5.flask与数据库
1.安装postgresql
注意:在flask中,操作数据库还是通过orm调用驱动来操作。sqlalchemy是python下的一款工业级的orm,比Django自带的orm要强大很多,至于什么类型的数据库不重要,通过orm上层操作的代码是一样的。我们目前介绍的是sqlalchemy,与flask没有太大关系,后面会介绍如何将sqlalchemy与flask集成,也有一个开源的第三方组件,叫flask-sqlalchemy。
关于数据库,我这里选择的是postgresql,当然mysql、Oracle、Mariadb等数据库也是可以的。
安装postgresql可以直接到这个网站下载,https://www.enterprisedb.com/downloads/postgres-postgresql-downloads,我这里下载的是Windows版本的。

直接去下载即可,一路next即可。我已经安装过了,这里就不再演示了。
使用navicat进行连接是没问题的
2.SQLAlchemy的介绍和基本使用
sqlalchemy是一款orm框架
注意:SQLAlchemy本身是无法处理数据库的,必须依赖于第三方插件,比方说pymysql,cx_Oracle等等
SQLAlchemy等于是一种更高层的封装,里面封装了许多dialect(相当于是字典),定义了一些组合,比方说: 可以用pymysql处理mysql,也可以用cx_Oracle处理Oracle,关键是程序员使用什么,然后会在dialect里面进行匹配,同时也将我们高层定义的类转化成sql语句,然后交给对应的DBapi去执行。
除此之外,SQLAlchemy还维护一个数据库连接池,数据库的链接和断开是非常耗时的 SQLAlchemy维护了一个数据库连接池,那么就可以拿起来直接用
首先要安装sqlalchemy和psycopg2(python中用于连接postgresql的驱动),直接pip install 即可
# 连接数据库需要创建引擎
from sqlalchemy import create_engine
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
# 创建一个引擎,可以用来执行sql语句
# 连接方式:数据库+驱动://用户名:密码@ip:端口/数据库
# 当然驱动也可以不指定,会选择默认的,如果有多种驱动的话,想选择具体的一种,可以指定。
# 但对于目前的postgresql来说,不指定驱动,默认就是psycopg2
# 这里去掉driver的话,也可以这么写engine = create_engine(f"{dialect}://{username}:{password}@{hostname}:{port}/{database}")
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
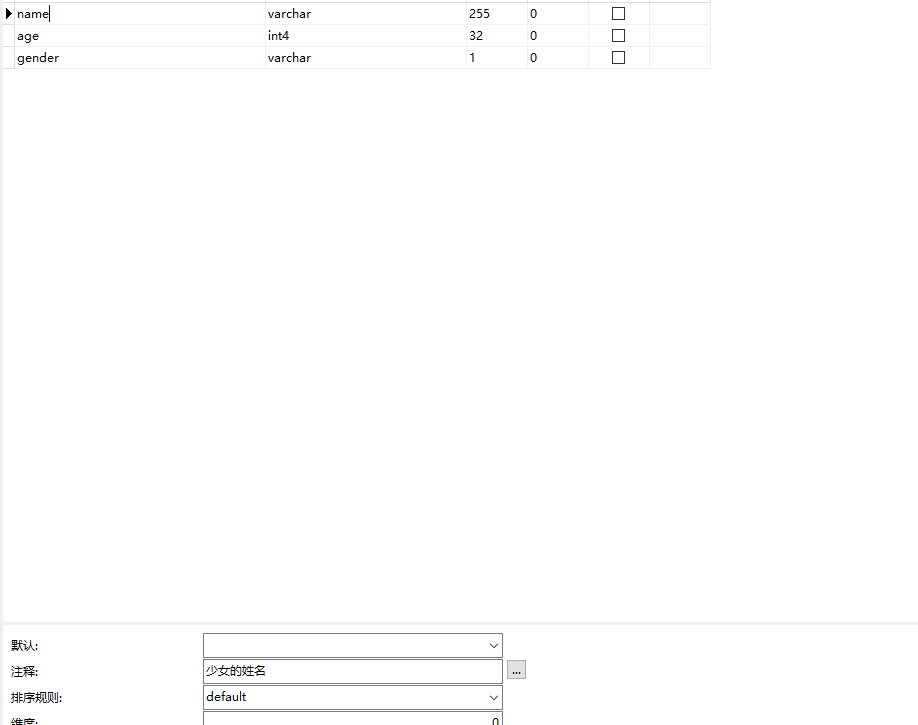
create_table_sql = """
create table girls(
name varchar(255),
age int,
gender varchar(1)
);
comment on column girls.name is '少女的姓名';
comment on column girls.age is '少女的年龄';
comment on column girls.gender is '少女的性别';
"""
engine.execute(create_table_sql)
显然是执行成功的,然后将表删掉也是没问题的。
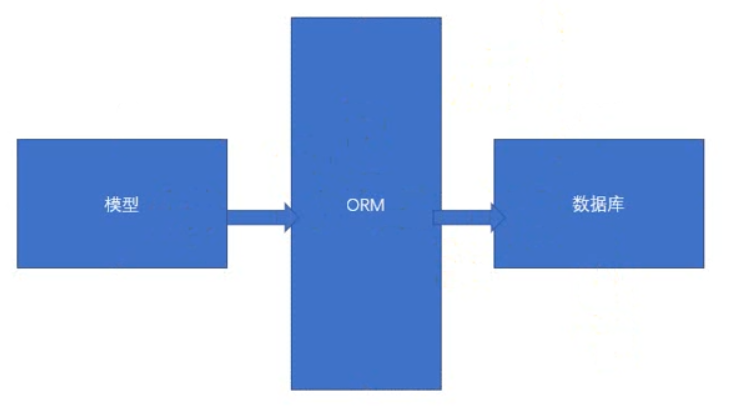
3.orm介绍
orm: object relation mapping,就是可以把我们写的类转化成表。将类里面的元素映射到数据库表里面
4.定义orm模型并映射到数据库中
刚才我们已经成功的创建了一张表了,但是我们发现实际上我们写的还是sql语句,只不过是用python来执行的。换句话说,我sql语句写好,我还可以在终端、Navicat等等地方执行。
下面,我们将使用python,通过定义一个类,然后通过sqlalchemy,映射为数据库中的一张表。
from sqlalchemy import create_engine
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
# 需要以下步骤
'''
1.创建一个orm模型,这个orm模型必须继承SQLAlchemy给我们提供好的基类
2.在orm中创建一些属性,来跟表中的字段进行一一映射,这些属性必须是SQLAlchemy给我们提供好的数据类型
3.将创建好的orm模型映射到数据库中
'''
# 1.生成一个基类,然后定义模型(也就是orm中的o),继承这个基类
from sqlalchemy.ext.declarative import declarative_base
# 这个declarative_base是一个函数,传入engine,生成基类
Base = declarative_base(bind=engine)
class Girl(Base):
# 指定表名:__tablename__
__tablename__ = "girls"
# 指定schema,postgresql是由schema的,如何指定呢
__table_args__ = {
"schema": "public" # 其实如果不指定,那么public默认是public,这里为了介绍,所以写上
}
# 2.创建属性,来和数据库表中的字段进行映射
from sqlalchemy import Column, Integer, VARCHAR
# 要以 xx = Column(type)的形式,那么在表中,字段名就叫xx,类型就是type
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(255))
age = Column(Integer)
gender = Column(VARCHAR(1))
class Boy(Base):
__tablename__ = "boys"
from sqlalchemy import Column, Integer, VARCHAR
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(255))
age = Column(Integer)
gender = Column(VARCHAR(1))
# 3.模型创建完毕,那么将模型映射到数据库中
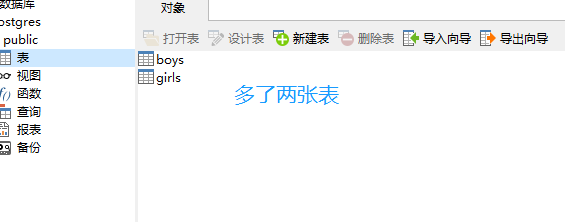
# 这行代码就表示将所有继承了Base的类映射到数据库中变成表,我们这里有两个类。不出意外的话,数据库中应该会有两张表,叫girls和boys
Base.metadata.create_all()
# 一旦映射,即使改变模型之后再次执行,也不会再次映射。
# 比如,我在模型中新增了一个字段,再次映射,数据库中的表是不会多出一个字段的
# 除非将数据库中与模型对应的表删了,重新映射。
# 如果模型修改了,可以调用Base.metadata.drop_all(),然后再create_all()
5.SQLAlchemy对数据的增删改查操作
将表删除,重新映射
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR
from sqlalchemy.orm import sessionmaker
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class Girls(Base):
__tablename__ = "girls"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(30))
age = Column(Integer)
gender = Column(VARCHAR(1))
anime = Column(VARCHAR(50))
Base.metadata.create_all()
# 将对象实例化,然后对对象进行操作,会映射为对数据库表的操作
girls = Girls()
# 创建Session类,绑定引擎
Session = sessionmaker(bind=engine)
# 实例化得到session对象,通过session来操作数据库的表
session = Session()
增
girls.name = "satori"
girls.age = 16
girls.gender = "f"
girls.anime = "动漫地灵殿"
# 一个Girls实例在数据库的表中对应一条记录,进行添加
session.add(girls)
# 将对girls做的操作提交执行
# 像增、删、改这些设计数据变更的操作,必须要提交
session.commit()
# 也可以批量进行操作
# 另外可以生成Girls实例,得到girls,通过girls.xx的方式赋值
# 也可以通过Girl(xx="")的方式
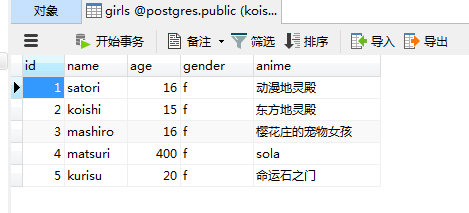
session.add_all([
Girls(name="koishi", age=15, gender="f", anime="东方地灵殿"),
Girls(name="mashiro", age=16, gender="f", anime="樱花庄的宠物女孩"),
Girls(name="matsuri", age=400, gender="f", anime="sola"),
Girls(name="kurisu", age=20, gender="f", anime="命运石之门")
])
session.commit()
查
# 调用session.query(Girls),注意里面传入的不是数据库的表名,而是模型。
# 映射到数据库相当于select * from girls
# 但得到是一个query对象,还可以加上filter进行过滤,相当于where,得到了仍是一个query对象
# 对query对象调用first()会拿到第一条数据,没有的话为None。调用all()会拿到所有满足条件的数据,没有的话则是一个空列表
query = session.query(Girls).filter(Girls.name == "satori")
print(type(query)) # <class 'sqlalchemy.orm.query.Query'>
# 直接打印query对象,会生成对应的sql语句
print(query)
"""
SELECT girls.id AS girls_id, girls.name AS girls_name, girls.age AS girls_age, girls.gender AS girls_gender, girls.anime AS girls_anime
FROM girls
WHERE girls.name = %(name_1)s
"""
# 调用first()或者all(),则可以获取具体的Girls类的对象。里面的属性,如:name、age等等则存放了数据库表中取的值。
# 但是我们没有写__str__方法,所以打印的是一个类对象
print(query.first()) # <__main__.Girls object at 0x000000000AF57908>
# 我们可以手动查找属性
girl1 = query.first()
print(girl1.name) # satori
print(girl1.age) # 16
print(girl1.gender) # f
print(girl1.anime) # 动漫地灵殿
改
# 改和查比较类似,首先要查想要修改的记录
# 熟悉东方的小伙伴会发现,我手癌把东方地灵殿写成动漫地灵殿了,我们这里改回来
# 将数据库的对应记录获取出来了。
"""
之前说过,Girls这个模型对应数据库的一张表
Girls的一个实例对应数据库表中的一条记录
那么反过来同理,数据库表中的一条记录对应Girls的一个实例
我们通过修改实例的属性,再同步回去,就可以反过来修改数据库表中的记录
"""
# 获取相应记录对应的实例
girl2 = session.query(Girls).filter(Girls.anime == "动漫地灵殿").first()
# 修改属性
girl2.anime = "东方地灵殿"
# 然后提交,由于是改,所以不需要add
# 然后girl2这个实例就会映射回去,从而把对应字段修改
session.commit()
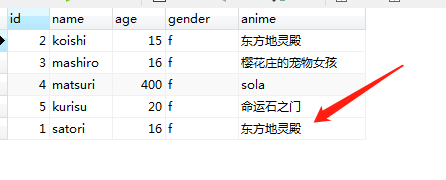
顺序无所谓啦,至少记录已经被我们修改了
删
# 筛选出要删除的字段
girl = session.query(Girls).filter(Girls.gender == "f").all()
for g in girl:
# 调用session.delete
session.delete(g)
# 同样需要提交
session.commit()

