xf logstash-6.5..tar.gz
进入解压目录后配置主配置文件,只需要定义并创建一项即可,logstash的数据存放目录。
[root@host2 [::]/usr/src]#cd logstash-6.5.
[root@host2 [::]/usr/src/logstash-6.5.]#cd config/
[root@host2 [::]/usr/src/logstash-6.5./config]#cat logstash.yml |grep -v ^#
path.data: /logstash-data
[root@host2 [::]/usr/src/logstash-6.5./config]#mkdir /logstash-data
将bin下logstash命令执行文件做一个链接,链接到/bin下,方便我们执行这个命令。
[root@host2 [::]/usr/src/logstash-6.5.]#ln -s /usr/src/logstash-6.5./bin/logstash /bin/
logstash每次进行拉取日志,对日志进行配置,输出日志的这个操作,都需要定义在一个单独的文件中,我们可以单独创建一个存放这个文件的目录,我是在logstash根目录进行创建的。
[root@host2 [::]/usr/src/logstash-6.5./conf]#pwd
/usr/src/logstash-6.5./conf
进入conf目录,新建一个文件,名称自定,配置第一个收取并输出的程序。
#input是一个块,里面有不同的方式,来定义从哪儿取数据,output同样,有不同的方式输出数据
#这里定义的stdin{}指的是标准输入,运行这个文件后,直接在终端上输入,即视为输入的数据,logstash将进行获取操作。
#从标准输入获取到数据后(如果有filter块就会经过filter块过滤,如果没有,就不过滤),触发output操作,output中定义的方式时标注输出,意味着将数据标准输出到终端。
#整个文件的意思是,在logstash终端中输入的数据,将会在logstash终端中打印出来
[root@host2 [::]/usr/src/logstash-6.5.]#cd conf
[root@host2 [::]/usr/src/logstash-6.5./conf]#cat test.conf
input{
stdin{}
} output{
stdout{ codec => "rubydebug"} }
接下来试一下运行这个文件的效果(运行文件时,logstash需要规划一些东西,所以速度比较慢,等个2分钟,不要ctrl+c了)
#logstash -f 运行指定文件 牢记此命令,并且同时只能运行一个文件
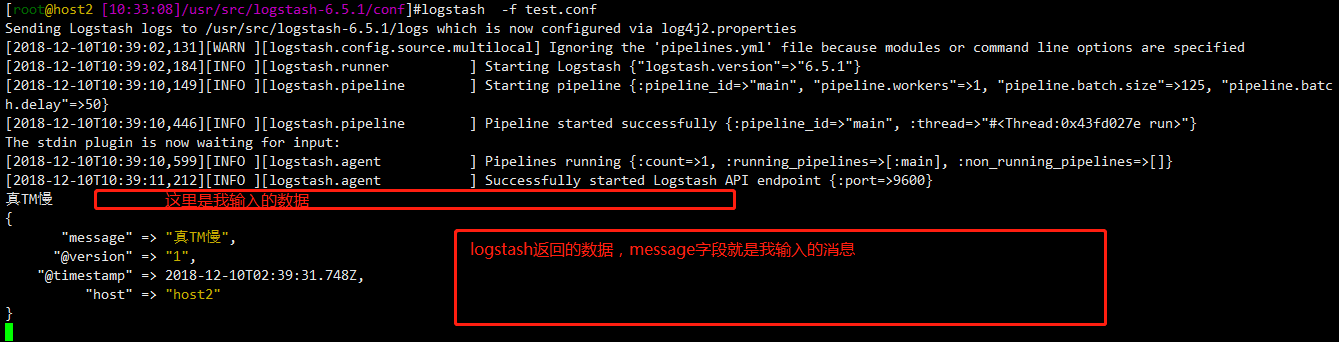
logstash
在部署了logstash机器上实验即可,此处讲解如何使用logstash,到讲解kibana时,你需要结合这里学的,配合使用
INPUT
对input块里面的方式进行讲解(收取数据的方式),output保持标准输出(输出到屏幕)的方式进行实验。
file》 从文件中读取数据,当文件中新增加了数据后,会触发input,将其读取过来,并进行一系列操作。
[root@host2 [::]/usr/src/logstash-6.5./conf]#cat test.conf
input{
file{
path => "/var/log/nginx/access.log" #日志文件路径
type => "nginx" #定义一个type变量,数据为nginx,后期可以在output中通过这个type变量判断是哪儿的数据,并区别处理
start_position => "beginning" #从文件开始处读写
}
}
output{
stdout{ codec => "rubydebug"}
}
运行
[root@host2 [::]/usr/src/logstash-6.5./conf]#logstash -f test.conf
往/var/log/nginx/access.log文件中写入一行数据(模拟新增加了一行日志)
[root@host2 [::]/var/log/nginx]#echo
'187.101.241.167 - - [10/Dec/2018:13:54:05 +0800] "GET / HTTP/1.1" 200 43 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/601.7.7 (KHTML, like Gecko) Version/9.1.2 Safari/601.7.7"'
>> /var/log/nginx/access.log
插入日志后,有新的数据,触发了logstash的input,input开始收集数据,并输出到终端,因为我们定义是输出到终端,不是输出到其他地方。
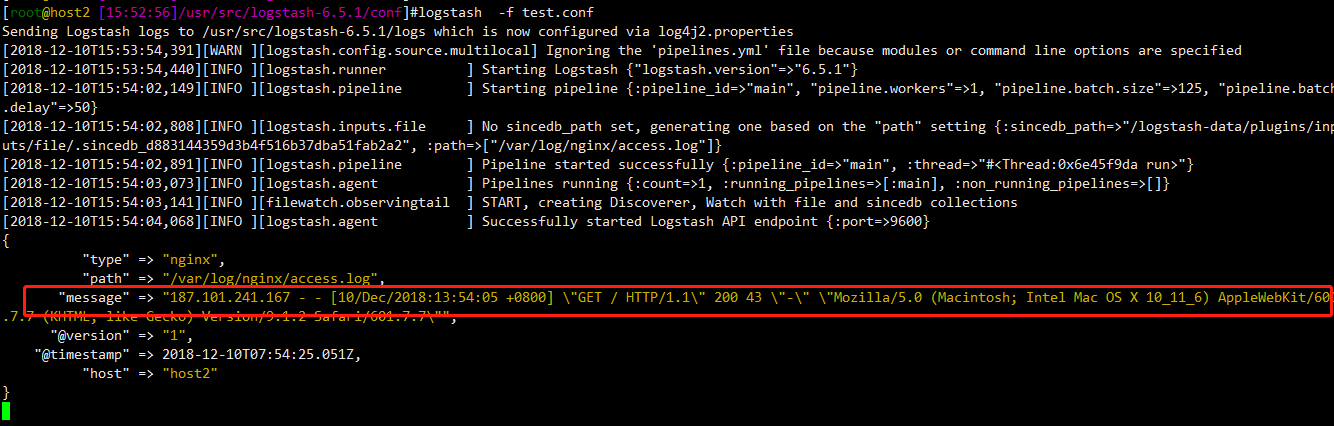
file模块进阶
logstash接收数据是一行一行接收的,那么你可能遇见过,有些java项目的日志数据,是这样的:
如果一行一行的读取数据,那么logstash收到的数据,是这样的
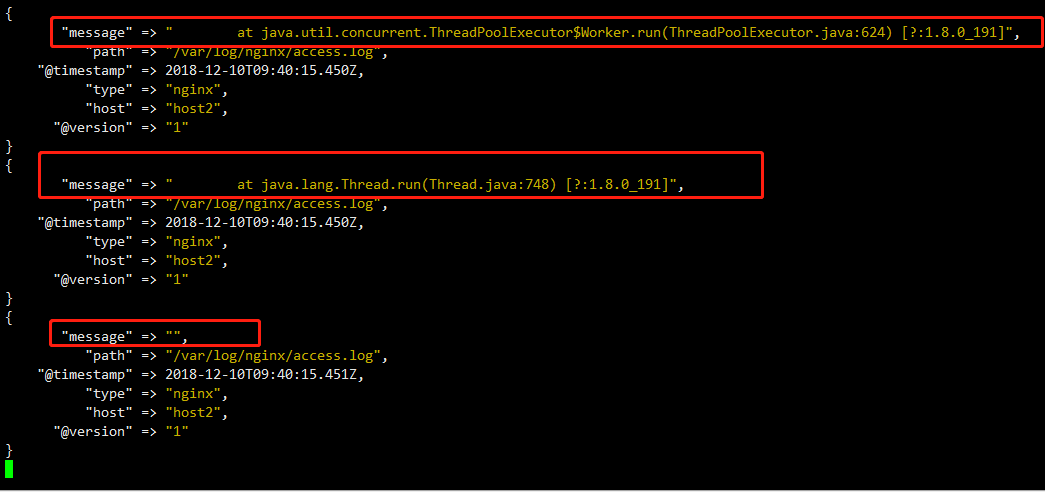
这谁看得懂,一行一行的,有没有办法把他连起来呢,你是否有注意到,正常的一段应该是时间开头后面是消息,下图中第一行是[时间]开头,视为第一行,第二行就不是[时间]开头,他不是独立的一段提示,而是上条提示的延续,那么怎么让这些凌乱数据规划好后再输出呢。
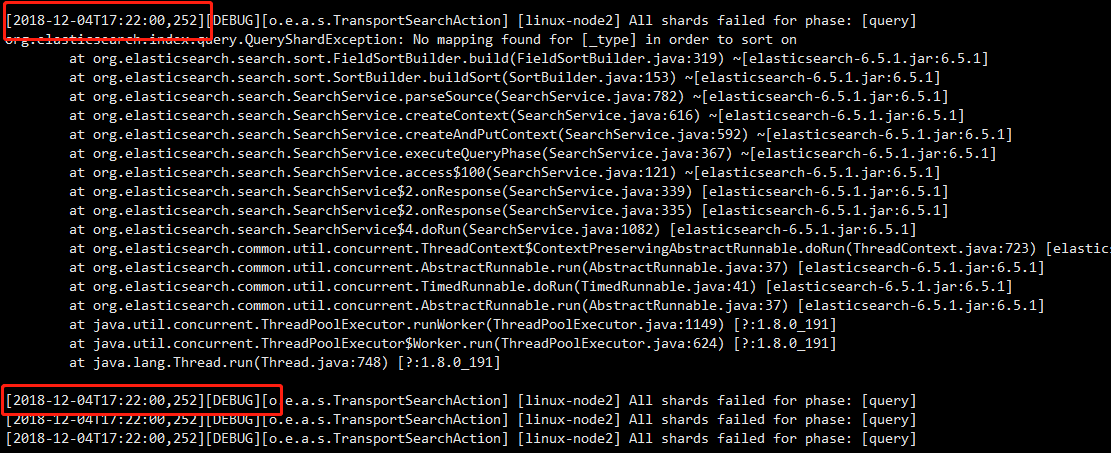
对input快中的file方法中的配置更改即可。
input{
file{
path => "/usr/local/elasticsearch/logs/test.log"
