用python爬取豆瓣电影Top 250
首先,打开豆瓣电影Top 250,然后进行网页分析。找到它的Host和User-agent,并保存下来。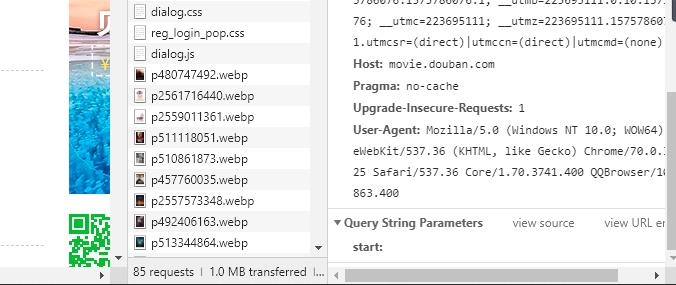 然后,我们通过翻页,查看各页面的url,发现规律:
然后,我们通过翻页,查看各页面的url,发现规律:
第一页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
第四页:https://movie.douban.com/top250?start=75&filter=
我们发现,每个页面的url都是https://movie.douban.com/top250?start= +25+ &filter=的规律。如此,就可以开始写代码:
import requests
from bs4 import BeautifulSoup
def get_movie():
headers={
'Host': 'movie.douban.com',
'User-Agent': 'Mozilla / 5.0(Windows NT 6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 45.0.2454.101Safari / 537.36'
} #防止反扒措施
movie_list=[]
for i in range(10):
url='https://movie.douban.com/top250?start='+str(i*25) #各页面url
response=requests.get(url,headers=headers,timeout=10)
soup=BeautifulSoup(response.text,'lxml')
div_list=soup.find_all('div',class_='hd')
for each in div_list:
movie=each.a.span.text.strip()
movie_list.append(movie)
for j in movie_list:
print(j) #按格式输出电影名称
get_movie()
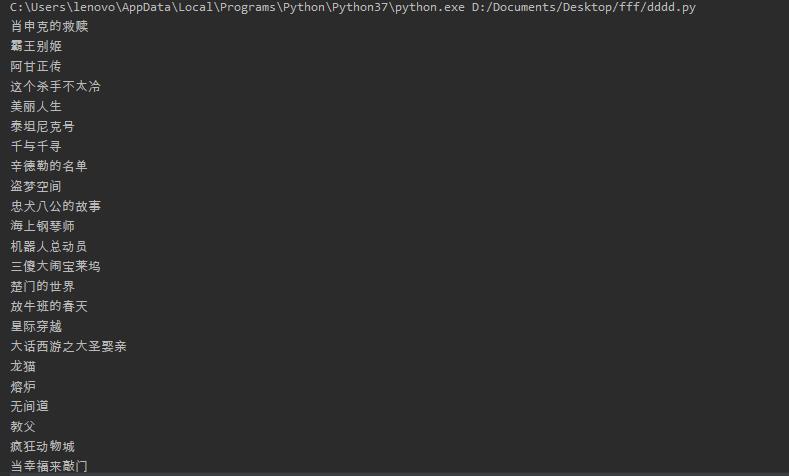
下面给出运行结果:
用python爬取豆瓣电影Top 250的更多相关文章
- 爬取豆瓣电影TOP 250的电影存储到mongodb中
爬取豆瓣电影TOP 250的电影存储到mongodb中 1.创建项目sp1 PS D:\scrapy> scrapy.exe startproject douban 2.创建一个爬虫 PS D: ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- 爬虫——正则表达式爬取豆瓣电影TOP前250的中英文名
正则表达式爬取豆瓣电影TOP前250的中英文名 1.首先要实现网页的数据的爬取.新建test.py文件 test.py 1 import requests 2 3 def get_Html_text( ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
随机推荐
- Nessus更新到8.6.0
Nessus更新到8.6.0 此次更新,变化主要有以下几点:(1)加强过期提醒.购买链接,并且允许用户启用关闭提醒功能.(2)Nessus基础班和试用版中,导出的报告默认带有水印.(3)Nessus企 ...
- redis删除多个键
DEL命令的参数不支持通配符,但我们可以结合Linux的管道和xargs命令自己实现删除所有符合规则的键.比如要删除所有以“user:”开头的键,就可以执行redis-cli KEYS "u ...
- numpy linspace
https://www.cnblogs.com/antflow/p/7220798.html numpy.linspace(start, stop, num=50, endpoint=True, re ...
- Java Sound : generate play sine wave - source code
转载自:http://ganeshtiwaridotcomdotnp.blogspot.com/2011/12/java-sound-generate-play-sine-wave.html Work ...
- antd 用 customize-cra 方式引入 sass
antd 用 customize-cra 方式引入 sass 只需要安装:node-sass 即可
- 【Leetcode_easy】1047. Remove All Adjacent Duplicates In String
problem 1047. Remove All Adjacent Duplicates In String 参考 1. Leetcode_easy_1047. Remove All Adjacent ...
- web端自动化——python多线程
Python通过两个标准库thread和threading提供对线程的支持.thread提供了低级别的.原始的线程以及一个简单的锁.threading基于Java的线程模型设计. 锁(Lock)条件变 ...
- 高级UI-TableLayout
TableLayout选项卡,用于需要使用选项卡的场景,一般是用于切换Fragment,现在的主流做法一般是TableLayout+ViewPager+Fragment,综合实现选项卡的操作 由于Ta ...
- Spring切面编程AOP
- solr关于日期范围查询
问题:从solr上查询创建日期在2019-06-25到2019-06-26之间的数据 createDate:[2019-06-25 TO 2019-06-26]