可以看到,数据库里面的数据全没了。为了后面介绍其他方法,我们再将数据重新写上去。
6.SQLAlchemy属性常用数据类型
- Integer:整形,映射到数据库是int类型
- Float:浮点型,映射到数据库是float类型,占32位。
- Boolean:布尔类型,传递True or False,映射到数据库是tinyint类型
- DECIMAL:顶点类型,一般用来解决浮点数精度丢失的问题
- Enum:枚举类型,指定某个字段只能是枚举中指定的几个值,不能为其他值,
- Date:传递datetime.date()进去,映射到数据库中是Date类型
- DateTime:传递datetime.datetime()进去,映射到数据库中是datatime类型
- String|VARCHAR:字符类型,映射到数据库中varchar类型
- Text:文本类型,可以存储非常长的文本
- LONGTEXT:长文本类型(只有mysql才有这种类型),可以存储比Text更长的文本
7.Column常用参数
- default:默认值,如果没有传值,则自动为我们指定的默认值
- nullable:是否可空,False的话,表示不可以为空,那么如果不传值则报错
- primary_key:是否为主键
- unique:是否唯一,如果为True,表示唯一,那么传入的值存在的话则报错
- autoincrement:是否自动增长
- name:该属性在数据库中的字段映射,如果不写,那么默认为赋值的变量名。
8.query查询
模型,指定查找这个模型中所有的对象
模型中的属性,可以指定查找模型的某几个属性
聚合函数
func.count:统计行的数量 func.avg:求平均值 func.max:求最大值 func.min:求最小值 func.sum:求总和
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, func
from sqlalchemy.orm import sessionmaker
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class Girls(Base):
__tablename__ = "girls"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(30))
age = Column(Integer)
gender = Column(VARCHAR(1))
anime = Column(VARCHAR(50))
def __str__(self):
return f"{self.name}-{self.age}-{self.gender}-{self.anime}"
Base.metadata.create_all()
# 创建Session类,绑定引擎
Session = sessionmaker(bind=engine)
# 实例化得到session对象,通过session来操作数据库的表
session = Session()
query = session.query(Girls).all()
print(query)
"""
[<__main__.Girls object at 0x000000000AF9F5C0>,
<__main__.Girls object at 0x000000000AF9F630>,
<__main__.Girls object at 0x000000000AF9F6A0>,
<__main__.Girls object at 0x000000000AF9F710>,
<__main__.Girls object at 0x000000000AF9F7B8>]
"""
for _ in query:
print(_)
"""
satori-16-f-动漫地灵殿
koishi-15-f-东方地灵殿
mashiro-16-f-樱花庄的宠物女孩
matsuri-400-f-sola
kurisu-20-f-命运石之门
"""
# 如果我不想一下子查出所有的字段,而是只要某几个字段,该怎么办呢?
# 只写调用模型.属性即可,那么到数据库就会选择相应的字段
print(session.query(Girls.name, Girls.age).all()) # [('satori', 16), ('koishi', 15), ('mashiro', 16), ('matsuri', 400), ('kurisu', 20)]
# 聚合函数
# 得到的query对象,直接打印是sql语句,加上first取第一个数据
print(session.query(func.count(Girls.name)).first()) # (5,)
print(session.query(func.avg(Girls.age)).first()) # (Decimal('93.4000000'),)
print(session.query(func.max(Girls.age)).first()) # (400,)
print(session.query(func.min(Girls.age)).first()) # (15,)
print(session.query(func.sum(Girls.age)).first()) # (467,)
9.filter方法常用过滤条件
为了演示,我将表删除重新创建,添加新的数据

from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, and_, or_
from sqlalchemy.orm import sessionmaker
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class Girls(Base):
__tablename__ = "girls"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(30))
age = Column(Integer)
gender = Column(VARCHAR(1))
anime = Column(VARCHAR(50))
def __str__(self):
return f"{self.name}-{self.age}-{self.gender}-{self.anime}"
Base.metadata.create_all()
# 创建Session类,绑定引擎
Session = sessionmaker(bind=engine)
# 实例化得到session对象,通过session来操作数据库的表
session = Session()
# 1. ==
print(session.query(Girls).filter(Girls.age == 16).first())
"""
古明地觉-16-f-动漫地灵殿
"""
# 2.!=
print(session.query(Girls).filter(Girls.age != 16).first())
"""
四方茉莉-400-f-sola
"""
# 3.like,和sql里面的like一样。除此之外,还有ilike,表示不区分大小写
print([str(q) for q in session.query(Girls).filter(Girls.name.like("%宫%")).all()])
"""
['森宫苍乃-20-f-sola', '雨宫优子-16-f-悠久之翼', '宫村宫子-15-f-悠久之翼']
"""
print([str(q) for q in session.query(Girls).filter(Girls.name.like("_宫%")).all()])
"""
['森宫苍乃-20-f-sola', '雨宫优子-16-f-悠久之翼']
"""
# 4.in_,至于为什么多了多了一个_,这个bs4类似,为了避免和python里的关键字冲突。
print([str(q) for q in session.query(Girls).filter(Girls.age.in_([16, 400])).all()])
"""
['古明地觉-16-f-动漫地灵殿', '椎名真白-16-f-樱花庄的宠物女孩', '四方茉莉-400-f-sola', '春日野穹-16-f-缘之空', '雨宫优子-16-f-悠久之翼']
"""
# 5.notin_, Girls.age.notin_也等价于~Girls.age.in_
print([str(q) for q in session.query(Girls).filter(Girls.age.notin_([16, 20, 400])).all()])
"""
['立华奏-18-f-angelbeats', '古河渚-19-f-Clannad', '坂上智代-18-f-Clannad', '古明地恋-15-f-东方地灵殿', '宫村宫子-15-f-悠久之翼']
"""
# 6.isnull
print(session.query(Girls).filter(Girls.age is None).first())
"""
None
"""
# 7.isnotnull
print(session.query(Girls).filter(Girls.age is not None).first())
"""
古明地觉-16-f-动漫地灵殿
"""
# 8.and_, from sqlachemy import and_
print(session.query(Girls).filter(and_(Girls.age == 16, Girls.anime == "樱花庄的宠物女孩")).first())
"""
椎名真白-16-f-樱花庄的宠物女孩
"""
# 9.or_, from sqlalchemy import or_
print([str(q) for q in session.query(Girls).filter(or_(Girls.age == 16, Girls.anime == "悠久之翼")).all()])
"""
['古明地觉-16-f-动漫地灵殿', '椎名真白-16-f-樱花庄的宠物女孩', '春日野穹-16-f-缘之空', '雨宫优子-16-f-悠久之翼', '宫村宫子-15-f-悠久之翼']
"""
# 10.count,统计数量
print(session.query(Girls).filter(Girls.age == 16).count()) # 4
# 11.切片
for g in session.query(Girls).filter(Girls.age == 16)[1: 3]:
print(g)
"""
椎名真白-16-f-樱花庄的宠物女孩
春日野穹-16-f-缘之空
"""
# 12.startswith
for g in session.query(Girls).filter(Girls.anime.startswith("悠久")):
print(g)
"""
雨宫优子-16-f-悠久之翼
宫村宫子-15-f-悠久之翼
"""
# 13.endswith
for g in session.query(Girls).filter(Girls.anime.endswith("孩")):
print(g)
"""
椎名真白-16-f-樱花庄的宠物女孩
"""
# 14.+ - * /
for g in session.query(Girls.name, Girls.age, Girls.age+3).filter((Girls.age + 3) >= 20).all():
print(g)
"""
('四方茉莉', 400, 403)
('牧濑红莉栖', 20, 23)
('立华奏', 18, 21)
('古河渚', 19, 22)
('坂上智代', 18, 21)
('森宫苍乃', 20, 23)
"""
# 15.concat
for g in session.query(Girls.name, Girls.anime.concat('a').concat('b')).all():
print(g)
"""
('古明地觉', '动漫地灵殿ab')
('椎名真白', '樱花庄的宠物女孩ab')
('四方茉莉', 'solaab')
('牧濑红莉栖', '命运石之门ab')
('春日野穹', '缘之空ab')
('立华奏', 'angelbeatsab')
('古河渚', 'Clannadab')
('坂上智代', 'Clannadab')
('古明地恋', '东方地灵殿ab')
('森宫苍乃', 'solaab')
('雨宫优子', '悠久之翼ab')
('宫村宫子', '悠久之翼ab')
"""
# 16.between,等价于and_(Girls.age >= 17, Girls.age <= 21)
for g in session.query(Girls).filter(Girls.age.between(17, 21)).all():
print(g)
"""
牧濑红莉栖-20-f-命运石之门
立华奏-18-f-angelbeats
古河渚-19-f-Clannad
坂上智代-18-f-Clannad
森宫苍乃-20-f-sola
"""
# 17.contains,等价于Girls.anime.like("%la%")
for g in session.query(Girls).filter(Girls.anime.contains("la")):
print(g)
"""
四方茉莉-400-f-sola
古河渚-19-f-Clannad
坂上智代-18-f-Clannad
森宫苍乃-20-f-sola
"""
# 18.distinct
for g in session.query(Girls.anime.distinct()):
print(g)
"""
('angelbeats',)
('sola',)
('悠久之翼',)
('缘之空',)
('东方地灵殿',)
('命运石之门',)
('Clannad',)
('动漫地灵殿',)
('樱花庄的宠物女孩',)
"""
10.外键及其四种约束
在mysql、postgresql等数据库中,外键可以使表之间的关系更加紧密。而SQLAlchemy中也同样支持外键,通过ForforeignKey来实现,并且可以指定表的外键约束
外键约束有以下几种:
- 1.RESTRICT:父表数据被删除,会阻止删除
- 2.No Action:在postgresql中,等价于RESTRICT
- 3.CASCADE:级联删除
- 4.SET NULL:父表数据被删除,字表数据被设置为NULL
既然如此的话,我们是不是要有两张表啊,我这里新创建两张表
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey
from sqlalchemy.orm import sessionmaker
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
# 我现在新建两张表
# 表People--表language ==》父表--子表
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
class Language(Base):
__tablename__ = "Language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(VARCHAR(20), nullable=False)
# 还记得约束的种类吗
# 1.RESTRICT:父表删除数据,会阻止。
'''
因为在子表中,引用了父表的数据,如果父表的数据删除了,那么字表就会懵逼,不知道该找谁了。
'''
# 2.NO ACTION
'''
和RESTRICT作用类似
'''
# 3.CASCADE
'''
级联删除:Language表的pid关联了People表的id。如果People中id=1的记录被删除了,那么Language中对应的pid=1的记录也会被删除
就是我们关联了,我的pid关联了你的id,如果你删除了一条记录,那么根据你删除记录的id,我也会相应的删除一条,要死一块死。
'''
# 4.SET NULL
'''
设置为空:和CASCADE类似,就是我的pid关联你的id,如果id没了,那么pid会被设置为空,不会像CASCADE那样,把相应pid所在整条记录都给删了
'''
# 这个pid关联的是People表里面的id,所以要和People表里的id属性保持一致
# 注意这里的People是表名,不是我们的类名,怪我,把两个写成一样的了
pid = Column(Integer, ForeignKey("People.id", ondelete="RESTRICT")) # 引用的表.引用的字段,约束方式
Base.metadata.create_all()
# 然后添加几条记录吧
Session = sessionmaker(bind=engine)
session = Session()
session.add_all([People(name="Guido van Rossum", age=62),
People(name="Dennis Ritchie", age=77),
People(name="James Gosling", age=63),
Language(name="Python", birthday=1991, type="解释型", pid=1),
Language(name="C", birthday=1972, type="编译型", pid=2),
Language(name="Java", birthday=1995, type="解释型", pid=3)])
session.commit()