type => "es-log"
start_position => "beginning"
codec => multiline { #多行配置
pattern => "^\[" #匹配开头为[的行
negate => true
what => "previous" #开头不是[的行是上一个开头是[的行的延续通知,logstash会将他们连起来
}
}
output{
stdout{ codec => "rubydebug"}
}
syslog》配合linux,/etc/rsyslog.conf文件中的配置使用,文件中配置将系统日志发送到某个ip的某个地址,logstash的syslog模块就用与此,监听本机ip的某个端口收集传输过来的系统日志。
#此模块的实际使用方法可以有区别,学习了file模块,了解logstash是从本机的文件中读取数据的,而syslog是监听一个端口,由对方发送数据过来,那么,你可以让logstash监听在某个端口,然后接收所有机器的系统日志,再选择输出方式~(输出方式在本文中下方会讲)
在/etc/rsyslog.conf中指定接收系统日志信息的地址和端口,(因为是实验环境,我这里指向的是本机的ip地址,系统日志发向本机的某个端口)
*.* @@IP:Port
[root@host2 [15:40:55]/usr/src/logstash-6.5.1/conf/backup]#cat /etc/rsyslog.conf |grep :514$
*.* @@192.168.100.3:514
修改配置后配置一个文件定义从本机的端口获取日志数据。
[root@host2 [16:01:11]/usr/src/logstash-6.5.1/conf]#cat test2.conf
input {
syslog{
port => "514"
host => "192.168.100.3" #监听本机ip的514端口,用于接收日志数据,再说一次。type的定义只是起一个标识作用,
type => "syslog"
}
} output{
stdout{ codec => "rubydebug"} }
运行此文件,并手动触发写入系统日志,看logstash是否可以正常接收数据。
运行后监听了本机514端口

手动触发写入系统日志
[root@host2 [16:12:01]~]#logger HelloWorld
查看logstash
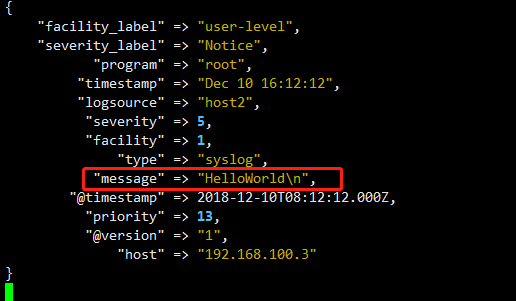
tcp》syslog日志也是通过tcp协议接收的日志数据,但是那些数据都是系统定义好了格式,然后发送到logstash中,如果某种情况,你自己建立了一个应用,然后定义了些日志的格式,需要用logstash收集后处理呢,那么此模块可以帮到你。
监听本机6666端口
input{
tcp{
port => "6666"
host => "192.168.100.3"
type => "tcp-log"
}
}
output{
stdout{ codec => "rubydebug"}
}
启动后传输数据到6666端口,看logstash能否获取到。
下方命令作用是使用tcp协议发送Hello World 至192.168.100.3的6666端口
[root@host2 [16:27:37]/usr/src/logstash-6.5.1/conf]#echo "Hello World" > /dev/tcp/192.168.100.3/6666
查看结果
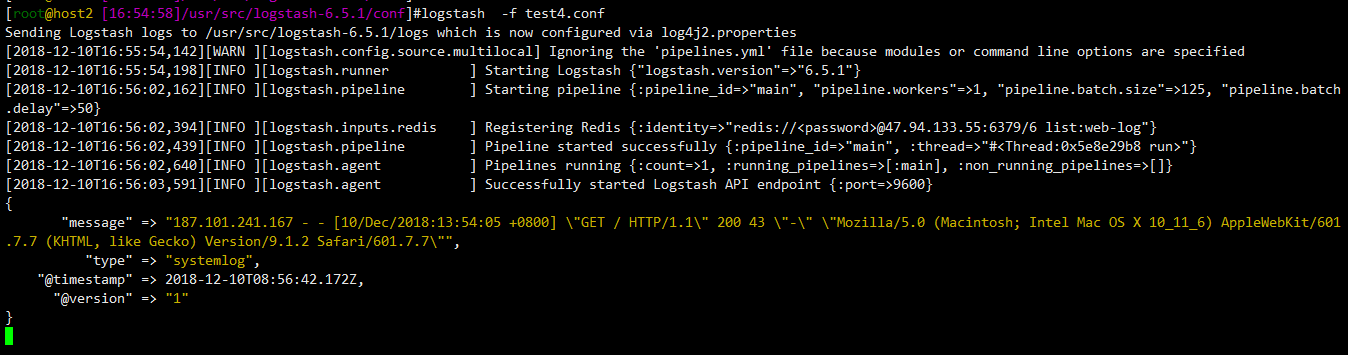
redis》从redis中读取数据
在redis中以列表形式写入如下数据

新建文件,定义从redis中拉取
[root@host2 [::]/usr/src/logstash-6.5./conf]# cat test4.conf
input{ redis {
type => "systemlog"
host => "47.94.133.111"
password => 'nihao123A'
port => ""
db => ""
data_type => "list"
key => "web-log"
codec=> "plain" #如果不加此选项,从redis中读取数据后,会做json处理,而如果redis中存储的字符串不能被json序列化就会报错
} } output{
stdout{ codec => "rubydebug"} }
查看结果,刚启动就拉取上了,拉取后,redis上就不存在这条数据了,如果有新的数据,logstash又会拉取
output
通过上面对input块方法的说明,input通过各种方法收取数据后,交给filter处理,如果没有filter块,那么就交给output处理,output指定输出位置。
经过logstash的数据获取并处理,最终存入es中的可能是
例子1-
{
message=>"name:xiaoming,age:22,,gender:man"
}
或者
例子1-
{
message=>"name:xiaoming,age:22,gender:man"
name=>xiaoming
age=>
gender=>man
}
kibanna可以在es中查询,并根据字段进行过滤,统计个数,他可以统计例子1-2中的name字段,找到值是xiaoming的数据有多少条,但是无法根据例子1-1中的message来匹配name这一个字段,
因为message字段存入es时,视为一个整体的字段,字段名称是message,所以我们要做的,就是让logstash存入es的数据,格式化成一个key=>values的格式,区分取来每个段的作用,
实现例子1-2的效果,让kibana可以根据key或者values进行匹配。
#为什么要kibana识别es中的存储的字段,什么意思?
