bert系列一:《Attention is all you need》论文解读
论文创新点:
- 多头注意力
- transformer模型
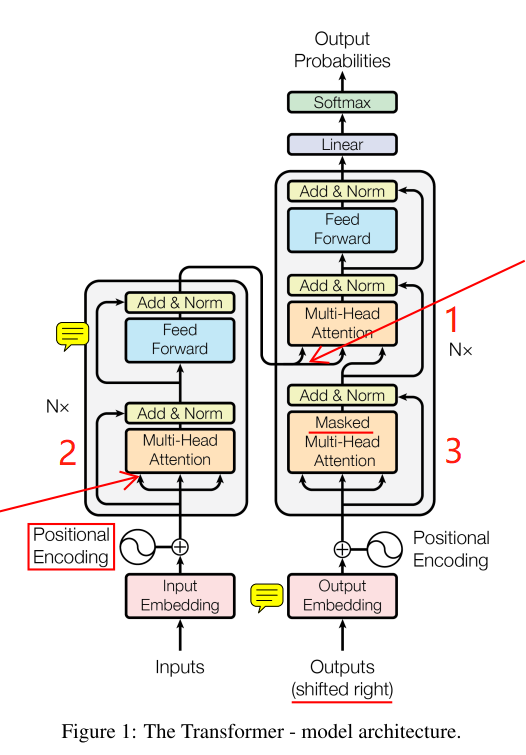
Transformer模型
上图为模型结构,左边为encoder,右边为decoder,各有N=6个相同的堆叠。
encoder
先对inputs进行Embedding,再将位置信息编码进去(cancat方式),位置编码如下:
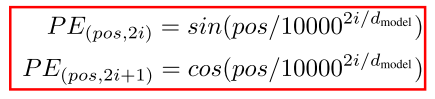
然后经过多头注意力模块后,与残余连接cancat后进行一个Norm操作,多头注意力模块如下:
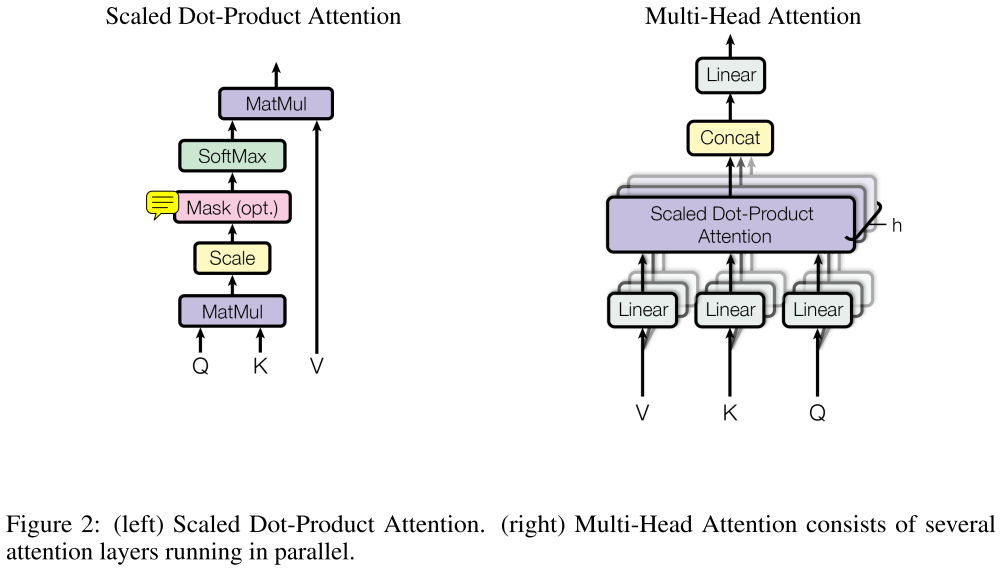
左图:缩放点乘注意力,这就是个平常的注意力机制,只不过多了scale和mask(仅对于decoder下面橙色框部分),使用的是dot-product attention,原文还提到另一种additive attention。
右图:多头注意力实现。每个Q,K,V都经过h个(不同)线性结构,以捕获不同子空间的信息,经过左图结构后,对h个dot-product attention进行concat后,再经过一个线性层。
之后,再通过一个有残余连接的前向网络。
decoder
同样先经过Embedding和位置编码,输入outputs右移了(因为每一个当前输出基于之前的输出)。
下面的橙色框:
之后也经过一个多头的self-attention,不同的是,它多了个mask操作。
这个mask操作是什么意思呢?注意我们的self-attention是一句话中每个词向量都与句子中所有词向量有关,对于encoder这没问题,而对于decoder,我们是根据之前的输出预测下一个输出。
举个例子,在BiLSTM中(当然这里是Transformer模型),假设我们decode时输入为A-B-C-D序列,在B处解码下一个输出时,我们根据之前的输出进行预测,但是这是双向模型,
即我们存在这样的一个之前的输出C-B-A-B,那么这个之前的输出里居然包含了我们下一个需要正确预测的C!这就是“自己看见自己”问题。
所以,mask操作是掩盖掉之后的位置(原文leftward,即向左流动的信息)的影响,原文是置为负无穷。这个橙色框我觉得可以称为half-self-attention。