我们下面删除数据,直接在Navicat里面演示

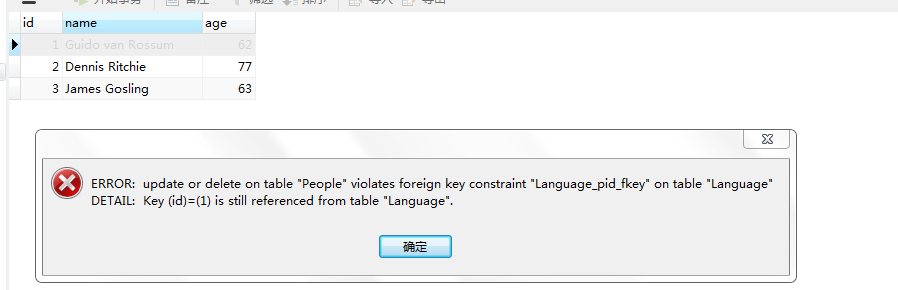
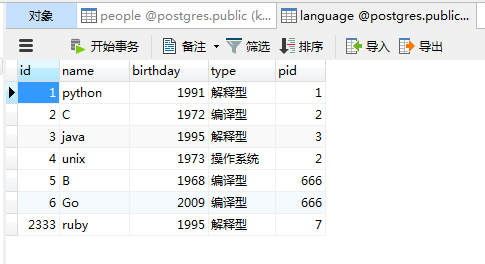
显示无法删除,因为在Language表中,pid关联了该表的id。而pid和id保持了一致,所以无法删除。换句话说,如果这里id=1,在字表中也有pid=1,那么这里的记录是无法删除的。
如果将字表中pid=1的记录进行修改,把pid=1改成pid=10,这样父表中id=1,在子表就没有pid与之对应了。但是:
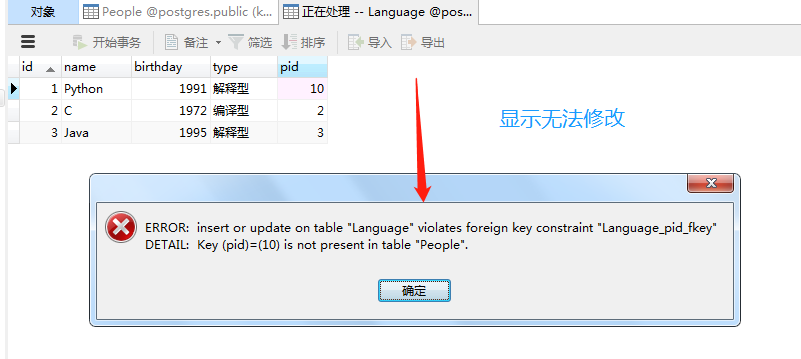
剩下的便不再演示了,都是比较类似的。另外,如果再ForeignKey中不指定ondelete,那么默认就是RESTRICT
11.ORM层外键和一对多关系
当一张表关联了另一张表的外键,我们可以根据子表中pid,从而找到父表与之对应的id的所在的记录。
但是有没有方法,能够直接通过子表来查询父表的内容呢?可以使用relationship
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class People(Base):
# 这里把表名改成小写,不然和类名一样,容易引起歧义
__tablename__ = "people"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
class Language(Base):
__tablename__ = "language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(VARCHAR(20), nullable=False)
# 这里的people.id指定的是数据库中people表的id字段
pid = Column(Integer, ForeignKey("people.id", ondelete="RESTRICT"))
# 如果我想通过Language表查询People表的数据呢?
# 可以通过relationship进行关联,表示关联的是数据库中的people表
# 然后取出language表中的记录,便可以通过 .父表.xxx 去取people表中的内容
# 这里的填入的不再是people表的表名了,而是对应的模型,也就是我们定义的People这个类,以字符串的形式
# 因为我们打印值,肯定是将数据库表的记录变成模型的实例来获取并打印的。
父表 = relationship("People")
# 删了重新创建
Base.metadata.drop_all()
Base.metadata.create_all()
# 然后添加几条记录吧
Session = sessionmaker(bind=engine)
session = Session()
session.add_all([People(name="Guido van Rossum", age=62),
People(name="Dennis Ritchie", age=77),
People(name="James Gosling", age=63),
Language(name="Python", birthday=1991, type="解释型", pid=1),
Language(name="C", birthday=1972, type="编译型", pid=2),
Language(name="Java", birthday=1995, type="解释型", pid=3)])
session.commit()
for obj in session.query(Language).all():
# obj获取的便是language表中的记录,可以找到在父表中id与字表的pid相对应的记录
print(obj.父表.name, "发明了", obj.name)
"""
Guido van Rossum 发明了 Python
Dennis Ritchie 发明了 C
James Gosling 发明了 Java
"""
目前数据是一对一的,我们也可以一对多
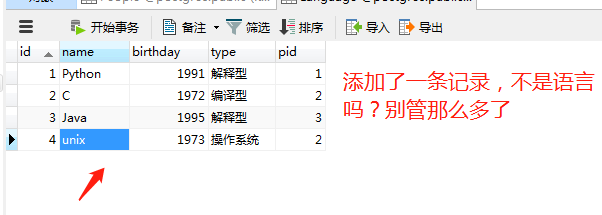
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class People(Base):
# 这里把表名改成小写,不然和类名一样,容易引起歧义
__tablename__ = "people"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
# 在父表中关联子表
子表 = relationship("Language")
def __str__(self):
return f"{self.name}--{self.age}--{self.字表}"
class Language(Base):
__tablename__ = "language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(VARCHAR(20), nullable=False)
# 这里的people.id指定的是数据库中people表的id字段
pid = Column(Integer, ForeignKey("people.id", ondelete="RESTRICT"))
父表 = relationship("People")
def __str__(self):
return f"{self.name}--{self.birthday}--{self.type}"
Session = sessionmaker(bind=engine)
session = Session()
for obj in session.query(Language).all():
print(obj.父表.name, "发明了", obj.name)
"""
Guido van Rossum 发明了 python
Dennis Ritchie 发明了 C
James Gosling 发明了 java
Dennis Ritchie 发明了 unix
"""
# 我们来遍历父表,那么由于我在父表中关联了字表
# 那么也可以通过父表来找到字表
for obj in session.query(People).all():
print(obj.子表)
"""
[<__main__.Language object at 0x000000000AFF4278>]
[<__main__.Language object at 0x000000000AFF4320>, <__main__.Language object at 0x000000000AFF4390>]
[<__main__.Language object at 0x000000000AFF4438>]
"""
# 因为父表的id是唯一的,不会出现字表的一条记录对应父表中多条记录
# 但是反过来是完全可以的,因此这里打印的是一个列表,即便只有一个元素,还是以列表的形式打印
for obj in session.query(People).all():
for o in obj.子表:
print(o)
"""
python--1991--解释型
C--1972--编译型
unix--1973--操作系统
java--1995--解释型
"""
可以看到,我们能通过在子表中定义relationship("父表模型"),这样查询子表,也可以通过子表来看父表的记录。那么同理,我也可以在父表中定义relations("子表模型"),查询父表,也可以通过父表来看子表的记录
但是这样还是有点麻烦,所以在relationship中还有一个反向引用
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class People(Base):
# 这里把表名改成小写,不然和类名一样,容易引起歧义
__tablename__ = "people"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
# 我把这行代码注释掉了
# 子表 = relationship("Language")
def __str__(self):
return f"{self.name}--{self.age}"
class Language(Base):
__tablename__ = "language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(VARCHAR(20), nullable=False)
# 这里的people.id指定的是数据库中people表的id字段
pid = Column(Integer, ForeignKey("people.id", ondelete="RESTRICT"))
# 我在子表(或者说子表对应的模型)的relationship中指定了backref="我屮艸芔茻"
# 就等价于在父表对应的模型中,指定了 我屮艸芔茻=relationship("Language")
父表 = relationship("People", backref="我屮艸芔茻")
def __str__(self):
return f"{self.name}--{self.birthday}--{self.type}"
Session = sessionmaker(bind=engine)
session = Session()
for obj in session.query(Language).all():
print(obj.父表.name, "发明了", obj.name)
"""
Guido van Rossum 发明了 python
Dennis Ritchie 发明了 C
James Gosling 发明了 java
Dennis Ritchie 发明了 unix
"""
for obj in session.query(People).all():
for o in obj.我屮艸芔茻:
print(o)
"""
python--1991--解释型
C--1972--编译型
unix--1973--操作系统
java--1995--解释型
"""
依旧是可以访问成功的
12.一对一关系实现
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class People(Base):
# 这里把表名改成小写,不然和类名一样,容易引起歧义
__tablename__ = "people"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
# 我把这行代码注释掉了
# 子表 = relationship("Language")
def __str__(self):
return f"{self.name}--{self.age}"
class Language(Base):
__tablename__ = "language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(VARCHAR(20), nullable=False)
# 这里的people.id指定的是数据库中people表的id字段
pid = Column(Integer, ForeignKey("people.id", ondelete="RESTRICT"))
# 我在子表(或者说子表对应的模型)的relationship中指定了backref="我屮艸芔茻"
# 就等价于在父表对应的模型中,指定了 我屮艸芔茻=relationship("Language")
父表 = relationship("People", backref="我屮艸芔茻")
def __str__(self):
return f"{self.name}--{self.birthday}--{self.type}"
Session = sessionmaker(bind=engine)
session = Session()
# 在父表people添加一条属性
# 在子表language中添加两条属性
people = People(id=666, name="KenThompson", age=75)
language1 = Language(id=5, name="B", birthday=1968, type="编译型", pid=666)
language2 = Language(id=6, name="Go", birthday=2009, type="编译型", pid=666)
# 由于People和Language是关联的,并且通过"people.我屮艸芔茻"可以访问到Language表的属性
# 那么可以通过people.我屮艸芔茻.append将Language对象添加进去
people.我屮艸芔茻.append(language1)
people.我屮艸芔茻.append(language2)
# 那么我只需要提交people即可,会自动提交language1和language2
session.add(people)
session.commit()

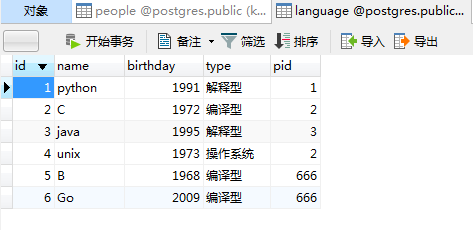
可以看到添加people的同时,language1和language2也被成功地添加进去了
通过往父表添加记录的同时,把子表的记录也添进去叫做正向添加。同理,如果在往子表添加记录的时候,把父表的记录也添加进去,叫做反向添加
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class People(Base):
# 这里把表名改成小写,不然和类名一样,容易引起歧义
__tablename__ = "people"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
# 我把这行代码注释掉了
# 子表 = relationship("Language")
def __str__(self):
return f"{self.name}--{self.age}"
class Language(Base):
__tablename__ = "language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(VARCHAR(20), nullable=False)
# 这里的people.id指定的是数据库中people表的id字段
pid = Column(Integer, ForeignKey("people.id", ondelete="RESTRICT"))
# 我在子表(或者说子表对应的模型)的relationship中指定了backref="我屮艸芔茻"
# 就等价于在父表对应的模型中,指定了 我屮艸芔茻=relationship("Language")
父表 = relationship("People", backref="我屮艸芔茻")
def __str__(self):
return f"{self.name}--{self.birthday}--{self.type}"
Session = sessionmaker(bind=engine)
session = Session()
people = People(id=7, name="松本行弘", age=53)
language = Language(id=2333, name="ruby", birthday=1995, type="解释型", pid=7)
"""
父表 = relationship("People", backref="我屮艸芔茻")
正向添加:
people.我屮艸芔茻.append(language)
反向添加:
language.父表 = people
"""
language.父表 = people
# 只需要添加language即可
session.add(language)
session.commit()
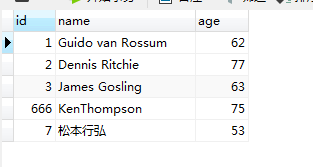
记录依旧可以添加成功
由于父表和字表可以是一对多,我们通过父表来查询子表那么得到的是一个列表,哪怕只有一个元素,得到的依旧是一个列表。可以如果我们已经知道只有一对一,不会出现一对多的情况,因此在获取通过父表获取子表记录的时候,得到的是一个值,而不再是只有一个元素的列表,该怎么办呢?
from sqlalchemy.orm import backref
父表 = relationship("People", backref=backref("我屮艸芔茻", uselist=False))
这时候添加数据的时候,就不再使用people.我屮艸芔茻.append(language)来添加了,因为是一对一。而是直接使用 people.我屮艸芔茻 = language来添加即可。
13.多对多关系实现
然而现实中,很多都是多对多的关系。比如博客园的文章,一个标签下可能会有多篇文章,同理一篇文章也可能会有多个标签。
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
# 既然要实现多对多,肯定要借助第三张表
# sqlalchemy已经为我们提供了一个Table,让我们去使用
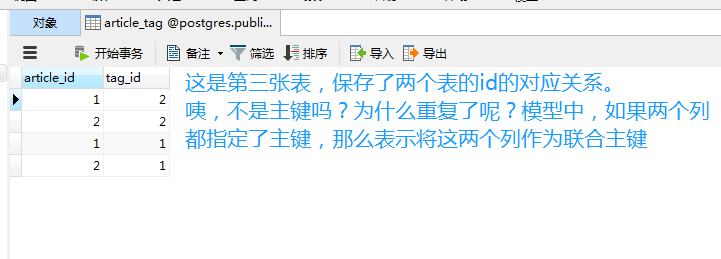
Article_Tag = Table("article_tag", Base.metadata,
# 一个列叫做article_id,关联article里面的id字段
Column("article_id", Integer, ForeignKey("article.id"), primary_key=True),
# 一个列叫做tag_id,关联tag里面的id字段
Column("tag_id", Integer, ForeignKey("tag.id"), primary_key=True)
)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
# 只需要在一个模型中,定义relationship即可,因为有反向引用。
# 通过Article().tags拿到对应的[tag1, tag2...],也可以通过Tag().articles拿到对应的[article1, article2]
tags = relationship("Tag", backref="articles", secondary=Article_Tag)
"""
或者在Tag中定义articles = relationship("Article", backref="tags", secondary=Article_Tag)
一样的道理,但是一定要指定中间表,secondary=Article_Tags
"""
class Tag(Base):
__tablename__ = "tag"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(50), nullable=False)
"""
总结一下:
1.先把两个需要多对多的模型建立出来
2.使用Table定义一个中间表,参数是:表名、Base.metadata、关联一张表的id的列、关联另一张表的id的列。并且都做为主键
3.在两个需要做多对多的模型中随便选择一个模型,定义一个relationship属性,来绑定三者之间的关系,在使用relationship的时候,需要传入一个secondary="中间表"
"""
Base.metadata.create_all()
添加数据
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
Article_Tag = Table("article_tag", Base.metadata,
Column("article_id", Integer, ForeignKey("article.id"), primary_key=True),
Column("tag_id", Integer, ForeignKey("tag.id"), primary_key=True)
)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
tags = relationship("Tag", backref="articles", secondary=Article_Tag)
def __str__(self):
return f"{self.title}"
class Tag(Base):
__tablename__ = "tag"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(50), nullable=False)
def __str__(self):
return f"{self.name}"
Base.metadata.create_all()
article1 = Article(title="article1")
article2 = Article(title="article2")
tag1 = Tag(name="tag1")
tag2 = Tag(name="tag2")
# 每一篇文章,添加两个标签
article1.tags.append(tag1)
article1.tags.append(tag2)
article2.tags.append(tag1)
article2.tags.append(tag2)
Session = sessionmaker(bind=engine)
session = Session()
# 只需添加article即可,tag会被自动添加进去
session.add_all([article1, article2])
session.commit()