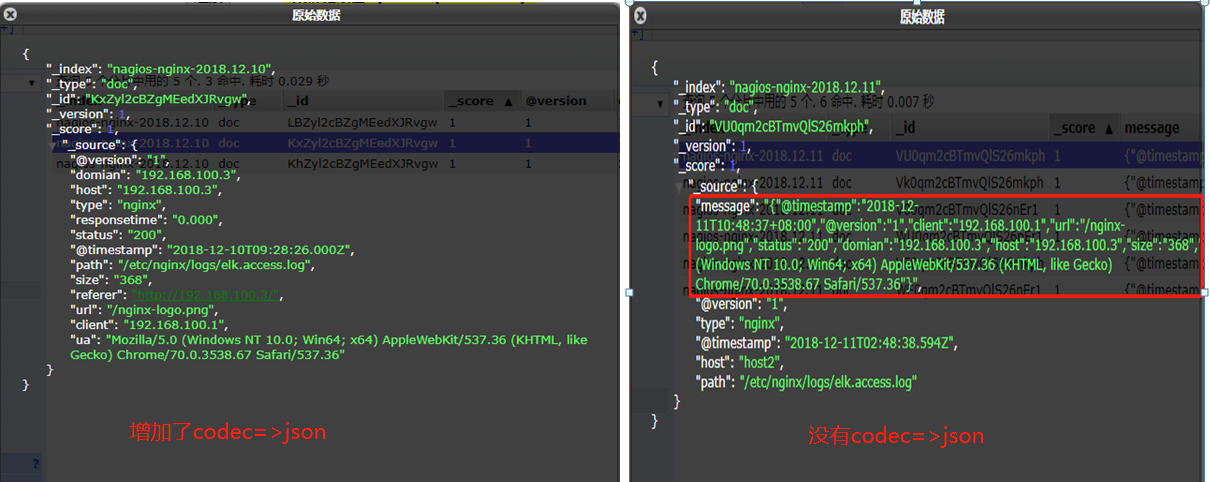
看下图一,下图二,两个图中的message完全相同,但是图二的参数要比图一多,图二中的参数大多是自定义的(从messages消息中取出来的),如client_ip,status等,kibana可以识别status并且可以对这些字段进行过滤,如在kibana中查看某个范围的status为404的日志数量等


为了能够让kibana能够更好的根据字段进行匹配,日志数据可以以json形式存储,然后放入es中但是如果logstash读取后不以json格式存入es内,那 kibana就无法通过json反序列化,根据字段做匹配,解决方法是在input中如file中添加选项:codec =>"json"
如果是自己开发的应用,存储的日志数据也建议用json来存储,直接使用json反序列化即可得到数据,可以省去很多操作,如果不用json存储,只能通过其他方法把一段日志过滤成key=>values的格式,比较麻烦,下面filter会讲述。
#nginx日志以json格式存储:
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domian":"$host",'
'"host":"$server_addr",'
'"size":"$body_bytes_sent",'
'"responsetime":"$request_time",'
'"referer":"$http_referer",'
'"ua":"$http_user_agent"'
'}';
access_log /etc/nginx/logs/elk.access.log json;
#apache以json格式存储:
LogFormat "{ \
\"@timestamp\": \"%{%Y-%m-%dT%H:%M:%S%z}t\", \
\"@version\": \"1\", \
\"tags\":[\"apache\"], \
\"message\": \"%h %l %u %t \\\"%r\\\" %>s %b\", \
\"clientip\": \"%a\", \
\"duration\": %D, \
\"status\": %>s, \
\"request\": \"%U%q\", \
\"urlpath\": \"%U\", \
\"urlquery\": \"%q\", \
\"bytes\": %B, \
\"method\": \"%m\", \
\"site\": \"%{Host}i\", \
\"referer\": \"%{Referer}i\", \
\"useragent\": \"%{User-agent}i\" \
}" ls_apache_json
CustomLog logs/access_log.ls_json ls_apache_json
elasticsearch》将收到的数据存储到es中
input{
file{
path => "/etc/nginx/logs/elk.access.log"
type => "nginx"
codec=>json #存入/etc/nginx/logs/elk.access.log文件中的数据是以json的格式存储的,logstash以json方式序列化后交给output处理(存入es中)
start_position => "beginning"
}
}
output{
elasticsearch{
hosts => ["192.168.100.2:9200"] #es连接地址
index => "nagios-nginx-%{+YYYY.MM.dd}" #定义es索引名称(+YYYY.MM.dd}年月日方式命名)
}
}
启动后测试下,访问nginx,让nginx新增加json格式日志,logstash收到后存入es中,然后在es的head插件中查看是否生成了索引数据。
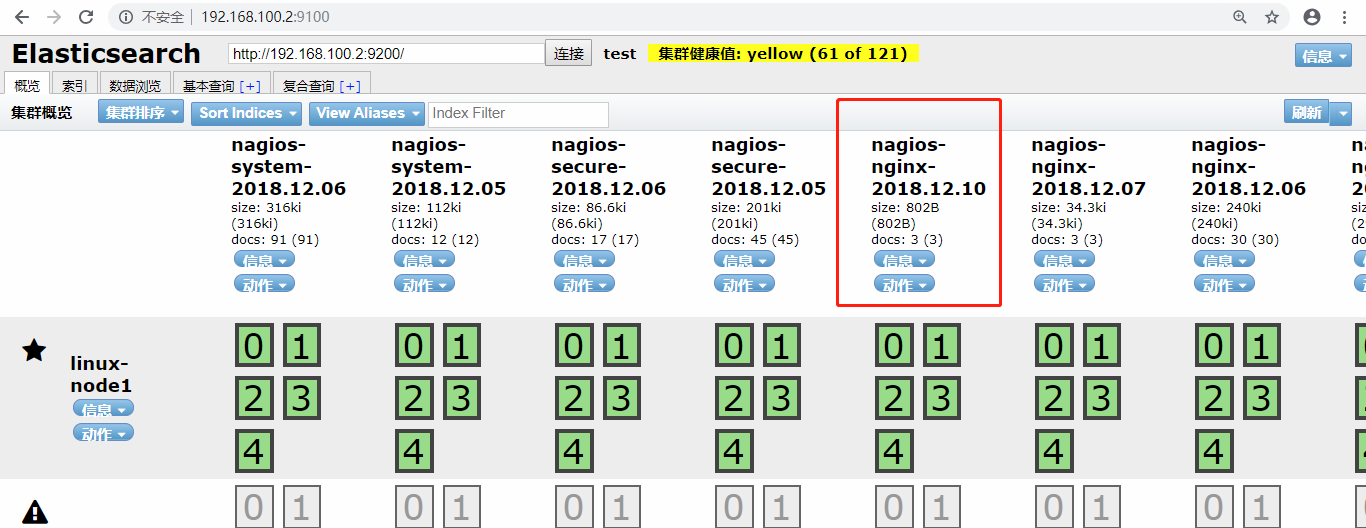
nginx生成的json日志格式如下,如果你不用json格式存储,你想想怎么把这下面的值,如这一段 "client":"192.168.100.1" 让它变成client=>192.168.100.1,想想都麻烦,当然,很多情况下有自定义的日志格式数据,不是用json格式存储的,无法做json序列化,那么就需要用其他方法了(filter过滤中的方法),这没办法。