最上面的橙色框:
它就不能叫self-attention结构了,因为它的K和V来自encoder的输出,Q是下面橙色框的输出。到这步为止,我们的输入inputs是完整的self-attention了,我们的输出outputs也是half-self-attention了。
好了,前戏准备完毕,开始短兵相接了。
这里的K和V一般相同,表示经过self-attention的隐藏语义向量,Q为经过half-self-attention的上一个输出,此处即为解码操作。经过一个有残余连接的前向网络,一个线性层,再softmax得到输出概率分布。
至此,Transformer模型描述完毕。
我们再看看self-attention模块,我之前一直不明白这些Q,K,V是啥东东。此处也是我个人推断。
在self-attention中,K,V表示当前位置的词向量,Q表示所有位置的词向量,用Q中每一个词向量与K进行操作(类似上面缩放点乘注意力截止到softmax),得到L个(L为句子单词数)权重向量。
此时应该有2种操作,一种是对L个权重向量相加,一种是取平均。得到的结果权重向量与V点乘,即为有self-attention后的词向量。
其余的实验及结果部分不再讲述,没什么难点。
这里再提下另一篇论文《End-To-End Memory Networks》中的一个模型结构。因为这篇论文被上面论文提到,对于理解上面论文有所帮助。
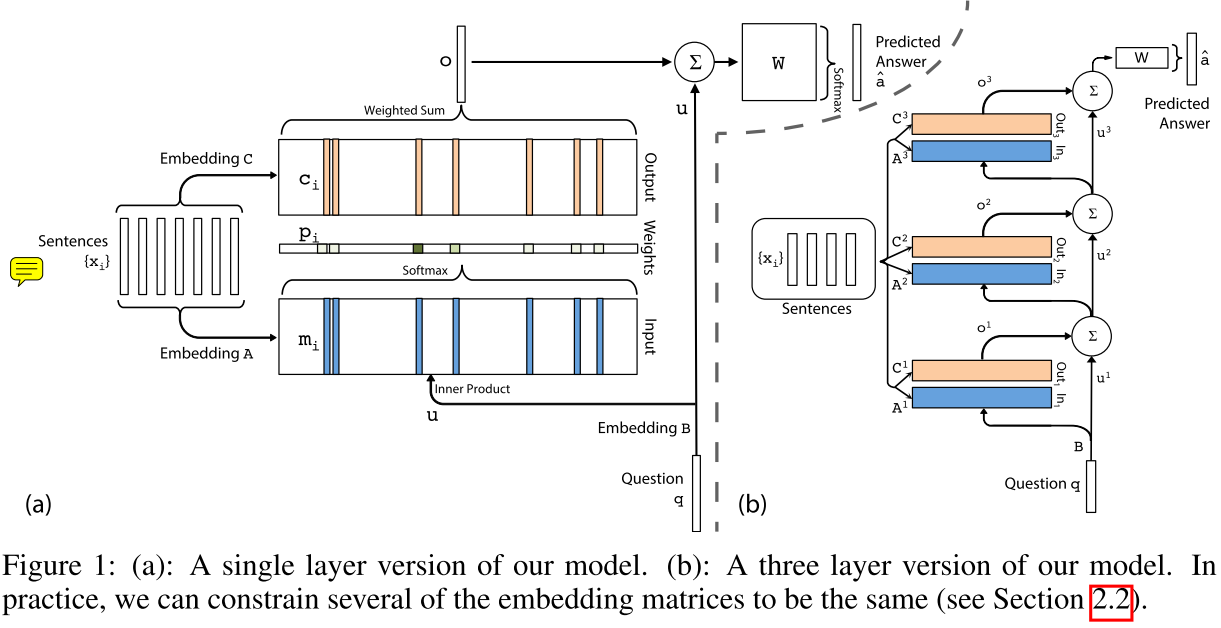
上图左边为单层,右边为多层版本。
单层的输出为:

Embedding B和C用于将输入x和问题q转化为嵌入向量,Embedding A用另一套参数将输出x转化为嵌入向量,与问题q共同决定注意力权重。
因为右图涉及到众多参数,为了简化模型,作者提出2种方案,这里直接上图:

这篇论文的创新点在于右图的多层版本类似RNNs,运算复杂度也比拟RNNs,避免了RNNs存在的一些问题。在QA问题上取得不错的成绩。
bert系列一:《Attention is all you need》论文解读的更多相关文章
- Bert系列 源码解读 四 篇章
Bert系列(一)——demo运行 Bert系列(二)——模型主体源码解读 Bert系列(三)——源码解读之Pre-trainBert系列(四)——源码解读之Fine-tune 转载自: https: ...