获取数据
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
Article_Tag = Table("article_tag", Base.metadata,
Column("article_id", Integer, ForeignKey("article.id"), primary_key=True),
Column("tag_id", Integer, ForeignKey("tag.id"), primary_key=True)
)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
tags = relationship("Tag", backref="articles", secondary=Article_Tag)
def __str__(self):
return f"{self.title}"
class Tag(Base):
__tablename__ = "tag"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(50), nullable=False)
def __str__(self):
return f"{self.name}"
Session = sessionmaker(bind=engine)
session = Session()
# 获取tag表的第一行
tag = session.query(Tag).first()
# 通过tag.articles获取对应的article表的内容
print([str(obj) for obj in tag.articles]) # ['article1', 'article2']
# 获取article表的第一行
article = session.query(Article).first()
# 通过article.tags获取对应的tag表的内容
print([str(obj) for obj in article.tags]) # ['tag1', 'tag2']
# 可以看到数据全部获取出来了
14.ORM层面删除数据注意事项
我们知道一旦关联,那么删除父表里面的数据是无法删除的,只能先删除字表的数据,然后才能删除关联的父表数据。如果在orm层面的话,可以直接删除父表数据,因为这里等同于两步。先将字表中关联的字段设置为NULL,然后删除父表中的数据
我们将表全部删除,建立新表。
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(VARCHAR(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
# uid是为了建立外键,我们要和use表的id进行关联,所以类型也要和user表的id保持一致
uid = Column(Integer, ForeignKey("user.id"))
# 这个是为了我们能够通过一张表访问到另外一张表
# 以后User对象便可以通过articles来访问Articles对象的属性,Article对象也可以通过author访问User对象的属性
author = relationship("User", backref="articles")
Base.metadata.create_all()
Session = sessionmaker(bind=engine)
session = Session()
# 创建几条记录
user = User(id=1, username="guido van rossum")
article = Article(title="Python之父谈论python的未来", uid=1)
article.author = user
# 然后使用session添加article即可,会自动添加user
session.add(article)
session.commit()
我们在数据库层面删除一下数据
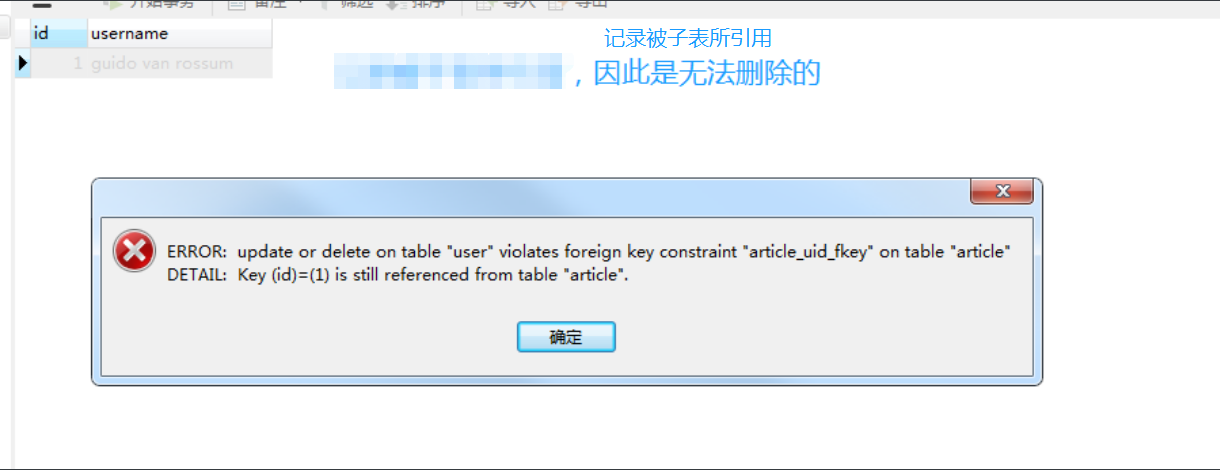
我们来试试从orm层面删除数据
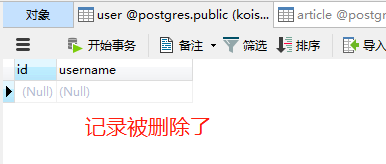
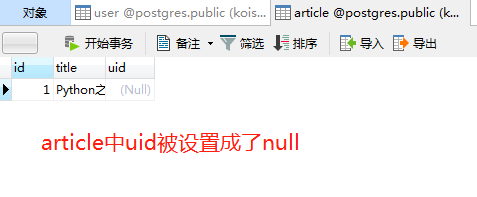
删除父表的数据,这个过程相当于先将article中的uid设置为Null,然后删除父表的数据。但是这样也有危险,如果不熟悉sqlalchemy的话,会造成不可避免的后果,怎么办呢?直接将uid设置为不可为空即可即可, 加上nullable=False
15.relationship中的cascade属性
orm层面的cascade:
首先我们知道如果如果数据库的外键设置为RESTRICT,那么在orm层面,如果删除了父表的数据,字表的数据将会被设置为NULL,如果想避免这一点,那么只需要将nullable设置为False即可
但是在SQLAlchemy中,我们只需要将一个数据添加到session中,提交之后,与其关联的数据也被自动地添加到数据库当中了,这是怎么办到的呢?其实是通过relationship的时候,其关键字参数cascade设置了这些属性:
- 1.save-update:默认选项,在添加一条数据的时候,会自动把与其相关联的数据也添加到数据库当中。这种行为就是save-update所影响的
- 2.delete:表示删除某一个模型的数据时,是否也删掉使用relationship与其相关联的数据。
- 3.delete-orphan:表示当对一个orm对象解除了父表中的关联对象的时候,自己便会被删掉。当然父表中的数据被删除了,自己也会被删除。这个选项只能用在一对多上,不能用在多对多以及多对一上。并且还需要在子模型的relationship中,添加一个single_parent=True的选项
- 4.merge:默认选项,当使用session.merge选项合并一个对象的时候,会将使用了relationship相关联的对象也进行merge操作
- 5.expunge:移除操作的时候,会将相关联的对象也进行移除。这个操作只会从session中删除,并不会从数据库当中移除
- 6.all:以上五种情况的总和
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(VARCHAR(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
# 其他不变,这里显示的指定了cascade="",那么便不会再使用默认地save-update了
author = relationship("User", backref="articles", cascade="")
Base.metadata.drop_all()
Base.metadata.create_all()
Session = sessionmaker(bind=engine)
session = Session()
# 创建几条记录
user = User(username="guido van rossum")
article = Article(title="Python之父谈论python的未来")
article.author = user
# 然后使用session添加article即可,此时就不会添加user了
session.add(article)
session.commit()

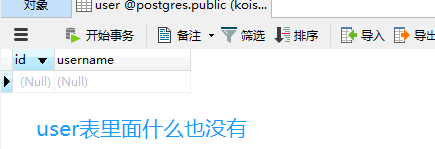
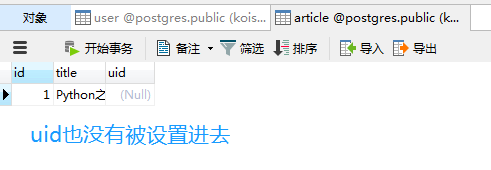
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(VARCHAR(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
# 指定save-update和delete,以逗号分隔即可
author = relationship("User", backref="articles", cascade="save-update,delete")
Base.metadata.drop_all()
Base.metadata.create_all()
Session = sessionmaker(bind=engine)
session = Session()
# 创建几条记录
user = User(username="guido van rossum")
article = Article(title="Python之父谈论python的未来")
article.author = user
# 然后使用session添加article即可,此时就不会添加user了
session.add(article)
session.commit()
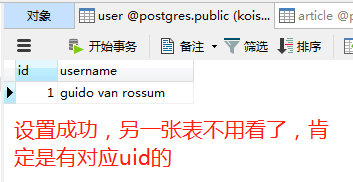
现在添加数据是没问题的,但是删除数据呢?如果是默认情况的话,那么删除父表的记录会将字表对应的记录设为空,但如果删除子表的记录,是不会影响父表的。可现在我在cascade加上了delete,那么再删除子表中的记录呢?
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(VARCHAR(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
# 指定save-update和delete,以逗号分隔即可
author = relationship("User", backref="articles", cascade="save-update,delete")
Session = sessionmaker(bind=engine)
session = Session()
article = session.query(Article).first()
session.delete(article)
session.commit()
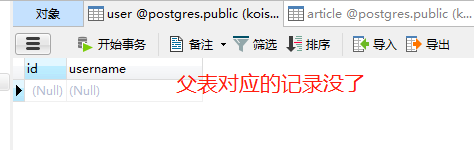

16.排序
- 正序:session.query(Model).order_by("table.column").all()
- 倒叙:session.query(Model).order_by("table.column.desc").all()
此外可以在模型中定义
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
age = Column(Integer)
# 就以User为例,在SQLAlchemy中有一个属性叫做__mapper_args__
# 是一个字典,我们可以指定一个叫做order_by的key,value则为一个字段
__mapper_args__ = {"order_by": age}
# 倒序的话,__mapper_args__ = {"order_by": age.desc()}
# 以后再查找的时候直接session.query(table).all()即可,自动按照我们指定的排序
17.limit、offset以及切片操作
- limit:session.query(Model).limit(10).all 从开头开始取十条数据
- offset:session.query(Model).offset(10).limit(10).all() 从第十条开始取10条数据
- slice:session.query(Model).slice(1,8).all() 从第一条开始取到第七条数据,或者session.query(Model)[1:8],这样更简单,连all()都不用了
18.数据查询懒加载技术
在一对一或者多对多的时候,如果想要获取多的这一部分数据的时候,往往通过一个属性就可以全部获取了。比如有一个作者,我们要获取这个作者的所有文章,那么通过user.articles就可以全部获取了,但是有时我们不想获取所有的数据,比如只获取这个作者今天发表的文章,那么这个时候就可以给relationship中的backref传递一个lazy=“dynamic”,以后通过user.articles获取到的就不是一个列表,而是一个AppendQuery对象了。以后就可以对这个对象再进行过滤和排序工作。
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(VARCHAR(50), nullable=False)
age = Column(Integer)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
author = relationship("User", backref=backref("articles"))
def __str__(self):
return f"{self.title}"
Base.metadata.drop_all()
Base.metadata.create_all()
Session = sessionmaker(bind=engine)
session = Session()
user = User(username="guido", age=63)
for i in range(10):
article = Article(title=f"title{i}")
article.author = user
session.add(article)
session.commit()
user = session.query(User).first()
for art in user.articles:
print(art)
"""
title0
title1
title2
title3
title4
title5
title6
title7
title8
title9
"""
以上获取了全部数据,如果指向获取一部分呢?
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(VARCHAR(50), nullable=False)
age = Column(Integer)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
# 如果获取部分数据, 只需要加上一个lazy="dynamic"即可
# 注意这里一定要写在backref里面,我们的目的是为了通过User模型实例取Article模型实例的属性,要写在backref里面
# 同理backref=backref("articles")和backref="articles"是一样的,但是之所以要加上里面的这个backref,是为了给user提供更好的属性,比如这里的懒加载
author = relationship("User", backref=backref("articles", lazy="dynamic"))
def __str__(self):
return f"{self.title}"
Base.metadata.drop_all()
Base.metadata.create_all()
Session = sessionmaker(bind=engine)
session = Session()
user = User(username="guido", age=63)
for i in range(10):
article = Article(title=f"title{i}")
article.author = user
session.add(article)
session.commit()
user = session.query(User).first()
print(user.articles)
"""
SELECT article.id AS article_id, article.title AS article_title, article.uid AS article_uid
FROM article
WHERE %(param_1)s = article.uid
"""
# 此时打印的是一个sql语句,如果不加lazy="dynamic"的话,打印的是一个列表,准确的说是InstrumentList对象,里面存储了很多的Article对象
# 但是现在不再是了,加上lazy="dynamic"之后,得到的是一个AppendQuery对象。
# 可以对比列表和生成器,只有执行的时候才会产出值
print(type(user.articles)) # <class 'sqlalchemy.orm.dynamic.AppenderQuery'>
# 查看一下源码发现,AppenderQuery这个类继承在Query这个类,也就是说Query可使用的,它都能使用
# 而user.articles已经是一个Query对象了,相当于session.query(XXX),可以直接调用filter
print([str(obj) for obj in user.articles.filter(Article.id > 5).all()]) # ['title5', 'title6', 'title7', 'title8', 'title9']
# 也可以动态添加数据
article = Article(title="100")
user.articles.append(article)
# 这个时候不需要add,只需要commit即可,因为这个user已经在里面了
# 我们append之后,只需要commit,那么append的新的article就提交到数据库里面了
session.commit()
# 继续获取
print([str(obj) for obj in user.articles.filter(Article.id > 5).all()]) # ['title5', 'title6', 'title7', 'title8', 'title9', '100']
"""
lazy有以下选择:
1.select:默认选项,以user.articles为例,如果没有访问user.articles属性,那么SQLAlchemy就不会从数据库中查找文章。一旦访问,就会查找所有文章,最为InstrumentList返回
2.dynamic:返回的不是一个InstrumentList,而是一个AppendQuery对象,类似一个生成器,可以动态添加,查找等等。
主要使用
"""
19.group_by和having字句
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, Enum, func
from sqlalchemy.orm import sessionmaker
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
Session = sessionmaker(bind=engine)
session = Session()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(VARCHAR(50), nullable=False)
age = Column(Integer)
# 注意:类型为Enum的时候,一定要指定name
gender = Column(Enum("male", "female", "secret", default="male", name="我擦"))
Base.metadata.drop_all()
Base.metadata.create_all()
user1 = User(username="神田空太", age=16, gender="male")
user2 = User(username="椎名真白", age=16, gender="female")
user3 = User(username="四方茉莉", age=400, gender="female")
user4 = User(username="木下秀吉", age=15, gender="secret")
user5 = User(username="牧濑红莉栖", age=18, gender="female")
session.add_all([user1, user2, user3, user4, user5])
session.commit()
# group_by:分组,比方说我想查看每个年龄对应的人数
print(session.query(User.age, func.count(User.id)).group_by(User.age).all())
'''
输出结果:
[(16, 2), (400, 1), (15, 1), (18, 1)
'''
# having:在group_by分组的基础上进行进一步查询,比方说我想查看年龄大于16的每一个年龄段对应的人数
print(session.query(User.age, func.count(User.id)).group_by(User.age).having(User.age > 16).all())
'''
输出结果:
[(18, 1), (400, 1)]
'''
# 想查看人数大于1的那一组
print(session.query(User.age, func.count(User.id)).group_by(User.age).having(func.count(User.id) > 1).all())
"""
输出结果:
[(16, 2)]
"""
20.join实现复杂查询
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
Session = sessionmaker(bind=engine)
session = Session()
class People(Base):
__tablename__ = "people"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(VARCHAR(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
uid = Column(Integer, ForeignKey("people.id"))
author = relationship("People", backref=backref("articles", lazy="dynamic"))
def __repr__(self):
return f"{self.title}"
Base.metadata.drop_all()
Base.metadata.create_all()
people1 = People(username="guido")
people2 = People(username="ken")
article1 = Article(title="python")
article1.author = people1
article2 = Article(title="B")
article2.author = people2
article3 = Article(title="go")
article3.author = people2
session.add_all([article1, article2, article3])
session.commit()