{"@timestamp":"2018-12-11T10:48:37+08:00","@version":"1","client":"192.168.100.1","url":"/index.html","status":"200","domian":"192.168.100.3","host":"192.168.100.3","size":"3698","responsetime":"0.000","referer":"-","ua":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36"}
redis》将数据输出到redis中去
input{
file{
path => "/etc/nginx/logs/elk.access.log"
type => "nginx"
codec=>json
start_position => "beginning"
}
}
output{
redis {
data_type => "list"
host => "47.94.133.111"
db => "6"
port => "6379"
password => "nihao123A"
key => "web-log"
}
}
以上是常用的收取数据,输出数据的方法,上面只讲了单种方法,但是也可以同时输入多路数据,并区别输出,如下。
input{
syslog{
port => "514"
host => "192.168.100.3"
type => "syslog"
}
file{
path => "/etc/nginx/logs/elk.access.log"
type => "nginx"
codec=>json
start_position => "beginning"
}
}
output{
if [type] == "syslog"{ #根据type变量来判断输出方式
elasticsearch{
hosts => ["192.168.100.2:9200"]
index => "nagios-system-%{+YYYY.MM.dd}"
}
}
if [type] == "nginx"{
elasticsearch{
hosts => ["192.168.100.2:9200"]
index => "nagios-nginx-%{+YYYY.MM.dd}"
}
}
}
filter
提供过滤的功能在input和output之间,经过处理后,再将数据交由output处理
grok》正则表达式在字符串中匹配出自己想要的,并付给一个变量,此模块CPU占用高,且难度较大,需要花时间练习,我给大家准备了练习程序,你们可以尝试下。
%{method:name}
method:正则表达式的名称
name:一个名称,正则表达式匹配到的值赋值给此值。
input {
stdin{}
}
filter{
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }此处是正则表达式
}
}
output{
stdout{ codec => "rubydebug"}
match => { "message" =>""} 固定格式
"%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"正则表达式
现有字符串
55.3.244.1 GET /index.html 15824 0.043
使用上方的文件进行正则表达式匹配之后的结果如下
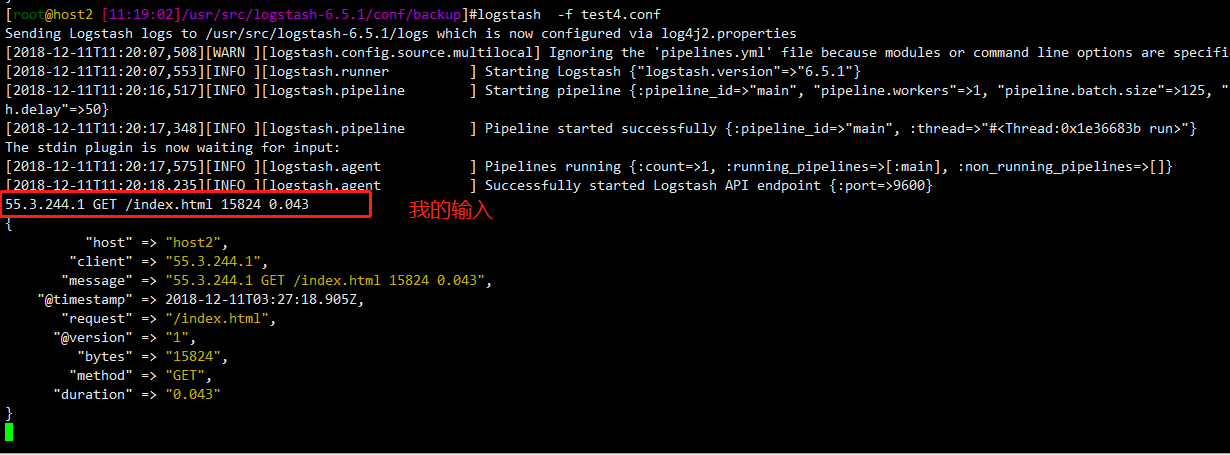 输入的字符串被格式化输出,这是最好的结果,来看看怎么实现的,对应匹配的值如下
输入的字符串被格式化输出,这是最好的结果,来看看怎么实现的,对应匹配的值如下
55.3.244.1 GET /index.html 0.043
"%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"
IP,WORD这类名称,是logstash默认提供的正则表达式,分别用来匹配ip地址,文本文档。。。。
