TensorFlow实战第六课(过拟合)
本节讲的是机器学习中出现的过拟合(overfitting)现象,以及解决过拟合的一些方法。
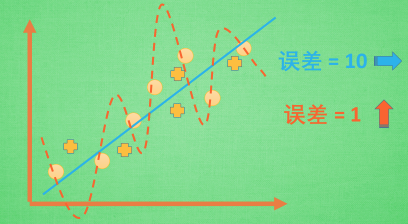
机器学习模型的自负又表现在哪些方面呢. 这里是一些数据. 如果要你画一条线来描述这些数据, 大多数人都会这么画. 对, 这条线也是我们希望机器也能学出来的一条用来总结这些数据的线. 这时蓝线与数据的总误差可能是10. 可是有时候, 机器过于纠结这误差值, 他想把误差减到更小, 来完成他对这一批数据的学习使命. 所以, 他学到的可能会变成这样 . 它几乎经过了每一个数据点, 这样, 误差值会更小 . 可是误差越小就真的好吗? 看来我们的模型还是太天真了. 当我拿这个模型运用在现实中的时候, 他的自负就体现出来. 小二, 来一打现实数据 . 这时, 之前误差大的蓝线误差基本保持不变 .误差小的 红线误差值突然飙高 , 自负的红线再也骄傲不起来, 因为他不能成功的表达除了训练数据以外的其他数据. 这就叫做过拟合. Overfitting.
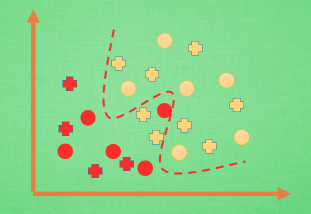
那么在分类问题当中. 过拟合的分割线可能是这样, 小二, 再上一打数据 . 我们明显看出, 有两个黄色的数据并没有被很好的分隔开来. 这也是过拟合在作怪.好了, 既然我们时不时会遇到过拟合问题, 那解决的方法有那些呢.
解决方法

方法一:增大数据量,大部分过拟合产生的原因是因为数据量太少了,如果我们有成千上百万的数据量,红线也会被慢慢拉直,不再那么扭曲。

方法二:运用正规化。L1,L2,regularization等等,这些方法适用于大多数的机器学习,包括神经网络。我们简化机器学习的公式为y=Wx。 W为机器需要学习到的各种参数. 在过拟合中, W 的值往往变化得特别大或特别小. 为了不让W变化太大, 我们在计算误差上做些手脚. 原始的 cost 误差是这样计算, cost = 预测值-真实值的平方. 如果 W 变得太大, 我们就让 cost 也跟着变大, 变成一种惩罚机制. 所以我们把 W 自己考虑进来. 这里 abs 是绝对值. 这一种形式的 正规化, 叫做 l1 正规化. L2 正规化和 l1 类似, 只是绝对值换成了平方. 其他的l3, l4 也都是换成了立方和4次方等等. 形式类似. 用这些方法,我们就能保证让学出来的线条不会过于扭曲.
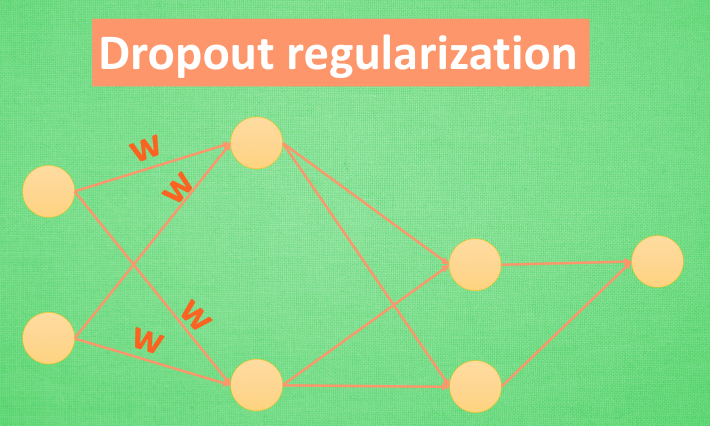
还有一种专门用在神经网络的正规化的方法, 叫作 dropout. 在训练的时候, 我们随机忽略掉一些神经元和神经联结 , 是这个神经网络变得”不完整”. 用一个不完整的神经网络训练一次.
到第二次再随机忽略另一些, 变成另一个不完整的神经网络. 有了这些随机 drop 掉的规则, 我们可以想象其实每次训练的时候, 我们都让每一次预测结果都不会依赖于其中某部分特定的神经元. 像l1, l2正规化一样, 过度依赖的 W , 也就是训练参数的数值会很大, l1, l2会惩罚这些大的 参数. Dropout 的做法是从根本上让神经网络没机会过度依赖.
https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/5-02-A-overfitting/
TensorFlow实战第六课(过拟合)的更多相关文章
- TensorFlow实战第七课(dropout解决overfitting)
Dropout 解决 overfitting overfitting也被称为过度学习,过度拟合.他是机器学习中常见的问题. 图中的黑色曲线是正常模型,绿色曲线就是overfitting模型.尽管绿色曲 ...