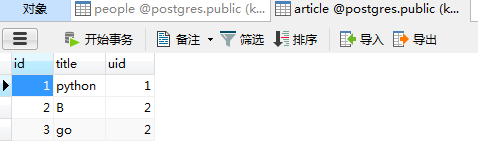
此时两张表建立完成,数据已经添加成功
先在数据库层面上进行查询,查询每个作者发表了多少文章
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, func
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
Session = sessionmaker(bind=engine)
session = Session()
class People(Base):
__tablename__ = "people"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(VARCHAR(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(50), nullable=False)
uid = Column(Integer, ForeignKey("people.id"))
author = relationship("People", backref=backref("articles", lazy="dynamic"))
def __repr__(self):
return f"{self.title}"
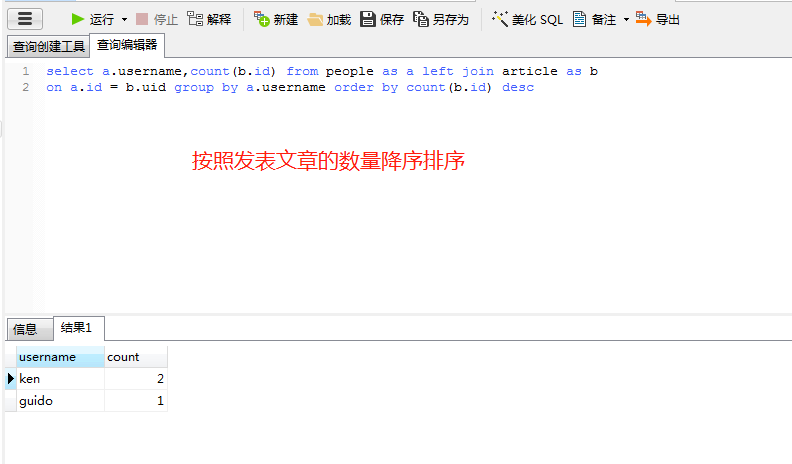
# 找到所有用户,按照发表文章的数量进行排序
# 此外还可以为字段起一个别名,比如把筛选出来的username改为姓名,可以调用People.username.label("姓名")
# 如果不指定别名,那么sqlachemy会默认将类名、下划线、字段名进行组合作为别名,
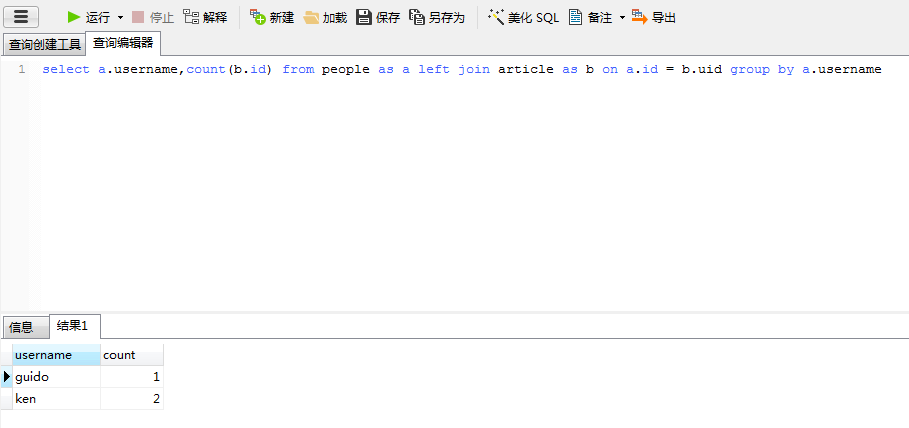
res = session.query(People.username, func.count(Article.id)).join(Article, People.id == Article.uid).\
group_by(People.id).order_by(func.count(Article.id))
print(res)
"""
SELECT people.username AS people_username, count(article.id) AS count_1
FROM people JOIN article ON people.id = article.uid GROUP BY people.id ORDER BY count(article.id)
"""
res = session.query(People.username.label("姓名"), func.count(Article.id).label("次数")).join(Article, People.id == Article.uid).\
group_by(People.id).order_by("次数")
print(res)
"""
SELECT people.username AS "姓名", count(article.id) AS "次数"
FROM people JOIN article ON people.id = article.uid GROUP BY people.id ORDER BY "次数"
"""
print(res.all()) # [('guido', 1), ('ken', 2)]
21.subquery实现复杂查询
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, func
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
Session = sessionmaker(bind=engine)
session = Session()
class Girl(Base):
__tablename__ = "girl"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(50), nullable=False)
anime = Column(VARCHAR(50), nullable=False)
age = Column(Integer, nullable=False)
def __repr__(self):
return f"{self.name}--{self.anime}--{self.age}"
Base.metadata.create_all()
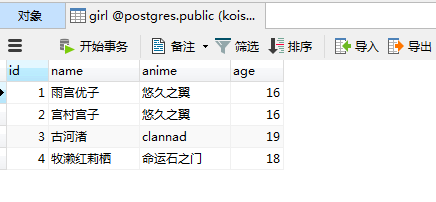
girl1 = Girl(name="雨宫优子", anime="悠久之翼", age=16)
girl2 = Girl(name="宫村宫子", anime="悠久之翼", age=16)
girl3 = Girl(name="古河渚", anime="clannad", age=19)
girl4 = Girl(name="牧濑红莉栖", anime="命运石之门", age=18)
session.add_all([girl1, girl2, girl3, girl4])
session.commit()
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, VARCHAR, ForeignKey, func
from sqlalchemy.orm import sessionmaker, relationship, backref
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
Session = sessionmaker(bind=engine)
session = Session()
class Girl(Base):
__tablename__ = "girl"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(50), nullable=False)
anime = Column(VARCHAR(50), nullable=False)
age = Column(Integer, nullable=False)
def __repr__(self):
return f"{self.name}--{self.anime}--{self.age}"
# 下面要寻找和雨宫优子在同一anime,并且age相同的记录,当然这里只有一条
girl = session.query(Girl).filter(Girl.name == "雨宫优子").first()
# filter里面如果没有指定and_或者or_,那么默认是and_
expect_girls = session.query(Girl).filter(Girl.anime == girl.anime, Girl.age == girl.age, Girl.name != "雨宫优子").all()
print(expect_girls) # [宫村宫子--悠久之翼--16]
这种查找方式,等于先筛选出name="雨宫优子"对应的记录,然后再从全表搜索出Girl.anime == girl.anime并且Girl.age == girl.age的记录,写成sql的话就类似于
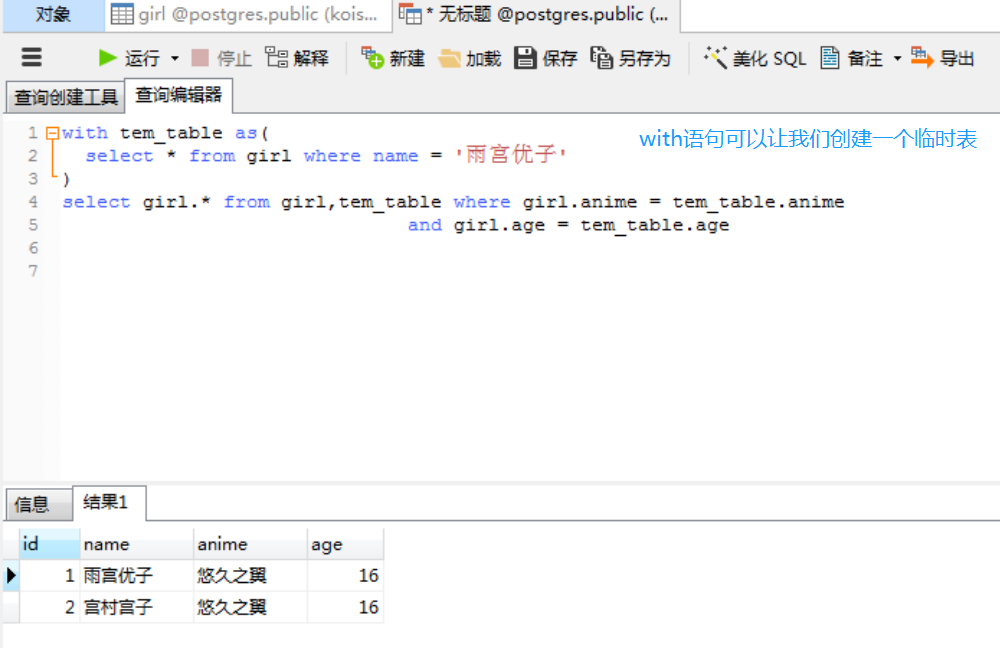
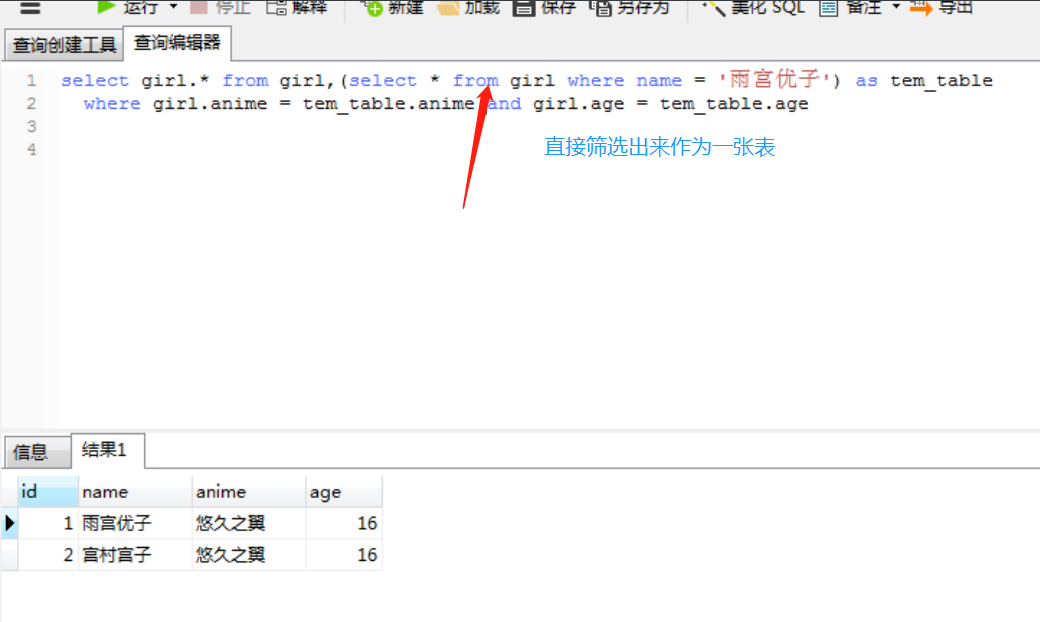
也可以使用subquery
# 创建一个subquery
girl = session.query(Girl).filter(Girl.name == "雨宫优子").subquery()
# 这里的girls.c的c代指的是column,是一个简写
expect_girls = session.query(Girl).filter(Girl.anime == girl.c.anime, Girl.age == girl.c.age, Girl.name != "雨宫优子").all()
print(expect_girls) # [宫村宫子--悠久之翼--16]
可以看到事实上没太大区别,貌似代码量还多了一丢丢。但是在数据库里面,我们只需要进行一次查询,效率会高一些
22.flask-sqlalchemy的使用
flask-sqlalchemy是flask的一个插件,可以更加方便我们去使用。sqlalchemy是可以独立于flask而存在的,这个插件是将sqlalchemy集成到flask里面来。我们之前使用sqlalchemy的时候,要定义Base,session,各个模型之类的,使用这个插件可以简化我们的工作。
这个插件首先需要安装,直接pip install flask-sqlalchemy即可。大家注意到没,flask虽然本身内容较少,但是有很多的第三方插件,扩展性极强。其实flask写到最后,感觉和Django没太大区别了。提到框架,首先想到的就是flask、Django、tornado,其中tornado是异步的。这里也主要想说的就是python中的异步框架,自从python3.5引入了async和await关键字、可以定义原生协程之后,python中的异步框架也是层出不穷,但是并没有一个怪兽级别的一步框架一统江湖。python中的tornado是一个,还有一个sanic,这是一个仿照flask接口设计的异步框架,只能部署在linux上,据说可以达到媲美go语言的性能,具体没有测试过,但缺点是第三方扩展没有flask这么多,质量也参差不齐。希望python能出现优秀的异步框架,目前的话还是推荐tornado,因为在python还没有引入原生协程的时候,就有了tornado,当时tornado是自己根据生成器实现协程、手动实现了一套事件循环机制。但是当python引入了原生的协程之后,我们在定义视图类的时候,就不需要在使用装饰器@tornado.gen.coroutine了,直接通过async def来定义函数即可,也不需要yield了,直接await即可,而且底层的事件循环也不再使用原来的哪一套了,而是直接使用的asyncio。目前异步框架,还是推荐tornado。
flask-sqlalchemy也是可以独立于flask而存在的,或者不以web的方式。
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
db_uri = f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}"
# 这个配置不直接与我们的SQLAlchemy这个类发生关系,而是要添加到app.config里面,这一步是少不了的
# 至于这里的key,作者规定就是这么写的
app = Flask(__name__)
app.config["SQLALCHEMY_DATABASE_URI"] = db_uri
# 并且还要加上这一段,不然会弹出警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
# 接收一个app,从此db便具有了app的功能,但我们只用数据库的功能
db = SQLAlchemy(app)
# 建立模型,肯定要继承,那么继承谁的,继承自db.Module,相当于之前的Base。这里操作简化了,不需要我们去创建了
class User(db.Model):
__tablename__ = "user"
# 可以看到,之前需要导入的通通不需要导入了,都在db下面。不过本质上调用的还是sqlalchemy模块里的类。
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(50), nullable=False)
class Article(db.Model):
__tablename__ = "article"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
title = db.Column(db.String(50), nullable=False)
uid = db.Column(db.Integer, db.ForeignKey("user.id"))
author = db.relationship("User", backref="articles")
# 所以我们发现这和SQLAlchemy框架中的使用方法基本上是一致的,只不过我们在SQLAlchemy中需要导入的,现在全部可以通过db来访问
# 那么如何映射到数据库里面呢?这里也不需要Base.metadata了,直接使用db即可。
db.create_all()
# 下面添加数据
user = User(name="guido")
article = Article(title="python之父谈python的未来")
user.articles.append(article)
# 这里的session也不需要创建了,因为在app中我们指定了SQLALCHEMY_DATABASE_URI
# 会自动根据配置创建session
db.session.add(user)
'''
或者
article.author = user
db.session.add(article)
'''
db.session.commit()
# 跟我们之前使用SQLAlchemy的流程基本一致