logstash提供的正则表达式规则写在:/usr/src/logstash-6.5.1/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns/ 文件夹下
以如下两个举例子,下方红色的就是我们在文件中指定的正则表达式名称,可以理解为在那个文件中调用这下面的正则,
[root@host2 [::]/usr/src/logstash-6.5./vendor/bundle/jruby/2.3./gems/logstash-patterns-core-4.1./patterns]#cat grok-patterns |grep -E "^IP |^WORD" --color
WORD \b\w+\b 匹配包括下划线在内的任何字字符:[A-Za-z0-9_]
IP (?:%{IPV6}|%{IPV4}) 这个IP正则,引用了IPV4,IPV6正则,总体就是匹配IPv4类ip地址,或则IPv6类ip地址。
我们可以自行定义一个正则表达式,用我们自己的正则匹配,详细理解下其中原理。
在正则表达式目录下新建一个文件,名称随便,添加如下内容。
[root@host2 [::]/usr/src/logstash-6.5./vendor/bundle/jruby/2.3./gems/logstash-patterns-core-4.1./patterns]#cat xiaodai
D_TIME [-]{}\-[-]{}\-[-]{}\/[-]{}\:[-]{}\:[-]{} 匹配时间格式的正则(2018-12-07/15:12:54)
更改文件,重新输入值,并匹配。
input {
stdin{}
}
filter{
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} \[%{D_TIME:time}\]" }
}
}
output{
stdout{ codec => "rubydebug"}
}
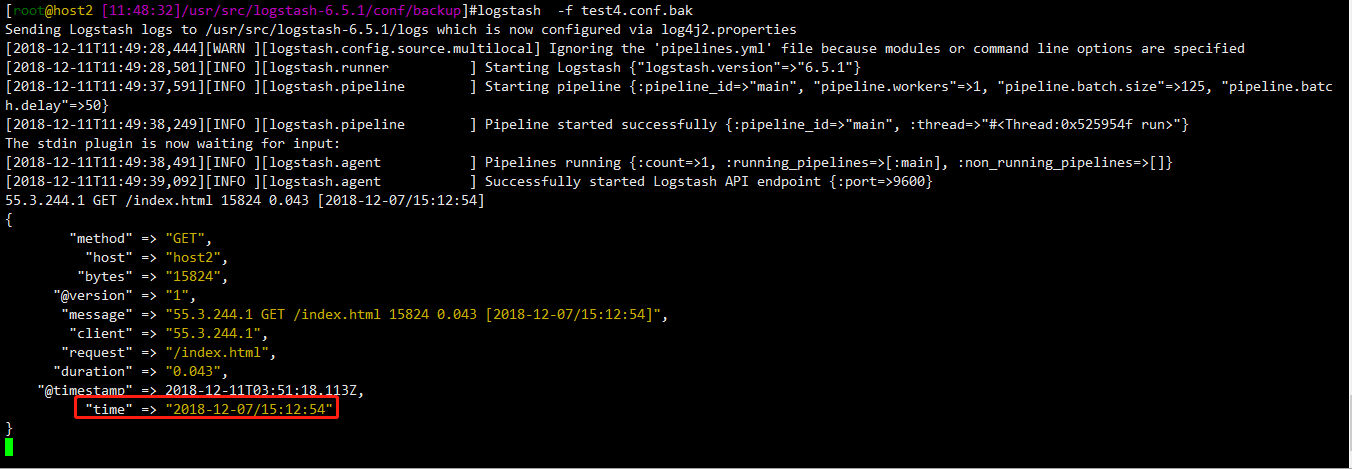
成功匹配了time值,你可能注意到了,我在定义正则表达式时,是这样设置的 \[%{D_TIME:time}\],加了中括号[]并且做了转义
因为我输入的时间也是有[]的,logstash,grok的正则表达式是在文件中设置的(match => { "message" => "正则"}),正则中,除了你需要进行正则匹配的地方,其他的地方要跟字符串中的值一样,否则无法正常匹配到值(这个点坑的我不行了)
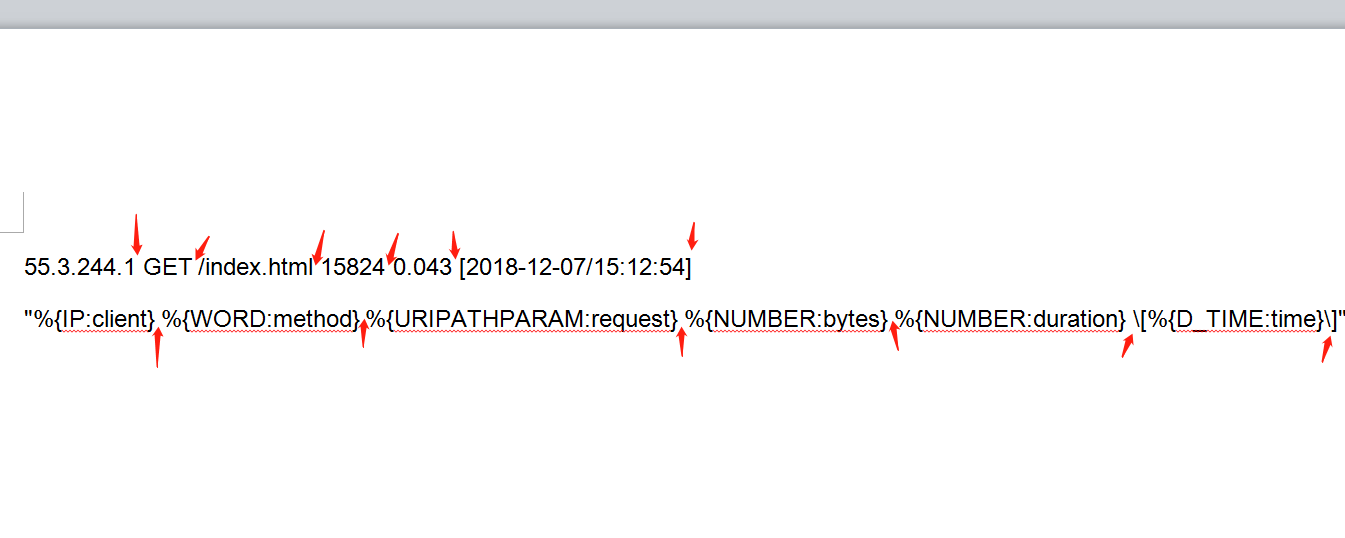
仔细观察图中的日志数据,和我的正则表达式的设置,其中除了我的匹配规则,剩下的空格,中括号,都是跟日志数据相同的,下面试试我多输入几个空格会发生什么还是上面的脚本
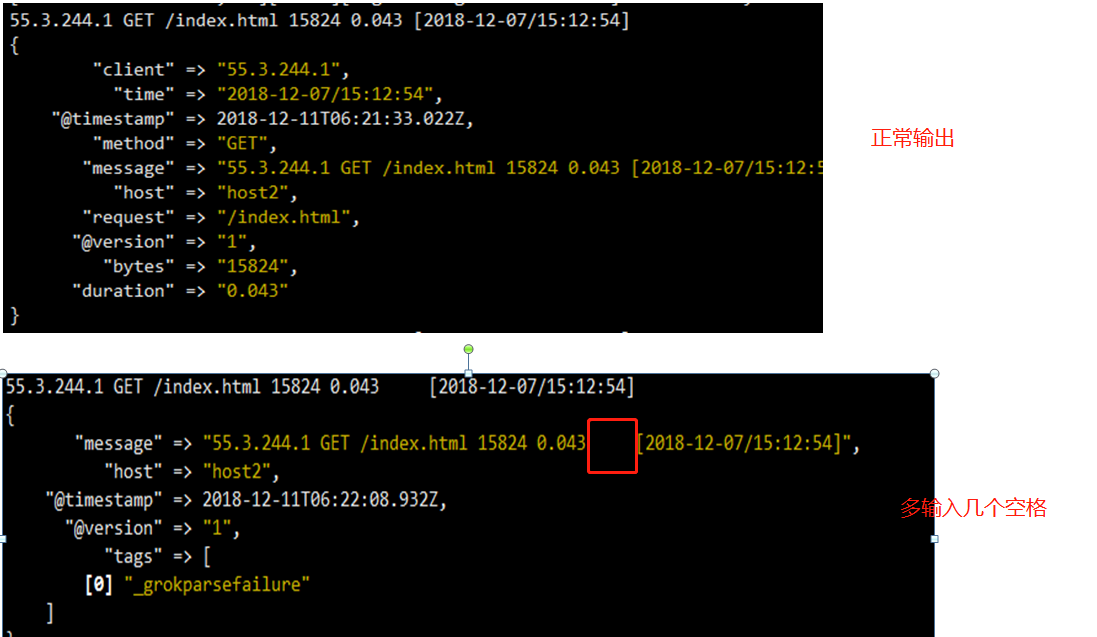
你看出来问题了吗,再说一次,除了要被匹配的值,其他固定的值要跟源数据中相同。(如果要被匹配的值会出现变更情况,那就需要发挥你的正则技术,自己做一个好的正则公式来匹配,可能出现的变化)
千学不如一看,千看不如一练 一个小任务,独立完成此任务,会对你学习logstash帮助很大:
1.新建一个文件,写入下方数据(我自己定义的一个格式的日志),下方字符中已经存在,且必须存在换行符。
[2018-12-07/15:12:54] [INFO] client:192.168.100.1 GET/47.92.77.111/index.html 200 page_size:1024 use_time:0.3
agent:"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36"
2.使用logstash,设置从文件中读取日志信息,并输出到终端上,最终结果类似下方,可以自己取名字,标识对应字段
{
"path" => "/usr/src/logstash-6.5.1/conf/log.log",
"size" => "1024",
"agent" => "\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36\"",
"request" => "/index.html",
"client_ip" => "192.168.100.1",
"@timestamp" => 2018-12-11T06:33:09.022Z,
