Kd-tree的学习
一.普通kd-tree
1.在选择划分维度的时候,不能简单的每一个维度轮流划分。还有一种更合适的是利用数据的方差来划分,哪个维度的方差大,就选择哪一个维度划分。理由解释如下:
最简单的方法就是轮着来,即如果这次选择了在第i维上进行数据划分,那下一次就在第j(j≠i)维上进行划分,例如:j = (i mod k) + 1。想象一下我们切豆腐时,先是竖着切一刀,切成两半后,再横着来一刀,就得到了很小的方块豆腐。
可是“轮着来”的方法是否可以很好地解决问题呢?再次想象一下,我们现在要切的是一根木条,按照“轮着来”的方法先是竖着切一刀,木条一分为二,干净利落,接下来就是再横着切一刀,这个时候就有点考验刀法了,如果木条的直径(横截面)较大,还可以下手,如果直径较小,就没法往下切了。因此,如果K维数据的分布像上面的豆腐一样,“轮着来”的切分方法是可以奏效,但是如果K维度上数据的分布像木条一样,“轮着来”就不好用了。因此,还需要想想其他的切法。
如果一个K维数据集合的分布像木条一样,那就是说明这K维数据在木条较长方向代表的维度上,这些数据的分布散得比较开,数学上来说,就是这些数据在该维度上的方差(invariance)比较大,换句话说,正因为这些数据在该维度上分散的比较开,我们就更容易在这个维度上将它们划分开,因此,这就引出了我们选择维度的另一种方法:最大方差法(max invarince),即每次我们选择维度进行划分时,都选择具有最大方差维度。
2.样本都放在叶子结点,非叶子节点存放一些其他信息,比如说划分维度和对应的划分值。
3.为了使左右子树样本数量相近,可以选择中位数作为划分点。
4.怎样判断未被访问过的树分支Branch里是否还有离Q更近的点?
从几何空间上来看,就是判断以Q为中心center和以Dcur为半径Radius的超球面(Hypersphere)与树分支Branch代表的超矩形(Hyperrectangle)之间是否相交。
在实现中,我们可以有两种方式来求Q与树分支Branch之间的距离。第一种是在构造树的过程中,就记录下每个子树中包含的所有数据在该子树对应的维度k上的边界参数[min, max];第二种是在构造树的过程中,记录下每个子树所在的分割维度k和分割值m,(k, m),Q与子树的距离则为|Q(k) - m|。如果|Q(k) - m|小于当前最小距离,则说明另一区域与该超球体相交,可能存在距离更近的样本,则进入该父节点的另一子树继续查找。反之继续回溯。
二、Kd-tree with BBF
上一节介绍的Kd-tree在维度较小时(例如:K≤30),算法的查找效率很高,然而当Kd-tree用于对高维数据(例如:K≥100)进行索引和查找时,就面临着维数灾难(curse of dimension)问题,查找效率会随着维度的增加而迅速下降。通常,实际应用中,我们常常处理的数据都具有高维的特点,例如在图像检索和识别中,每张图像通常用一个几百维的向量来表示,每个特征点的局部特征用一个高维向量来表征(例如:128维的SIFT特征)。因此,为了能够让Kd-tree满足对高维数据的索引,Jeffrey S. Beis和David G. Lowe提出了一种改进算法——Kd-tree with BBF(Best Bin First),该算法能够实现近似K近邻的快速搜索,在保证一定查找精度的前提下使得查找速度较快。
在介绍BBF算法前,我们先来看一下原始Kd-tree是为什么在低维空间中有效而到了高维空间后查找效率就会下降。在原始kd-tree的最近邻查找算法中(第一节中介绍的算法),为了能够找到查询点Q在数据集合中的最近邻点,有一个重要的操作步骤:回溯,该步骤是在未被访问过的且与Q的超球面相交的子树分支中查找可能存在的最近邻点。随着维度K的增大,与Q的超球面相交的超矩形(子树分支所在的区域)就会增加,这就意味着需要回溯判断的树分支就会更多,从而算法的查找效率便会下降很大。
一个很自然的思路是:既然kd-tree算法在高维空间中是由于过多的回溯次数导致算法查找效率下降的话,我们就可以限制查找时进行回溯的次数上限,从而避免查找效率下降。这样做有两个问题需要解决:1)最大回溯次数怎么确定?2)怎样保证在最大回溯次数内找到的最近邻比较接近真实最近邻,即查找准确度不能下降太大。
问题1):最大回溯次数怎么确定?
最大回溯次数一般人为设定,通常根据在数据集上的实验结果进行调整。
问题2):怎样保证在最大回溯次数内找到的最近邻比较接近真实最近邻,即查找准确度不能下降太大?