那么问题来了,如何查找数据呢?首先我们可以想到db.session.query(User),这毫无疑问是可以的,但是我们的模型继承了db.Model,那么我们有更简单的方法
# 直接使用User.query即可,就等价于db.session.query(User)
user = User.query.first()
print(user.name) # guido
print(user.articles[0].title) # python之父谈python的未来
'''
可以看到,使用方法和session.query(Model)没有啥区别
'''
23.alembic数据库迁移工具的使用
alembic是SQLAlchemy作者所写的一款用于做ORM与数据库的迁移和映射的一个框架,类似于git。
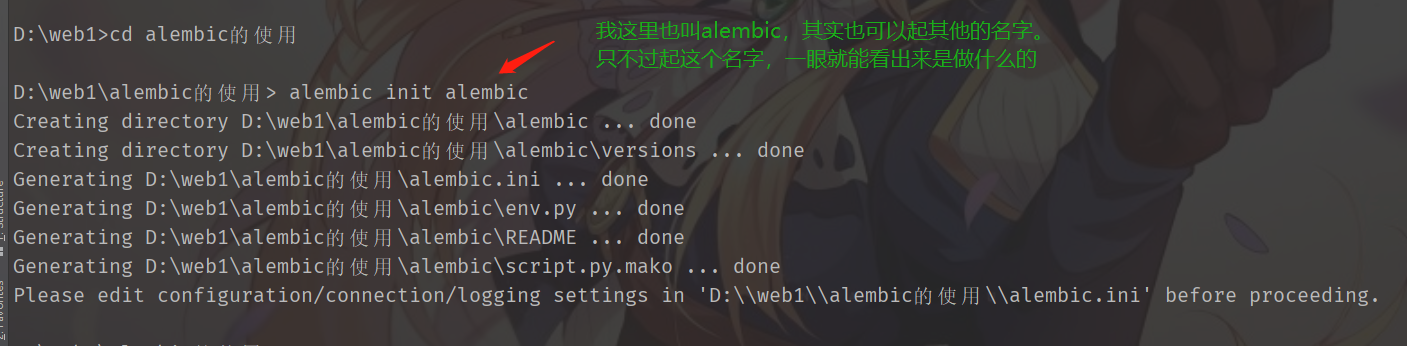
首先肯定要安装,pip install alembic

注意这个目录
进入文件夹里面,输入alembic init xxxx
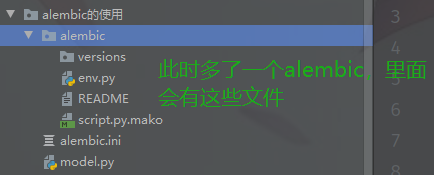
接下来建立模型,这个是独立于flask的,所以我们这次还是使用SQLAlchemy做演示
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, func
from sqlalchemy import Column, Integer, String
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class People(Base):
__tablename__ = "people"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
def __repr__(self):
return f"{self.name}--{self.age}"
下面修改配置文件,alembic.ini


然后修改env.py
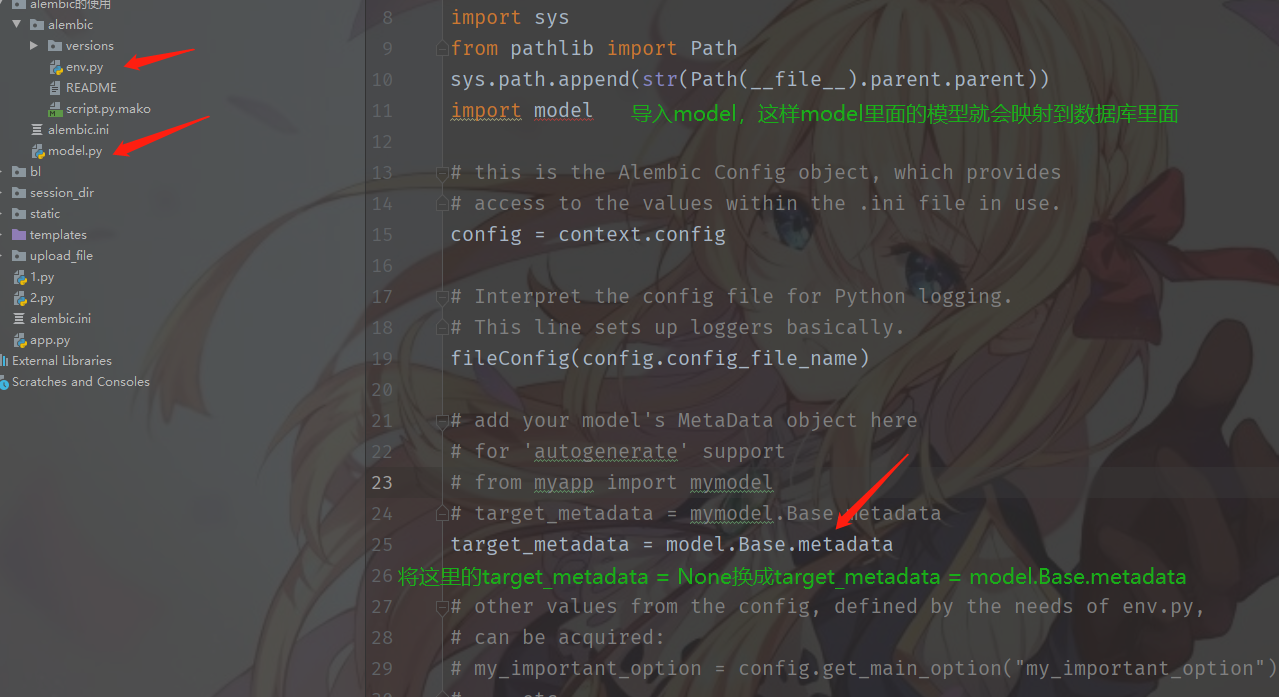
接下来生成迁移文件,alembic revision --autogenerate -m "message",这里的"message"是我们的注释信息
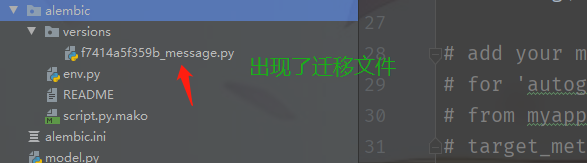
下面就要更新数据库了,将刚才生成的迁移文件映射到数据库。至于为什么需要迁移文件,那是因为无法直接映射orm模型,需要先转化为迁移文件,然后才能映射到数据库当中。
alembic upgrade head,将刚刚生成的迁移文件映射到数据库当中

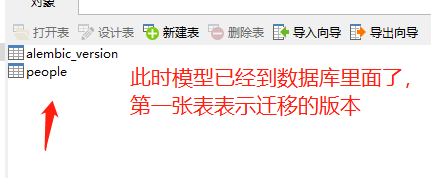
如果需要修改表的结构,不需要再drop_all,create_all了,如果里面有大量数据,不可能清空之后重新创建。那么在修改之后,直接再次生成迁移文件然后映射到数据库就可以了
先来看看数据库的表
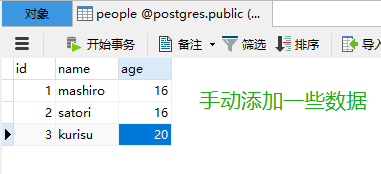
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, func
from sqlalchemy import Column, Integer, String
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
engine = create_engine(f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(bind=engine)
class People(Base):
__tablename__ = "people"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False)
age = Column(Integer, nullable=False)
serifu = Column(String(100)) # 增加一列
def __repr__(self):
return f"{self.name}--{self.age}"
我给模型添加了一个字段serifu,然后重新生成迁移文件,并再次映射
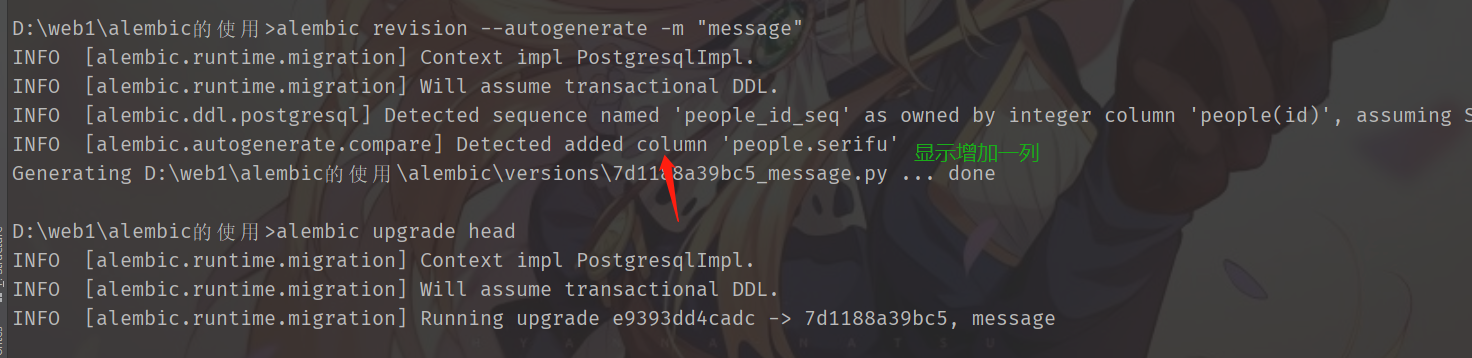

可以看到,自动增加了一列,并且原来的数据也没有被破坏。因此也可以发现,我们再增加列的时候,不能设置nullable=False,不然添加不进去
class People(Base):
__tablename__ = "people"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
serifu = Column(String(100), nullable=False) # 不添加默认值,设置不能为空
def __repr__(self):
return f"{self.name}--{self.age}"

总结一下,就是五个步骤:
- 1.定义好自己的模型
- 2.使用alembic init 仓库名,新建一个仓库,会在当前路径生成
- 3.修改两个配置文件,在alembic.ini中配置数据库的连接方式,在env中将model导入,再将target_metadata = None换成model里面的Base.metadata
- 4.使用alembic revision --autogenerate -m "message"生成迁移文件
- 5.使用alembic upgrade head将迁移文件映射到数据库
可以看出,和Django比较类似,如果以后修改了模型的话,那么重复4和5即可
24.alembic常用命令和经典错误解决办法
常用命令:
init:创建一个alembic仓库
revision:创建一个新的版本文件
--autogenerate:自动将当前模型的修改,生成迁移脚本
-m:本次迁移做了哪些修改,用户可以指定这个参数,方便回顾
upgrade:将指定版本的迁移文件映射到数据库中,会执行版本文件中的upgrade函数。如果有多个迁移脚本没有被映射到数据库中,那么会执行多个迁移脚本
[head]:代表最新的迁移脚本的版本号
downgrade:降级,我们每一个迁移文件都有一个版本号,如果想退回以前的版本,直接使用alembic downgrade version_id
heads:展示head指向的脚本文件
history:列出所有的迁移版本及其信息
current:展示当前数据库的版本号
经典错误:
FAILED:Target database is not up to date。原因:主要是heads和current不相同。current落后于heads的版本。解决办法:将current移动到head上,alembic upgrade head
FAILED:can’t locate revision identified by “78ds75ds7s”。原因:数据库中村的版本号不在迁移脚本文件中。解决办法:删除数据库中alembic_version表的数据,然后重新执行alembic upgrade head
执行upgrade head 时报某个表已经存在的错误。解决办法:1.删除version中所有的迁移文件的代码,修改迁移脚本中创建表的代码
25.flask-script讲解
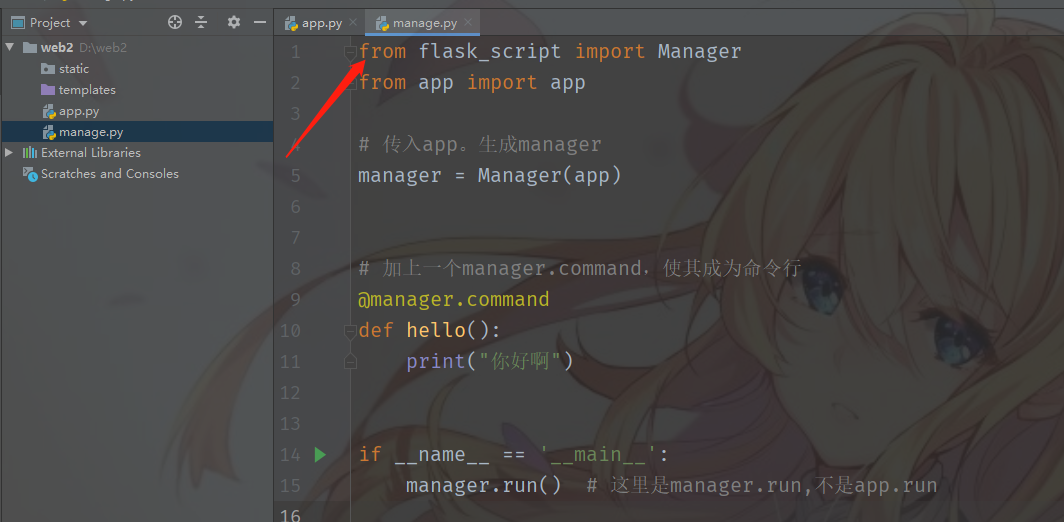
flask-script的作用是可以通过命令行的方式来操作flask。例如通过命令来跑一个开发版本的服务器,设置数据库,定时任务等等。要使用的话,首先要安装,pip install flask-script
然后要做什么呢?
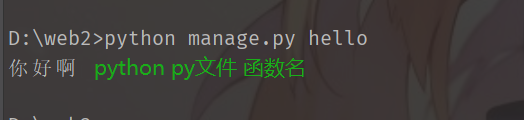
from flask_script import Manager
from app import app
# 传入app。生成manager
manager = Manager(app)
# 加上一个manager.command,使其成为命令行
@manager.command
def hello():
print("你好啊")
# 也可以添加参数,并且此时manager.command也可以不要了
@manager.option("--name", dest="username")
@manager.option("--age", dest="age")
def foo(username, age):
# 类似于python里的optparse,可以见我的python常用模块,里面有介绍
return f"name={username}, age={age}"
if __name__ == '__main__':
manager.run() # 这里是manager.run,不是app.run

