【python cookbook】找出序列中出现次数最多的元素
问题
《Python Cookbook》中有这么一个问题,给定一个序列,找出该序列出现次数最多的元素。
例如:
words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the',
'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into',
'my', 'eyes', "you're", 'under'
]
统计出words中出现次数最多的元素?
初步探讨
1、collections模块的Counter类
首先想到的是collections模块的Counter类,具体用法看这里!具体用法看这里!具体用法看这里!https://docs.python.org/3.6/l...,重要的事情强调三遍。
from collections import Counter words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the',
'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into',
'my', 'eyes', "you're", 'under'
] counter_words = Counter(words)
print(counter_words)
most_counter = counter_words.most_common(1)
print(most_counter)
关于most_common([n]):

2、根据dict键值唯一性和sorted()函数
import operator words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the',
'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into',
'my', 'eyes', "you're", 'under'
] dict_num = {}
for item in words:
if item not in dict_num.keys():
dict_num[item] = words.count(item) # print(dict_num) most_counter = sorted(dict_num.items(),key=lambda x: x[1],reverse=True)[0]
print(most_counter)
sorted函数:
传送门:https://docs.python.org/3.6/l...
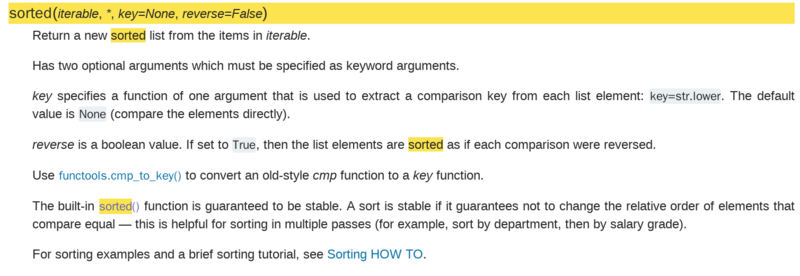
iterable:可迭代类型;
key:用列表元素的某个属性或函数进行作为关键字,有默认值,迭代集合中的一项;
reverse:排序规则. reverse = True 降序 或者 reverse = False 升序,有默认值。
返回值:是一个经过排序的可迭代类型,与iterable一样。
这里,我们使用匿名函数key=lambda x: x[1]
等同于:
def key(x):
return x[1]
这里,我们利用每个元素出现的次数进行降序排序,得到的结果的第一项就是出现元素最多的项。
更进一步
这里给出的序列很简单,元素的数目很少,但是有时候,我们的列表中可能存在上百万上千万个元素,那么在这种情况下,不同的解决方案是不是效率就会有很大差别了呢?
为了验证这个问题,我们来生成一个随机数列表,元素个数为一百万个。
这里使用numpy Package,使用前,我们需要安装该包,numpy包下载地址:https://pypi.python.org/pypi/...。这里我们环境是centos7,选择numpy-1.14.2.zip (md5, pgp)进行下载安装,解压后python setup.py install
def generate_data(num=1000000):
return np.random.randint(num / 10, size=num)
np.random.randint(low[, high, size]) 返回随机的整数,位于半开区间 [low, high)
具体用法参考https://pypi.python.org/pypi
OK,数据生成了,让我们来测试一下两个方法所消耗的时间,统计时间,我们用time函数就可以。
#!/usr/bin/python
# coding=utf-8
#
# File: most_elements.py
# Author: ralap
# Data: 2018-4-5
# Description: find most elements in list
# from collections import Counter
import operator
import numpy as np
import random
import time def generate_data(num=1000000):
return np.random.randint(num / 10, size=num) def collect(test_list):
counter_words = Counter(test_list)
print(counter_words)
most_counter = counter_words.most_common(1)
print(most_counter) def list_to_dict(test_list):
dict_num = {}
for item in test_list:
if item not in dict_num.keys():
dict_num[item] = test_list.count(item) most_counter = sorted(dict_num.items(), key=lambda x: x[1], reverse=True)[0]
print(most_counter) if __name__ == "__main__":
list_value = list(generate_data()) t1 = time.time()
collect(list_value)
t2 = time.time()
print("collect took: %sms" % (t2 - t1)) t1 = t2
list_to_dict(list_value)
t2 = time.time()
print("list_to_dict took: %sms" % (t2 - t1))
以下结果是我在自己本地电脑运行结果,主要是对比两个方法相对消耗时间。
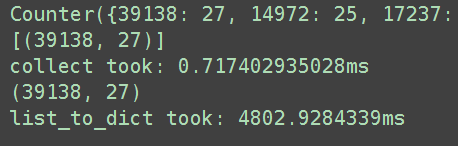
当数据比较大时,消耗时间差异竟然如此之大!下一步会进一步研究Counter的实现方式,看看究竟是什么魔法让他性能如此好。
参考资料
https://blog.csdn.net/xie_0723/article/details/51692806
【python cookbook】找出序列中出现次数最多的元素的更多相关文章
- 【python cookbook】【数据结构与算法】12.找出序列中出现次数最多的元素
问题:找出一个元素序列中出现次数最多的元素是什么 解决方案:collections模块中的Counter类正是为此类问题所设计的.它的一个非常方便的most_common()方法直接告诉你答案. # ...