"tags" => [
[0] "multiline"
],
"status" => "200",
"time" => "2018-12-07/15:12:54",
"http_response_time" => "0.3",
"message" => "[2018-12-07/15:12:54] [INFO] client:192.168.100.1 GET/47.92.77.123/index.html 200 page_size:1024 use_time:0.3\nagent:\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36\"",
"domain" => "47.92.77.123",
"level" => "INFO",
"method" => "GET",
"host" => "host2",
"type" => "test",
"@version" => "1"
}
答案:
input{
file{
path=> "/usr/src/logstash-6.5.1/conf/log.log"
type => "test"
start_position => "beginning"
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
}
}
}
filter {
grok{
match => { "message" =>"\[%{D_TIME:time}\] \[%{D_LEVEL:level}\] client\:%{IP:client_ip} %{WORD:method}\/%{IP:domain}%{URIPATHPARAM:request} %{NUMBER:status} page_size\:%{NUMBER:size} use_time\:%{NUMBER:http_response_time}\sagent\:%{D_ALL:agent}"}
}
}
output{
stdout{codec => "rubydebug"}
}
任务-答案
kibana
kibana下载安装
链接:https://pan.baidu.com/s/1NAXqHX5qLHJnVb711GdUtA
提取码:wio6
下载下来解压后配置config/kibana.yml 后,即可运行,默认监听5106端口
[root@host1 [14:53:32]/usr/src/kibana-6.5.1-linux-x86_64/config]#cat kibana.yml |grep -v -E "^$|^#"
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.100.2:9200" #这里指向你的es地址
kibana.index: ".kibana" #es上显示的索引名称,供kibana使用 [root@host1 [14:43:16]/usr/src/kibana-6.5.1-linux-x86_64]#/usr/src/kibana-6.5.1-linux-x86_64/bin/kibana #启动
访问测试
kibana是默认英文界面的,我的kibana经过汉化处理,如果你也想汉化,汉化包地址:
https://github.com/anbai-inc/Kibana_Hanization
#添加收集apache,nginx日志。
#apache,nginx日志以json格式存储日志(教程见上方logstash,output项)
新建文件如下,并运行此文件,访问nginx,apache,让它们记录日志,在head插件中查看es中是否正常创建了索引和数据:
input{
file{
path => "/var/log/httpd/access_log.ls_json"
type => "apache"
codec => json
start_position => "beginning"
}
file{
path => "/etc/nginx/logs/elk.access.log"
type => "nginx"
codec=>json
start_position => "beginning"
}
}
output{
if [type] == "nginx"{
elasticsearch{