将flask-script和alembic集成
start.py
from flask import Flask
app = Flask(__name__)
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
app.config["SQLALCHEMY_DATABASE_URI"] = f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}"
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
app.run()
model.py
from app import app
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy(app)
# 话说回来,这个db.Model就相当于之前的Base
# 我们将env里面的target_metadata = None,也可以换成db.Model.metadata
class User(db.Model):
__tablename__ = "user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.VARCHAR(100))
age = db.Column(db.Integer)
class Score(db.Model):
__tablename__ = "score"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
math = db.Column(db.Integer)
english = db.Column(db.Integer)
history = db.Column(db.Integer)
manage.py
from flask_script import Manager
from app import app
# 从模型里面导入User和Score模型,以及db
from model import User, Score, db
# 传入app。生成manager
manager = Manager(app)
# 创建表
@ manager.command
def create_table():
db.create_all()
# 往user表里面添加数据
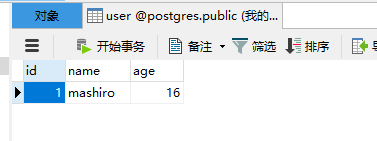
@manager.option("--n", dest="name")
@manager.option("--a", dest="age")
def add_user(name, age):
user = User()
user.name = name
user.age = age
db.session.add(user)
db.session.commit()
# 往score表里面添加数据
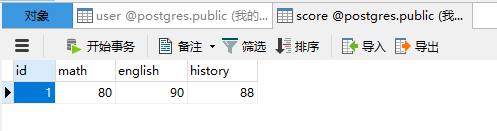
@manager.option("--m", dest="math")
@manager.option("--e", dest="english")
@manager.option("--h", dest="history")
def add_score(math, english, history):
score = Score()
score.math = math
score.english = english
score.history = history
db.session.add(score)
db.session.commit()
if __name__ == '__main__':
manager.run() # 这里是manager.run,不是app.run
生成表

给user表添加数据

给score表添加数据

而且我们还可以模拟数据库迁移,映射等等。Django的manage.py不就是这么做的吗?python manage.py makemigrations迁移,然后再python manage.py migrate映射。
而这种方式的实现,flask也帮我们封装好了
26.flask-migrate
在实际的数据库开发中,经常会出现数据表修改的行为。一般我们不会手动修改数据库,而是去修改orm模型,然后再把模型映射到数据库中。这个时候如果能有一个工具专门做这件事情就非常好了,而flask-migrate就是用来干这个的。flask-migrate是基于alembic的一个封装,并集成到flask当中,而所有的操作都是alembic做的,它能跟踪模型的变化,并将模型映射到数据库中。
显然也要安装,pip install flask-migrate,所以flask有着丰富的第三方插件,可以自己定制。所以写到最后,真的和Django没啥区别了。

model.py
from flask_script import Manager
from app import app
# 从模型里面导入User和Score模型,以及db
from model import User, Score, db
from flask_migrate import Migrate, MigrateCommand
# 传入app。生成manager
manager = Manager(app)
# 传入app和db,将app和db绑定在一起
migrate = Migrate(app, db)
# 把MigrateCommand命令添加到manager中
manager.add_command("db", MigrateCommand)
if __name__ == '__main__':
# 此时就可以了,大家可能看到我们这里导入了User和Score模型,但是没有使用
# 其实不是,生成数据库的表,是在命令行中操作的
# 为了在映射的时候能够找到这两个模型,所以要导入,只不过找模型我们不需要做,flask-migrate会自动帮我们处理
# 我们只负责导入就可以了
manager.run() # 这里是manager.run,不是app.run
执行python manage.py db init。这里的db就是我们manager.add_command("db", MigrateCommand)的db,我们也可以起其他的名字
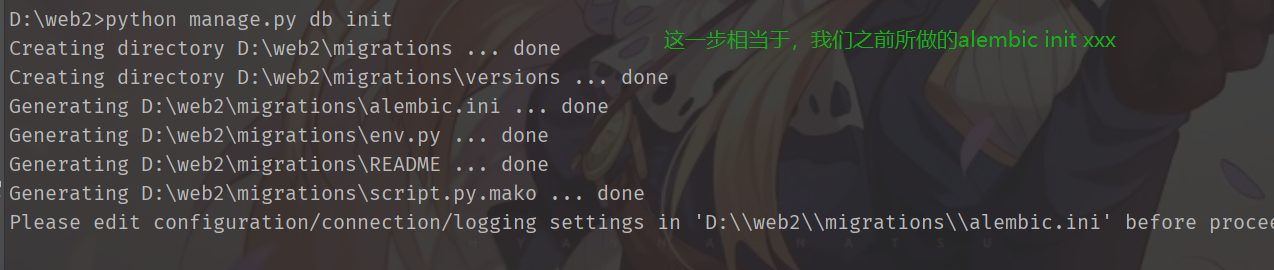
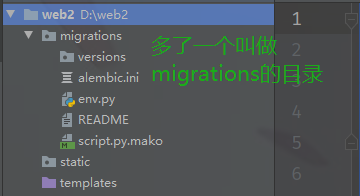
此时里面的文件,我们也不需要手动去改了,都帮我们弄好了
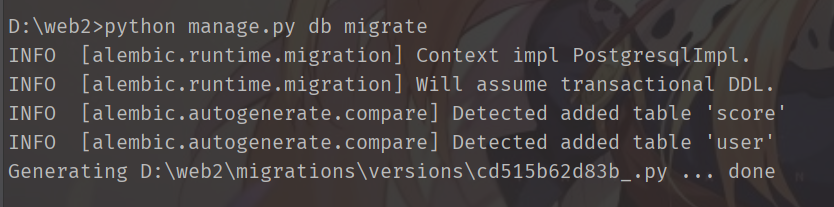
python manage.py db migrate,生成迁移文件

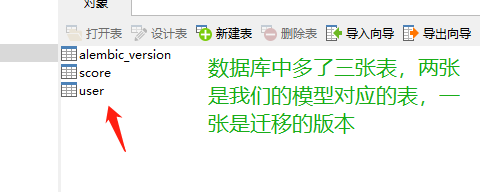
python manage.py db upgrade,将迁移文件映射到数据库中

总结如下:
介绍:因为采用db.create_all在后期修改字段的时候,不会自动的映射到数据库中,必须删除表,然后重新运行db.craete_all,或者先db.drop_all,才会重新映射,这样不符合我们的需求。因此flask-migrate就是为了解决这个问题,它可以在每次修改模型后,可以将修改的东西映射到数据库中。
使用flask_migrate必须借助flask_scripts,这个包的MigrateCommand中包含了所有和数据库相关的命令。
flask_migrate相关的命令:
python manage.py db init:初始化一个迁移脚本的环境,只需要执行一次。
python manage.py db migrate:将模型生成迁移文件,只要模型更改了,就需要执行一遍这个命令。
python manage.py db upgrade:将迁移文件真正的映射到数据库中。每次运行了migrate命令后,就记得要运行这个命令。
注意点:需要将你想要映射到数据库中的模型,都要导入到manage.py文件中,如果没有导入进去,就不会映射到数据库中。
我们来使用web的方式,添加数据吧
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="/add" method="post">
<table>
<tr>
<td>用户名:</td>
<td><input name="username" type="text"/></td>
</tr>
<tr>
<td>年龄:</td>
<td><input name="age" type="text"/></td>
</tr>
<tr>
<td>提交:</td>
<td><input type="submit"/></td>
</tr>
</table>
</form>
</body>
</html>
我们将代码的结构重新修改一下
config.py:存放配置
username = "postgres" # 用户名
password = "zgghyys123" # 密码
hostname = "localhost" # ip
port = 5432 # 端口
db_type = "postgresql" # 数据库种类
driver = "psycopg2" # 驱动
database = "postgres" # 连接到哪个数据库
SQLALCHEMY_DATABASE_URI = f"{db_type}+{driver}://{username}:{password}@{hostname}:{port}/{database}"
SQLALCHEMY_TRACK_MODIFICATIONS = False
exts.py
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
model.py
from exts import db
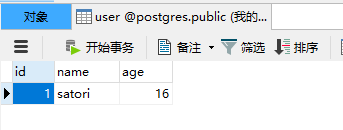
class User(db.Model):
__tablename__ = "user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.VARCHAR(100))
age = db.Column(db.Integer)
class Score(db.Model):
__tablename__ = "score"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
math = db.Column(db.Integer)
english = db.Column(db.Integer)
history = db.Column(db.Integer)
看到这里可能发现了,这里的db并没有传入app啊,那么它是如何找到的呢?别急
manage.py
from flask_script import Manager
from app import app
from model import User, Score
from exts import db
from flask_migrate import Migrate, MigrateCommand
# 传入app。生成manager
manager = Manager(app)
# 传入app和db,将app和db绑定在一起
migrate = Migrate(app, db)
# 把MigrateCommand命令添加到manager中
manager.add_command("db", MigrateCommand)
if __name__ == '__main__':
manager.run()
app.py
from flask import Flask, request, render_template
from model import User
from exts import db
import config
app = Flask(__name__)
# 导入配置
app.config.from_object(config)
# 通过db.init_app(app)会自动地将app里面的信息绑定到db里面去
db.init_app(app)
@app.route('/')
def hello_world():
return 'Hello World!'
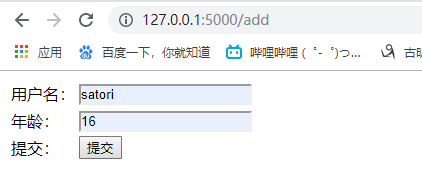
@app.route("/add", methods=["GET", "POST"])
def add():
if request.method == 'GET':
return render_template("add.html")
else:
name = request.form.get("username", None)
age = request.form.get("age", None)
user = User()
user.name = name
user.age = age
db.session.add(user)
db.session.commit()
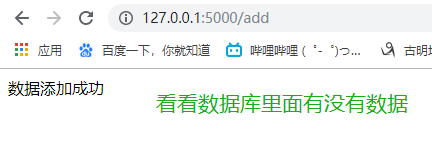
return f"数据添加成功"
if __name__ == '__main__':
app.run()
27.实战项目-中国工商银行注册功能
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>中国工商银行首页</title>
</head>
<body>
<h1>欢迎来到中国工商银行</h1>
<ul>
<li><a href="{{ url_for('register') }}">立即注册</a></li>
</ul>
</body>
</html>
register.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>中国银行注册页面</title>
</head>
<body>
<form action="/register" method="post">
<table>
<tbody>
<tr>
<td>邮箱:</td>
<td><input type="email" name="email"></td>
</tr>
<tr>
<td>用户名:</td>
<td><input type="text" name="username"></td>
</tr>
<tr>
<td>密码:</td>
<td><input type="password" name="password"></td>
</tr>
<tr>
<td>重复密码:</td>
<td><input type="password" name="repeat_password"></td>
</tr>
<tr>
<td>余额:</td>
<td><input type="text", name="deposit"></td>
</tr>
<tr>
<td></td>
<td><input type="submit" value="立即注册"></td>
</tr>
</tbody>
</table>
</form>
</body>
</html>
exts.py
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
model.py
from exts import db
class User(db.Model):
__tablename__ = "user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
email = db.Column(db.String(50), nullable=False)
username = db.Column(db.String(50), nullable=False)
password = db.Column(db.String(50), nullable=False)
deposit = db.Column(db.Float(50), default=10)
manage.py
from flask_script import Manager
from app import app
from model import User
from exts import db
from flask_migrate import Migrate, MigrateCommand
# 传入app。生成manager
manager = Manager(app)
# 传入app和db,将app和db绑定在一起
migrate = Migrate(app, db)
# 把MigrateCommand命令添加到manager中
manager.add_command("db", MigrateCommand)
if __name__ == '__main__':
manager.run()
forms.py
from wtforms import Form, StringField, FloatField
from wtforms.validators import Length, EqualTo, Email, InputRequired
class RegisterForm(Form):
email = StringField(validators=[Email()])
username = StringField(validators=[Length(6, 20)])
password = StringField(validators=[Length(6, 20)])
repeat_password = StringField(validators=[EqualTo("password")])
deposit = FloatField(validators=[InputRequired()])
app.py
from flask import Flask, render_template, request, views
from forms import RegisterForm
from exts import db
from model import User
import config
app = Flask(__name__)
app.config.from_object(config)
db.init_app(app) # 这个和db = SQLAlchemy(app)效果是一样的
@app.route('/')
def index():
return render_template("index.html")
class RegisterView(views.MethodView):
def get(self):
return render_template("register.html")
def post(self):
form = RegisterForm(request.form)
if form.validate():
email = form.email.data
username = form.username.data
password = form.password.data
deposit = form.deposit.data
user = User(email=email, username=username, password=password, deposit=deposit)
db.session.add(user)
db.session.commit()
return "注册成功"
else:
return f"注册失败,{form.errors}"
app.add_url_rule("/register", view_func=RegisterView.as_view("register"))
if __name__ == '__main__':
app.run()
将之前的表全部删除,然后执行python manage.py db init,然后执行python manage.py db migrate 然后执行python manage.py db upgrade,然后会发现数据库多了一张user表