限制回溯次数后,如果我们还是按照原来的回溯方法挨个地进行访问的话,那很显然最后的查找结果的精度就很大程度上取决于数据的分布和回溯次数了。挨个访问的方法的问题在于认为每个待回溯的树分支中存在最近邻的概率是一样的,所以它对所有的待回溯树分支一视同仁。实际上,在这些待回溯树分支中,有些树分支存在最近邻的可能性比其他树分支要高,因为树分支离Q点之间的距离或相交程度是不一样的,离Q更近的树分支存在Q的最近邻的可能性更高。因此,我们需要区别对待每个待回溯的树分支,即采用某种优先级顺序来访问这些待回溯树分支,使得在有限的回溯次数中找到Q的最近邻的可能性很高。我们要介绍的BBF算法正是基于这样的解决思路,下面我们介绍BBF查找算法。
基于BBF的Kd-Tree近似最近邻查找算法
已知:
Q:查询数据; KT:已建好的Kd-Tree;
1. 查找Q的当前最近邻点P
1)从KT的根结点开始,将Q与中间结点node(k,m)进行比较,根据比较结果选择某个树分支Branch(或称为Bin);并将未被选择的另一个树分支(Unexplored Branch)所在的树中位置和它跟Q之间的距离一起保存到一个优先级队列中Queue;
2)按照步骤1)的过程,对树分支Branch进行如上比较和选择,直至访问到叶子结点,然后计算Q与叶子结点中保存的数据之间的距离,并记录下最小距离D以及对应的数据P。
注:
A、Q与中间结点node(k,m)的比较过程:如果Q(k) > m则选择右子树,否则选择左子树。
B、优先级队列:按照距离从小到大的顺序排列。
C、叶子结点:每个叶子结点中保存的数据的个数可能是一个或多个。
2. 基于BBF的回溯
已知:最大回溯次数BTmax
1)如果当前回溯的次数小于BTmax,且Queue不为空,则进行如下操作:
从Queue中取出最小距离对应的Branch,然后按照1.1步骤访问该Branch直至达到叶子结点;计算Q与叶子结点中各个数据间距离,如果有比D更小的值,则将该值赋给D,该数据则被认为是Q的当前近似最近邻点;
2)重复1)步骤,直到回溯次数大于BTmax或Queue为空时,查找结束,此时得到的数据P和距离D就是Q的近似最近邻点和它们之间的距离。
下面用一个简单的例子来演示基于Kd-Tree+BBF的近似最近邻查找的过程。
数据点集合:(2,3), (4,7), (5,4), (9,6), (8,1), (7,2) 。
已建好的Kd-Tree:
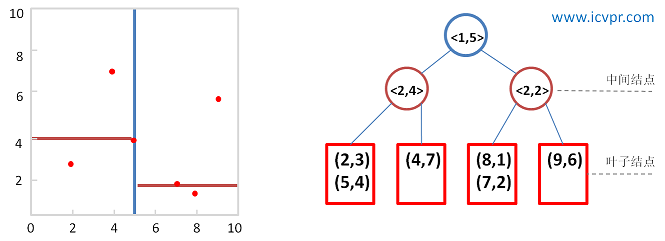
图6 构建的kd-tree
基于BBF的查找的过程:
查询点Q: (5.5, 5)
第一遍查询:

图7 第一次查询的kd-tree
当前最近邻点: (9, 6) , 最近邻距离: sqrt(13.25),
同时将未被选择的树分支的位置和与Q的距离记录到优先级队列中。
BBF回溯:
从优先级队列里选择距离Q最近的未被选择树分支进行回溯。

图8 利用BBF方法回溯kd-tree
当前最近邻点: (4, 7) , 最近邻距离: sqrt(6.25)
继续从优先级队列里选择距离Q最近的未被选择树分支进行回溯。
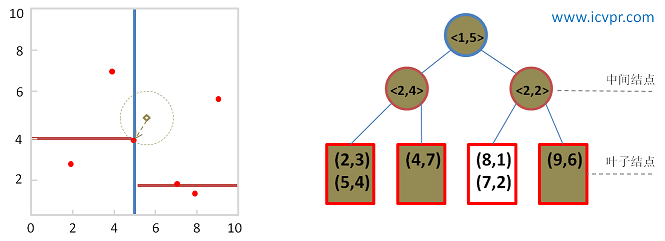
图9 利用BBF方法回溯kd-tree
当前最近邻点: (5, 4) , 最近邻距离: sqrt(1.25)
最后,查询点(5.5, 5)的近似最近邻点为(5, 4) 。
转自:https://my.oschina.net/keyven/blog/221792
Kd-tree的学习的更多相关文章
- k-d tree 学习笔记
以下是一些奇怪的链接有兴趣的可以看看: https://blog.sengxian.com/algorithms/k-dimensional-tree http://zgjkt.blog.uoj.ac ...