- Bert系列(三)——源码解读之Pre-train
https://www.jianshu.com/p/22e462f01d8c pre-train是迁移学习的基础,虽然Google已经发布了各种预训练好的模型,而且因为资源消耗巨大,自己再预训练也不现 ...
- bert系列二:《BERT》论文解读
论文<BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding> 以下陆续介绍ber ...
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- nlp任务中的传统分词器和Bert系列伴生的新分词器tokenizers介绍
layout: blog title: Bert系列伴生的新分词器 date: 2020-04-29 09:31:52 tags: 5 categories: nlp mathjax: true ty ...
- Java容器--2021面试题系列教程(附答案解析)--大白话解读--JavaPub版本
Java容器--2021面试题系列教程(附答案解析)--大白话解读--JavaPub版本 前言 序言 再高大上的框架,也需要扎实的基础才能玩转,高频面试问题更是基础中的高频实战要点. 适合阅读人群 J ...
- 论文解读(FedGAT)《Federated Graph Attention Network for Rumor Detection》
论文信息 论文标题:Federated Graph Attention Network for Rumor Detection论文作者:Huidong Wang, Chuanzheng Bai, Ji ...
- BERT论文解读
本文尽量贴合BERT的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进行翻译,其中有一些论文没有解释清楚或者笔者未能深入理解的地方,都有放出原文,如有不当之处,请各位多多包含,并 ...
- [Attention Is All You Need]论文笔记
主流的序列到序列模型都是基于含有encoder和decoder的复杂的循环或者卷积网络.而性能最好的模型在encoder和decoder之间加了attentnion机制.本文提出一种新的网络结构,摒弃 ...
随机推荐
- nginx日志、变量
日志格式类型等 包含两类:access_log error.log log_format log只能在http模块下配置 下图是一个典型error_log配置 warn表示默认日志级别为‘’警告‘’ ...
- js swal()弹出框
做前端开发的时候时常会遇到修改成功.新增成功这类弹出框,用alert的话未免有点太low了,而swal()是一个简单又实用的弹出框方法 alert 弹出框样式如下: swal() 弹出框样式如下: 代 ...
- 洛谷-p5410-扩展KMP模板
链接: https://www.luogu.org/problem/P5410#submit 题意: 有两个字符串aa,bb,要求输出bb与aa的每一个后缀的最长公共前缀 思路: 扩展kmp模板, 上 ...
- Mac修改显示器使支持原生缩放
教程 直接搬运没有意义,直接放链接.地址:https://bbs.feng.com/read-htm-tid-11677019.html 若无法访问请使用网页截图备份.地址:https://img20 ...
- Module parse failed: Export 'instance' is not defined (35:19)
Module parse failed: Export 'instance' is not defined (35:19) 使用npm出现的这错误,用yarn就可以了 这种情况rm node_modu ...
- mysql优化(上)
磁盘组成 和 磁盘读取过程 尽量减少 i/o 操作. 表结构设计:(1)三范式 : 原子性(不可拆分).唯一性(不能有完全相同的数据).无冗余性(不能有多余的数据),对于冗余性说明一下:拿订单 ...
- maven的概念-01
1.maven 简介 maven是Apach软件基金会维护的一款自动化构建工具: 作用是服务于java平台的项目构建和依赖管理: 2.关于项目构建 1)java代码 Java是一门编译型语言,.j ...
- word粘贴图片到ekitor
最近公司做项目需要实现一个功能,在网页富文本编辑器中实现粘贴Word图文的功能. 我们在网站中使用的Web编辑器比较多,都是根据用户需求来选择的.目前还没有固定哪一个编辑器 有时候用的是UEditor ...
- svn版本更新
1.查看当前版本:svn --version 2.配置svn yum源 tee /etc/yum.repos.d/wandisco-svn.repo <<-'EOF' [WandiscoS ...
- 微信小程序_(校园视)开发用户注册登陆
微信小程序_(校园视) 开发用户注册登陆 传送门 微信小程序_(校园视) 开发上传视频业务 传送门 微信小程序_(校园视) 开发视频的展示页-上 传送门 微信小程序_(校园视) 开发视频的展示页-下 ...