字符编码unicode,utf-8和ascii
Ascii编码
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode编码
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
字母A用ASCII编码是十进制的65,二进制的01000001;
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。
UTF-8编码
UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
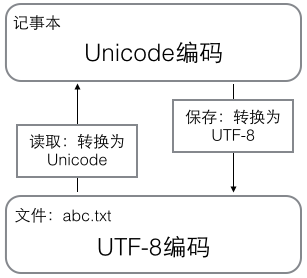
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
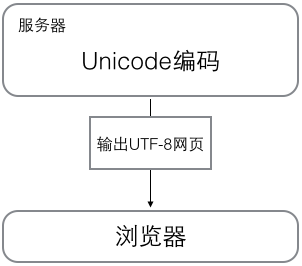
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
字符编码unicode,utf-8和ascii的更多相关文章
- 各种编码UNICODE、UTF-8、ASCII学习笔记
本文转自csdn博客:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html ,感谢作者的分享 作者: 阮一峰 日期: ...
- 字符编码-UNICODE,GBK,UTF-8区别【转转】
字符编码介绍及不同编码区别 今天看到这篇关于字符编码的文章,抑制不住喜悦(总结的好详细)所以转到这里来.转自:祥龙之子http://www.cnblogs.com/cy163/archive/2007 ...
- 彻底搞懂字符编码(unicode,mbcs,utf-8,utf-16,utf-32,big endian,little endian...)[转]
最近有一些朋友常问我一些乱码的问题,和他们交流过程中,发现这个编码的相关知识还真是杂乱不堪,不少人对一些知识理解似乎也有些偏差,网上百度, google的内容,也有不少以讹传讹,根本就是错误的(例如说 ...
- java字符编码-Unicode编码问题刨根究底
博客搬家: java字符编码问题 前段时间在读<java核心技术卷一>,遇到一些名词:码点.代码单元等,其实字面意思不难理解,解释如下 码点(code point):Unicode编码表中 ...
- 字符串和字符编码unicode
python基础第三天 字符串 str 作用: 用来记录文本(文字)信息,给人类识别用的,为人们提供注释解释说明 表示方式: 在非注释中,凡是用引号括起来的部分都是字符串 ' 单引号 " 双 ...
- 字符集和编码——Unicode(UTF&UCS)深度历险
计算机网络诞生后,大家慢慢地发现一个问题:一个字节放不下一个字符了!因为需要交流,本地化的文字需要能够被支持. 最初的字符集使用7bit来存储字符,因为那时只需要存下一些英文字母和符号.后来虽然扩展到 ...
- 各个系统和语言对Unicode的支持 字符集和编码——Unicode(UTF&UCS)深度历险
http://www.cnblogs.com/Johness/p/3322445.html 各个系统和语言对Unicode的支持: Windows NT从底层支持Unicode(不幸的是,Window ...
- 一句话理解字符编码(Unicode ,UTF8,UTF16)
Unicode和ASCII码属于同一级别的,都是字符集,字符集规定从1到这个字符集的最大范围每个序号都各表示什么意思.比如ASCII字符集中序号65表示"A". 那接下来的UTF8 ...
- 字符编码-Unicode、Utf-8 笔记
Unicode 将世界上所有的符号都纳入其中.每一个符号都给予一个独一无二的编码,那么乱码问题就会消失.这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码 UTF-8 UTF-8 就 ...
随机推荐
- cesium编程中级开篇
cesium编程中级开篇 其实初级,中级并无定论,我理解的初级是根据官方教程,先学会如何部署环境,搭建hello world,使用官方提供的工具,完成一些示例, 而中级就是在这些的基础上,自己定制一些 ...
- UDP通讯
上一篇有说到TCP通讯,这篇来谈谈UDP通讯方式 基于Udp协议是无连接模式通讯,占用资源少,响应速度快,延时低.至于可靠性,可通过应用层的控制来满足.(不可靠连接) (1).建立一个套接字(Sock ...
- Spring Boot 学习系列(06)—采用log4j2记录日志
此文已由作者易国强授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 为什么选择log4j2 log4j2相比于log4j1.x和logback来说,具有更快的执行速度.同时也支 ...
- 【OCP题库】最新CUUG OCP 12c 071考试题库(66题)
66.(22-19)choose two Examine the structure proposed for the TRANSACTIONS table: Which two statements ...
- 【Oracle 12c】最新CUUG OCP-071考试题库(56题)
56.(14-14) choose the best answer: You need to create a table with the following column specificatio ...
- css3半圆
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- zTree第三章,异步加载,前端
zTree异步加载 ---------------------------------------------------------------------------------- 具体详见API ...
- deepin配置反向代理映射本地到公网
这里我是用的小米球的免费ngrok 相信deepin的新用户在配置反向代理时,会感觉到一脸茫然,因为一开始我也是这样,但经过短暂的了解了deepin后,发现,其实与在Debian上配置并没有什么区别! ...
- java使用Redis1--安装与简单使用
环境: CentOS6.4,Redis3.0.3 一.Redis安装(需要安装gcc) 官网http://download.redis.io/releases/redis-3.0.3.tar.gz上下 ...
- 总结day13 ----内置函数
内置函数 我们一起来看看python里的内置函数.什么是内置函数?就是Python给你提供的,拿来直接用的函数,比如print,input等等.截止到python版本3.6.2,现在python一共为 ...