[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
一、前言
之前使用原生的 Python 库去爬取网页信息,经常要使用正则表达式,笔者记性不是很好,经常经常忘记相关符号及其作用。
后来使用著名的 Scrapy 框架去爬取信息,感觉太笨重了,特别是一个项目开发到一半,要引入爬虫功能,再使用 Scrapy,就不是那么友好了,其本身就是一个 Web Project。
近来使用一个和之前 Java 爬虫特别简单好使的 Jsoup 框架极其类似的 Beautiful Soup
引入也很简单:
# Python 2+
pip install beautifulsoup4
# Python 3+
pip3 install beautifulsoup4- 1
- 2
- 3
- 4
- 5
使用 Python 爬虫体验当然是比 Java 要好,java开发有点 “做作” —— 每一步都极其格式化(面向对象),Python 则运用自如。
二、需求
现在要爬取 CSDN首页 的今日推荐的 文章 标题 及其 链接,
2.1.这是网页目标内容
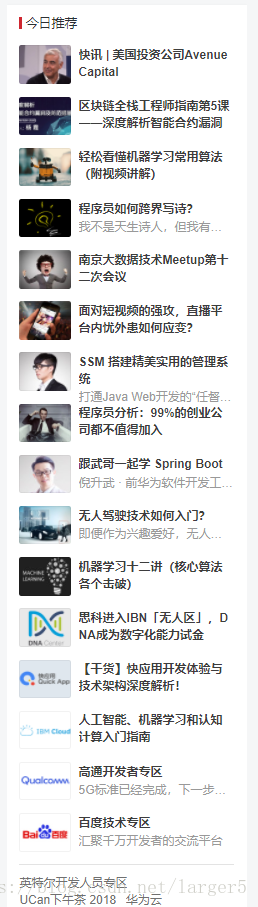
2.2.这是网页目标内容对应的源码

三、实践
你猜需要多少行代码,没错,就这几行,就是这么牛逼。
因力求精简,笔者为此费了几个小时通读官方 API 文档数遍。
3.1.代码
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://www.csdn.net/").read().decode('utf-8')
soup = BeautifulSoup(html,"html.parser")
titles=soup.select("h3[class='company_name'] a") # CSS 选择器
for title in titles:
print(title.get_text(),title.get('href'))# 标签体、标签属性- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.2.效果

四、小结
参考文献:
Beautiful Soup 中文文档
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息的更多相关文章
- python爬虫之Beautiful Soup基础知识+实例
python爬虫之Beautiful Soup基础知识 Beautiful Soup是一个可以从HTML或XML文件中提取数据的python库.它能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档 ...
- Python爬虫之Beautiful Soup解析库的使用(五)
Python爬虫之Beautiful Soup解析库的使用 Beautiful Soup-介绍 Python第三方库,用于从HTML或XML中提取数据官方:http://www.crummv.com/ ...
- python 爬虫利器 Beautiful Soup
python 爬虫利器 Beautiful Soup Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文 ...
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- Python爬虫库-Beautiful Soup的使用
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,简单来说,它能将HTML的标签文件解析成树形结构,然后方便地获取到指定标签的对应属性. 如在上一篇文章通过爬虫 ...
- python爬虫之Beautiful Soup的基本使用
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
- python标准库Beautiful Soup与MongoDb爬喜马拉雅电台的总结
Beautiful Soup标准库是一个可以从HTML/XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,Beautiful Soup将会节省数小 ...
- python 爬虫5 Beautiful Soup的用法
1.创建 Beautiful Soup 对象 from bs4 import BeautifulSoup html = """ <html><head& ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
随机推荐
- Sentinel 快速入门
Sentinel 简介 什么是 Sentinel? 『Sentinel』是阿里中间件团队开源的,面向分布式服务架构的轻量级高可用流量控制组件,主要以流量为切入点,从流量控制.熔断降级.系统负载保护等多 ...
- new HttpClient().PostAsync封装参数
var data = Encoding.UTF8.GetBytes("{ \"y\": 5, \"x\": 3}"); var conten ...
- error storage size of my_addr isn't known
- Java工作笔记:工作中使用JNA调用C++库的一些细节(转载)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/zjutzmh/article/detai ...
- Javescript——数据类型
原文链接:Understanding Data Types in JavaScript Data types are used to classify one particular type of d ...
- [Scikit-learn] 1.1 Generalized Linear Models - from Linear Regression to L1&L2
Introduction 一.Scikit-learning 广义线性模型 From: http://sklearn.lzjqsdd.com/modules/linear_model.html#ord ...
- Java-WebSocket调用报错:WebSocketClient objects are not reuseable
我的代码 import com.google.common.collect.ImmutableMap; import com.google.common.io.ByteArrayDataOutput; ...
- 【leetcode_easy】598. Range Addition II
problem 598. Range Addition II 题意: 第一感觉就是最小的行和列的乘积即是最后结果. class Solution { public: int maxCount(int ...
- 第二十四章 在线会话管理——《跟我学Shiro》
目录贴:跟我学Shiro目录贴 有时候需要显示当前在线人数.当前在线用户,有时候可能需要强制某个用户下线等:此时就需要获取相应的在线用户并进行一些操作. 本章基于<第十六章 综合实例>代码 ...
- 开始学习Docker啦--容器理论知识(一)
目录 一.容器核心技术 1.容器规范 2.容器 runtime 3.容器管理工具 4.容器定义工具 5.Registry 6.容器 OS 二.说说容器 1.什么是容器 Containers vs. v ...