- [学习笔记]K-D Tree
以前其实学过的但是不会拍扁重构--所以这几天学了一下 \(K-D\ Tree\) 的正确打开姿势. \(K\) 维 \(K-D\ Tree\) 的单次操作最坏时间复杂度为 \(O(k\times n^ ...
- K-D Tree学习笔记
用途 做各种二维三维四维偏序等等. 代替空间巨大的树套树. 数据较弱的时候水分. 思想 我们发现平衡树这种东西功能强大,然而只能做一维上的询问修改,显得美中不足. 于是我们尝试用平衡树的这种二叉树结构 ...
- 【学习笔记】K-D tree 区域查询时间复杂度简易证明
查询算法的流程 如果查询与当前结点的区域无交集,直接跳出. 如果查询将当前结点的区域包含,直接跳出并上传答案. 有交集但不包含,继续递归求解. K-D Tree 如何划分区域 可以借助下文图片理解. ...
- k-d tree算法
k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构.主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索). 应用背景 SIFT算法中做特征点匹配的时候就会利用到k ...
- [转载]kd tree
[本文转自]http://www.cnblogs.com/eyeszjwang/articles/2429382.html k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据 ...
- 【数据结构与算法】k-d tree算法
k-d tree算法 k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构.主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索). 应用背景 SIFT算法中做特征点 ...
- P4169-CDQ分治/K-D tree(三维偏序)-天使玩偶
P4169-CDQ分治/K-D tree(三维偏序)-天使玩偶 这是一篇两种做法都有的题解 题外话 我写吐了-- 本着不看题解的原则,没写(不会)K-D tree,就写了个cdq分治的做法.下面是我的 ...
- AOJ DSL_2_C Range Search (kD Tree)
Range Search (kD Tree) The range search problem consists of a set of attributed records S to determi ...
- 【BZOJ-2648&2716】SJY摆棋子&天使玩偶 KD Tree
2648: SJY摆棋子 Time Limit: 20 Sec Memory Limit: 128 MBSubmit: 2459 Solved: 834[Submit][Status][Discu ...
随机推荐
- windows cmd中查看某个命令所在的路径
需求描述: 之前用linux环境下的which命令就能看到某个命令的绝对路径, 然后想在windows下的cmd中是否也能够查看到命令的绝对路径呢 操作过程: 1.windows环境下,通过where ...
- supervisorctl unix:///var/run/supervisor.sock refused connection
运行supervisorct 报如下错误 supervisorctl unix:///var/run/supervisor.sock refused connection 查看supervisord. ...
- ubuntu13.10更换源
Ubuntu13.10更新源 不同的网络状况连接以下源的速度不同, 建议在添加前手动验证以下源的连接速度(ping下就行),选择最快的源可以节省大批下载时间. 首先备份源列表: sudo cp /et ...
- Android Tab切换
ViewPager+FragmentStatePagerAdapter 页面切换案例详解 http://blog.csdn.net/u010203181/article/details/4462963 ...
- VC++第三方库配置-OpenSpirit 4.2.0 二次开发
在VS中右击项目,点击属性 1.配置属性--常规--输出目录:Windows\VS2010\debug\ 2.配置属性--常规--中间目录:Windows\VS2010\debug\ 3.配置属性-- ...
- redis客户端使用密码
./redis-cli -h 127.0.0.1 -p 6379 -a password
- Discuz! X2验证码的产生及验证
http://www.mcqyy.com/wenku/jiaocheng/jzjc/cjc/106729.html http://blog.sina.com.cn/s/blog_4acbd39c010 ...
- GIT+ Coding使用方法
1 进入码市 :https://coding.net 注册一个账户 2 创建一个项目: 3 本地window环境.安装git : https://git-scm.com/download/win ...
- MQTT协议笔记之mqtt.io项目Websocket协议支持
前言 MQTT协议专注于网络.资源受限环境,建立之初不曾考虑WEB环境,倒也正常.虽然如此,但不代表它不适合HTML5环境. HTML5 Websocket是建立在TCP基础上的双通道通信,和TCP通 ...
- [UML]UML 教程
统一建模语言(UML)已经迅速变成建立面向对象软件的事实标准.本教程提供了Enterprise Architect支持的13种UML图的技术概览.UML 2 详细的语义解释请看新的UML 2 教程. ...