hosts => ["192.168.100.2:9200"]
index => "nginx-access%{+YYYY.MM.dd}"
}
}
if [type] == "apache"{
elasticsearch{
hosts => ["192.168.100.2:9200"]
index => "apache-access%{+YYYY.MM.dd}"
}
}
}
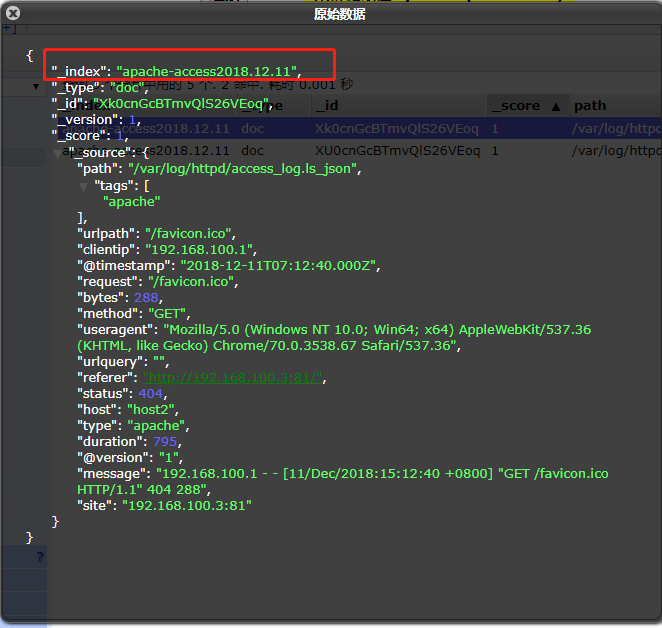
数据正常存入es中后,登录kibana,创建对这两个项的可视化。

到此,apache的访问日志已经设置完毕,你需要把nginx日志的也给做好,下面就可以看到日志条数的图形报表了。
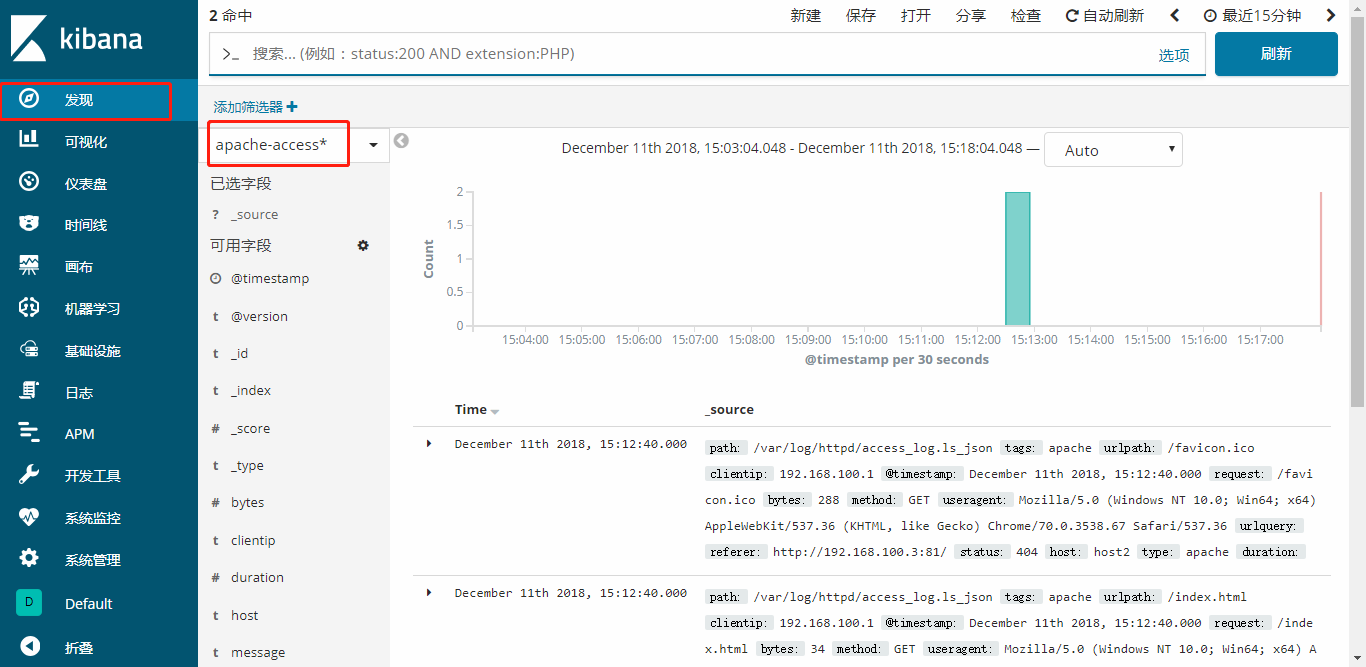
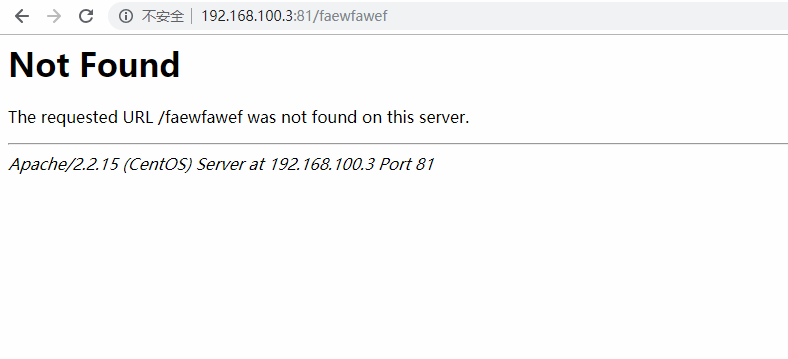
访问你的apache一个不存在的界面,让它报错404,然后可以在kibana里面过滤出报错404的数据和200的数据的比例等。
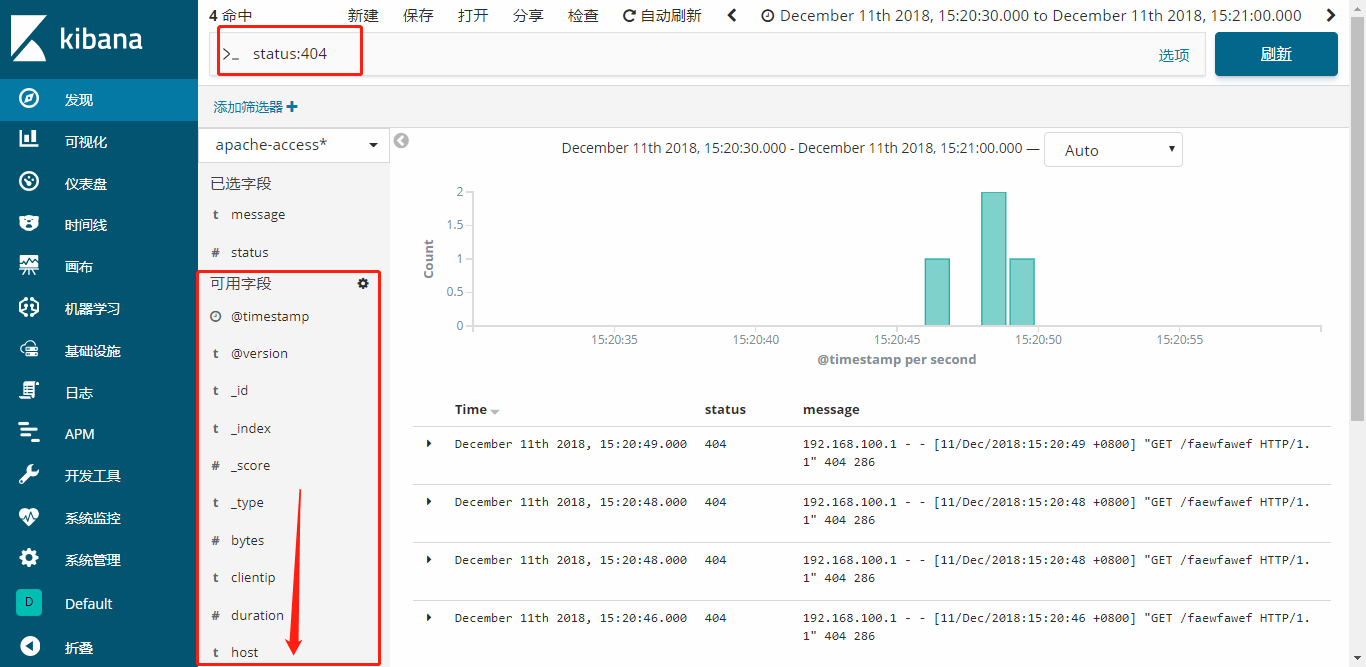
你可以在kibana中搜索报错404的日志数量,前提是定义状态码的字段,在可用字段中(文中提到过,需要将数据已key=>value形式存入es中,kibana取得时候才能识别)
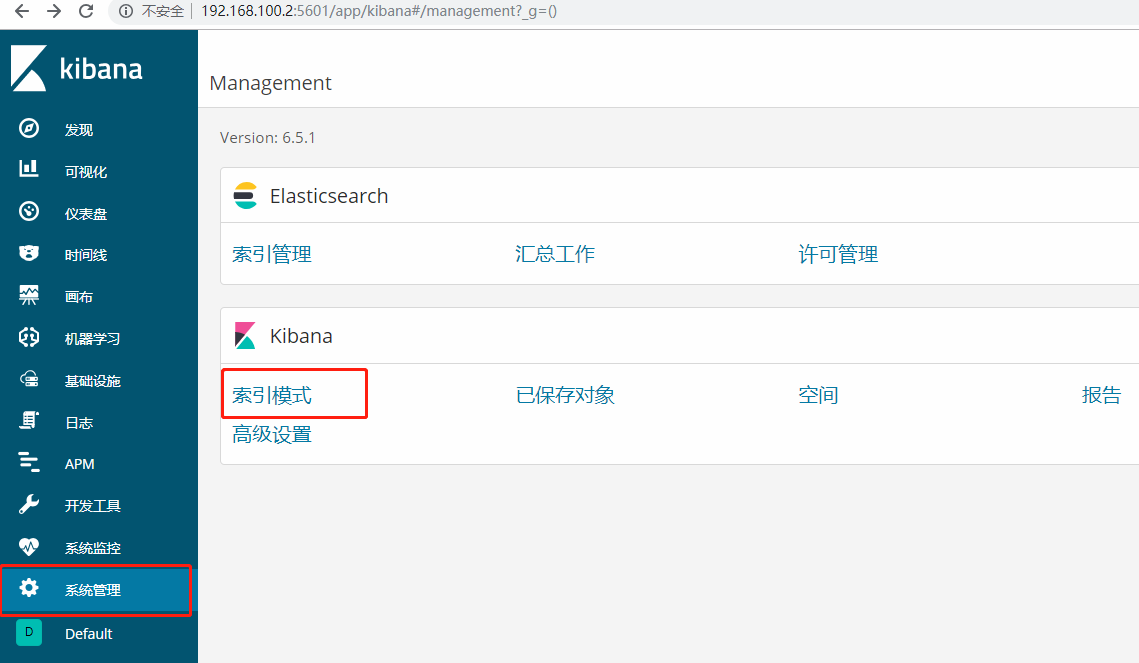
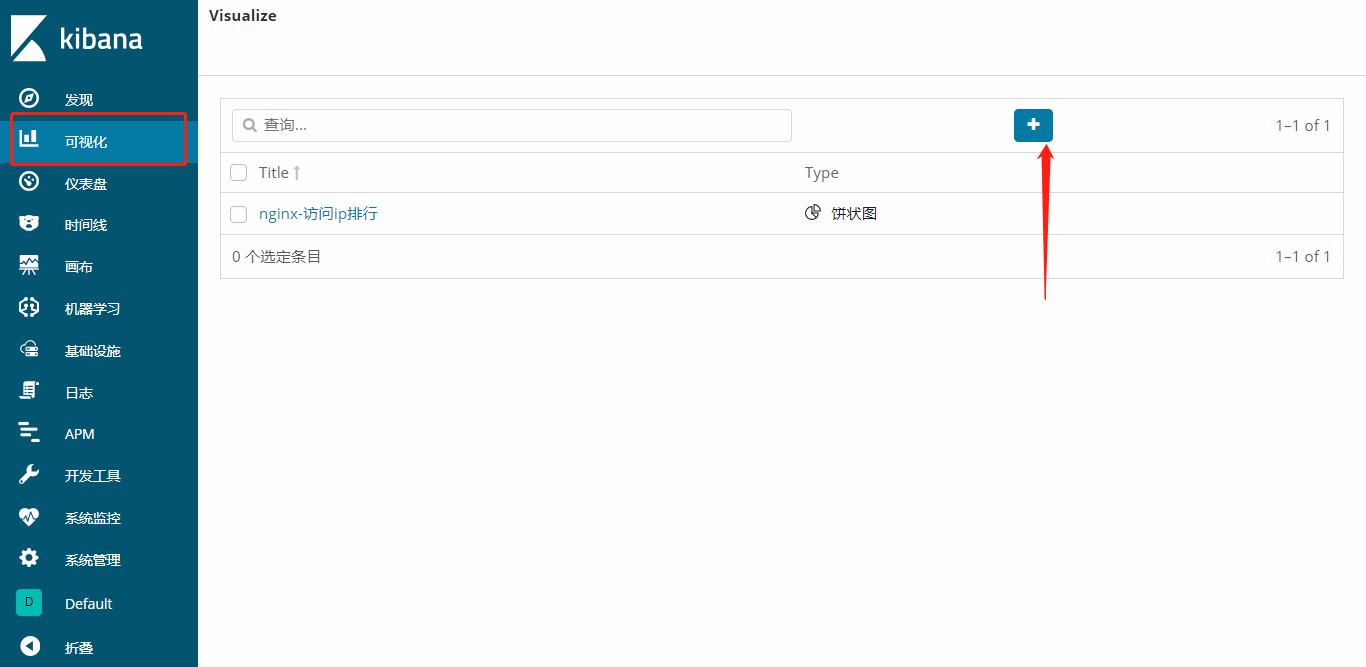
创建可视化
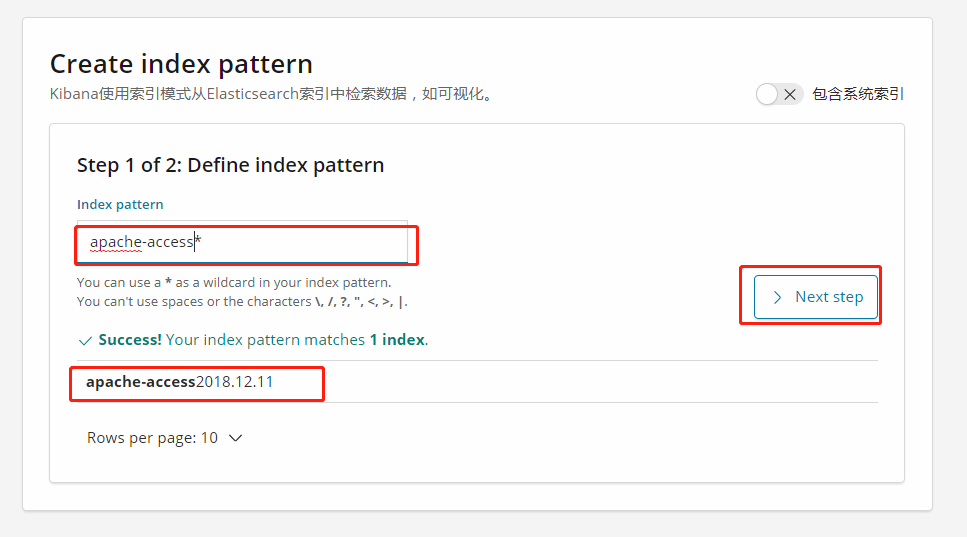
选一个你喜欢的图表
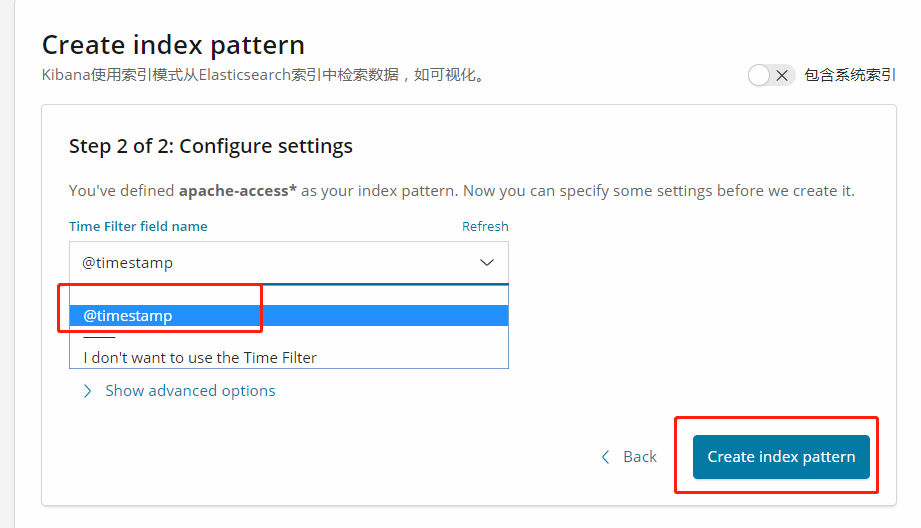
并选择,你定义的索引名称
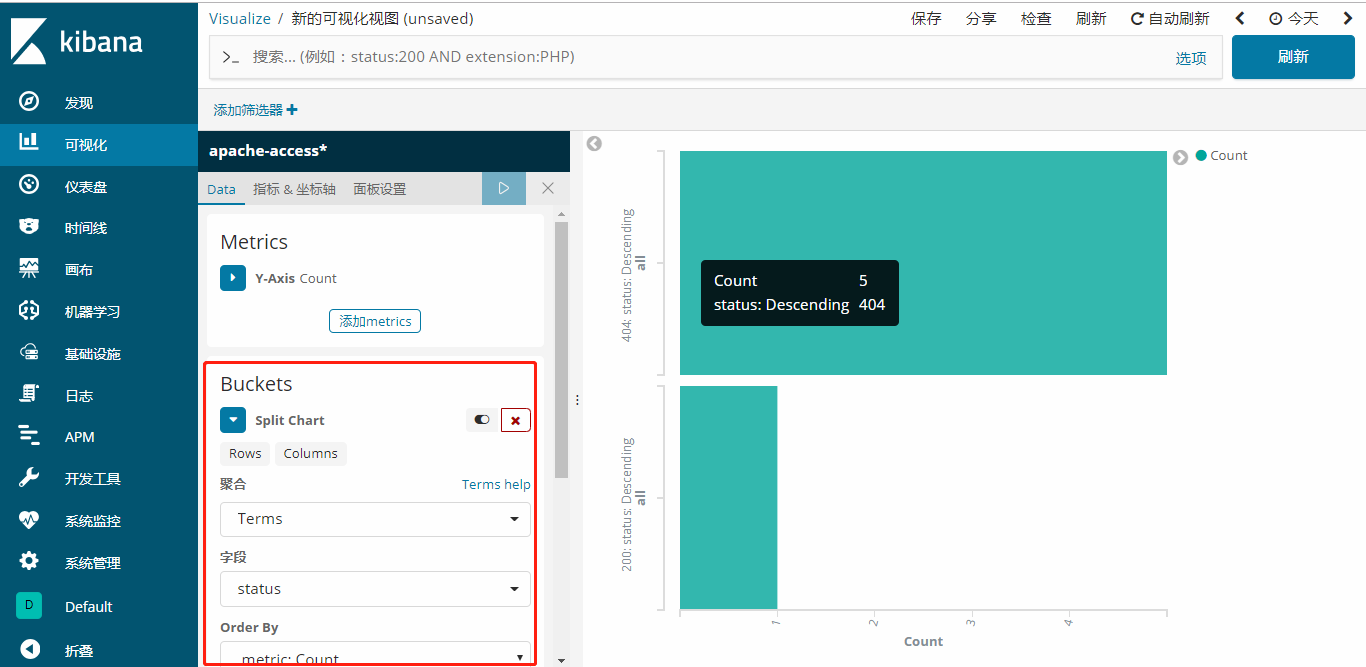
新建一个对状态码进行统计的图表
右上角保存这个可视化,在仪表盘中奖这个可视化添加进去,
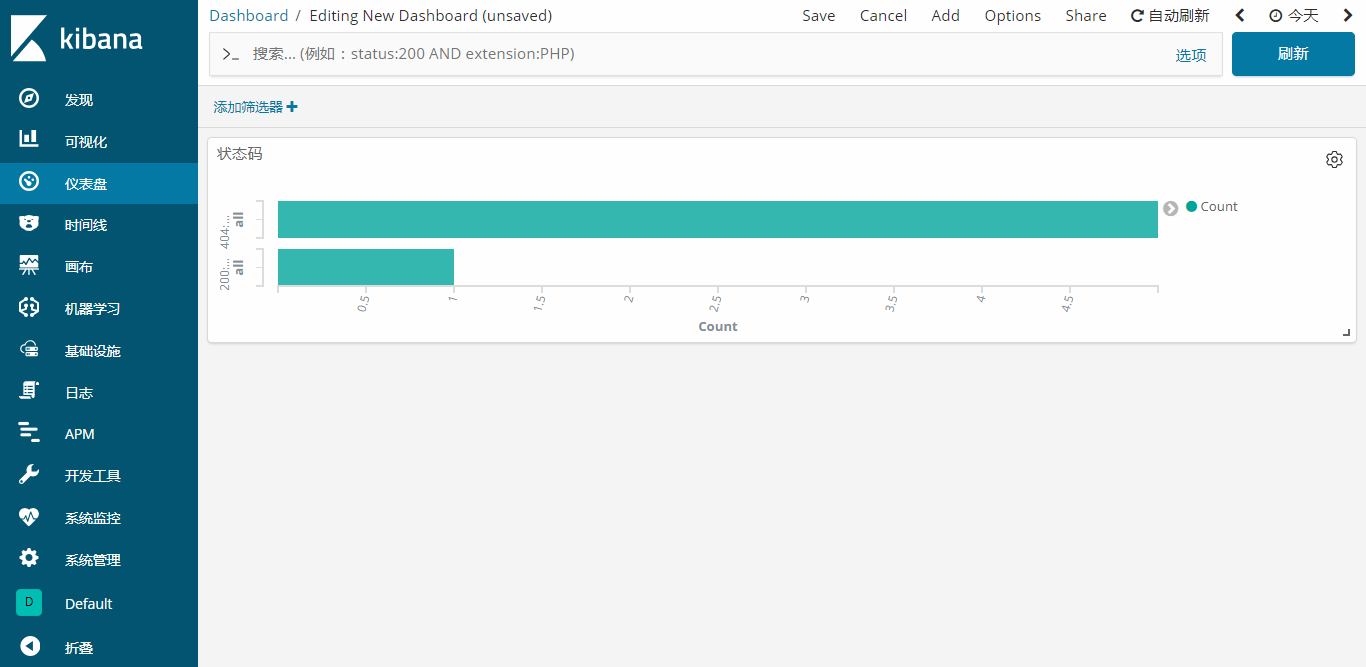 还有很多的功能,这就不细讲,平台已经搭建了,怎么学习,任你来,开启探索之旅把。
还有很多的功能,这就不细讲,平台已经搭建了,怎么学习,任你来,开启探索之旅把。
ELK(elasticsearch+logstash+kibana)入门到熟练-从0开始搭建日志分析系统教程的更多相关文章
- (转)开源分布式搜索平台ELK(Elasticsearch+Logstash+Kibana)入门学习资源索引
Github, Soundcloud, FogCreek, Stackoverflow, Foursquare,等公司通过elasticsearch提供搜索或大规模日志分析可视化等服务.博主近4个月搜 ...
- 开源分布式搜索平台ELK(Elasticsearch+Logstash+Kibana)入门学习资源索引
from: http://www.w3c.com.cn/%E5%BC%80%E6%BA%90%E5%88%86%E5%B8%83%E5%BC%8F%E6%90%9C%E7%B4%A2%E5%B9%B ...
- 使用ELK(Elasticsearch + Logstash + Kibana) 搭建日志集中分析平台实践--转载
原文地址:https://wsgzao.github.io/post/elk/ 另外可以参考:https://www.digitalocean.com/community/tutorials/how- ...
- ELk(Elasticsearch, Logstash, Kibana)的安装配置
目录 ELk(Elasticsearch, Logstash, Kibana)的安装配置 1. Elasticsearch的安装-官网 2. Kibana的安装配置-官网 3. Logstash的安装 ...
- CentOS 6.x ELK(Elasticsearch+Logstash+Kibana)
CentOS 6.x ELK(Elasticsearch+Logstash+Kibana) 前言 Elasticsearch + Logstash + Kibana(ELK)是一套开源的日志管理方案, ...