- TensorFlow实战第八课(卷积神经网络CNN)
首先我们来简单的了解一下什么是卷积神经网路(Convolutional Neural Network) 卷积神经网络是近些年逐步兴起的一种人工神经网络结构, 因为利用卷积神经网络在图像和语音识别方面能 ...
- Tensorflow实战第十一课(RNN Regression 回归例子 )
本节我们会使用RNN来进行回归训练(Regression),会继续使用自己创建的sin曲线预测一条cos曲线. 首先我们需要先确定RNN的各种参数: import tensorflow as tf i ...
- Tensorflow实战第十课(RNN MNIST分类)
设置RNN的参数 我们本节采用RNN来进行分类的训练(classifiction).会继续使用手写数据集MNIST. 让RNN从每张图片的第一行像素读到最后一行,然后进行分类判断.接下来我们导入MNI ...
- TensorFlow实战第五课(MNIST手写数据集识别)
Tensorflow实现softmax regression识别手写数字 MNIST手写数字识别可以形象的描述为机器学习领域中的hello world. MNIST是一个非常简单的机器视觉数据集.它由 ...
- TensorFlow实战第四课(tensorboard数据可视化)
tensorboard可视化工具 tensorboard是tensorflow的可视化工具,通过这个工具我们可以很清楚的看到整个神经网络的结构及框架. 通过之前展示的代码,我们进行修改从而展示其神经网 ...
- TensorFlow实战第三课(可视化、加速神经网络训练)
matplotlib可视化 构件图形 用散点图描述真实数据之间的关系(plt.ion()用于连续显示) # plot the real data fig = plt.figure() ax = fig ...
- 6.windows-oracle实战第六课 --数据管理
数据库管理员: 每个oracle数据库应该至少有一个数据库管理员(dba),对于一个小的数据库,一个dba就够了,但是对于一个大的数据库可能需要多个dba分担不同的管理职责. 对于dba来说,会权限管 ...
- TensorFlow实战第二课(添加神经层)
莫烦tensorflow实战教学 1.添加神经层 #add_layer() import tensorflow as tf def add_layer(inputs,in_size,out_size, ...
随机推荐
- git回退错误的提交
提交代码导致冲突,执行merge后,冲掉其他人的提交.需要reset,并新建分支进行恢复 解决方法: 1.找到最后一次提交到master分支的版本号,即[merge前的版本号] 2.会退到某个版本号 ...
- [Javascirpt] What’s new in JavaScript (Google I/O ’19)
Private variable in class: class Counter { #count = 0; // cannot be access publicly get value () { r ...
- vue2.0 + element-ui2实现分页
当我们向服务端请求大量数据的时候,并要在页面展示出来,怎么办?这个时候一定会用到分页. 本次所使用的是vue2.0+element-ui2.12实现一个分页功能,element-ui这个组件特别丰富, ...
- bzoj3307 雨天的尾巴题解及改题过程(线段树合并+lca+树上差分)
题目描述 N个点,形成一个树状结构.有M次发放,每次选择两个点x,y对于x到y的路径上(含x,y)每个点发一袋Z类型的物品.完成所有发放后,每个点存放最多的是哪种物品. 输入格式 第一行数字N,M接下 ...
- java浮点数精度问题解决方法
基础知识回顾: BigDecimal.setScale()方法用于格式化小数点setScale(1)表示保留一位小数,默认用四舍五入方式 setScale(1,BigDecimal.ROUND_DOW ...
- Java基础__ToString()方法
Java toString() 方法 (一).方便println()方法的输出 public class TString { private String name; public TString(S ...
- 如何在main.js中改变vuex中的值?
做登录权限控制的时候, 我通过全局路由守卫来去做权限判断,这样的话可能需要在整个项目加载的初期去做一些诸如 接口请求. vuex修改 之类的问题 其实非常简单,直接如图:
- 设置PyCharm中选择文本的背景颜色和代码中和选中单词相同单词的背景颜色
1 设置选中单词的背景颜色 首先进入File->Setting->Editor->Color Scheme后复制一个存在的颜色主题作为自定义的颜色主题(默认的颜色主题是无法修改的,也 ...
- 【译】OkHttp3 拦截器(Interceptor)
一,OkHttp 拦截器介绍(译自官方文档) 官方文档:https://github.com/square/okhttp/wiki/Interceptors 拦截器是 OkHttp 提供的对 Http ...
- LVS分析
概述 LVS是章文嵩博士十几年前的开源项目,已经被何如linux kernel 目录十几年了,可以说是国内最成功的kernle 开源项目, 在10多年后的今天,因为互联网的高速发展LVS得到了极大的应 ...