访问localhost:5000
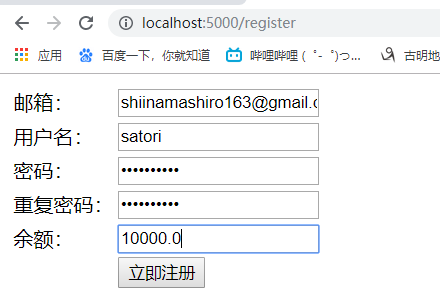
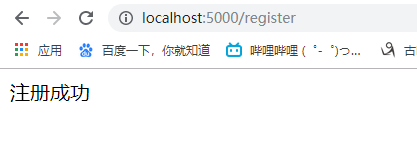
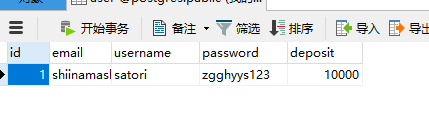
发现数据已经被添加到数据库里面了
28.实战项目-中国工商银行登录和转账实现
首页,index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>中国工商银行首页</title>
</head>
<body>
<h1>欢迎来到中国工商银行</h1>
<ul>
<li><a href="{{ url_for('register') }}">立即注册</a></li>
<li><a href="{{ url_for('login') }}">立即登录</a></li>
<li><a href="{{ url_for('transfer') }}">立即转账</a></li>
</ul>
</body>
</html>
注册页面,register.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>中国银行注册页面</title>
</head>
<body>
<form action="/register" method="post">
<table>
<tbody>
<tr>
<td>邮箱:</td>
<td><input type="email" name="email"></td>
</tr>
<tr>
<td>用户名:</td>
<td><input type="text" name="username"></td>
</tr>
<tr>
<td>密码:</td>
<td><input type="password" name="password"></td>
</tr>
<tr>
<td>重复密码:</td>
<td><input type="password" name="repeat_password"></td>
</tr>
<tr>
<td>余额:</td>
<td><input type="text", name="deposit"></td>
</tr>
<tr>
<td></td>
<td><input type="submit" value="立即注册"></td>
</tr>
</tbody>
</table>
</form>
</body>
</html>
登录页面,login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>中国工商银行登录页面</title>
</head>
<body>
<form action="/login" method="post">
<table>
<tbody>
<tr>
<td>邮箱:</td>
<td><input name="email" type="email"></td>
</tr>
<tr>
<td>密码:</td>
<td><input name="password" type="password"></td>
</tr>
<tr>
<td></td>
<td><input type="submit" value="立即登录"></td>
</tr>
</tbody>
</table>
</form>
</body>
</html>
转账页面,transfer.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="/transfer" method="post">
<table>
<tbody>
<tr>
<td>转到邮箱:</td>
<td><input type="email" name="email"></td>
</tr>
<tr>
<td>转账金额:</td>
<td><input type="text" name="money"></td>
</tr>
<tr>
<td></td>
<td><input type="submit" value="立即转账"></td>
</tr>
</tbody>
</table>
</form>
</body>
</html>
py文件只有forms.py和app.py发生了变化,其他的没变
forms.py
from wtforms import Form, StringField, FloatField
from wtforms.validators import Length, EqualTo, Email, InputRequired, NumberRange
from model import User
class RegisterForm(Form):
email = StringField(validators=[Email()])
username = StringField(validators=[Length(6, 20)])
password = StringField(validators=[Length(6, 20)])
repeat_password = StringField(validators=[EqualTo("password")])
deposit = FloatField(validators=[InputRequired()])
class LoginForm(Form):
email = StringField(validators=[Email()])
password = StringField(validators=[Length(6, 20)])
class TransferForm(Form):
email = StringField(validators=[Email()])
money = FloatField(validators=[NumberRange(min=1, max=10000)])
app.py
from flask import Flask, render_template, request, views, session, redirect, url_for
from forms import RegisterForm, LoginForm, TransferForm
from exts import db
from model import User
import secrets
app = Flask(__name__)
app.config["SECRET_KEY"] = secrets.token_bytes()
app.config.from_object(config)
db.init_app(app) # 这个和db = SQLAlchemy(app)效果是一样的
@app.route('/')
def index():
return render_template("index.html")
# 注册
class RegisterView(views.MethodView):
def get(self):
return render_template("register.html")
def post(self):
form = RegisterForm(request.form)
if form.validate():
email = form.email.data
username = form.username.data
password = form.password.data
deposit = form.deposit.data
user = User(email=email, username=username, password=password, deposit=deposit)
db.session.add(user)
db.session.commit()
return "注册成功"
else:
return f"注册失败,{form.errors}"
app.add_url_rule("/register", view_func=RegisterView.as_view("register"))
# 登录
class LoginView(views.MethodView):
def get(self):
return render_template("login.html")
def post(self):
form = LoginForm(request.form)
if form.validate():
email = form.email.data
password = form.password.data
user = User.query.filter(User.email == email, User.password == password).first()
if user:
session["session_id"] = user.id
return "登录成功"
else:
return "邮箱或密码错误"
else:
return f"{form.errors}"
app.add_url_rule("/login", view_func=LoginView.as_view("login"))
# 转账
class TransferView(views.MethodView):
def get(self):
# 只有登录了才能转账,否则让其滚回登录页面
if session.get("session_id"):
return render_template("transfer.html")
else:
return redirect(url_for("login"))
def post(self):
form = TransferForm(request.form)
if form.validate():
email = form.email.data
money = form.money.data
user = User.query.filter_by(email=email).first()
if user:
session_id = session.get("session_id")
myself = User.query.get(session_id)
if myself.deposit >= money:
user.deposit += money
myself.deposit -= money
db.session.commit()
return f"转账成功,您向{user.email}转了{money}"
else:
return "您的资金不足,无法完成当前转账"
else:
return "该用户不存在"
else:
return "数据填写不正确"
app.add_url_rule("/transfer", view_func=TransferView.as_view("transfer"))
if __name__ == '__main__':
app.run()




下面进行转账
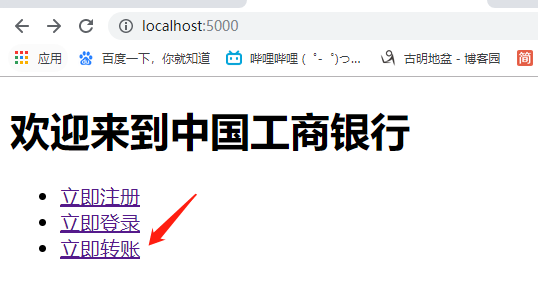

我们接下来看看数据库里面的金额
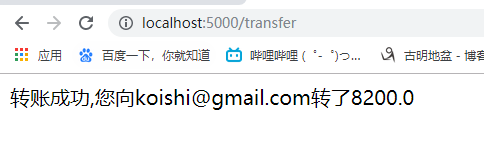
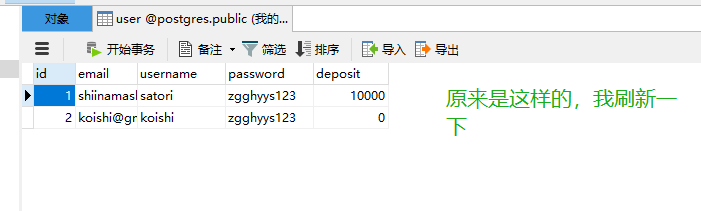
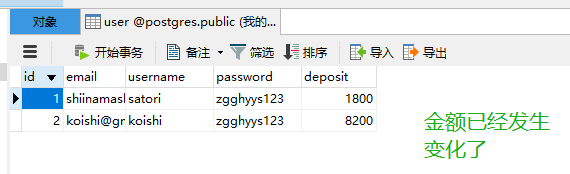
此时继续转账
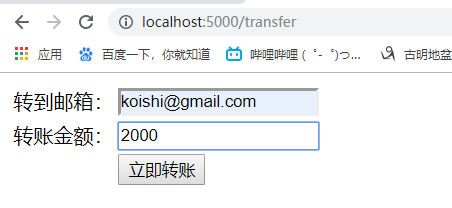
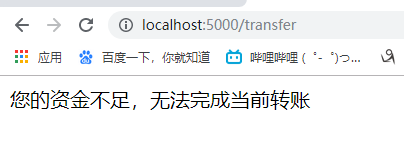
显示资金不够了
5.flask与数据库的更多相关文章
- Flask之数据库设置
4 数据库 知识点 Flask-SQLALchemy安装 连接数据库 使用数据库 数据库迁移 邮件扩展 4.1 数据库的设置 Web应用中普遍使用的是关系模型的数据库,关系型数据库把所有的数据都存储在 ...
- flask修改数据库字段的类型和长度
flask修改数据库字段的类型和长度 在将models中的字段的db.String(256)修改为db.String(1024)后,执行migrate和upgrade操作后,发现数据库并没有更新, ...
- flask从数据库反向导入Model以及出现报错No module named sqlacodegen.main
使用flask的朋友肯定了解了flask_sqlalchemy,不了解的小伙伴也可以查看博文:Flask 操作Mysql数据库 - flask-sqlalchemy扩展 上面博文中讲解了如何将flas ...
- python flask框架 数据库的使用
#coding:utf8 from flask import Flask from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) # ...
- Flask对数据库的操作-----
首先得做好做基本的框架 # -*- encoding: utf-8 -*- from flask import Flask,render_template #导入第三方连接库sql点金术 from f ...
- flask 更新数据库
在做项目的过程中,我们都遇到过,经常需要修改我们数据库的字段,在flask中,是通过ORM(对象关系映射)来创建数据库的,表--->model class,字段---->属性 在flask ...
- 关于 flask 实现数据库迁移以后 如何根据创建的模型类添加新的表?
在此之前 我们先说一下常规的flask运用第三方扩展来实现数据库的迁移的三个步骤以及每步的目的. 数据库的迁移的三个步骤:(cd 到run.py所在路径) python run.py db init ...
- Python——Flask框架——数据库
一.数据库框架 Flask-SQLAlchemy (1)安装: pip install flask-sqlalchemy (2)Flask-SQLAlchemy数据库URL 数据库引擎 URL MyS ...
- flask 定义数据库关系(一对多)
定义关系 在关系型数据库中,我们可以通过关系让不同表之间的字段建立联系.一般来说,定义关系需要两步,分别是创建外键和定义关系属性.在更复杂的多对多关系中,我们还需要定义关联表来管理关系.下面我们学习用 ...
- flask 操作数据库(分类)
数据库 数据库是大多数动态web程序的基础设施,只要你想把数据存下来,就离不开数据库. 这里所说的数据库指的是有存储数据的单个或多个文件组成的集合,它是一种容器,可以类比文文件柜.而人们通常使用数据库 ...
随机推荐
- linux性能分析之平均负载
平均负载 1,执行 top 或者 uptime 命令 来了解系统负载 uptime 分析显示 当前时间,系统运行时间,正在登录用户数 平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程 ...
- 学习前端第二天心得体会(初步了解HTML5的部分API以及画布Canvas)
一.HTML5部分API 1.选择器querySelector和querySelectorAll 1.1.querySelector:返回文档中匹配指定的CSS选择器的第一元素. document. ...
- rsync服务安装使用
ssh方式与daemon方式有什么大的区别吗?相对来说ssh比较简单易理解,是不是daemon安全性比较高呢? 区别是:ssh方式是通过ssh协议来传输,需要知道对方机器的用户名和密码. daemon ...
- Docker在CentOS下的安装
工欲善其事,必先利其器. 在我们以后的Docker学习中,都推荐使用CentOS6.5作为学习平台,毕竟Docker的内核也是基于Linux的.本文主要分享笔者在CentOS下的安装Docker的过程 ...
- Could not resolve host: mirrorlist.centos.org Centos 7 Unkown error
安装Centos7(core)以后,网卡默认不会启用.这是一个大坑,直接报错,这是一个过度优化,有几个开发人员/运维人员安装centos7(core)不用ssh去连接服务器的. 报错如下: Loade ...
- VMWare虚拟机->锁定文件失败,打不开磁盘的解决办法
VMWare虚拟机提示:锁定文件失败,打不开磁盘的解决办法 如果使用VMWare虚拟机的时候突然系统崩溃蓝屏,有一定几率会导致无法启动,会提示:“锁定文件失败,打不开磁盘...或它所依赖的某个快照 ...
- C语言基础:汉诺塔(递归方法)
分析:当只有一个盘子的时候,只需要从将A塔上的一个盘子移到C塔上.当A塔上有两个盘子是,先将A塔上的1号盘子(编号从上到下)移动到B塔上,再将A塔上的2号盘子移动的C塔上,最后将B塔上的小盘子移动到C ...
- 7-1 shell编程基础之二
shell编程基础之二 算数运算 bash中的算术运算:help let +, -, *, /, %取模(取余), **(乘方),乘法符号有些场景中需要转义 实现算术运算: (1) let var=算 ...
- PJzhang:从js文件中寻找子域名的SubDomainizer
猫宁!!! 有些专门针对企业客户的网站,可能没有供公开注册的页面,但是在js文件中可能会隐藏他们的注册接口,当然这也是一种安全风险,就像有些后台是一定不能不小心放外网一个道理. 最近看到一篇文章提 ...
- Linux C/C++基础——文件(上)
1.文件指针 FILE* fp=NULL; fp指针,只调用了fopen(),在堆区分配空间,把地址返回给fp fp指针不是指向文件,fp指针和文件关联,fp内部成员保存在文件的状态 操作fp指针,不 ...