- 基于CentOS6.5或Ubuntu14.04下Suricata里搭配安装 ELK (elasticsearch, logstash, kibana)(图文详解)
前期博客 基于CentOS6.5下Suricata(一款高性能的网络IDS.IPS和网络安全监控引擎)的搭建(图文详解)(博主推荐) 基于Ubuntu14.04下Suricata(一款高性能的网络ID ...
- 键盘侠Linux干货| ELK(Elasticsearch + Logstash + Kibana) 搭建教程
前言 Elasticsearch + Logstash + Kibana(ELK)是一套开源的日志管理方案,分析网站的访问情况时我们一般会借助 Google / 百度 / CNZZ 等方式嵌入 JS ...
- filebeat+redis+logstash+elasticsearch+kibana搭建日志分析系统
filebeat+redis+elk搭建日志分析系统 官网下载地址:https://www.elastic.co/downloads 1.下载安装filebeat wget https://artif ...
- linux下利用elk+redis 搭建日志分析平台教程
linux下利用elk+redis 搭建日志分析平台教程 http://www.alliedjeep.com/18084.htm elk 日志分析+redis数据库可以创建一个不错的日志分析平台了 ...
随机推荐
- ES6入门十一:Generator生成器、async+await、Promisify
生成器的基本使用 生成器 + Promise async+await Promise化之Promisify工具方法 一.生成器的基本使用 在介绍生成器的使用之前,可以简单理解生成器实质上生成的就是一个 ...
- asp.net 简单的身份验证
1 通常我们希望已经通过身份验证的才能够登录到网站的后台管理界面,对于asp.net 介绍一种简单的身份验证方式 首先在webconfig文件中添加如下的代码 <!--身份验证--> &l ...
- 转载:Java:字节流和字符流(输入流和输出流)
本文内容: 什么是流 字节流 字符流 首发日期:2018-07-24 什么是流 流是个抽象的概念,是对输入输出设备的抽象,输入流可以看作一个输入通道,输出流可以看作一个输出通道. 输入流是相对程序而言 ...
- ffmpeg 命令行 杂记
输入mp4文件中的音频每一帧的信息 ffprobe -show_streams -select_streams a -show_format -show_frames .\HYUNDAIMOBIS.m ...
- Javascript节点选择
jQuery.parent(expr) 找父亲节点,可以传入expr进行过滤,比如$("span").parent()或者$("span").parent(&q ...
- String特性之 “字符串驻留池”
1. 字符串驻留池,就是一块与堆区并行的存放字符串对象的内存区,JVM的驻留池机制规定: 在池中创建一个String对象,第二行会先在池中寻找是否有值与"abc"相同的String ...
- fixed固定元素
1.css <style type="text/css"> .elementFixed{ position: fixed; top:0; } </style> ...
- Binary Search-使用二叉搜索树
终于到二叉树了,每次面试时最担心面试官问题这块的算法问题,所以接下来就要好好攻克它~ 关于二叉树的定义网上一大堆,这篇做为二叉树的开端,先了解一下基本概念,直接从网上抄袭: 先了解下树的概念,bala ...
- Google 的Web开发相关工具
一.PageSpeed Insights PageSpeed Insights 能够针对移动设备和桌面设备生成网页的实际性能报告,并能够提供关于如何改进相应网页的建议. 在线工具:https://de ...
- 【leetcode】1295. Find Numbers with Even Number of Digits
题目如下: Given an array nums of integers, return how many of them contain an even number of digits. Exa ...