- Python实用黑科技——找出序列里面出现次数最多的元素
需求: 如何从一个序列中快速获取出现次数最多的元素. 方法: 利用collections.Counter类可以解决这个问题,特别是他的most_common()方法更是处理此问题的最快途径.比如,现在 ...
- Java实现找出数组中重复次数最多的元素以及个数
/**数组中元素重复最多的数 * @param array * @author shaobn * @param array */ public static void getMethod_4(int[ ...
- [PY3]——找出一个序列中出现次数最多的元素/collections.Counter 类的用法
问题 怎样找出一个序列中出现次数最多的元素呢? 解决方案 collections.Counter 类就是专门为这类问题而设计的, 它甚至有一个有用的 most_common() 方法直接给了你答案 c ...
- 剑指Offer:找出数组中出现次数超过一半的元素
题目:找出数组中出现次数超过一半的元素 解法:每次删除数组中两个不同的元素,删除后,要查找的那个元素的个数仍然超过删除后的元素总数的一半 #include <stdio.h> int ha ...
- python之Counter类:计算序列中出现次数最多的元素
Counter类:计算序列中出现次数最多的元素 from collections import Counter c = Counter('abcdefaddffccef') print('完整的Cou ...
- Python中用max()筛选出列表中出现次数最多的元素
1 List = [1,2,3,4,2,3,2] # 随意创建一个只有数字的列表 2 maxTimes = max(List,key=List.count) # maxTimes指列表中出现次数最多的 ...
- python 找出字符串中出现次数最多的字母
# 请大家找出s=”aabbccddxxxxffff”中 出现次数最多的字母 # 第一种方法,字典方式: s="aabbccddxxxxffff" count ={} for i ...
- js常会问的问题:找出字符串中出现次数最多的字符。
一.循环obj let testStr = 'asdasddsfdsfadsfdghdadsdfdgdasd'; function getMax(str) { let obj = {}; for(le ...
随机推荐
- SharpGL学习笔记(一) 平台构建与Opengl的hello World (转)
(一)平台构建与Opengl的hello World OpenGL就是3d绘图的API,微软针和它竞争推出D3D,也就是玩游戏时最常见的DirectorX组件中的3d功能. 所以不要指望windows ...
- Python - Django - 模板语言之自定义过滤器
自定义过滤器的文件: 在 app01 下新建一个 templatetags 的文件夹,然后创建 myfilter.py 文件 这个 templatetags 名字是固定的,myfilter 是自己起的 ...
- IE浏览器提示打印控件未安装的一些原因
打印控件未安装!点击这里执行安装,安装后请刷新页面或重新进入.--该提示是写在LodopFuncs.js里的.相关本博客其他博文:提示“Web打印服务CLodop未安装启动”的各种原因和解决方法.C- ...
- RabbitMQ官方教程二 Work Queues(GOLANG语言实现)
RabbitMQ官方教程二 Work Queues(GOLANG语言实现) 在第一个教程中,我们编写了程序来发送和接收来自命名队列的消息. 在这一部分中,我们将创建一个工作队列,该队列将用于在多个wo ...
- instance与type区别
class Foo(object): pass class Bar(Foo): pass obj = Bar() # isinstance用于判断,对象是否是指定类的实例 (错误的) # isinst ...
- php有关类和对象的相关知识1
有关类和对象的相关知识 类的自动加载 类的自动加载是指,在外面的页面中,并不需要去“引入”(包含)类文件,但是程序会在需要一个类的时候就自动去“动态加载”该类. 什么叫做“需要一个类”?通常是这样的情 ...
- AVIator -- Bypass AV tool
前提概要 项目地址:https://github.com/Ch0pin/AVIator AV:全名为AntiVirus,意指为防病毒软件 AVIator是一个后门生成器实用程序,它使用加密和注入技术来 ...
- tp5功能模块添加与调试
在原先完善的功能基础上添加比如导出列表为excel ,一下子把所有属性写全了,出了问题,不好查找问题在哪? 所以遇到这种问题,需要最简单的测试.比如新建一个mysql表内就放一列一行数据.减少代码量, ...
- Python 模块初始化的时候,发生了什么?
假设有一个 hello.py 的模块,当我们从别的模块调用 hello.py 的时候,会发生什么呢? 方便起见,我们之间在 hello.py 的目录下使用 ipython 导入了. hello.py ...
- 转:Cesium 和 Webpack
原文地址:https://www.jianshu.com/p/85917bcc023f 注意:webpack 和 webpack-cli 的安装参考 https://www.cnblogs.com/m ...